容器監測環境有多種形態和大小。有些是開源的,而另一些則是商業性質的。有些可以藉助平臺一鍵部署(例如在Rancher容器管理平臺的應用目錄中一鍵部署這些監控應用),而另一些則需要手動配置。有些是通用的,有些是專門針對容器環境的。有些託管在公有雲中,而另一些則需要在自己的叢集主機上安裝。
在本文中,我將對容器領域的10個監控解決方案進行全面的分析對比。監控解決方案的數量之多令人望而生畏。新的解決方案不斷湧現,同時現有的解決方案不斷發展。我沒有深入研究每個解決方案,而是採取了high-level的對比方法。透過這種方法,讀者可以“縮小串列”,並能針對自身需求進行更認真的評估,從而選出最適合的解決方案。
在以下章節中,我提出了一個對比監控解決方案的架構,並對每個解決方案進行了高階對比,然後透過討論每個解決方案將如何與Rancher協同工作,從而更詳細地討論每個解決方案的細節。我還會在最後談談一些其它的監控解決方案,這些方案未被納入本文的“十大”中,但你也可能遇到過。

客觀地對比監控解決方案面臨的一個挑戰是,解決方案的架構、功能、部署模型和成本可能會有很大的差異。一個解決方案可以從單個主機提取和繪製Docker相關的資料,而另一個解決方案則可以從許多主機收集資料,測量應用程式響應時間,併在特定條件下傳送自動警報。
在對比解決方案時,先確定一個對比架構,將會為後期的對比工作帶來很大幫助。我有些武斷地提出瞭如下圖的對比架構,以大多數監控解決方案都具有的功能層,來作為我對比的基礎。這個對比架構可以分為7層:
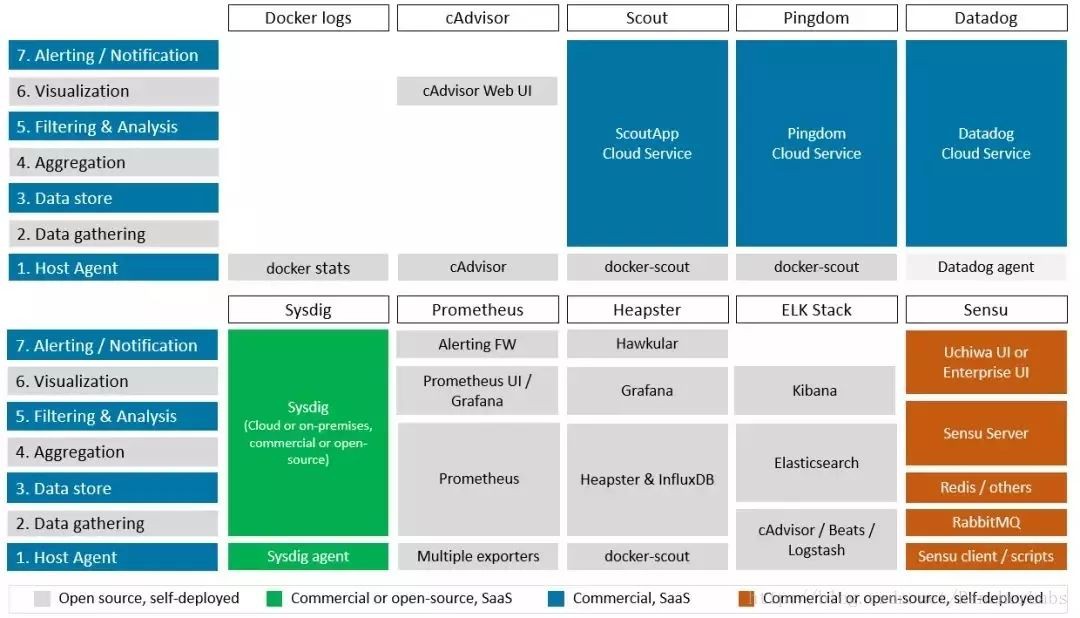
主機代理——主機代理代表監控解決方案的“肢體”,它會從各種來源(如API和日誌檔案)提取時間序列資料。主機代理通常安裝在每個叢集主機上(無論是本地還是雲端),並且它們通常被打包成Docker容器,以便部署和管理。
資料收集架構——雖然單主機資料有時很有用,但管理員可能需要所有主機和應用程式的統一檢視。監控解決方案通常具備一些機制來收集每個主機的資料,並將其儲存在共享資料儲存區中。
資料儲存——資料儲存可能是傳統的資料庫,但更常見的一種形式是可伸縮的分散式資料庫,由鍵值對組成的時間序列資料進行了最佳化。有些解決方案具有原生資料儲存,而其他解決方案則使用的是開源的資料儲存外掛。
聚合引擎——要儲存來自數十個主機的原始資料,可能遇見的一大問題是資料量會變得過大。監控架構通常提供資料聚合功能,定期將原始資料轉換為統一的度量標準(比如每小時或每日進行彙總),清除不再需要的舊資料,或以某種方式重新分解資料,以支援預期的查詢和分析。
過濾和分析——一個監控解決方案就像是你從資料中獲得的洞察力。不同的監控解決方案之間,篩選和分析的能力常常差別很大。有些解決方案僅支援以簡單的時間序列圖表的形式來進行一些預先打包的查詢, 而另一些則具有可自定義的儀錶板、嵌入式查詢語言和複雜的分析功能。
視覺化層——監控工具通常具有視覺化層,使用者可以在其中與Web介面進行互動以生成圖表、制定查詢以及在某些情況下定義警報條件。視覺化層可能與篩選和分析功能緊密耦合,也可能根據解決方案而與其分開。
告警和通知——很少管理員有時間整天坐著、時刻關註監控圖表。監控系統的另一個常見特性是告警子系統,如果達到或超過了預定義的閾值,可以向管理員發出通知。
除瞭解每個監控解決方案如何實現上述基本功能之外,如下方面也是使用者在選擇監控解決方案時應該註意與考量的:
下圖以high-level的形式展示了我們提出的的10個監控解決方案如何對應我們在上文提出的七層對比模型,哪些元件實現了每層功能,以及元件的所在位置。每個框架都是極其複雜的,下圖的對比方式毋庸置疑是一種簡化,不過它也會給大家提供一個有用的視角來瞭解各個元件的功能。
下圖的摘要介紹了每個監控解決方案的附加屬性。其中某些解決方案有多個部署選項,所以它們之間的對比就變得更加細微。
https://www.docker.com/docker-community
Docker透過Docker stats命令為Docker主機提供了內建命令監控功能。管理員可以查詢Docker守護行程,並獲取有關容器資源消耗資料的詳細實時資訊,包括CPU和記憶體使用、磁碟和網路I/O以及正在執行的行程數。Docker stats利用Docker引擎API來檢索這些資訊。Docker統計資訊沒有歷史概念,它只能監控單個主機,但聰明的管理員可以編寫指令碼從多個主機收集資料。
