最近越來越多的同學找我討論 “TensorFlow on Kubernetes” 的方案和實踐,並且想瞭解自從上次分享《淺嘗 TensorFlow on Kubernetes》和《如何落地 TensorFlow on Kubernetes[1]》後,現在做成什麼樣了。這說明越來越多的企業開始基於 Kubernetes 和 TensorFlow 來構建自己的深度學習平臺,我們非常願意同大家交流和分享我們的實踐。下麵將主要介紹當前 vivo TaaS 平臺的架構和功能。
關於如何將 Kubernetes 和 TensorFlow 整合起來的 Topic,以及我們的 CaaS 技術棧的介紹,請參考過往的兩篇文章,在這裡我不再贅述。

-
有的同學問我,我們是如何將 HDFS 的訓練資料遷移到 Glusterfs 的,在這統一回覆:目前基於 HDFS 作為後端分散式儲存的 TaaS 能滿足演演算法團隊的需求,所以最終我們也沒有做這個資料遷移工作。
-
由於這個方案中,每個 TensorFlow 訓練都會對應一個 Kubernetes NameSpace,每個TensorFlow Task 都會對應一個 Headless Service,各個 Task 透過 KubeDNS 進行發現和域名解析。
在我們的環境中,當一個 TensorFlow 訓練的 Task 數超過600時,偶爾會出現 Headless Service Name 域名解析失敗的情況,導致分散式 TensorFlow 叢集內部的 Session 連線建立失敗,最終無法成功啟動這次 Between-Graph 訓練。
我們透過 Kubernetes 的孵化專案 cluster-proportional-autoscaler 來根據叢集 Node 數量對 KubeDNS 副本數進行彈性伸縮來解決這一問題的。下麵是我們使用的 kube-dns-autoscaler 配置:
kind: ConfigMap
apiVersion: v1
metadata:
name: kube-dns-autoscaler
namespace: kube-system
data:
linear: |
{
"nodesPerReplica": 10,
"min": 1,
"max": 50,
"preventSinglePointFailure": true
}
關於這個問題的深入探討,請參考我的博文《cluster-proportional-autoscale源 碼分析及如何解決 KubeDNS 效能瓶頸[2]》。
當然更好的解決辦法其實是應該是對 cluster-proportional-autoscaler 進行二次開發,根據叢集中 Service Number 來對 KubeDNS 進行彈性伸縮。
因為在我們 AI 的場景下,一臺高配的伺服器能執行的 Pods 數可以多達80個,正常情況不會超過30個,這麼大的彈性範圍,無疑使用 Service Number 來對 KubeDNS 進行彈性伸縮是最好的選擇。

