

在大資料蓬勃發展的今天,基於Hadoop黃金搭檔HDFS和MapReduce的Hive,已經無法滿足人們對於海量資料處理速度越來越快的要求。時勢造英雄,Cloudera依據Google的Dremel為原型開發了跨時代的查詢引擎:Impala。
Impala的本意是黑斑羚,產於非洲中南部,行動敏捷,奔跑迅速。下麵我們就來揭開這隻敏捷迅速黑斑羚的神秘面紗,以饗各位看官。
01 概述
Impala是基於MPP的SQL查詢系統,可以直接為儲存在HDFS或HBase中的Hadoop資料提供快速、互動式的SQL查詢。Impala和Hive一樣也使用了相同的元資料、SQL語法(Hive SQL)、ODBC驅動和使用者介面(Hue Beeswax),這就很方便地為使用者提供了一個相似並且統一的平臺來進行批次或實時查詢。
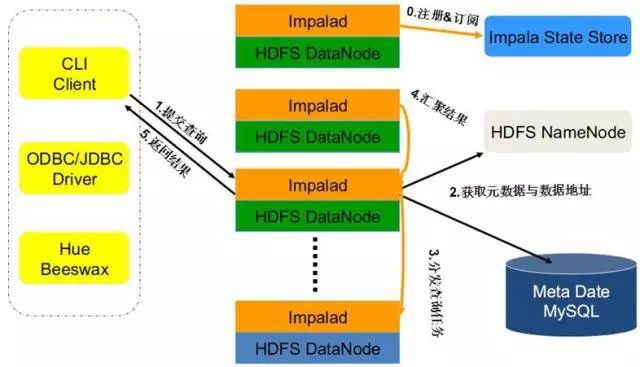
Impala系統架構圖如下所示:

Impala主要包括以下組成部分:
-
Impala Shell:客戶端工具,提供一個互動介面ODBC,供使用者連線到Impalad發起資料查詢或管理任務等。
-
Impalad:分散式查詢引擎,由Query Planner、Query Coordinator和Query Exec Engine三部分組成,可以直接從HDFS或者HBase中用SELECT、JOIN和統計函式查詢資料。
-
State Store:主要為跟蹤各個Impalad實體的位置和狀態,讓各個Impalad實體以叢集的方式執行起來。
-
Catalog Service:主要跟蹤各個節點上對元資料的變更操作,並且通知到每個節點。
Impala支援以下特性:
-
支援ANSI-92 SQL所有子集,包括CREATE/ALTER/SELECT/INSERT/JOIN/subqueries
-
支援分割槽join、完全分散式聚合以及完全分散式top-n查詢
-
支援多種資料格式:Hadoop原生格式(apache Avro,SequenceFile,RCFile with Snappy,GZIP, BZIP或未壓縮)、文字(未壓縮或者LZO壓縮)和Parquet(Snappy或未壓縮)
-
可以透過JDBC、ODBC、Hue GUI或者命令列shell進行連線
02 查詢處理流程
Impalad分為Java前端(Frontend)與C++處理後端(Backend),接受客戶端連線的Impalad即作為這次查詢的Coordinator,Coordinator透過JNI呼叫Java前端對使用者的查詢SQL進行分析生成執行計劃樹,不同的操作對應不用的PlanNode, 如:SelectNode, ScanNode, SortNode, AggregationNode, HashJoinNode等等。
執行計劃樹的每個原子操作由一個PlanFragment表示,通常一條查詢陳述句由多個Plan Fragment組成, Plan Fragment 0表示執行樹的根,匯聚結果傳回給使用者,執行樹的葉子結點一般是Scan操作,分散式並行執行。
Java前端產生的執行計劃樹以Thrift資料格式傳回給Impala C++後端Coordinator,執行計劃分為多個階段,每一個階段叫做一個PlanFragment,每一個PlanFragment在執行時可以由多個Impalad實體並行執行(有些PlanFragment只能由一個Impalad實體執行,如聚合操作),整個執行計劃即為一個執行計劃樹。Coordinator收到執行計劃後,資料儲存資訊(Impala透過libhdfs與HDFS進行互動,透過hdfsGetHosts方法獲得檔案資料塊所在節點的位置資訊),透過排程器(現在只有simple-scheduler, 使用round-robin演演算法)Coordinator::Exec對生成的執行計劃樹分配給相應的後端執行器Impalad執行(查詢會使用LLVM進行程式碼生成,編譯,執行),透過呼叫GetNext()方法獲取計算結果,如果是insert陳述句,則將計算結果透過libhdfs寫回HDFS,當所有輸入資料被消耗光,執行結束,之後登出此次查詢服務。
Impala查詢處理流程如下圖所示:
03 訪問Impala
訪問Impala有兩種方式,一種是使用命令列工具impala-shell,另一種是使用JDBC程式設計,下麵分別闡述。
Impala-shell
可以透過命令列工具Impala-shell來建立資料庫、表、插入資料、執行查詢等。
Impala shell命令格式如下:
impala-shell [選項]
impala-shell使用選項如下:
|
選項 |
描述 |
|
-B or –delimited |
導致使用分隔符分割的普通文字格式列印查詢結果。當為其他 Hadoop 元件生成資料時有用。對於避免整齊列印所有輸出的效能開銷有用,特別是使用查詢傳回大量的結果集進行基準測試的時候。使用 –output_delimiter 選項指定分隔符。使用 -B 選項常用於儲存所有查詢結果到檔案裡而不是列印到螢幕上。 |
|
–print_essay-header |
是否列印列名。整齊列印時是預設啟用。同時使用 -B 選項時,在首行列印列名 |
|
-o filename or –output_file filename |
儲存所有查詢結果到指定的檔案。通常用於儲存在命令列使用 -q 選項執行單個查詢時的查詢結果。對互動式會話同樣生效;此時你只會看到獲取了多少行資料,但看不到實際的資料集。當結合使用 -q 和 -o 選項時,會自動將錯誤資訊輸出到 /dev/null。 |
|
–output_delimiter=character |
當使用 -B 選項以普通檔案格式列印查詢結果時,用於指定欄位之間的分隔符。預設是製表符 tab (‘\t’)。假如輸出結果中包含了分隔符,該列會被引起且/或轉義。 |
|
-p or –show_profiles |
對 shell 中執行的每一個查詢,顯示其查詢執行計劃 (與 EXPLAIN 陳述句輸出相同) 和發生低階故障的執行步驟的更詳細的資訊 |
|
-h or –help |
顯示幫助資訊 |
|
-i hostname or –impalad=hostname |
指定連線執行 impalad 守護行程的主機。預設埠是 21050。你可以連線到叢集中執行 impalad 的任意主機。假如你連線到 impalad 實體透過 –fe_port 標誌使用了其他埠,則應當同時提供埠號,格式為 hostname:port |
|
-q query or –query=query |
從命令列中傳遞一個查詢或其他 shell 命令。執行完這一陳述句後 shell 會立即退出。限製為單條陳述句,可以是 SELECT, CREATE TABLE, SHOW TABLES, 或其他 impala-shell 認可的陳述句。因為無法傳遞 USE 陳述句再加上其他查詢,對於 default 資料庫之外的表,應在表名前加上資料庫識別符號(或者使用 -f 選項傳遞一個包含 USE 陳述句和其他查詢的檔案) |
|
-f query_file or –query_file=query_file |
傳遞一個檔案中的 SQL 查詢。檔案內容必須以分號分隔 |
|
-k or –kerberos |
當連線到 impalad 時使用 Kerberos 認證。如果要連線的 impalad 實體不支援 Kerberos,將顯示一個錯誤 |
|
-s kerberos_service_name or –kerberos_service_name=name |
指示impala-shell對特定impalad服務主體進行身份驗證。 如果沒有設定 kerberos_service_name ,預設使用 impala。如果啟用了本選項,而試圖建立不支援Kerberos 的連線時,傳回一個錯誤。 |
|
-V or –verbose |
啟用詳細輸出 |
|
–quiet |
關閉詳細輸出 |
|
-v or –version |
顯示版本資訊 |
|
-c |
查詢執行失敗時繼續執行 |
|
-r or –refresh_after_connect |
建立連線後掃清 Impala 元資料,與建立連線後執行 REFRESH 陳述句效果相同 |
|
-d default_db or –database=default_db |