Docker stats本身用處有限,但Docker統計資料可以與其他資料源(如Docker日誌檔案和Docker事件)結合使用,以滿足更高階別的監控服務。Docker只能得到單個主機報告的資料,所以Docker stats對於使用多主機應用程式服務的Kubernetes或對Swarm叢集進行監控的能力有限。由於沒有視覺化介面,沒有聚合,沒有資料儲存,也無法從多個主機收集資料,所以Docker的統計資料對我們的七層模型來說並不太適用。由於Rancher在Docker上執行,Rancher使用者可以自動使用基本的docker stats功能。
https://github.com/google/cadvisor
cAdvisor是一個開源專案,好比Docker stats向用戶提供關於執行容器的資源使用資訊。cAdvisor最初是由谷歌開發的,用於管理其lmctfy容器,但它現在也支援Docker。作為守護行程,它收集、聚集、處理和匯出關於執行容器的資訊。
cAdvisor有一個web介面,可以生成多個圖表,但是像Docker stats一樣,它只監控一個Docker主機。它可以作為容器安裝在Docker machine上,也可以在Docker主機本身上安裝。
cAdvisor本身只保留60秒的資訊。需要將cAdvisor設定為將資料記錄到外部資料儲存庫中。常用於cAdvisor資料的資料儲存庫包括Prometheus和InfluxDB。雖然cAdvisor本身並不是一個完整的監控解決方案,但它通常是其他監控解決方案的組成部分。在Rancher版本1.2前,Rancher在Rancher agent中嵌入了cAdvisor(用於Rancher的內部使用),但現在已經不是這樣了。最新版本的Rancher使用Docker統計來收集透過Rancher UI公開的資訊,因為它們可以減少開銷。
管理員可以輕鬆地在Rancher上部署cAdvisor,它是幾個綜合監控堆疊的一部分,但是cAdvisor不再是Rancher本身的一部分。
Scout是一家總部位於科羅拉多州的公司,它提供基於雲的應用程式和資料庫監控服務,主要針對Ruby和Elixir環境。其現有的監控和警報架構使其能夠監控Docker容器。
我們提到Scout,因為之前在比較監控Docker的解決方案時就提到了它。透過靈活的告警和與第三方告警服務的整合,Scout提供全面的資料收集、過濾和監控功能。
Scout的團隊提供瞭如何使用Ruby和StatsD編寫指令碼的指導,以利用Docker Stats API、Docker Event API和傳遞資料來監控這些指令碼。他們還打包了一個docker-scout容器,可以在Docker Hub(scoutapp / Docker – scout)上使用,這就使安裝和配置Scout代理變得更簡單。易用性取決於使用者是自行配置StatsD代理,還是使用打包的docker-scout容器。
作為一種託管雲服務,ScoutApp可以在快速啟動並執行容器監控解決方案時省去許多麻煩。如果您正在部署Ruby應用程式或執行Scout支援的資料庫環境,使用Scout解決方案,可以幫助您很好地整合您的Docker、應用程式和資料庫級別的監控。
但是,使用者可能需要註意一些事項。在大多數服務級別上,該平臺只允許保留30天的資料,而不是每個被監控的主機。至於價格,每月定價的標準套餐價格從99美元到299美元不等。這一開箱即用的解決方案只能提取和傳遞有限的指標,也不太適用於Kubernetes相關的監控。此外,雖然docker-scout在Docker Hub上可用,但開發是由Pingdom完成的,在過去的兩年中,Scout的代理元件只有很小的更新。
Rancher自身並不預設原生支援Scout,但由於Scout是雲服務,所以它在Rancher中很容易部署和使用,特別是當使用基於容器的代理時。目前,docker-scout代理不在Rancher應用程式目錄中。
