
學Python最簡單的方法是什麼?推薦閱讀:30萬年薪Python開發工程師成長魔法
用 Python 做到每秒處理上百萬次 HTTP 請求,可能嗎?也許不能,但直到最近,這已成為現實。
很多公司都在為了提升程式的執行效能和降低伺服器的運營成本,而放棄 Python 去選擇其它程式語言,其實這樣做並不是必須,因為 Python 完全可以勝任這些任務。
Python 社群最近做了大量關於效能的最佳化。CPython 3.6 重寫了新的字典從而全面提升解析器的執行效能。由於引入更快的呼叫規則和字典查詢快取,CPython 3.7 甚至還要更快。
我們可以用 PyPy 的 Just-in-Time 來編譯複雜的科學計算任務,NumPy 的測試套件也優化了和 C 擴充套件的相容性,同時 PyPy 還計劃於今年晚些時候做到和 Python 3.5 保持一致。
這些振奮人心的變化激勵著我想要有所創新,Python 所擅長的領域眾多,我選擇了其中一個:Web 和 MicroServices 開發。
瞭解 Japronto!
Japronto 是一個全新的,為微服務量身打造的微框架。實現它的主要標的包含夠快、可擴充套件和輕量化。的確它快的嚇人,甚至遠比 NodeJS 和 Go 還要快的多的多。要感謝 asyncio,讓我可以同時編寫同步和非同步程式碼。
Python 的微框架(藍色)、NodeJS 和 Go (綠色) 和 Japronto (紫色)
勘誤表:使用者 @heppu 提到,如果謹慎點用 Go 的 stdlib HTTP 伺服器可以寫出比上圖的 Go 快 12% 的程式碼。另外 fasthttp 也是一個非常棒的 Go 伺服器,同樣的測試中它的效能幾乎只比 Japronto 低 18%。真是太棒了!更多細節查可以看 https://github.com/squeaky-pl/japronto/pull/12 和 https://github.com/squeaky-pl/japronto/pull/14
我們可以看到其實 Meinheld WSGI 伺服器已經和 NodeJS 和 Go 的效能差不多了。儘管它用的是阻塞式設計,但還是要比前面那四個要快的多,前面四個用的是非同步的 Python 解決方案。所以,不要輕易相信別人那些關於非同步系統總是比同步系統更快的說法,雖然都是併發處理的問題,但事實遠不如想象的那麼簡單。
雖然我只是用 “Hello World” 來完成上面這個關於微框架的測試,但它清晰的展現了各種伺服器框架的處理能力。
這些測試是在一臺亞馬遜 AWS EC2 的 c4.2xlarge 實體上完成的,它有 8 VCPUs,資料中心選在聖保羅區域,共享主機、HVM 虛擬化、普通磁碟。作業系統是 Ubuntu 16.04.1 LTS (Xenial Xerus),核心為 Linux 4.4.0–53-generic x86_64。作業系統顯示的 CPU 是 Xeon® E5–2666 v3 @ 2.90GHz。Python 我用的版本是 3.6,剛從原始碼編譯來的。
公平起見,所有程式,包括 Go,都只執行在單個處理器核心上。測試工具為 wrk,引數是 1 個執行緒,100 個連結和每個連結 24 個請求(累計併發 2400 次請求)。

