(點選上方公眾號,可快速關註)
來源:naughty,
my.oschina.net/taogang/blog/983586
本文就架構,功能,產品線,概念等方面就ElasticSearch和Splunk做了一下全方位的對比,希望能夠大家在制定大資料搜尋方案的時候有所幫助。
簡介
ElasticSearch (1)(2)是一個基於Lucene的開源搜尋服務。它提供了一個分散式多使用者能力的全文搜尋引擎,基於RESTful web介面。Elasticsearch是用Java開發的,並作為Apache許可條款下的開放原始碼釋出,是當前流行的企業級搜尋引擎。設計用於雲端計算中,能夠達到實時搜尋,穩定,可靠,快速,安裝使用方便。
ELK是ElasticSearch,Logstash,Kibana的縮寫,分別提供搜尋,資料接入和視覺化功能,構成了Elastic的應用棧。
Splunk 是大資料領域第一家在納斯達克上市公司,Splunk提供一個機器資料的引擎。使用 Splunk 可收集、索引和利用所有應用程式、伺服器和裝置(物理、虛擬和雲中)生成的快速移動型計算機資料 。從一個位置搜尋並分析所有實時和歷史資料。 使用 Splunk 處理計算機資料,可讓您在幾分鐘內(而不是幾個小時或幾天)解決問題和調查安全事件。監視您的端對端基礎結構,避免服務效能降低或中斷。以較低成本滿足合規性要求。關聯並分析跨越多個系統的複雜事件。獲取新層次的運營可見性以及 IT 和業務智慧。
根據最新的資料庫引擎排名顯示,Elastic,Solr和Splunk分別佔據了資料庫搜尋引擎的前三位。

從趨勢上來看,Elastic和Splunk上升明顯,Elastic更是表現出了非常強勁的勢頭。

基本概念
Elastic
-
準實時(NRT)
Elasticsearch是一個準實時性的搜尋平臺,從資料索引到資料可以被搜尋存在一定的時延。
-
索引(Index)
索引是有共同特性的檔案的集合,索引有自己的名字,可以對索引執行搜尋,更新,刪除等操作。
-
型別(Type)
每個索引可以包含一個或者多個型別,型別可以看作一個索引資料的邏輯分組,通常我們會把擁有相同欄位的檔案定義為同一個型別。
-
檔案(Document)
檔案是索引資訊的基本單元。Elastic中檔案表現為JSON物件,檔案物理存貯在索引中,並需要被制定一個型別。因為表現為JSON, 很自然的,檔案是由一個個的欄位(Feilds)組成,每個欄位是一個名值對(Name Value Pair)
-
評分(score)
Elastic是基於Lucene構建的,所以搜尋的結果會有一個打分。來評價搜尋結果和查詢的相關性。
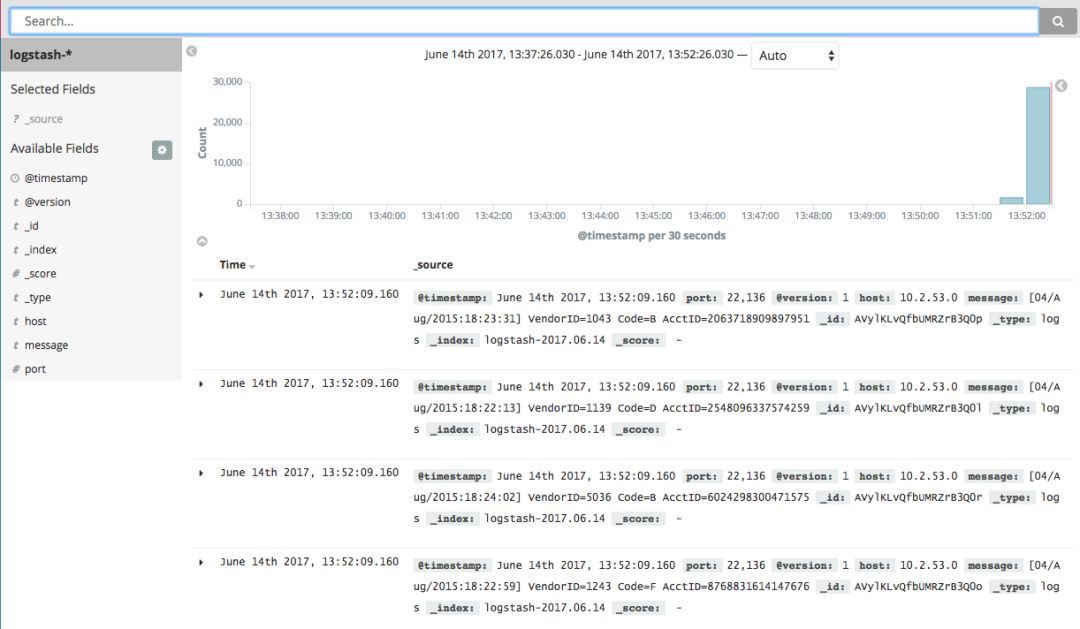
下圖是一個Elastic的搜尋在Kibana中看到的例子,原始的資料是一個簡單的日誌檔案:

