
近日,有位粉絲向我請教,在爬取某網站時,網頁的原始碼出現了中文亂碼問題。之前關於爬蟲亂碼有很多粉絲的各式各樣的問題,今天與大家一起總結下關於網路爬蟲的亂碼處理。註意,這裡不僅是中文亂碼,還包括一些如日文、韓文 、俄文、藏文之類的亂碼處理,因為他們的解決方式 是一致的,故在此統一說明。
一、亂碼問題的出現
就以爬取51job網站舉例,講講為何會出現“亂碼”問題,如何解決它以及其背後的機制。
程式碼示例:
import requests
url = "http://search.51job.com"
res = requests.get(url)
print(res.text)
顯示結果:
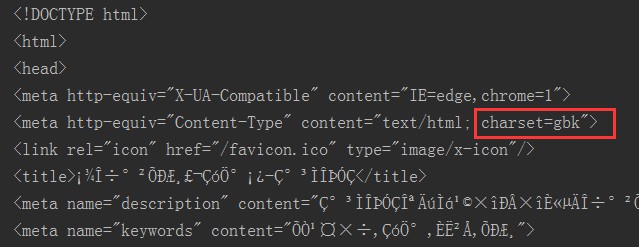
列印res.text時,發現了什麼?中文亂碼!!!不過發現,網頁的字符集型別採用的gbk編碼格式。
我們知道Requests 會基於 HTTP 頭部對響應的編碼作出有根據的推測。當你訪問 r.text 之時,Requests 會使用其推測的文字編碼。你可以找出 Requests 使用了什麼編碼,並且能夠使用r.encoding 屬性來改變它。
接下來,我們一起透過resquests的一些用法,來看看Requests 會基於 HTTP 頭部對響應的編碼方式。
print(res.encoding) #檢視網頁傳回的字符集型別
print(res.apparent_encoding) #自動判斷字符集型別
輸出結果為:

可以發現Requests 推測的文字編碼(也就是網頁傳回即爬取下來後的編碼轉換)與源網頁編碼不一致,由此可知其正是導致亂碼原因。
二、亂碼背後的奧秘
當源網頁編碼和爬取下來後的編碼轉換不一致時,如源網頁為gbk編碼的位元組流,而我們抓取下後程式直接使用utf-8進行編碼並輸出到儲存檔案中,這必然會引起亂碼,即當源網頁編碼和抓取下來後程式直接使用處理編碼一致時,則不會出現亂碼,此時再進行統一的字元編碼也就不會出現亂碼了。最終爬取的所有網頁無論何種編碼格式,都轉化為utf-8格式進行儲存。
註意:區分源網編碼A-gbk、程式直接使用的編碼B-ISO-8859-1、統一轉換字元的編碼C-utf-8。
在此,我們拓展講講unicode、ISO-8859-1、gbk2312、gbk、utf-8等之間的區別聯絡,大概如下:
最早的編碼是iso8859-1,和ascii編碼相似。但為了方便表示各種各樣的語言,逐漸出現了很多標準編碼。iso8859-1屬於單位元組編碼,最多能表示的字元範圍是0-255,應用於英文系列。很明顯,iso8859-1編碼表示的字元範圍很窄,無法表示中文字元。
1981年中國人民透過對 ASCII 編碼的中文擴充改造,產生了 GB2312 編碼,可以表示6000多個常用漢字。但漢字實在是太多了,包括繁體和各種字元,於是產生了 GBK 編碼,它包括了 GB2312 中的編碼,同時擴充了很多。中國又是個多民族國家,各個民族幾乎都有自己獨立的語言系統,為了表示那些字元,繼續把 GBK 編碼擴充為 GB18030 編碼。每個國家都像中國一樣,把自己的語言編碼,於是出現了各種各樣的編碼,如果你不安裝相應的編碼,就無法解釋相應編碼想表達的內容。終於,有個叫 ISO 的組織看不下去了。他們一起創造了一種編碼 UNICODE ,這種編碼非常大,大到可以容納世界上任何一個文字和標誌。所以只要電腦上有 UNICODE 這種編碼系統,無論是全球哪種文字,只需要儲存檔案的時候,儲存成 UNICODE 編碼就可以被其他電腦正常解釋。UNICODE 在網路傳輸中,出現了兩個標準 UTF-8 和 UTF-16,分別每次傳輸 8個位和 16個位。於是就會有人產生疑問,UTF-8 既然能儲存那麼多文字、符號,為什麼國內還有這麼多使用 GBK 等編碼的人?因為 UTF-8 等編碼體積比較大,佔電腦空間比較多,如果面向的使用人群絕大部分都是中國人,用 GBK 等編碼也可以。
也可以這樣來理解:字串是由字元構成,字元在計算機硬體中透過二進位制形式儲存,這種二進位制形式就是編碼。如果直接使用 “字串↔️字元↔️二進製表示(編碼)” ,會增加不同型別編碼之間轉換的複雜性。所以引入了一個抽象層,“字串↔️字元↔️與儲存無關的表示↔️二進製表示(編碼)” ,這樣,可以用一種與儲存無關的形式表示字元,不同的編碼之間轉換時可以先轉換到這個抽象層,然後再轉換為其他編碼形式。在這裡,unicode 就是 “與儲存無關的表示”,utf—8 就是 “二進製表示”。
三、亂碼的解決方法
根據原因來找解決方法,就非常簡單了。
方法一:直接指定res.encoding
import requests
url = "http://search.51job.com"
res = requests.get(url)
res.encoding = "gbk"
html = res.text
print(html)
方法二:透過res.apparent_encoding屬性指定
import requests
url = "http://search.51job.com"
res = requests.get(url)
res.encoding = res.apparent_encoding
html = res.text
print(html)
方法三:透過編碼、解碼的方式
import requests
url = "http://search.51job.com"
res = requests.get(url)
html = res.text.encode('iso-8859-1').decode('gbk')
print(html)
輸出結果:
基本思路三步走:確定源網頁的編碼A—gbk、程式透過編碼B—ISO-8859-1對源網頁資料還原、統一轉換字元的編碼C-utf-8。至於為啥為出現統一轉碼這一步呢? 網路爬蟲系統資料來源很多,不可能使用資料時,再轉化為其原始的資料,假使這樣做是很廢事的。所以一般的爬蟲系統都要對抓取下來的結果進行統一編碼,從而在使用時做到一致對外,方便使用。
比如如果我們想講網頁資料儲存下來,則會將起轉為utf-8,程式碼如下:
with open("a.txt",'w',encoding='utf-8') as f:
f.write(html)
四、總結
關於網路爬蟲亂碼問題,本文不僅給出了一個解決方案,還深入到其中的原理,由此問題引申出很多有意思的問題,如,utf-8、gbk、gb2312的編碼方式怎樣的?為什麼這樣轉化就可以解決問題?
最後,多動腦,多思考,多總結,致每一位碼農!