指定啟動後使用的資料庫,與建立連線後使用 USE 陳述句選擇資料庫作用相同,如果沒有指定,那麼使用 default 資料庫 |
|
-l |
啟用 LDAP 認證 |
|
-u |
當使用 -l 選項啟用 LDAP 認證時,提供使用者名稱(使用短使用者名稱,而不是完整的 LDAP 專有名稱distinguished name),shell 會提示輸入密碼 |
JDBC程式設計
Impala支援JDBC訪問,JAVA程式透過JDBC驅動訪問Impala。配置Impala的JDBC連線包括以下步驟:
-
配置Impala JDBC埠
預設的Impala JDBC訪問埠是21050,確保Impala上此埠能被其他機器訪問;如果使用其他埠,啟動impalad時帶上–hs2_port引數。
-
在客戶端安裝Impala JDBC驅動
客戶端impala JDBC驅動包含一些jar檔案,檔案串列如下:
-
下載上述jar檔案到impala JDBC客戶端。
-
儲存jar檔案到CLASSPATH路徑中。
-
設定CLASSPATH環境變數包含jar檔案路徑
在linux系統:增加jar路徑到CLASSPATH前面:比如jar檔案儲存到/opt/jars/,設定命令為:export CLASSPATH=/opt/jars/*.jar:$CLASSPATH
在windows系統:在“系統屬性”控制面板中修改“環境變數”,設定CLASSPATH開頭包含jar檔案路徑
-
Java應用程式配置JDBC連線字串,連線Impalad
JDBC驅動類是org.apache.hive.jdbc.HiveDriver,連線分為以下幾種:
-
連線的Impala叢集沒有使用Kerberos鑒權,JDBC連線字串形式為:jdbc:hive2://host:port/;auth=noSasl
-
連線的Impala叢集使用Kerberos鑒權,JDBC連線字串形式為:jdbc:hive2://host:port/;principal=principal_name
-
連線的Impala叢集使用LDAP鑒權,JDBC連線字串形式為:jdbc:hive2://host:port/db_name;user=ldap_userid;password=ldap_password
下麵的例子使用Impala JDBC程式設計介面查詢指定表的資料:

04 效能調優
Impala效能調優使用以下方法:
-
選擇合適的檔案格式
通常情況,對大量資料,Parquet檔案格式是最好的,因為它結合了列儲存佈局、大的I / O請求大小、壓縮和編碼。
-
避免資料攝入過程產生許多小檔案
使用INSERT……SELECT複製表資料,避免對任何海量資料或影響效能的關鍵型表使用INSERT……VALUES,因為每一個這樣的陳述句產生一個單獨的小資料檔案。
如果在資料處理中產生過多小檔案,需要使用INSERT……SELECT將資料複製到另外一張表,這樣解決了小檔案過多的問題。
-
選擇合適的分割槽技術
分割槽是一種技術,基於一個或多個列的值物理上把資料分成多部分。當你發出查詢請求一個特定分割槽鍵列的值或值範圍,Impala可以避免讀取無關的資料可能產生的巨大的磁碟I / O。
分割槽技術適用於以下情況:
-
表的資料量非常大,讀取整個表的時間不在我們的承受範圍之內
-
表總是依據某些特定的列進行查詢
-
列有合理的基數(不同值的數量)
-
資料已經經過ETL處理
-
使用COMPUTE STATS蒐集連線查詢中海量資料表或者影響效能的關鍵表的統計資訊
-
最小化傳回結果給客戶端的傳輸開銷
使用聚合、過濾、限制、避免精細列印結果集等方法傳回最小化結果。
-
在執行查詢前使用EXPLAIN檢視執行計劃是否高效合理
-
在執行查詢後使用PROFILE從底層確認IO、記憶體消耗、網路頻寬佔用、CPU使用率等資訊是否在預期範圍內
來源:中興大資料
精彩活動
推薦閱讀
2017年資料視覺化的七大趨勢!
全球100款大資料工具彙總(前50款)
Q: 關於Impala,你還瞭解什麼?
歡迎留言與大家分享
請把這篇文章分享給你的朋友
轉載 / 投稿請聯絡:hzzy@hzbook.com
更多精彩文章,請在公眾號後臺點選“歷史文章”檢視