我們透過logstash索引到Elasticsearch後,就可以搜尋了。
Splunk
-
實時性
Splunk同樣是準實時的,Splunk的實時搜尋(Realtime Search)可以提供不間斷的搜尋結果的資料流。
-
事件(Event)
對應於Elastic的檔案,Splunk的資料索引的基本單元是事件,每一個事件包含了一組值,欄位,時間戳。Splunk的事件可以是一段文字,一個配置檔案,一段日誌或者JSON物件。
-
欄位(Fields)
欄位是可以被搜尋的名值對,不同的事件可能擁有不同的欄位。Splunk支援索引時(index time)和搜尋時(search time)的欄位抽取(fields extraction)
-
索引(Indexes)
類似Elastic的索引,所有的事件物理儲存在索引上,可以把索引理解為一個資料庫的表。
-
知識物件(Knowledge Object)
Splunk的知識物件提供對資料進一步的解釋,分類,增強等功能,包括:欄位(fields),欄位抽取(fields extraction),事件型別(event type),事務(transaction),查詢(lookups),標簽(tags),別名(aliases),資料模型(data model)等等。
下圖是一個Splunk的搜尋在Splunk客戶端看到的和前一個例子同樣的日誌資料的搜尋結果。
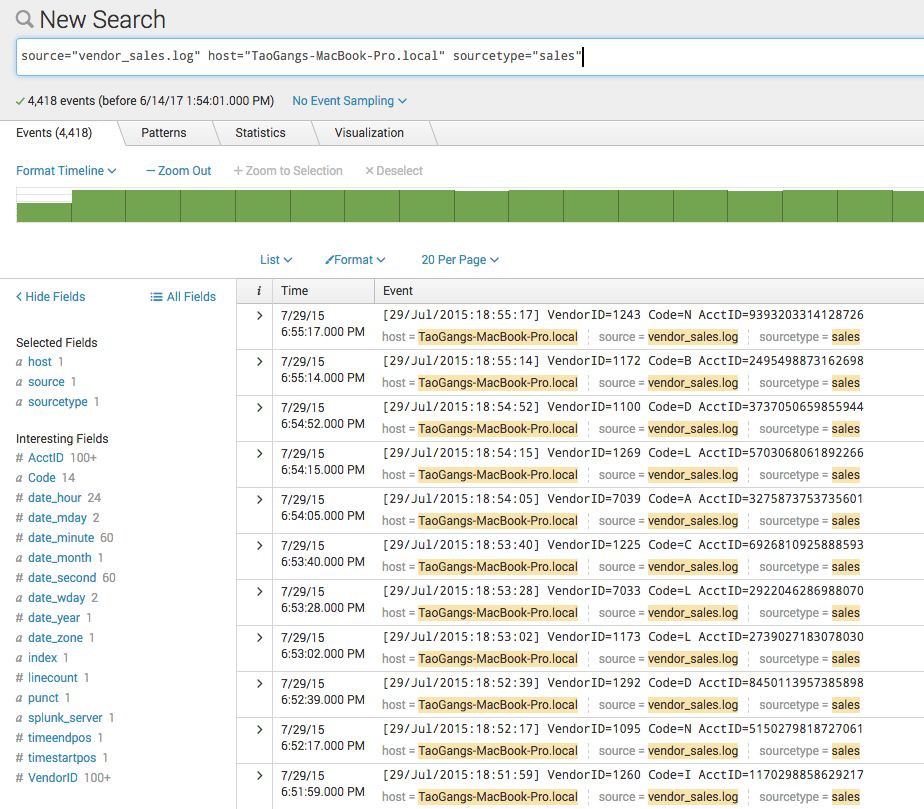
從基本概念上來看,Elasticsearch和Splunk基本一致。從例子中我們可以看到很多的共性,事件/檔案,時間戳,欄位,搜尋,時間軸圖等等。其中有幾個主要的差別:
-
Elastic不支援搜尋時的欄位抽取,也就是說Elastic的檔案中的所有欄位在索引時已經固定了,而Splunk支援在搜尋時,動態的抽取新的欄位
-
Elastic的搜尋是基於評分機制的,搜尋的結果有一個打分,而Splunk沒有對搜尋結果評分
-
Splunk的知識物件可以提供對資料更高階,更靈活的管理能力。
使用者介面
ElasticSearch提供REST API來進行
-
叢集的管理,監控,健康檢查
-
索引的管理(CURD)
-
搜尋的執行,包括排序,分頁,過濾,指令碼,聚合等等高階的搜尋功能。
Elasticsearch 本身並沒有提供任何UI的功能,搜尋可以用Kibana,但是沒有管理UI還是讓人不爽的,好在開源的好處就是會有很多的開發者來構建缺失的功能:
-
ElasticHQ
-
cerebro (推薦,介面乾凈,我喜歡)
-
dejavu
另一選擇就是安裝X-Pack,這個是要收費的。
Splunk作為企業軟體,管理及訪問介面比較豐富,除了REST API 和命令列介面,Splunk的UI非常友好易用,基本上所有的功能都能透過整合的UI來使用。同時提供以下介面
-
REST API
-
Splunk UI
-
CLI
功能
資料接入和獲取
Elastic棧使用Logstash和Beats來進行資料的消化和獲取。
Logstash用jruby實現,有點像一個資料管道,把輸入的資料進行處理,變形,過濾,然後輸出到其它地方。Logstash 設計了自己的 DSL,包括有區域,註釋,資料型別(布林值,字串,數值,陣列,雜湊),條件判斷,欄位取用等。
Logstash的資料管道包含三個步驟,Input,Filter和Output,每一步都可以透過plugin來擴充套件。另外Input和Output還支援配置Codecs,完成對輸入輸出資料的編解碼工作。

