(點選上方公眾號,可快速關註)
轉自:Treant
http://www.cnblogs.com/en-heng/p/5013995.html
決策樹模型與學習
決策樹(decision tree)演演算法基於特徵屬性進行分類,其主要的優點:模型具有可讀性,計算量小,分類速度快。
決策樹演演算法包括了由Quinlan提出的ID3與C4.5,Breiman等提出的CART。其中,C4.5是基於ID3的,對分裂屬性的標的函式做出了改進。
決策樹模型
決策樹是一種透過對特徵屬性的分類對樣本進行分類的樹形結構,包括有向邊與三類節點:
1、根節點(root node),表示第一個特徵屬性,只有出邊沒有入邊;
2、內部節點(internal node),表示特徵屬性,有一條入邊至少兩條出邊
3、葉子節點(leaf node),表示類別,只有一條入邊沒有出邊。

上圖給出了(二叉)決策樹的示例。決策樹具有以下特點:
1、對於二叉決策樹而言,可以看作是if-then規則集合,由決策樹的根節點到葉子節點對應於一條分類規則;
2、分類規則是互斥並且完備的,所謂互斥即每一條樣本記錄不會同時匹配上兩條分類規則,所謂完備即每條樣本記錄都在決策樹中都能匹配上一條規則。
3、分類的本質是對特徵空間的劃分,如下圖所示,

決策樹學習
決策樹學習的本質是從訓練資料集中歸納出一組分類規則[2]。但隨著分裂屬性次序的不同,所得到的決策樹也會不同。如何得到一棵決策樹既對訓練資料有較好的擬合,又對未知資料有很好的預測呢?
首先,我們要解決兩個問題:
1、如何選擇較優的特徵屬性進行分裂?每一次特徵屬性的分裂,相當於對訓練資料集進行再劃分,對應於一次決策樹的生長。ID3演演算法定義了標的函式來進行特徵選擇。
2、什麼時候應該停止分裂?有兩種自然情況應該停止分裂,一是該節點對應的所有樣本記錄均屬於同一類別,二是該節點對應的所有樣本的特徵屬性值均相等。但除此之外,是不是還應該其他情況停止分裂呢?
決策樹演演算法
特徵選擇
特徵選擇指選擇最大化所定義標的函式的特徵。下麵給出如下三種特徵(Gender, Car Type, Customer ID)分裂的例子:

圖中有兩類類別(C0, C1),C0: 6是對C0類別的計數。直觀上,應選擇Car Type特徵進行分裂,因為其類別的分佈機率具有更大的傾斜程度,類別不確定程度更小。
為了衡量類別分佈機率的傾斜程度,定義決策樹節點t
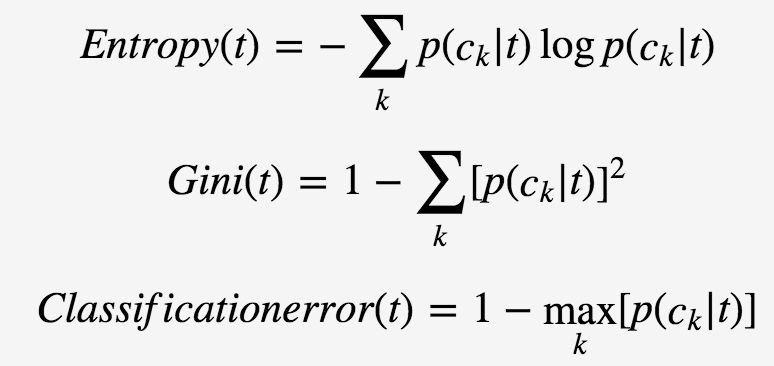
其中,p(ck|t)表示對於決策樹節點tt類別ckck的機率。這三種不純度的度量是等價的,在等機率分佈是達到最大值。
為了判斷分裂前後節點不純度的變化情況,標的函式定義為資訊增益(information gain):
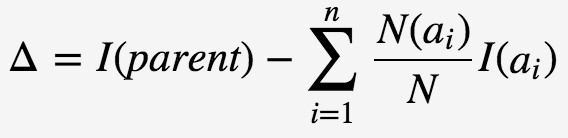
I(⋅)對應於決策樹節點的不純度,parent表示分裂前的父節點,N表示父節點所包含的樣本記錄數,ai表示父節點分裂後的某子節點,N(ai)為其計數,n為分裂後的子節點數。
特別地,ID3演演算法選取熵值作為不純度I(⋅)的度量,則