上文中我們提到Scout作為雲託管的應用程式,因此還需要提到一個類似的解決方案,稱為Pingdom。Pingdom是由德克薩斯州奧斯汀市的SolarWinds公司運營的託管雲服務,它是一家專註於監控IT基礎架構的公司。Pingdom的主要用例是網站監控,作為伺服器監控平臺的一部分,Pingdom提供了大約90個外掛。事實上,Pingdom維護docker-scout,同樣地,Scout也使用StatsD代理。
Pingdom值得關註的原因在於,它靈活的定價方案似乎更適合監控Docker環境。使用者可以根據計劃收集到的StatsD資料數(每10個資料每月要價1美元)在基於每個伺服器的計劃之間進行選擇。Pingdom易於設定和管理,對於需要一個完整的監視解決方案的使用者以及希望監控容器管理平臺之外的其他服務的使用者而言,Pingdom非常合適。像Scout一樣,Pingdom是一種雲服務,並且易於同Rancher結合使用。
https://www.datadoghq.com/
Datadog是另一個類似於Scout和Pingdom的商業託管雲監控服務。Datadog還提供了一個Dockerized agent,用於在每個Docker主機上進行安裝;然而,Datadog並沒有像前面提到的雲監控解決方案那樣使用StatsD,而是開發了一種增強的StatsD,稱為DogStatsD。Datadog代理收集並傳遞Docker API提供的完整資料,從而進行更詳實、細緻的監控。
雖然Datadog不能原生支援Rancher,但是Rancher UI中有Datadog目錄,使用者可以在Rancher上輕鬆地安裝和配置Datadog agent。使用者還可以使用Rancher 標簽,Datadog中的報告反映了您在Rancher中用於主機和應用程式的標簽。與前面提到的雲服務相比,Datadog能夠提供更好的資料訪問許可權和更精細的定義警報條件。與其他服務一樣,Datadog也可用於監視其他服務和應用程式,並擁有超過200個整合的庫。Datadog還能保留18個月的全解析度資料,這比雲服務要更長。
與其他雲服務相比,Datadog的優勢在於它具有超越Docker的整合功能,並且可以從Kubernetes、Mesos、etcd和其他在您的Rancher環境中執行的服務中收集資料。對於在Rancher上執行Kubernetes的使用者來說,這種多功能性是很重要的,因為他們希望能夠監控諸如Kubernetes Pods、服務、namespaces和kubelet health之類的資料。Datadog-Kubernetes監控解決方案透過Kubernetes中的DaemonSets,能夠自動將資料收集代理部署到每個叢集節點。
Datadog的定價為每臺主機每月約15美元,總價會根據使用者需要的服務和每個主機監控的容器數量相應增加。
Sysdig是一家加州公司,為使用者提供基於雲端計算的監控解決方案。與前文所描述的幾個基於雲的監控解決方案不同的是,Sysdig更專註於監控容器環境,包括Docker、叢集、Mesos和Kubernetes。此外,Sysdig還在開源專案中提供了一些可用功能,並且可以選擇對Sysdig監控服務進行雲部署還是本地部署。在這些方面,Sysdig不同於迄今為止所出現的其他基於雲的解決方案。
Sysdig,與Datadog類似,其目錄可用於Rancher,但Sysdig的本地和雲安裝都有單獨目錄。從Rancher Catalog裡自動安裝的Sysdig無法用於對Kubernetes的監控;不過,它也可以不透過Rancher Catalog來安裝到Rancher之上。商用Sysdig監控具有Docker監控、告警和故障排除功能,並且還具有 Kubernetes、Mesos和叢集識別的功能。Sysdig能夠自動識別Kubernetes Pod和服務,因此選擇Kubernetes作為Rancher的編排架構將是一個很好的解決方案。
Sysdig和Datadog一樣是按每個主機每月定價。雖然Sysdig入門價格略高,但它每個主機上可以支援更多容器,因此根據使用者的環境,實際定價可能非常相似。 Sysdig還提供了一個全面的CLI——csysdig,將其與一些產品區分開來。