Logstash支援的常見的Input包含File,syslog,beats等。Filter中主要完成資料的變形處理,可以增刪改欄位,加標簽,等等。作為一個開源軟體,Output不僅僅支援ElasticSearch,還可以和許多其它軟體整合和標的,Output可以是檔案,graphite,資料庫,Nagios,S3,Hadoop等。
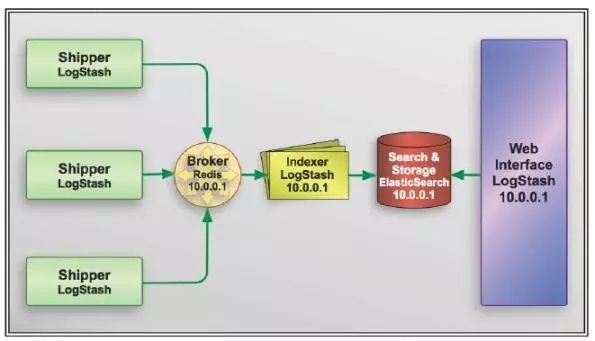
在實際運用中,logstash 行程會被分為兩個不同的角色。執行在應用伺服器上的,儘量減輕執行壓力,只做讀取和轉發,這個角色叫做 shipper;執行在獨立伺服器上,完成資料解析處理,負責寫入 Elasticsearch 的角色,叫 indexer。
logstash 作為無狀態的軟體,配合訊息佇列系統,可以很輕鬆的做到線性擴充套件
Beats是 Elastic 從 packetbeat 發展出來的資料收集器系統。beat 收集器可以直接寫入 Elasticsearch,也可以傳輸給 Logstash。其中抽象出來的 libbeat,提供了統一的資料傳送方法,輸入配置解析,日誌記錄框架等功能。

開源社群已經貢獻了許多的beats種類。
因為Beats是使用Golang編寫的,效率上很不錯。
Splunk使用Farwarder和Add-ons來進行資料的消化和獲取。
Splunk內建了對檔案,syslog,網路埠等input的處理。當配置某個節點為Forwarder的時候,Splunk Forwarder可以作為一個資料通道把資料傳送到配置好的indexer去。這時候,它就類似logstash。這裡一個主要的區別就是對資料欄位的抽取,Elastic必須在logstash中透過filter配置或者擴充套件來做,也就是我們所說的Index time抽取,抽取後不能改變。Splunk支援Index time的抽取,但是更多時候,Splunk 在index time並不抽取而是等到搜尋是在決定如何抽取欄位。
對於特定領域的資料獲取,Splunk是用Add-on的形式。Splunk 的App市場上有超過600個不同種類的Add-on。

