
資料清理是很多機器學習任務上我們遇到的首要問題。本文介紹的 FastText 是一個開源 Python 庫,可用於快速進行大規模語料庫的文字搜尋與替換。該專案的作者表示,使用正則運算式(Regex)需要 5 天的任務在新的方法中只需要 15 分鐘即可完成。
專案連結:https://github.com/vi3k6i5/flashtext
自然語言處理領域的開發者在處理文字之前必須對資料進行清理。有些時候,此類工作是由關鍵詞替換完成的,就像吧「Javascript」替換成「JavaScript」。另一些時候,我們只需要知道檔案中是否提到了「JavaScript」。
這類資料清理任務是大多數處理文字的資料科學專案必須要做的。
資料科學從清理資料開始
本文作者是 Belong.co 的一名資料科學家,需要從事有關自然語言處理的工作,於是遇到了這個問題。當我在自己的檔案語料庫中開始訓練 Word2Vec 模型時,它開始將同義詞歸為同類項,「Javascripting」被歸類為「JavaScript」的同類項。
為瞭解決這個問題,我寫了一個正則運算式(Regex),用標準化命名來替換所有已知的同義詞。Regex 會將「Javascripting」替換為「JavaScript」,這解決了一個問題,卻又帶來了另一個問題。
有些人遇到問題時會想:「沒關係,我們有正則運算式。」現在問題變成了兩個。
上文所述引自 Stack-exchange question,現在讓我遇到了。
事實證明,正則運算式的速度很快——如果要搜尋和替換的關鍵詞數量是一百多個的話。但是面對超過 20k 個關鍵詞,300 萬個檔案的語料庫,事情就會變得很糟。當我測試我的程式碼時,我發現完全執行需要 5 天之久。

通常,面對這種情況我們的解決方案是並行運算。但在面對上千萬個檔案中成百上千出現頻次的關鍵詞,並行的效能提升有限,我們必須找到更好的方法!
幸好,在 Stack Overflow 上我的疑問獲得了大家的關註,網友們和公司同事 Vinay Pandey、Suresh Lakshmanan 等人提到了一個名叫 Aho-Corasick 演演算法的神奇工具,以及字首樹資料結構(Trie Data Structure)。然而目前網路上還缺乏相關資源。
-
Aho-Corasick 演演算法:https://en.wikipedia.org/wiki/Aho%E2%80%93Corasick_algorithm
-
Trie Data Structure:https://en.wikipedia.org/wiki/Trie
所以我開始自己動手,FlashText 誕生了。
在介紹 FlashText 的結構和工作原理之前,先看看它的搜尋效能表現:

下麵的紅線是 FlashText 的搜尋耗時
如上圖所示,Regex 演演算法和 FlashText 搜尋同一篇檔案的耗時相差很大。隨著關鍵詞數量的增加,Regex 的耗時呈線性增長,而對於 FlashText 來說並沒有影響。
FlashText 可以把 5 天的工作縮短到 15 分鐘!

這是 FlashText 替換的速度:

同樣,下麵的紅線是 FlashText 的替換速度。
所以,FlashText 是什麼?
FlashText 是我在 GitHub 上開源的一個 Python 庫,它能高效地提取和替換關鍵詞。
使用 FlashText 時,首先你需要傳送一系列關鍵詞,這個串列將被用於在內部建立一個字首樹字典。隨後你需要傳遞一個字串,告訴它你需要執行替換還是搜尋。
在替換時,它會建立一個新字串來替換關鍵詞。在搜尋時,它會傳回一個關鍵詞串列。這一切都將在輸入字串上進行。
有的使用者是這樣評價FastText的:

Radim Řehůřek 是著名 Python 庫 Gensim 的作者
FlashText 為什麼那麼快?
我們用一個例子來嘗試和理解這一部分。假設我們有一個包含三個單詞的句子 I like Python,和一個有四個單詞的語料庫 {Python,Java,J2ee,Ruby}。
如果每次取出語料庫中的一個單詞,並檢查其在句子中是否出現,這需要四次操作。
is 'Python' in sentence?
is 'Java' in sentence?
...
如果語料庫有 n 個單詞,意味著需要做 n 次的迴圈操作,並且每一個時間步的搜尋都是 is
還有另一種和第一種相反的方法。對於句子中的每一個單詞,檢查其是否在語料庫中出現。
is 'I' in corpus?
is 'like' in corpus?
is 'python' in corpus?
如果句子 m 個單詞,意味著需要做 m 次的迴圈操作。在這個例子中所需的時間步取決於句子中的單詞數。而使用字典查詢進行 is
FlashText 基於第二種方法,由 Aho-Corasick 演演算法和字首樹(Trie)資料結構所啟發。
它的工作方式為:
首先由語料庫建立一個如下圖所示的字首樹字典:
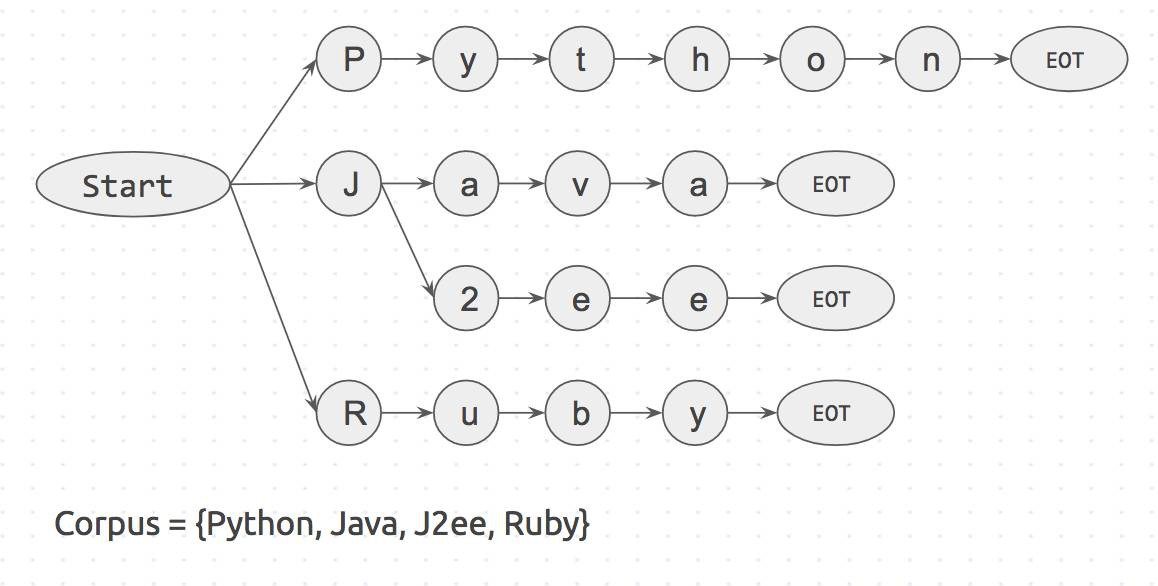
語料庫的字首樹字典
Start 和 EOT(End Of Term,期末)表示單詞的邊界比如 space、period 和 new_line。只有兩側都有邊界的關鍵詞才能得到匹配,這可以防止把 apple 匹配到 pineapple。
下一步我們將取輸入字串為 I like Python,並按字元逐個對齊進行搜尋。
Step 1: isI in dictionary? No
Step 2: islike in dictionary? No
Step 3: isPython in dictionary? Yes

由於這是一個字元匹配過程,我們可以輕易地在進行到
FlashText 演演算法只需要遍歷輸入字串『I like Python』的每一個字元。即使字典有上百萬個關鍵詞,對執行時間也沒有任何影響。這是 FlashText 演演算法的真正威力。
什麼時候需要使用 FlashText?
簡單的回答是:當關鍵詞數量>500 的時候

當關鍵詞數量>500 的時候,FlashText 的搜尋速度開始超過 Regex
完整的回答是:Regex 可以搜尋基於特殊字元比如^、$、*、d 等的關鍵詞,而 FlashText 不支援這種搜尋。
所以如果想要匹配部分單詞比如『worddvec』,使用 FlashText 並沒有好處,但其非常善於提取完整的單詞比如『word2vec』。
用於尋找關鍵詞的程式碼
# pip install flashtext
from flashtext.keyword import KeywordProcessor
keyword_processor = KeywordProcessor()
keyword_processor.add_keyword('Big Apple', 'New York')
keyword_processor.add_keyword('Bay Area')
keywords_found = keyword_processor.extract_keywords('I love Big Apple and Bay Area.')
keywords_found
# ['New York', 'Bay Area']
使用 FlashText 提取關鍵詞的簡單例子
用於替換關鍵詞的程式碼
FlashText 不僅可以提取句子中的關鍵詞還可以對其進行替換。我們將此作為資料處理管道的資料清理步驟。 
from flashtext.keyword import KeywordProcessor
keyword_processor = KeywordProcessor()
keyword_processor.add_keyword('Big Apple', 'New York')
keyword_processor.add_keyword('New Delhi', 'NCR region')
new_sentence = keyword_processor.replace_keywords('I love Big Apple and new delhi.')
new_sentence
# 'I love New York and NCR region.'
使用 FlashText 替換關鍵詞的簡單例子
原文連結:https://medium.freecodecamp.org/regex-was-taking-5-days-flashtext-does-it-in-15-minutes-55f04411025f
本文轉載自微信公眾號:機器之心
————近期開班————
馬哥聯合BAT、豆瓣等一線網際網路Python開發達人,根據目前企業需求的Python開發人才進行了深度定製,加入了大量一線網際網路公司:大眾點評、餓了麼、騰訊等生產環境真是專案,課程由淺入深,從Python基礎到Python高階,讓你融匯貫通Python基礎理論,手把手教學讓你具備Python自動化開發需要的前端介面開發、Web框架、大監控系統、CMDB系統、認證堡壘機、自動化流程平臺六大實戰能力,讓你從0開始蛻變成Hold住年薪20萬的Python自動化開發人才。
10期面授班:2018年03月05號(北京)
09期網路班:騰訊課堂隨到隨學(網路)

 掃描二維碼領取學習資料
掃描二維碼領取學習資料

更多Python好文請點選【閱讀原文】哦
↓↓↓