Prometheus是一個很受歡迎的開源監控和警報工具包,它最初是在SoundCloud進行構建的。現在是CNCF專案,也是該公司在Kubernetes之後的第二個託管專案。作為一個工具包,它與目前為止所描述的其他監視解決方案有很大不同。首先一個主要的區別是,Prometheus,作為一種雲服務,是模組化的,可以自行託管,這意味著無論是在本地還是在雲端,使用者都可以在他們的叢集上部Prometheus。
值得註意的是,Prometheus不是將資料推送到雲服務,而是安裝在每個Docker主機上,並透過HTTP從Prometheus提供的各種輸出口獲取或“抓取”資料。其中,一些輸出口被官方保留為Prometheus GitHub專案的一部分,而另一些則是由外部貢獻。有些專案本身暴露了Prometheus資料,因此不需要輸出口。由於Prometheus可高度擴充套件,使用者需要考慮輸出方的數量,並根據收集的資料量適當地配置輪詢間隔。
Prometheus的伺服器從各種來源檢索時間序列資料,並將資料儲存在其內部資料儲存區中。此外,Prometheus提供服務發現等功能,這是一種針對特定型別資料的獨立推送閘道器,並且有一個嵌入的查詢語言(PromQL),該語言擅長查詢多維資料。同時,它也有一個嵌入式的Web UI和API。雖然Prometheus中的Web UI提供了強大的功能,但使用者必須對PromQL十分瞭解,因此一些站點更願意使用Grafana作為繪製和檢視叢集相關指標的介面。
Prometheus有一個獨立的告警管理器,它也具有獨特的UI,並且可以處理儲存在Prometheus中的資料。和其他告警管理器一樣,它可以與各種外部告警服務一起工作,包括電子郵件、Hipchat、Pagerduty、#Slack、OpsGenie、VictorOps等。
由於Prometheus由許多元件組成,輸出方需要根據所監控的服務進行選擇和安裝,所以安裝起來比較困難,但是作為免費產品,在價格上Prometheus具有無可比擬的優勢。
雖然不像Datadog或Sysdig這樣精煉,但是Prometheus提供了類似的功能、廣泛的第三方軟體整合以及一流的雲監控解決方案,並且Prometheus十分瞭解Kubernetes和其他容器管理架構。另外,由Infinityworks開發的Rancher Catalog中的條目使得在使用Cattle作為Rancher的編排架構時,Prometheus更容易入門,但由於配置選項的種類繁多,管理員需要花費一些時間才能正確安裝和配置。
Infinityworks提供了一些有用的外掛,其中包括prometheus-rancher-exporter,這些外掛將Rancher stack和從Rancher API獲得的主機的健康狀況傳送給Prometheus相容端點。因此,Prometheus對於那些願意花更多精力的管理者來說是最強大的監控解決方案之一。
https://github.com/kubernetes/heapster
Heapster是Kubernetes旗下的一個專案,它有助於實現容器叢集監控和效能分析。此外,Heapster對Kubernetes和OpenShift的支援十分良好,也很適用於在Rancher上使用Kuberenetes作為編排工具的使用者。Cattle或者Swarm的使用者則通常不會選擇它。
人們經常將Heapster定義為一個監控解決方案,但更確切地說,它應該是一個“叢集範圍內的監控和事件資料聚合器”。Heapster從來不單獨部署,相反,它是一堆開源元件的一部分。Heapster監控堆疊通常由以下部分組成:
-
資料收集層:例如,在每個叢集主機上使用kubelet訪問的cAdvisor
-
可插入式儲存後端:例如,ElasticSearch、InfluxDB、Kafka、Graphite等
-
資料視覺化元件:Grafana或Google Cloud Monitoring
Heapster與InfluxDB、Grafana共同組成了一個流行的堆疊,當使用者在Rancher上部署Kubernetes時,此組合便會預設安裝在Rancher上。需要註意的是,這些元件被認為是Kubernetes的附加元件,因此它們可能不會被自動部署到所有Kubernetes發行版中。