我們 TaaS 平臺目前支援訓練指令碼的託管、訓練專案的建立和管理、TensorBoard服務的一鍵建立能力,雖然支援一鍵建立 TensorFlow Serving 服務幫助模型上線,但是因為還沒做 TensorFlow Serving 的 Load Balance,所以這個特性還沒正式上線,目前正在開發中,以後有機會再跟大家分享。
使用者登入 TaaS Portal,上傳本地的演演算法指令碼到 TaaS 平臺,提供一系列演演算法指令碼管理的能力,這個沒多少可說的。
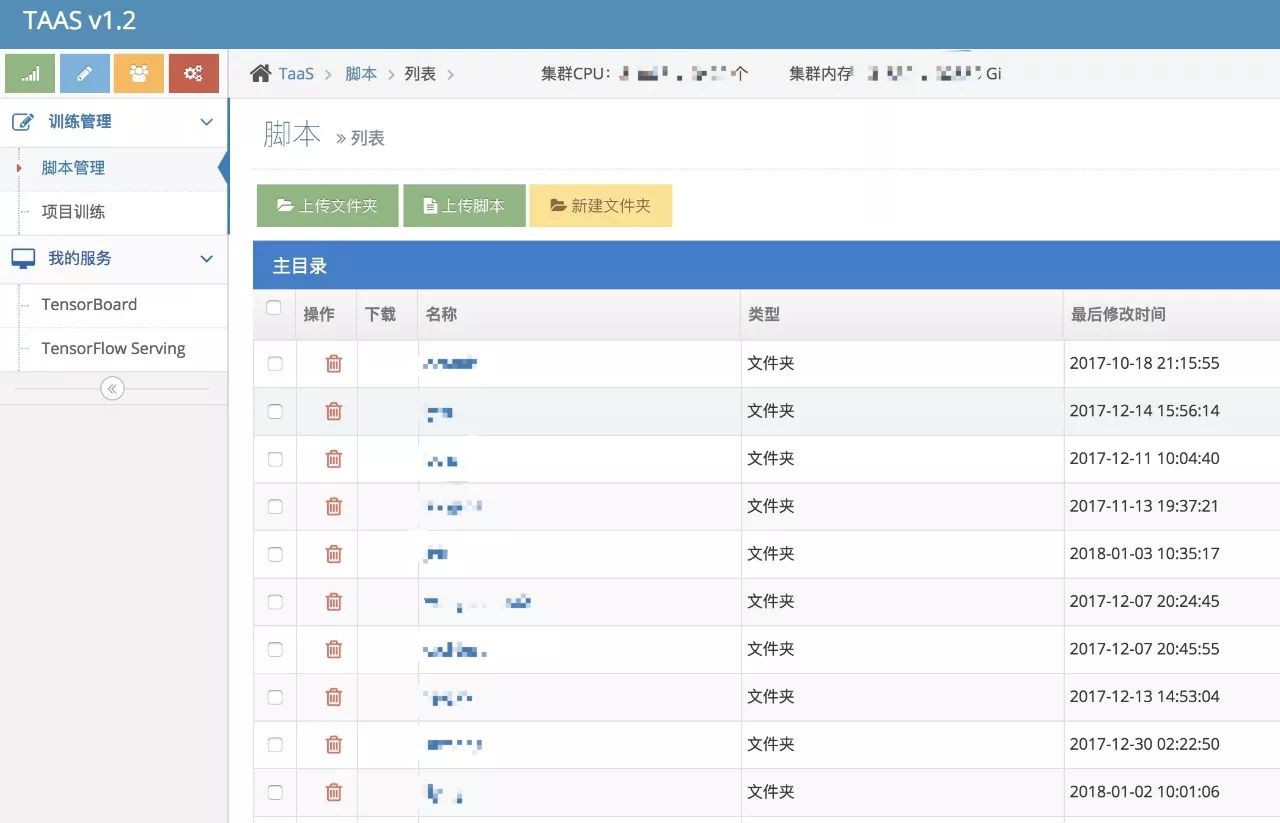
每個演演算法,我們約定使用 run.sh 檔案啟動訓練。

接下來,使用者根據演演算法指令碼的路徑建立對應的訓練專案。

訓練專案分兩種型別:普通訓練和定時訓練。定時訓練顧名思義,就是透過定時器控制訓練實體,每隔一定週期啟動一次訓練,並且支援啟動下一次訓練前是否強行殺死上一次的訓練。還可以設定該次訓練最長允許的時長,超時強行殺死本次訓練。

