
作者 | Gustavo Duarte
譯者 | qhwdw
記憶體管理是作業系統的核心任務;它對程式員和系統管理員來說也是至關重要的。在接下來的幾篇文章中,我將從實踐出發著眼於記憶體管理,並深入到它的內部結構。雖然這些概念很通用,但示例大都來自於 32 位 x86 架構的 Linux 和 Windows 上。這第一篇文章描述了在記憶體中程式如何分佈。
在一個多工作業系統中的每個行程都執行在它自己的記憶體“沙箱”中。這個沙箱是一個虛擬地址空間,在 32 位的樣式中它總共有 4GB 的記憶體地址塊。這些虛擬地址是透過核心頁表對映到物理地址的,並且這些虛擬地址是由作業系統核心來維護,進而被行程所消費的。每個行程都有它自己的一組頁表,但是這裡有點玄機。一旦虛擬地址被啟用,這些虛擬地址將被應用到這臺電腦上的 所有軟體,包括核心本身。因此,一部分虛擬地址空間必須保留給核心使用:

Kernel/User Memory Split
但是,這並不是說核心就使用了很多的物理記憶體,恰恰相反,它只使用了很少一部分可用的地址空間對映到其所需要的物理記憶體。核心空間在核心頁表中被標記為獨佔使用於 特權程式碼[1] (ring 2 或更低),因此,如果一個使用者樣式的程式嘗試去訪問它,將觸發一個頁面故障錯誤。在 Linux 中,核心空間是始終存在的,並且在所有行程中都對映相同的物理記憶體。核心程式碼和資料總是可定址的,準備隨時去處理中斷或者系統呼叫。相比之下,使用者樣式中的地址空間,在每次行程切換時都會發生變化:

Process Switch Effects on Virtual Memory
藍色的區域代表對映到物理地址的虛擬地址空間,白色的區域是尚未對映的部分。在上面的示例中,眾所周知的記憶體“饕餮” Firefox 使用了大量的虛擬記憶體空間。在地址空間中不同的條帶對應了不同的記憶體段,像堆、棧等等。請註意,這些段只是一系列記憶體地址的簡化表示,它與 Intel 型別的段[2] 並沒有任何關係 。不過,這是一個在 Linux 行程的標準段佈局:
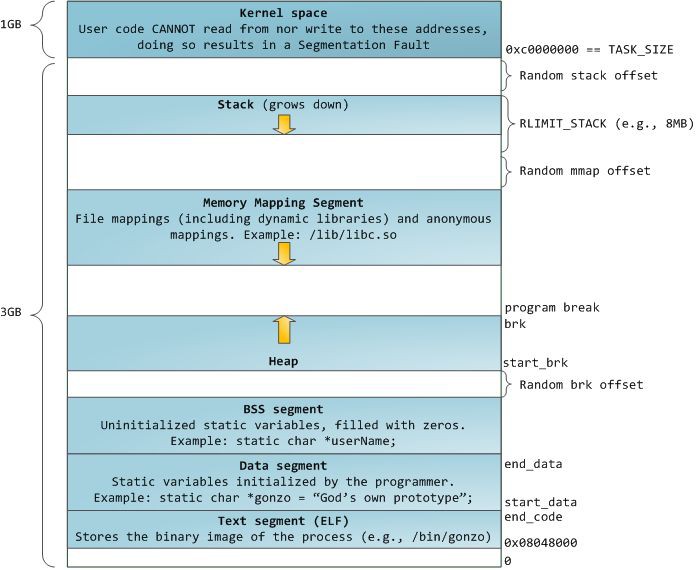
Flexible Process Address Space Layout In Linux
當計算機還是快樂、安全的時代時,在機器中的幾乎每個行程上,那些段的起始虛擬地址都是完全相同的。這將使遠端挖掘安全漏洞變得容易。漏洞利用經常需要去取用絕對記憶體位置:比如在棧中的一個地址,一個庫函式的地址,等等。遠端攻擊可以閉著眼睛選擇這個地址,因為地址空間都是相同的。當攻擊者們這樣做的時候,人們就會受到傷害。因此,地址空間隨機化開始流行起來。Linux 會透過在其起始地址上增加偏移量來隨機化棧[3]、記憶體對映段[4]、以及堆[5]。不幸的是,32 位的地址空間是非常擁擠的,為地址空間隨機化留下的空間不多,因此 妨礙了地址空間隨機化的效果[6]。
在行程地址空間中最高的段是棧,在大多數程式語言中它儲存本地變數和函式引數。呼叫一個方法或者函式將推送一個新的棧幀到這個棧。當函式傳回時這個棧幀被刪除。這個簡單的設計,可能是因為資料嚴格遵循 後進先出(LIFO)[7] 的次序,這意味著跟蹤棧內容時不需要複雜的資料結構 —— 一個指向棧頂的簡單指標就可以做到。推入和彈出也因此而非常快且準確。也可能是,持續的棧區重用往往會在 CPU 快取[8] 中保持活躍的棧記憶體,這樣可以加快訪問速度。行程中的每個執行緒都有它自己的棧。
向棧中推送更多的而不是剛合適的資料可能會耗盡棧的對映區域。這將觸發一個頁面故障,在 Linux 中它是透過 expand_stack()[9] 來處理的,它會去呼叫 acct_stack_growth()[10] 來檢查棧的增長是否正常。如果棧的大小低於 RLIMIT_STACK 的值(一般是 8MB 大小),那麼這是一個正常的棧增長和程式的合理使用,否則可能是發生了未知問題。這是一個棧大小按需調節的常見機制。但是,棧的大小達到了上述限制,將會發生一個棧上限溢位,並且,程式將會收到一個段故障錯誤。當對映的棧區為滿足需要而擴充套件後,在棧縮小時,對映區域並不會收縮。就像美國聯邦政府的預算一樣,它只會擴張。
動態棧增長是 唯一例外的情況[11] ,當它去訪問一個未對映的記憶體區域,如上圖中白色部分,是允許的。除此之外的任何其它訪問未對映的記憶體區域將觸發一個頁面故障,導致段故障。一些對映區域是隻讀的,因此,嘗試去寫入到這些區域也將觸發一個段故障。
在棧的下麵,有記憶體對映段。在這裡,核心將檔案內容直接對映到記憶體。任何應用程式都可以透過 Linux 的 mmap()[12] 系統呼叫( 程式碼實現[13])或者 Windows 的 CreateFileMapping()[14] / MapViewOfFile()[15] 來請求一個對映。記憶體對映是實現檔案 I/O 的方便高效的方式。因此,它經常被用於載入動態庫。有時候,也被用於去建立一個並不匹配任何檔案的匿名記憶體對映,這種對映經常被用做程式資料的替代。在 Linux 中,如果你透過 malloc()[16] 去請求一個大的記憶體塊,C 庫將會建立這樣一個匿名對映而不是使用堆記憶體。這裡所謂的“大”表示是超過了MMAP_THRESHOLD 設定的位元組數,它的預設值是 128 kB,可以透過 mallopt()[17] 去調整這個設定值。
接下來講的是“堆”,就在我們接下來的地址空間中,堆提供執行時記憶體分配,像棧一樣,但又不同於棧的是,它分配的資料生存期要長於分配它的函式。大多數程式語言都為程式提供了堆管理支援。因此,滿足記憶體需要是程式語言執行時和核心共同來做的事情。在 C 中,堆分配的介面是 malloc()[16] 一族,然而在支援垃圾回收的程式語言中,像 C#,這個介面使用 new 關鍵字。
如果在堆中有足夠的空間可以滿足記憶體請求,它可以由程式語言執行時來處理記憶體分配請求,而無需核心參與。否則將透過 brk()[18] 系統呼叫(程式碼實現[19])來擴大堆以滿足記憶體請求所需的大小。堆管理是比較 複雜的[20],在面對我們程式的混亂分配樣式時,它透過複雜的演演算法,努力在速度和記憶體使用效率之間取得一種平衡。服務一個堆請求所需要的時間可能是非常可觀的。實時系統有一個 特定用途的分配器[21] 去處理這個問題。堆也會出現 碎片化 ,如下圖所示:

Fragmented Heap
最後,我們抵達了記憶體的低位段:BSS、資料、以及程式文字。在 C 中,靜態(全域性)變數的內容都儲存在 BSS 和資料中。它們之間的不同之處在於,BSS 儲存 未初始化的 靜態變數的內容,它的值在原始碼中並沒有被程式員設定。BSS 記憶體區域是 匿名 的:它沒有對映到任何檔案上。如果你在程式中寫這樣的陳述句 static int cntActiveUsers,cntActiveUsers 的內容就儲存在 BSS 中。
反過來,資料段,用於儲存在原始碼中靜態變數 初始化後 的內容。這個記憶體區域是 非匿名 的。它映射了程式的二進值映象上的一部分,包含了在原始碼中給定初始化值的靜態變數內容。因此,如果你在程式中寫這樣的陳述句 static int cntWorkerBees = 10,那麼,cntWorkerBees 的內容就儲存在資料段中,並且初始值為 10。儘管可以透過資料段對映到一個檔案,但是這是一個私有記憶體對映,意味著,如果改變記憶體,它並不會將這種變化反映到底層的檔案上。必須是這樣的,否則,分配的全域性變數將會改變你磁碟上的二進位制檔案映象,這種做法就太不可思議了!
用圖去展示一個資料段是很困難的,因為它使用一個指標。在那種情況下,指標 gonzo 的內容(一個 4 位元組的記憶體地址)儲存在資料段上。然而,它並沒有指向一個真實的字串。而這個字串存在於文字段中,文字段是隻讀的,它用於儲存你的程式碼中的類似於字串常量這樣的內容。文字段也會在記憶體中對映你的二進位制檔案,但是,如果你的程式寫入到這個區域,將會觸發一個段故障錯誤。儘管在 C 中,它比不上從一開始就避免這種指標錯誤那麼有效,但是,這種機制也有助於避免指標錯誤。這裡有一個展示這些段和示例變數的圖:

ELF Binary Image Mapped Into Memory
你可以透過讀取 /proc/pid_of_process/maps 檔案來檢查 Linux 行程中的記憶體區域。請記住,一個段可以包含很多的區域。例如,每個記憶體對映的檔案一般都在 mmap 段中的它自己的區域中,而動態庫有類似於 BSS 和資料一樣的額外的區域。下一篇文章中我們將詳細說明“區域”的真正含義是什麼。此外,有時候人們所說的“資料段”是指“資料 + BSS + 堆”。
你可以使用 nm[22] 和 objdump[23] 命令去檢查二進位制映象,去顯示它們的符號、地址、段等等。最終,在 Linux 中上面描述的虛擬地址佈局是一個“彈性的”佈局,這就是這幾年來的預設情況。它假設 RLIMIT_STACK 有一個值。如果沒有值的話,Linux 將恢復到如下所示的“經典” 佈局:

Classic Process Address Space Layout In Linux
這就是虛擬地址空間佈局。接下來的文章將討論核心如何對這些記憶體區域保持跟蹤、記憶體對映、檔案如何讀取和寫入、以及記憶體使用資料的意義。
via: http://duartes.org/gustavo/blog/post/anatomy-of-a-program-in-memory/
作者:Gustavo Duarte[25] 譯者:qhwdw 校對:wxy
本文由 LCTT 原創編譯,Linux中國 榮譽推出