InfluxDB受歡迎的其中一個原因是,它是少數幾個支援Kubernetes專案和資料的資料後端之一,並且可以對Kubernetes進行更全面的監控。
值得註意的是,Heapster本身不支援在商用雲的解決方案或Prometheus中發現的與應用程式效能管理(APM)相關的告警或服務。需要監控服務的使用者可以使用Hawkular來彌補這一不足,不過Hawkular並不會自動配置為Rancher部署的一部分,而是需要使用者另行操作。
另一個可用於監視容器環境的開源軟體棧是ELK,由Elastic提供的三個開源專案組成。ELK是通用的,廣泛用於各種分析應用程式,日誌檔案監控是其中關鍵的一環。ELK以其關鍵元件的首字母命名:
-
Elasticsearch:基於Lucene的分散式搜尋引擎
-
Logstash:一個資料處理管道,用於獲取資料並將其傳送到Elastisearch(或其他“託盤”)
-
Kibana:Elasticsearch的視覺化搜尋儀錶板和分析工具
Elastic棧中一個容易被忽視的成員是Beats,專案開發人員將其描述為“輕量級資料託運器”。現在有許多現成的Beats託運器,包括Filebeat(用於日誌檔案)、Metricbeat(用於收集各種來源的資料)以及用於簡單的uptime監控等。
ELK棧的部署方式有所不同。Kiratech的Lorenzo Fontana在這篇文章中[1]解釋瞭如何使用cAdvisor從Docker Swarm主機收集資料以儲存在ElasticSearch中,並使用Kibana進行分析。在另一篇文章中[2],Aboullaite Mohammed描述了一個不同的用例,其重點是收集Docker日誌檔案,分析各種Linux和NGINX日誌檔案(error.log、access.log和syslog)。有些商用ELK棧提供者,例如logz.io和Elastic Co,向用戶提供“ELK即服務”,在原生ELK之外補充提供了告警功能。有關在Docker上使用ELK的更多資訊,請訪問https://elk-docker.readthedocs.io/。
對於希望嘗試使用ELK的Rancher使用者,它在Rancher Catalog中已有條目,《如何在Rancher上執行Elasticsearch[3]》一文介紹瞭如何在Rancher Catalog中部署ELK。《使用容器和Elasticsearch叢集對Twitter進行監控[4]》一文介紹瞭如何使用ELK監控Twitter資料。儘管博洽多聞的管理員可以使用ELK進行容器監控,但與Sysdig、Prometheus或Datadog等直接針對容器監控的解決方案相比,ELK的上手和使用難度都會更大。
Sensu是一個通用的自主監控解決方案,支援多種監控應用。使用者可在MIT許可下獲得一個免費的Sensu Core版本,Sensu的企業版則擁有更多的附加功能,價格為每月99美元,可以為50個Sensu客戶端提供服務。Sensu使用術語“客戶端”來指代其監控代理,因此根據您監控的主機和應用程式環境的數量,企業版可能會變得非常昂貴。Sensu在容器管理之外還擁有非常強大的功能,但就監控容器環境和容器化應用程式這方面來看,它與其他平臺並無差別。
Sensu外掛的數量持續增長,現在已有數十個Sensu和社群支援的外掛可以從各種來源提取資料。2015年Rancher對Sensu進行早期評估時,那時Sensu使用者要從Docker中提取資訊,需要開發shell指令碼。但是現在,Sensu已經有了一個不錯的Docker外掛,這使得Sensu更易於使用了。
外掛往往是用Ruby編寫的,使用基於gem的安裝指令碼,這些指令碼需要在Docker主機上執行。使用者可以在他們選擇的語言中開發額外的外掛。與我們討論過的其他監控解決方案相同的是,Sensu外掛不是部署在自身容器中。(這一點毫無疑問,因為Sensu並非在監控容器的基礎上構建的。)
