

對於微服務的成功實施,團隊持續交付能力是至關重要的衡量指標。在由上百個服務組成的複雜系統中,如果所有服務都按照人為指定釋出週期進行整體交付,很容易出現由於細小的失誤導致大面積線上故障。
持續交付實踐要求每個獨立服務都具有完備的交付流水線,在流水線的末端隨時能提供當時最新的可工作、可交付的產品。持續交付通常會配合自動化的測試和部署手段,從而減少功能程式碼提交到上線的端到端時間。這就使得每個獨立服務能按照各自不同的節奏進行釋出,並且將自己的釋出狀態可視化出來。
採用盡可能精簡且穩定的分支策略也是使得持續交付流程能夠順利實施的關鍵,我們提倡使用單主幹的分支策略(Trunk Based Development)。在單主幹的開發方式中,除了一個用於持續開發和整合的『主幹分支』(通常即Master分支)和一系列依據釋出週期建立的釋出分支以外,應該避免建立其他的Long-lived分支。如果有多個功能需要開發,則推薦採用特性開關(Feature Toggle)的方法來控制它們的釋出時機。當然,單主幹策略是允許存在短生命週期特性分支的(短於一週),有時這些小分支甚至無需提交到遠端倉庫中。下麵這是一幅經典的單主幹分支策略示意圖。
值得指出的是,在劃分得當的微服務系統中,同一個服務需要同時進行開發的特性通常不會多於兩到三個(否則應該考慮這個服務是否承擔了過多的職責)。因此即使在不需要特性開關和其他額外開發工作量的情況下,已經可以比較好的實現每個功能點的獨立釋出和測試,這反向說明瞭微服務架構對於持續交付的實施也是十分友好的。
除了嚴格的單主幹,一種常見的變式是多主幹策略,典型的是一個開發分支加幾個固定的釋出分支,通常用於無需維護多個釋出版本的SaaS服務交付。這種樣式的優點是能夠將釋出流水線標的環境和分支顯示的關聯起來,例如『Develop分支』對應整合環境,『Release分支』對應驗收環境和正式環境。下圖展示了一組與此樣式下的持續交付流水線。

保持每個服務高頻率的整合和交付,會使得有故障的功能在很短的反饋週期內被髮現,在快速迭代釋出的前提下做到整個系統釋出井然有序。這樣的氛圍不僅有利於改善程式碼的質量,而且能夠提高開發士氣,頻繁的釋出上線也有利於增強團隊對產品的榮譽感和自信心。
全功能團隊是DevOps運動所倡導的一種產品團隊組織結構,透過將不同角色的業務和技術成員納入到團隊,組成具備端到端交付和運營能力的完整單元。
康威定律闡述了開發團隊的組織結構和其設計的產品結構之間具有的相似關係。許多的實踐結果也表明,將全功能團隊實踐應用在微服務產品中帶來的收益,要遠遠超過它在傳統模組化開發的產品中所帶來的收益。這是因為微服務的架構中的所有服務真正具備獨立執行和獨立運營的能力,從本質上來說就是一個端到端的子業務產品。
這種架構和團隊的影響是雙向的。一方面,微服務的運營結構要求團隊具有高內聚的自主管理能力。另一方面,全功能團隊也為特定服務進行獨立技術選型提供了更靈活的發揮空間。服務與團隊通常是多對一的關係,每個團隊管理的是一組相互關聯緊密的服務群,並且可以在必要的情況下對服務進行進一步拆分。在實際的實踐中推薦採用例如介面閘道器(API Gateway)等方式對一組具有業務意義的服務介面進行聚合,從而保證區域性服務結構變化不會直接影響服務的消費方的呼叫。
值得一說的是,在一些傳統企業內的IT部門劃分,往往已經按照職能分為開發團隊、運維團隊、運營團隊,甚至單獨的測試團隊。在這樣的企業中很難快速完成全功能團隊的轉變,因此在實施微服務架構過程中比較容易走偏。對於這種情況可以採用逐步演進的轉換方式,具體途徑主要有兩種。