使用者可以透過特定的Add-on或者自己開發Add-on來獲取特定的資料。
對於大資料的資料採集,大家也可以參考我的另一篇部落格。
https://my.oschina.net/taogang/blog/524385
資料管理和儲存
ElasticSearch的資料存貯模型來自於Lucene,基本原理是實用了倒排表。大家可以參考這篇文章。
http://www.infoq.com/cn/articles/analysis-of-elasticsearch-cluster-part01
Splunk的核心同樣是倒排表,推薦大家看這篇去年Splunk Conf上的介紹,Behind the Magnifying Glass: How Search Works
https://conf.splunk.com/files/2016/slides/behind-the-magnifying-glass-how-search-works.pdf

Splunk的Event存在許多Buckets中,多個Buckets構成邏輯分組的索引分佈在Indexer上。

每個Bucket中都是倒排表的結構儲存資料,原始資料透過gzip壓縮。

搜尋時,利用Bloom filter定位資料所在的bucket。
在對資料的儲存管理上,Elastic 和Splunk都是利用了倒排表。Splunk對資料進行壓縮,所以儲存空間的佔用要少很多,尤其考慮到大部分資料是文字,壓縮比很高的,當然這會損失一部分效能用於資料的解壓。
資料分析和處理
對資料的處理分析,ElasticSearch主要使用 Search API來實現。而Splunk則提供了非常強大的SPL,相比起ES的Search API,Splunk的SPL要好用很多,可以說SPL就是非結構化資料的SQL。無論是利用SPL來開發分析應用,還是直接在Splunk UI上用SPL來處理資料,SPL都非常易用。開源社群也在試圖為Elastic增加類似SPL的DSL來改善資料處理的易用性。例如:
https://github.com/chenryn/ESPL
從這篇反饋可以看出,ES的search還有許多的不足。
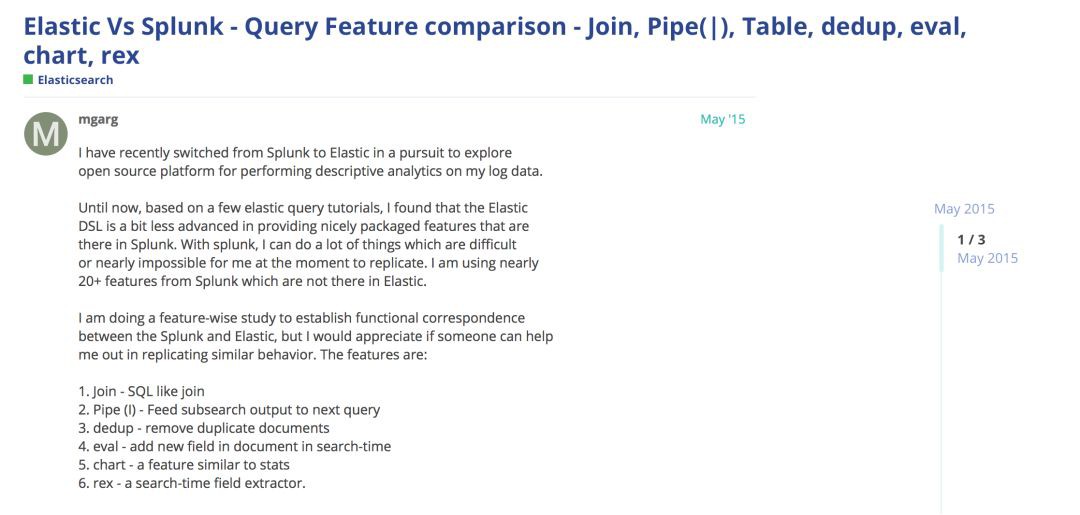
作為對此的響應,Elastic推出了painless script,該功能還處於實驗階段。
資料展現和視覺化
Kibana是一個針對Elasticsearch的開源分析及視覺化平臺,用來搜尋、檢視互動儲存在Elasticsearch索引中的資料。使用Kibana,可以透過各種圖表進行高階資料分析及展示。

