
1.最基本的抓站

2.使用代理伺服器
這在某些情況下比較有用,比如IP被封了,或者比如IP訪問的次數受到限制等等。

3.需要登入的情況
登入的情況比較麻煩我把問題拆分一下:
3.1 cookie的處理

是的沒錯,如果想同時用代理和cookie,那就加入proxy_support然後operner改為
opener = urllib2.build_opener(proxy_support, cookie_support, urllib2.HTTPHandler)
3.2 表單的處理
登入必要填表,表單怎麼填?首先利用工具擷取所要填表的內容。
比如我一般用firefox+httpfox外掛來看看自己到底發送了些什麼包
這個我就舉個例子好了,以verycd為例,先找到自己發的POST請求,以及POST表單項:

可以看到verycd的話需要填username,password,continueURI,fk,login_submit這幾項,其中fk是隨機生成的(其實不太隨機,看上去像是把epoch時間經過簡單的編碼生成的),需要從網頁獲取,也就是說得先訪問一次網頁,用正則運算式等工具擷取傳回資料中的fk項。continueURI顧名思義可以隨便寫,login_submit是固定的,這從原始碼可以看出。還有username,password那就很顯然了。
好的,有了要填寫的資料,我們就要生成postdata

然後生成http請求,再傳送請求:

3.3 偽裝成瀏覽器訪問
某些網站反感爬蟲的到訪,於是對爬蟲一律拒絕請求。這時候我們需要偽裝成瀏覽器,這可以透過修改http包中的essay-header來實現:

3.4 反”反盜鏈”
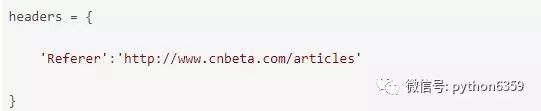
某些站點有所謂的反盜鏈設定,其實說穿了很簡單,就是檢查你傳送請求的essay-header裡面,referer站點是不是他自己,所以我們只需要像3.3一樣,把essay-headers的referer改成該網站即可,以黑幕著稱地cnbeta為例:
essay-headers是一個dict資料結構,你可以放入任何想要的essay-header,來做一些偽裝。例如,有些自作聰明的網站總喜歡窺人隱私,別人透過代理訪問,他偏偏要讀取essay-header中的X-Forwarded-For來看看人家的真實IP,沒話說,那就直接把X-Forwarde-For改了吧,可以改成隨便什麼好玩的東東來欺負欺負他,呵呵。
3.5 終極絕招
有時候即使做了3.1-3.4,訪問還是會被據,那麼沒辦法,老老實實把httpfox中看到的essay-headers全都寫上,那一般也就行了。 再不行,那就只能用終極絕招了,selenium直接控制瀏覽器來進行訪問,只要瀏覽器可以做到的,那麼它也可以做到。類似的還有pamie,watir,等等等等。
4.多執行緒併發抓取
單執行緒太慢的話,就需要多執行緒了,這裡給個簡單的執行緒池模板 這個程式只是簡單地列印了1-10,但是可以看出是併發地。

![]()
5.驗證碼的處理
碰到驗證碼咋辦?這裡分兩種情況處理:
-
google那種驗證碼,涼拌
-
簡單的驗證碼:字元個數有限,只使用了簡單的平移或旋轉加噪音而沒有扭曲的,這種還是有可能可以處理的,一般思路是旋轉的轉回來,噪音去掉,然後劃分單個字元,劃分好了以後再透過特徵提取的方法(例如PCA)降維並生成特徵庫,然後把驗證碼和特徵庫進行比較。這個比較複雜,一篇博文是說不完的,這裡就不展開了,具體做法請弄本相關教科書好好研究一下。
-
事實上有些驗證碼還是很弱的,這裡就不點名了,反正我透過2的方法提取過準確度非常高的驗證碼,所以2事實上是可行的。
6 gzip/deflate支援
現在的網頁普遍支援gzip壓縮,這往往可以解決大量傳輸時間,以VeryCD的主頁為例,未壓縮版本247K,壓縮了以後45K,為原來的1/5。這就意味著抓取速度會快5倍。
然而python的urllib/urllib2預設都不支援壓縮,要傳回壓縮格式,必須在request的essay-header裡面寫明’accept-encoding’,然後讀取response後更要檢查essay-header檢視是否有’content-encoding’一項來判斷是否需要解碼,很繁瑣瑣碎。如何讓urllib2自動支援gzip, defalte呢?
其實可以繼承BaseHanlder類,然後build_opener的方式來處理:

然後就簡單了,
encoding_support = ContentEncodingProcessor opener = urllib2.build_opener( encoding_support, urllib2.HTTPHandler ) #直接用opener開啟網頁,如果伺服器支援gzip/defalte則自動解壓縮 content = opener.open(url).read()
7. 更方便地多執行緒
總結一文的確提及了一個簡單的多執行緒模板,但是那個東東真正應用到程式裡面去只會讓程式變得支離破碎,不堪入目。在怎麼更方便地進行多執行緒方面我也動了一番腦筋。先想想怎麼進行多執行緒呼叫最方便呢?
1、用twisted進行非同步I/O抓取
事實上更高效的抓取並非一定要用多執行緒,也可以使用非同步I/O法:直接用twisted的getPage方法,然後分別加上非同步I/O結束時的callback和errback方法即可。例如可以這麼乾:

twisted人如其名,寫的程式碼實在是太扭曲了,非正常人所能接受,雖然這個簡單的例子看上去還好;每次寫twisted的程式整個人都扭曲了,累得不得了,檔案等於沒有,必須得看原始碼才知道怎麼整,唉不提了。
如果要支援gzip/deflate,甚至做一些登陸的擴充套件,就得為twisted寫個新的HTTPClientFactory類諸如此類,我這眉頭真是大皺,遂放棄。有毅力者請自行嘗試。
這篇講怎麼用twisted來進行批次網址處理的文章不錯,由淺入深,深入淺出,可以一看。
2、設計一個簡單的多執行緒抓取類
還是覺得在urllib之類python“本土”的東東裡面折騰起來更舒服。試想一下,如果有個Fetcher類,你可以這麼呼叫

這麼個多執行緒呼叫簡單明瞭,那麼就這麼設計吧,首先要有兩個佇列,用Queue搞定,多執行緒的基本架構也和“技巧總結”一文類似,push方法和pop方法都比較好處理,都是直接用Queue的方法,taskleft則是如果有“正在執行的任務”或者”佇列中的任務”則為是,也好辦,於是程式碼如下:

8. 一些瑣碎的經驗
1、連線池:
opener.open和urllib2.urlopen一樣,都會新建一個http請求。通常情況下這不是什麼問題,因為線性環境下,一秒鐘可能也就新生成一個請求;然而在多執行緒環境下,每秒鐘可以是幾十上百個請求,這麼乾只要幾分鐘,正常的有理智的伺服器一定會封禁你的。
然而在正常的html請求時,保持同時和伺服器幾十個連線又是很正常的一件事,所以完全可以手動維護一個HttpConnection的池,然後每次抓取時從連線池裡面選連線進行連線即可。
這裡有一個取巧的方法,就是利用squid做代理伺服器來進行抓取,則squid會自動為你維護連線池,還附帶資料快取功能,而且squid本來就是我每個伺服器上面必裝的東東,何必再自找麻煩寫連線池呢。
2、設定執行緒的棧大小
棧大小的設定將非常顯著地影響python的記憶體佔用,python多執行緒不設定這個值會導致程式佔用大量記憶體,這對openvz的vps來說非常致命。stack_size必須大於32768,實際上應該總要32768*2以上
from threading import stack_size stack_size(32768*16)
3、設定失敗後自動重試

4、設定超時
import socket socket.setdefaulttimeout(10) #設定10秒後連線超時
5、登陸
登陸更加簡化了,首先build_opener中要加入cookie支援,參考“總結”一文;如要登陸VeryCD,給Fetcher新增一個空方法login,併在init()中呼叫,然後繼承Fetcher類並override login方法:

於是在Fetcher初始化時便會自動登入VeryCD網站。
9. 總結
如此,把上述所有小技巧都糅合起來就和我目前的私藏最終版的Fetcher類相差不遠了,它支援多執行緒,gzip/deflate壓縮,超時設定,自動重試,設定棧大小,自動登入等功能;程式碼簡單,使用方便,效能也不俗,可謂居家旅行,殺人放火,咳咳,之必備工具。
之所以說和最終版差得不遠,是因為最終版還有一個保留功能“馬甲術”:多代理自動選擇。看起來好像僅僅是一個random.choice的區別,其實包含了代理獲取,代理驗證,代理測速等諸多環節,這就是另一個故事了。