建立完專案後,接下來就是啟動訓練了,填入worker 數和 ps 數,選擇對應的 resource.requests,提交訓練請求。
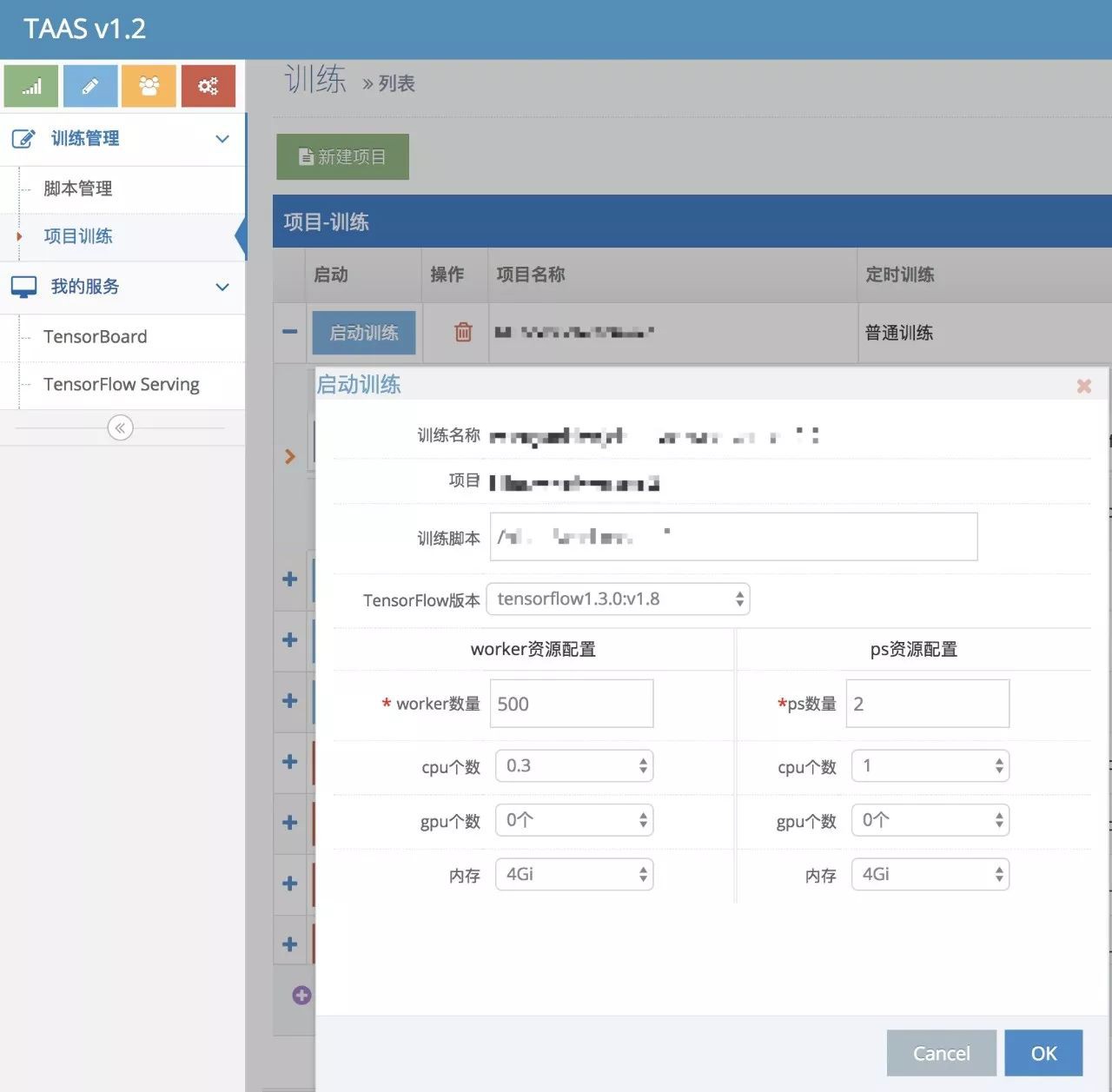
然後請求轉到 Kubernetes 中,建立對應的 Namespace, workers job,ps deployment及其對應的 Headless Services,imagePullSecret 等 Object,TaaS 生成對應的訓練記錄。