Splunk集成了非常方便的資料視覺化和儀錶盤功能,對於SPL的結果,可以非常方便的透過UI的簡單設定進行視覺化的分析,匯出到儀錶盤。

下圖的比較來自https://www.itcentralstation.com/products/comparisons/kibana_vs_splunk
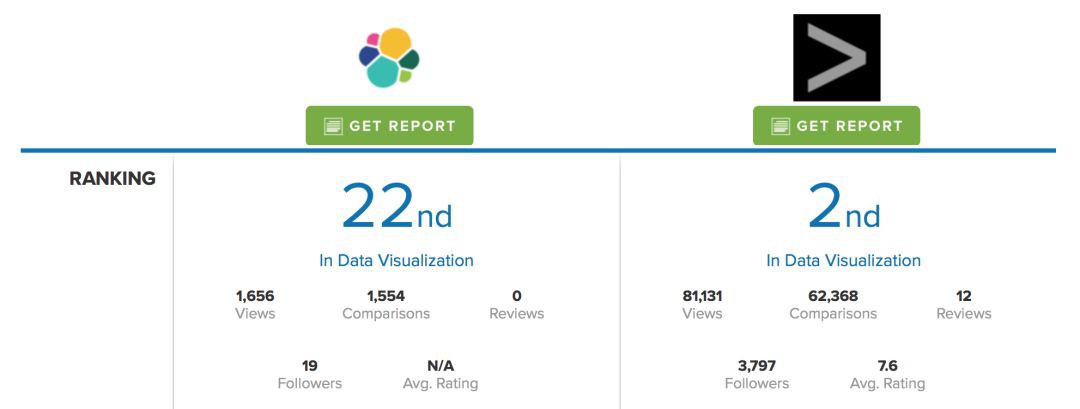
在資料視覺化的領域的排名,Splunk僅僅落後於Tableau而已

擴充套件性
從擴充套件性的角度來看,兩個平臺都擁有非常好的擴充套件性。
Elastic棧作為一個開源棧,很容易透過Plugin的方式擴充套件。包括:
-
ElasticSearch Plugin
-
Kibana Plugin
-
Logstash Plugin
-
Beats Platform
Splunk提供一系列的擴充套件點支援應用和Add-on的開發, 在http://dev.splunk.com/可以找到更多的資訊和檔案。包括:
-
Web Framework
-
SDK
-
Modular Input
-
… …
比起Elastic的Plugin,Splunk的擴充套件概念上比較複雜,開發一個App或者Add-on的門檻都要相對高一些。做為一個資料平臺,Splunk應該在擴充套件性上有所改進,使得擴充套件變的更為容易和簡單。
架構
Elastic Stack
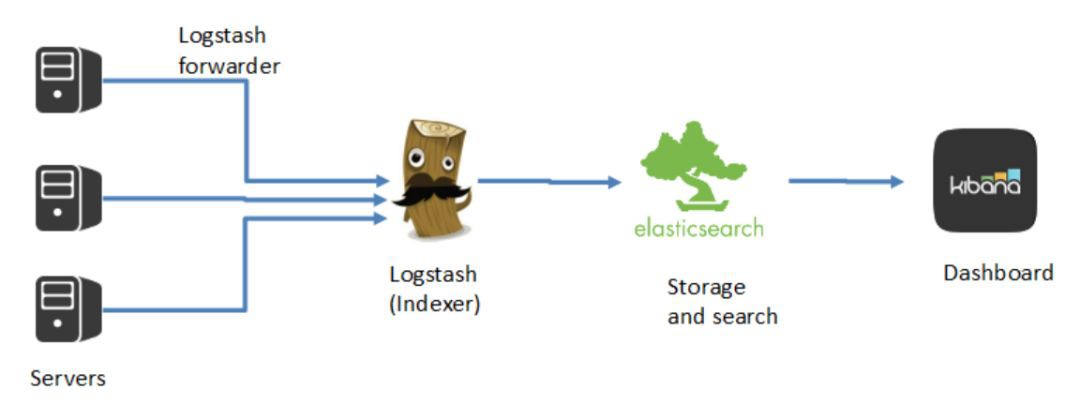
如上圖所示,ELK是一套棧,Logstash提供資料的消化和獲取,Elasticsearch對資料進行儲存,索引和搜尋,而Kibana提供資料視覺化和報表的功能。
Splunk

Splunk的架構主要有三個角色:
-
Indexer
Indexer提供資料的儲存,索引,類似Elasticsearch的作用
-
Search Head
Search Head負責搜素,客戶接入,從功能上看,一部分是Kibana,因為Splunk的UI是執行在Search Head上的,提供所有的客戶端和視覺化的功能,還有一部分,是提供分散式的搜尋功能,包含對搜尋的分發到Indexer和搜尋結果的合併,這一部分功能對應在Elasticsearch上。
-
Forwarder
Splunk的Forwarder負責資料接入,類似Logstash
除了以上的三個主要的角色,Splunk的架構中還有:Deployment Server,License Server,Master Cluster Node,Deployer等。
Splunk和ELK的基本架構非常類似,但是ELK的架構更為簡單和清楚,Logstash負責資料接入,Kibana負責資料展現,所有的複雜性在Elasticsearch中。Splunk的架構更為複雜一些,角色的型別也更多一些。
如果裝單機版本,Splunk更容易,因為所有的功能一次性就裝好了,而ELK則必須分別安裝E/L/K,從這一點上來看,Splunk有一定的優勢。
分佈叢集和擴充套件性
ElasticSearch