HTTP 流水線(圖片來自 Wikipedia)
HTTP 流水線在這裡起著決定性的因素,因為 Japronto 用它來做執行併發請求的最佳化。
大多數伺服器把來自客戶端的流水線和非流水線請求都一視同仁,用同樣的方法處理,並沒有做針對性的最佳化。(實際上 Sanic 和 Meinheld 也是默默的把流水線請求當做非流水線來處理,這違反了 HTTP 1.1 協議)
簡單來說,透過流水線技術,客戶端不用等到伺服器端傳回,就可以在同一條 TCP 連結上繼續傳送後續的請求。為了保障通訊的完整性,伺服器端會按照請求的順序逐個把結果傳回給客戶端。
細節最佳化過程
當一堆小的 GET 請求被客戶端以流水線打包傳送過來,伺服器端很可能只需要一次系統呼叫,讀取一個 TCP 資料包就能拿到全部的請求。
系統呼叫,以及在核心空間到使用者空間之間行動資料,相比起在行程內部行動資料,成本要高的多。這就是為什麼不到萬不得已,要盡可能少做系統呼叫的次數。
當 Japronto 收到資料併成功解析出請求序列時,它會嘗試盡可能快的把這些請求執行完成,並以正確的順序合併所有結果,然後只執行一次系統呼叫傳送資料給客戶端。實際上因為有 scatter/gather IO 這樣的系統呼叫,合併的工作並不需要自己去完成,只不過 Japronto 暫時還沒有用到這些功能。
然而事情並不總是那麼完美,有時候請求需要耗費很長時間去處理,等待完成的過程增加了不必要的延遲。
當我們做最佳化時,有必要考慮系統呼叫的成本和請求的預期完成時間。
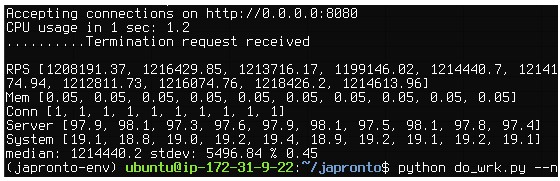
經過最佳化 Japronto 拿到了 1,214,440 RPS 的成績
除了利用客戶端流水線請求,和最佳化呼叫,還有一些其它可用的技術。
Japronto 幾乎都是用 C 寫的。包含解析器、協議、連結管理、路由、請求、應答等物件都是用 C 擴充套件寫的。
Japronto 力圖做到 Python 的懶載入,比如,協議頭的字典只有在被試圖請求到時才會被建立,另外一系列的物件也只有在第一次使用時才會被建立。
Japronto 使用超牛逼的 picohttpparser C 庫來解析狀態、協議頭以及分片的 HTTP 訊息體。Picohttpparser 是直接呼叫現代 CPU 整合的 SSE4.2 擴充套件文字處理指令去快速匹配 HTTP 標記的邊界(那些 10 年前的老 x86_64 CPU 都有這玩意兒)。I/O 用到了超棒的 uvloop,它是一個 libuv 的封裝,在最底層,它是呼叫 epoll 來提供非同步讀寫通知。

Picohttpparser 依賴 SSE4.2 和 CMPESTRI x86_64 的特性做解析
Python 是有垃圾收集功能的語言,為避免不必要的增加垃圾收集器的壓力,在設計高效能系統時一定要多加註意。Japronto 的內部被設計的嘗試避免迴圈取用和盡可能少的分配、釋放記憶體,它會預先申請一塊區域來存放物件各種,同時嘗試在後續請求中重用那些沒有被繼續取用的 Python 的物件,而不是將那些物件直接扔掉。
這些預先申請的記憶體的大小被固定為 4KB 的倍數。內部結構會非常小心和頻繁的使用這些連續的記憶體區域,以減少快取失效的可能性。
Japronto 會盡可能避免不必要的快取間複製,只在正確的位置執行操作。比如,在處理路由時,先做 URL 解碼再進行路由匹配。
開源貢獻者們,我需要你們的幫助
我已經連續不斷的開發 Japronto 超過三個月,不光在每一個工作日,週末也無休。除了每天的工作外,我把所有時間精力都投入到這個專案上了。
我想是時候和社群分享我的勞動果實了。
Japronto 已經可靠的實現了下麵這些功能:
-
實現 HTTP 1.x 並且支援分片上傳
-
完整支援 HTTP 流水線
-
可配置是否讓連結 Keep-alive
-
支援同步和非同步檢視
-
Master-multiworker 多工處理
-
程式碼熱載入
-
簡單易用的路由規則
下一次,我將深入研究關於 Websockets 和 HTTP 非同步應答資料流。
寫檔案和做測試還有許多工作要做,如果你有興趣加入我,請在 Twitter 上直接聯絡我. 這裡是 Japronto 的 GitHub 專案倉庫.
同時,如果你的公司正在尋找熟悉效能最佳化和 DevOps 的 Python 工程師,我很樂意為你效勞,在全球任何地方都可以。
結束語
上面提到的所有技術不只適用於 Python,也同樣可以被應用到其它語言,如 Ruby、JavaScript,甚至 PHP 等。我非常感興趣去付諸實踐,但是,除非有人能在這事上投入資金支援,恐怕我沒有足夠的精力去完成。
在此我要感謝 Python 社群為最佳化效能所付出的持續投入。尤其是 Victor Stinner @VictorStinner、INADA Naoki @methane 和 Yury Selivanov @1st1 以及整個 PyPy 團隊。
獻給我摯愛的 Python。
本文作者: Victor
本文地址:http://www.iteye.com/news/32363


更多Python好文請點選【閱讀原文】哦
↓↓↓
