分享一個新浪微博的爬蟲,基於 Scrapy + MongoDB 實現,號稱一小時可爬千萬條資料。
作者:LiuXingMing
來源:http://blog.csdn.net/bone_ace/article/details/50903178
專案地址:https://github.com/LiuXingMing/SinaSpider
爬蟲功能:
-
此專案和QQ空間爬蟲類似,主要爬取新浪微博使用者的個人資訊、微博資訊、粉絲和關註(詳細見此)。
-
程式碼獲取新浪微博Cookie進行登入,可透過多賬號登入來防止新浪的反扒(用來登入的賬號可從淘寶購買,一塊錢七個)。
-
專案爬的是新浪微博wap站,結構簡單,速度應該會比較快,而且反扒沒那麼強,缺點是資訊量會稍微缺少一些(可見爬蟲福利:如何爬wap站)。
-
爬蟲抓取微博的速度可以達到 1300萬/天 以上,具體要視網路情況,我使用的是校園網(廣工大學城校區),普通的家庭網路可能才一半的速度,甚至都不到。
環境、架構:
開發語言:Python2.7
開發環境:64位Windows8系統,4G記憶體,i7-3612QM處理器。
資料庫:MongoDB 3.2.0
(Python編輯器:Pycharm 5.0.4;MongoDB管理工具:MongoBooster 1.1.1)
-
主要使用 scrapy 爬蟲框架。
-
下載中介軟體會從Cookie池和User-Agent池中隨機抽取一個加入到spider中。
-
start_requests 中根據使用者ID啟動四個Request,同時對個人資訊、微博、關註和粉絲進行爬取。
-
將新爬下來的關註和粉絲ID加入到待爬佇列(先去重)。
使用說明:
啟動前配置:
-
MongoDB安裝好 能啟動即可,不需要配置。
-
Python需要安裝好scrapy(64位的Python儘量使用64位的依賴模組)
-
另外用到的python模組還有:pymongo、json、base64、requests。
-
將你用來登入的微博賬號和密碼加入到 cookies.py 檔案中,裡面已經有兩個賬號作為格式參考了。
-
另外一些scrapy的設定(如間隔時間、日誌級別、Request執行緒數等)可自行在setting裡面調。
執行截圖:
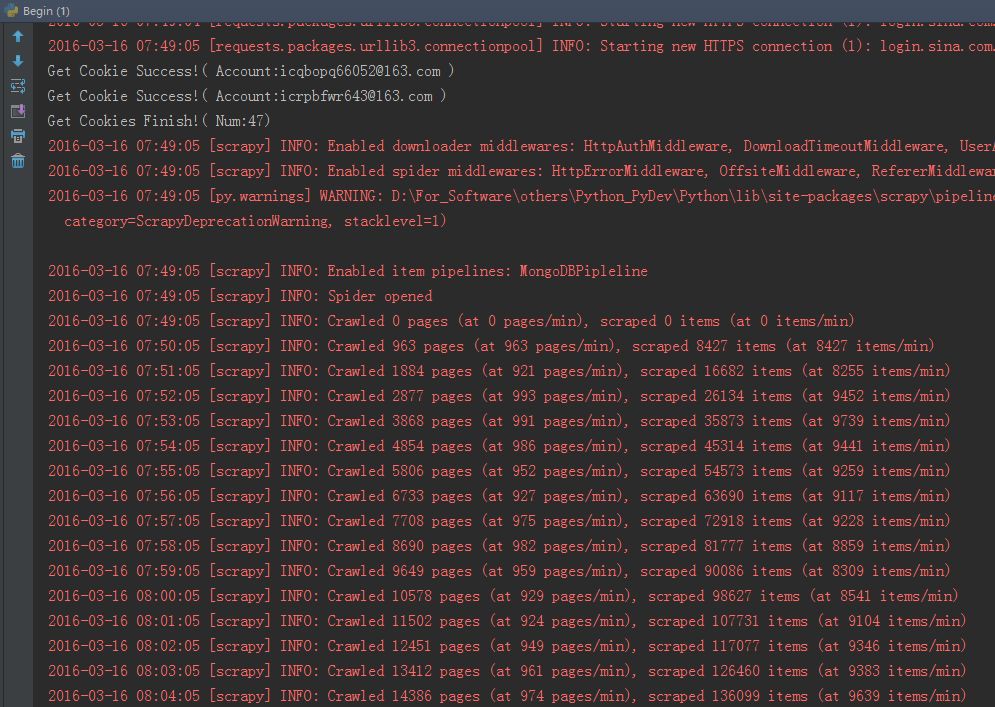

資料庫說明:
SinaSpider主要爬取新浪微博的個人資訊、微博資料、關註和粉絲。 資料庫設定 Information、Tweets、Follows、Fans四張表,此處僅介紹前面兩張表的欄位。
Information 表:
id:採用 “使用者ID” 作為唯一標識。
Birthday:出生日期。
City:所在城市。
Gender:性別。
Marriage:婚姻狀況。
NickName:微博暱稱。
NumFans:粉絲數量。
NumFollows:關註數量。
NumTweets:已發微博數量。
Province:所在省份。
Signature:個性簽名。
URL:微博的個人首頁。Tweets 表:
id:採用 “使用者ID-微博ID” 的形式作為一條微博的唯一標識。
Cooridinates:發微博時的定位坐標(經緯度),呼叫地圖API可直接檢視具體方位,可識別到在哪一棟樓。
Comment:微博被評論的數量。
Content:微博的內容。
ID:使用者ID。
Like:微博被點贊的數量。
PubTime:微博發表時間。
Tools:發微博的工具(手機型別或者平臺)
Transfer:微博被轉發的數量。
●本文編號322,以後想閱讀這篇文章直接輸入322即可
●輸入m獲取文章目錄