ElasticSearch是為分散式設計的,有很好的擴充套件性,在一個典型的分散式配置中,每一個節點(node)可以配製成不同的角色,如上圖所示:
-
Client Node,負責API和資料的訪問的節點,不儲存/處理資料
-
Data Node,負責資料的儲存和索引
-
Master Node, 管理節點,負責Cluster中的節點的協調,不儲存資料。
每一種角色可以透過ElasticSearch的配置檔案或者環境變數來配置。每一種角色都可以很方便的Scale,因為Elastic採用了對等性的設計,也就是所有的角色是平等的,(Master Node會進行Leader Election,其中有一個是領導者)這樣的設計使得在叢集環境的伸縮性非常好,尤其是在容器環境,例如Docker Swarm或者Kubernetes中使用。
參考:
-
https://elk-docker.readthedocs.io/#elasticsearch-cluster
-
https://github.com/pires/kubernetes-elasticsearch-cluster
Splunk
Splunk作為企業級的分散式機器資料的平臺,擁有強大的分散式配置,包括跨資料中心的叢集配置。Splunk提供兩種叢集,Indexer叢集和Search Head叢集。
Splunk Indexer叢集
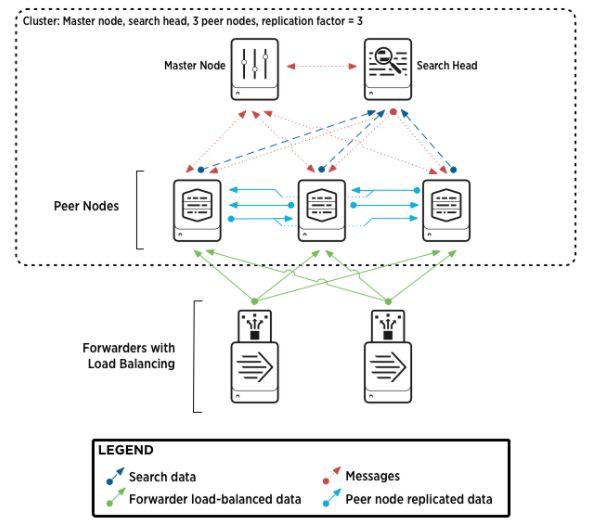
如上圖所示,Splunk的indexer叢集主要由三種角色:
-
Master Node,Master Node負責管理和協調整個的叢集,類似ES的Master。但是隻有一個節點,不支援多Master(最新版本6.6)。Master Node負責
-
協調Peer Node之間的資料複製
-
告訴Search Head資料在哪裡
-
Peer Node的配置管理
-
Peer Node故障時的故障恢復
-
Peer Nodes,負責資料索引,類似ES的Data Node,Peer Node負責
-
儲存索引資料
-
傳送/接收複製資料到其他Peer節點
-
響應搜尋請求
-
Search Head,負責資料的搜尋和客戶端API訪問,類似ES的Client Node,但不完全相同。Search Head負責傳送搜尋請求到Peer Nodes,並對搜尋的結果進行合併。
有人會問,那Master是不是叢集中的單點故障?What if Master node goes down?Splunk的回答是否。即使Master 節點出現故障,Peer Nodes仍然可以正常工作,除非,同時有Peer Node出現故障。
-
http://docs.splunk.com/Documentation/Splunk/6.6.1/Indexer/Whathappenswhenamasternodegoesdown