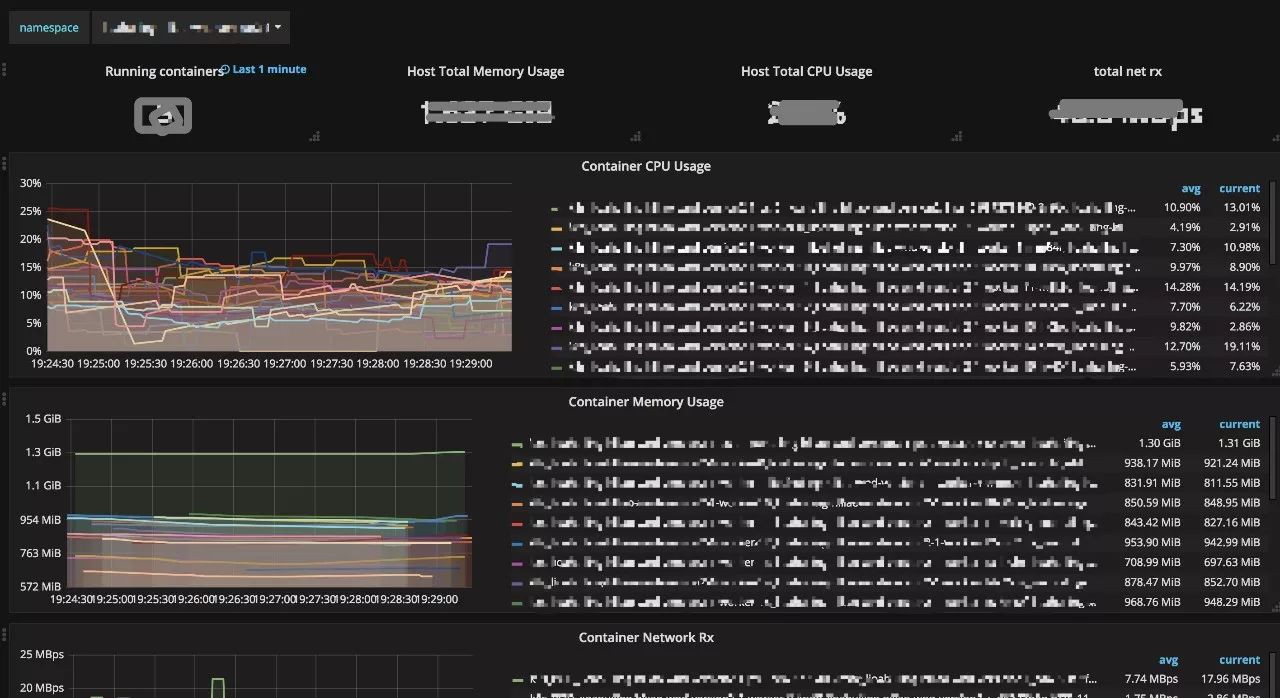
每個訓練記錄都對應一個 Kubernetes Namespace,可以檢視訓練詳情、各個 task 的日誌和對應的 Grafana 監控面板。

TensorBoard 透過載入 log 目錄下的 summary data,為模型和訓練提供了 Web 檢視,可以幫助演演算法工程師定位演演算法的瓶頸。vivo TaaS 平臺支援一鍵建立 TensorBoard 服務。

請求會轉到 Kubernetes 建立對應的 TensorBoard Deployment 等 Object,TaaS頁面提供該 TensorBoard 服務的訪問入口。

點選“模型展示”,即可跳轉到對應的 TensorBoard Web 檢視。

-
目前我們的 TaaS 平臺仍然處於早期階段,還有很多工作需要去做:
-
為訓練新增自定義命令列引數;
-
大規模 TensorFlow 訓練的排程最佳化;
-
排程時考慮伺服器的網路 IO 資源;
-
訓練資料和模型的管理;
-
為 TensorFlow Serving 提供自動化LB配置;
-
基於 GPU 的排程和訓練;
-
叢集資源使用情況的動態監控,並對新的 TensorFlow 叢集建立請求做更有意義的資源檢查;
-
如果需要,使用 Glusterfs 提高訓練資料的 Read IO;
-
……(事情總是做不完的)
這裡對 vivo TaaS 平臺做了簡單介紹,在這背後摸索的過程中我們解決了很多問題,但是未來的路很長,隨著叢集規模的快速膨脹,我們要做的工作會越來越多。TaaS 平臺只是我們 Kubernetes 在 vivo 落地的一個方向,DevOps、ESaaS等平臺的開發也面臨很多挑戰。
-
https://my.oschina.net/jxcdwangtao/blog/1554472
-
https://my.oschina.net/jxcdwangtao/blog/1581879
本文轉載自公眾號: vivo網際網路技術,ID:vivoVMIC,點選閱讀原文。
本次培訓包含:Kubernetes核心概念;Kubernetes叢集的安裝配置、運維管理、架構規劃;Kubernetes元件、監控、網路;針對於Kubernetes API介面的二次開發;DevOps基本理念;微服務架構;微服務的容器化等,點選識別下方二維碼加微信好友瞭解具體培訓內容。

長按二維碼向我轉賬

受蘋果公司新規定影響,微信 iOS 版的贊賞功能被關閉,可透過二維碼轉賬支援公眾號。