c指父節點對應所有樣本記錄的類別;A表示選擇的特徵屬性,即ai的集合。那麼,決策樹學習中的資訊增益Δ等價於訓練資料集中類與特徵的互資訊,表示由於得知特徵A的資訊訓練資料集c不確定性減少的程度。
在特徵分裂後,有些子節點的記錄數可能偏少,以至於影響分類結果。為瞭解決這個問題,CART演演算法提出了只進行特徵的二元分裂,即決策樹是一棵二叉樹;C4.5演演算法改進分裂標的函式,用資訊增益比(information gain ratio)來選擇特徵:

因而,特徵選擇的過程等同於計算每個特徵的資訊增益,選擇最大資訊增益的特徵進行分裂。
此即回答前面所提出的第一個問題(選擇較優特徵)。ID3演演算法設定一閾值,當最大資訊增益小於閾值時,認為沒有找到有較優分類能力的特徵,沒有往下繼續分裂的必要。
根據最大表決原則,將最多計數的類別作為此葉子節點。即回答前面所提出的第二個問題(停止分裂條件)。
決策樹生成
ID3演演算法的核心是根據資訊增益最大的準則,遞迴地構造決策樹;演演算法流程如下:
1、如果節點滿足停止分裂條件(所有記錄屬同一類別 or 最大資訊增益小於閾值),將其置為葉子節點;
2、選擇資訊增益最大的特徵進行分裂;
3、重覆步驟1-2,直至分類完成。
C4.5演演算法流程與ID3相類似,只不過將資訊增益改為資訊增益比。
決策樹剪枝
過擬合
生成的決策樹對訓練資料會有很好的分類效果,卻可能對未知資料的預測不準確,即決策樹模型發生過擬合(overfitting)——訓練誤差(training error)很小、泛化誤差(generalization error,亦可看作為test error)較大。
下圖給出訓練誤差、測試誤差(test error)隨決策樹節點數的變化情況:

可以觀察到,當節點數較小時,訓練誤差與測試誤差均較大,即發生了欠擬合(underfitting)。
當節點數較大時,訓練誤差較小,測試誤差卻很大,即發生了過擬合。只有當節點數適中是,訓練誤差居中,測試誤差較小;對訓練資料有較好的擬合,同時對未知資料有很好的分類準確率。
發生過擬合的根本原因是分類模型過於複雜,可能的原因如下:
1、訓練資料集中有噪音樣本點,對訓練資料擬合的同時也對噪音進行擬合,從而影響了分類的效果;
2、決策樹的葉子節點中缺乏有分類價值的樣本記錄,也就是說此葉子節點應被剪掉。
剪枝策略
為瞭解決過擬合,C4.5透過剪枝以減少模型的複雜度。[2]中提出一種簡單剪枝策略,透過極小化決策樹的整體損失函式(loss function)或代價函式(cost function)來實現,決策樹T的損失函式為:

其中,C(T)
如果剪枝後損失函式減少了,即說明這是有效剪枝。具體剪枝演演算法可以由動態規劃等來實現。
參考資料
[1] Pang-Ning Tan, Michael Steinbach, Vipin Kumar, Introduction to Data Mining.
[2] 李航,《統計學習方法》.
[3] Naren Ramakrishnan, The Top Ten Algorithms in Data Mining
覺得本文有幫助?請分享給更多人
關註「演演算法愛好者」,修煉程式設計內功