-
https://answers.splunk.com/answers/129446/why-does-master-node-continue-to-be-single-point-of-failure-in-clustering.html
Splunk Search Header 叢集
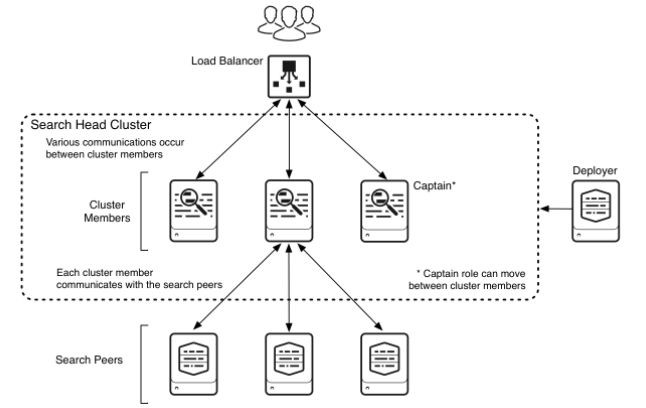
Search Head叢集是由一組Search Head組成,它們共享配置,搜尋任務等狀態。該Cluster主要有以下角色:
-
Deployer, 負責分髮狀態和應用到peers
-
Cluster Member,其中有一個是Captain,負責協調。Cluster Memeber之間會互相通訊,來保證狀態一致。Load Balancer是個可選項,可以負責Search的接入。
-
Search Peers,負責資料索引的 Indexer Nodes
另外Splunk還曾經提供過一個功能叫做Search Head Pooling,不過現在已經Depecated了。
Indexer叢集可以和Search Head叢集一起配置,構成一個分散式的Splunk配置。
相比較ES的相對比較簡單的叢集配置,Splunk的叢集配置比較複雜,ES中所有每一個節點可以靈活的配置角色,並且可以相對比較容易的擴充套件,利用例如Kubernetes的Pod的複製可以很容易的擴充套件每一個角色。擴充套件Splunk相對比較困難,要做到動態的伸縮,需要比較複雜的配置。大家可以參考這裡,在容器環境裡配置一個Splunk的叢集需要比較多的佈置,例如在這個Master的配置中,使用者需要考慮:
-
如何配置License
-
修改預設的使用者名稱口令
-
為每一個Search Head配置Search Head Cluster
-
等待Splunk行程成功啟動
-
配置業務發現
-
安裝應用
-
… …
https://github.com/outcoldman/docker-splunk-cluster
並且叢集的擴充套件很難直接利用容器編排平臺提供的擴充套件介面,這一點Splunk還有很多提高的空間。
產品線
Elastic
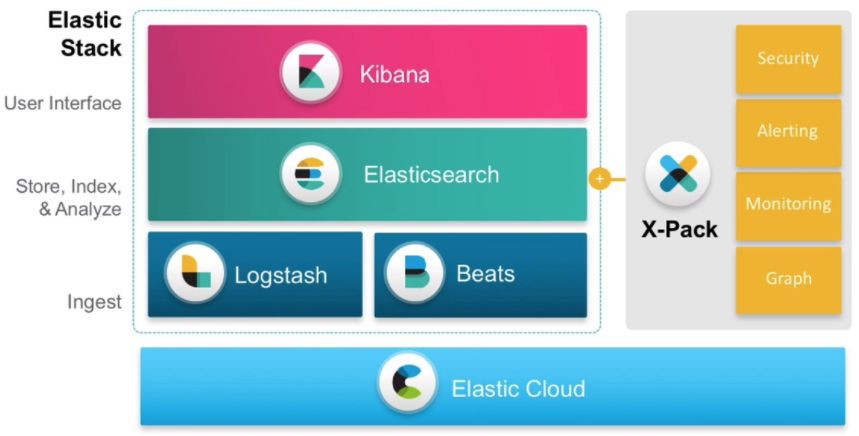
Elastic的產品線除了大家熟悉的ELK(ElasticSearch,Logstash,Kikana),主要包含
-
Beats Beats是一個開源元件,提供一個代理,把本地抓到的資料傳送到ElasticSearch
-
Elastic Cloud, Elasti提供的雲服務
-
X-Pack, Elastic的擴充套件元件,提供安全,告警,監控,機器學習和圖處理能力。主要功能需要付費使用。
Splunk