由於不同的使用者希望根據自己的監控要求混合和匹配外掛,因此為每個外掛設定單獨的容器將會非常棘手,這可能是為什麼不使用容器進行部署的原因。不過,外掛可以使用Chef、Puppet和Ansible等平臺進行部署。例如,對於Docker來說,有6個獨立的外掛可以從各種來源收集與Docker相關的資料,包括Docker統計資訊、容器數量、容器執行狀況、Docker ps等等。Sensu外掛的數量非常多,包括許多使用者可能在容器環境(ElasticSearch、Solr、Redis、MongoDB、RabbitMQ、Graphite和Logstash等)中執行的應用程式棧。此外,Sensu還提供用於管理和編排架構的外掛,如AWS服務(EC2、RDS、ELB)。但是在外掛串列中,Kubernetes似乎消失了。但是Sensu提供對OpenStack和Mesos的支援。
Sensu透過RabbitMQ使用訊息匯流排,以協助代理/客戶端與Sensu伺服器之間的通訊。Sensu用 Redis儲存資料,但它的設計目的是將資料路由到外部的時間序列資料庫。支援的資料庫包括Graphite、Librato和InfluxDB。
安裝和配置Sensu需要花點功夫。安裝Sensu前必須先安裝Redis和RabbitMQ。 Sensu伺服器、Sensu客戶端和Sensu儀錶板需要單獨安裝,並且根據部署的是Sensu核心還是企業版本,流程也會有所不同。如前所述,Sensu不提供容器友好的部署模型。為了方便起見,可以使用Docker映象(hiroakis/Docker-sensu-server)執行redis、rabbitmq-server、uchiwa(開源web層)和Sensu伺服器元件,但在評估上,這個軟體包比生產部署更有用。
Sensu的特性非常多,但對容器使用者而言,它的缺點是架構很難安裝、配置和維護,因為這些元件本身沒有被Docker化。此外,許多告警功能(例如傳送警報給諸如PagerDuty、Slack或HipChat等服務)可以在基於雲的解決方案或像Prometheus這樣的開原始碼解決方案中使用,因此需要購買Sensu企業版許可。特別是若你使用Kubernetes,可能Sensu不是最好的選擇。
Graylog是另一個監控Docker的開源解決方案。和ELK一樣,Graylog也適用於Docker日誌檔案分析。它可以接受和解析來自多個資料源的日誌和事件資料,並支援像Beats、Fluentd和NXLog這樣的第三方收集器。
Nagios通常被認為更適合於監控叢集主機而不是容器,但對於那些在監控叢集環境中浸淫已久的人來說,Nagios最受歡迎。
Netsil是一家矽谷初創公司,作為一個監控應用程式,它為Docker、Kubernetes、Mesos以及各種應用程式和雲提供商提供外掛。Netsil的應用運營中心(AOC)與我們討論的其它監控架構一樣,以雲/SaaS或自主託管的形式為雲應用服務提供架構感知監控。
容器監控解決方案很多,新的解決方案不斷湧現,同時現有的解決方案不斷發展。此次我們採取了high-level的對比方法,希望可以幫助您 “縮小串列”,針對自身需求進行更認真的評估,從而選出最適合的解決方案。
-
https://blog.codeship.com/monitoring-docker-containers-with-elasticsearch-and-cadvisor/
-
https://aboullaite.me/docker-monitoring-with-the-elk-stack/
-
http://rancher.com/deploying-an-elasticsearch-cluster-using-rancher-catalog/
-
http://rancher.com/using-containers-elasticsearch-cluster-twitter-monitoring/
本次培訓內容包括:Docker容器的原理與基本操作;容器網路與儲存解析;Kubernetes的架構與設計理念詳解;Kubernetes的資源物件使用說明;Kubernetes 中的開放介面CRI、CNI、CSI解析;Kubernetes監控、網路、日誌管理;容器應用的開發流程詳解等,點選識別下方二維碼加微信好友瞭解具體培訓內容。

長按二維碼向我轉賬

受蘋果公司新規定影響,微信 iOS 版的贊賞功能被關閉,可透過二維碼轉賬支援公眾號。