Splunk的產品線包括
-
Splunk Enterprise
-
Splunk Cloud, Splunk運營的雲服務,跑在AWS上
-
Splunk Light,Splunk Light版本,功能有所精簡,面向中小企業
-
Hunk, Splunk on Hadoop
-
Apps / Add-ons, Splunk提供大量的應用和資料獲取的擴充套件,可以參考 http://apps.splunk.com/
-
Splunk ITSI (IT Service Intelligence), Splunk為IT運維專門開發的產品
-
Splunk ES (Enterprise Security), Splunk為企業安全開發的產品,這個是Splunk 公司的拳頭產品,連續被Gartner評為SIEM領域的領導者,挑戰了該行業的傳統巨鱷IBM,HP
-
Splunk UBA (User Behavior Analytic), UBA是Splunk在15年收購的Caspidia帶來的基於機器學習的安全產品。
從產品線的角度來看,Splunk除了提供基本平臺,在IT運維和安全領域都有自己的拳頭產品。Elastic缺乏某個領域的應用。
價格
價格是大家非常關心的一個因素
Elastic的基本元件都是開源的,參看下錶,X-pack中的一些高階功能需要付費使用。包含安全,多叢集,報表,監控等等。

雲服務的價格參考下圖,ES的雲是按照所使用的資源來收費,從這裡選取的區域可以看出,ES的雲也是執行在AWS上的。下圖中的配置每月需要花費200美元左右。(不同區域的收費不同)

同時,除了Elastic自己,還有許多其他公司也提供Elastic Search的雲服務,例如Bonsai,Qbox.io等。
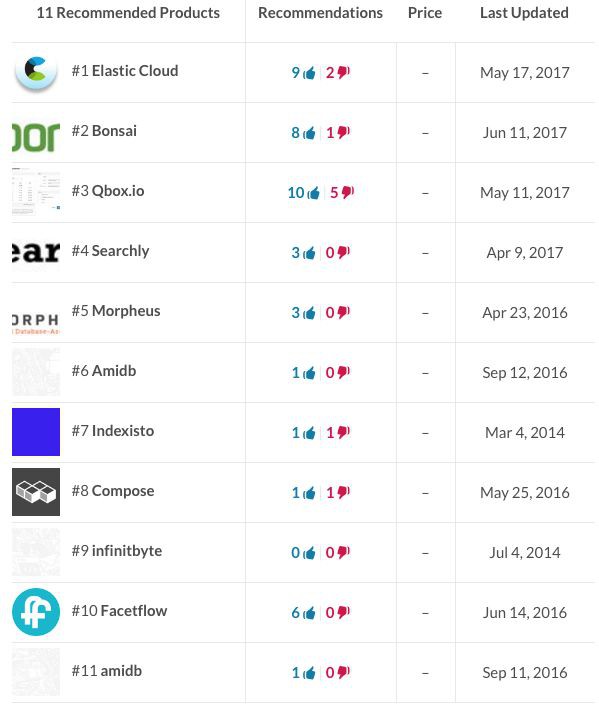
Splunk
Splunk Enterprise是按照資料每日的流量按年或者無限制事件付費,每天1GB的話,每年是2700美元,每個月也是差不多200塊。如果每天的資料量少於500M,可以使用Splunk提供的免費License,只是不能用安全,分散式等高階功能,500M可以做很多事情了。

雲服務的價格就要便宜多了,每天5GB,每年只要2430元,每個月不到200塊。當然因為計費的方式不同,和Elastic的雲就不好比較了。另外因為是在AWS上,中國的使用者,呵呵了。

總結
大資料的搜尋平臺已經成為了眾多企業的標配,Elastic棧和Splunk是其中最為優秀和流行的選擇。兩者都有各自的優點和值得改進的地方。希望本文能夠在你的大資料平臺的選型上,有所幫助。也希望大家來和我交流,共同成長。
參考檔案
ELK
-
ElasticSearch 參考檔案
https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html
-
Github上收集的ElasticSearch相關開源軟體串列
https://github.com/dzharii/awesome-elasticsearch
-
知乎ElaticSearch專題
https://www.zhihu.com/topic/19899427/hot
-
中文書
https://github.com/chenryn/ELKstack-guide-cn
-
中文書
https://www.gitbook.com/book/wizardforcel/mastering-elasticsearch/details
Splunk
-
Splunk 檔案
https://docs.splunk.com/Documentation
-
Splunk電子書
https://www.splunk.com/web_assets/v5/book/Exploring_Splunk.pdf
-
Splunk 開發檔案
http://dev.splunk.com/getstarted
-
Splunk 應用市場
http://apps.splunk.com/
-
Splunk 快速參考
https://www.splunk.com/content/dam/splunk2/pdfs/solution-guides/splunk-quick-reference-guide.pdf
其它
-
https://www.upguard.com/articles/splunk-vs-elk
-
https://db-engines.com/en/system/Elasticsearch%3BSplunk
-
https://www.searchtechnologies.com/blog/log-analytics-tools-open-source-vs-commercial
-
http://www.learnsplunk.com/splunk-vs-elk-stack.html
-
https://www.slideshare.net/hepterida/splunk-vs-elk
-
http://blog.takipi.com/log-management-tools-face-off-splunk-vs-logstash-vs-sumo-logic/
-
http://blog.takipi.com/splunk-vs-elk-the-log-management-tools-decision-making-guide/
-
https://www.edureka.co/blog/splunk-vs-elk-vs-sumologic
-
https://www.youtube.com/watch?v=ElMZqeogc3w (請自行翻牆)
看完本文有收穫?請轉發分享給更多人
關註「ImportNew」,提升Java技能