第一種方式是進行專案試點。對於習慣了按功能分層、分塊的『實現介面開發』式的組織,即使勉強湊齊每個角色的人組在一起也難以成為真正具備端到端交付能力的團隊。因此與其做得徒有其表,不如找出專案中一些全域性意識比較到位的成員,對特定的專案進行試點,然後逐步擴大,將這種端到端的責任和意識帶入到更多的專案中去。試點的專案應該是以實施現有系統的一個獨立業務功能點為標的,而不是開發與企業主線系統無關的短期產品,否則容易出現試點專案很成功,但專案結束便不了了之的結果。
自動化運維是實施持續交付的必要前提,因此也可以說是採用微服務架構的必要前提。但這裡所說的自動化運維,不僅僅包含持續交付所需的服務部署時『一鍵操作』能力,更重要的是運維基礎設施構建的自動化、以及服務災備、恢復的自動化。
微服務架構最初受到追捧的一個原因是它靈活的『區域性Scale Out』能力,以功能點為單元的擴充套件、收縮,這對於具有業務週期性的服務而言更加重要。但一些企業在自身基礎設施自動化不到位的情況下盲目實施微服務,期望透過其實現複雜架構的解構,結果在面對突發線上事故時出現雪崩式的連鎖反應,情急之下也只能手工恢復重建,耽誤大量時間。
實施自動化運維涉及的工具有很多,例如Ansible、SaltStack、Terraform,甚至Docker都可以看做是自動化運維的一部分。這當中大多數工具都提供有定義操作行為的領域DSL,它們通常是一些配置式語言或指令碼語言,因此自動化運維也涉及到程式碼的編寫。與開發專案程式碼不同的地方在於,自動化運維的程式碼大多不是長期執行的,很多程式碼也許只在特定場景使用一次,然後就會非常長時間無人問津,直到某些緊急情況才會再次需要用到。此外,運維的程式碼本身並不直接具有業務價值,這些因素導致它們往往沒有被很好的管理起來。
下麵以採用Ansible或SaltStack這類通用自動化工具為例,介紹一些在實踐中需要註意的地方。
首先是運維指令碼應該透過Git或SVN這樣的版本管理工具進行歸類和管理。通常來說,推薦將特定服務部署的Ansible或SaltStack YAML指令碼檔案與服務本身的程式碼放在同一個程式碼倉庫中,方便開發人員在必要時候快速的修改它。然後將基礎設施管理的YAML指令碼檔案放在單獨的程式碼倉庫,方便復用和查詢。但這樣可能帶來的問題是,在實際使用時可能會需要同時獲取兩個程式碼倉庫的指令碼以獲得完整的部署功能,因此如果使用的其他配套工具對多倉庫支援不佳,也可以將所有運維指令碼在同一個倉庫管理。
其次,應該在持續交付流水線上使用服務部署的自動化工具,從而實現快速的交付上線。在條件允許的情況下,還應該在流水線上直接配備自動化的災備恢復任務入口,以及定期的對這些恢復指令碼進行測試和演練。
由於微服務系統中存在著眾多跨服務呼叫,任何一個服務都不能假設自己可以隨意的停機一段時間而不對系統的整體功能造成影響。但在現實情況中,正常的服務升級或意外的故障都有可能造成服務短暫或長時間的中斷,這種中斷輕則引起區域性功能不可用,重則導致連鎖反應造成重大事故。這些都是在架構設計時候就應該予以考慮的問題。應對這兩類情況的方法分別是對服務採用高可用的部署方式,和進行不離線的部署。
實現服務高可用的方法有很多,常見的有:L7負載均衡、DNS負載均衡、服務發現、同步/非同步訊息佇列等。
L7負載均衡即在OSI網路模型應用層進行的軟體負載均衡,例如Nginx和HAProxy都屬於這類。這些L7負載均衡通常帶有後端服務檢查的能力,會自動遮蔽掉不可用的後端服務,從而在一部分服務出現故障時候,請求仍然能被正常執行的後端服務接收。
DNS負載均衡是利用了DNS服務可以為同一個域名配置多個解析地址,且配置多個地址後,每次解析域名時輪詢著將配置的地址傳回給請求方,這個特性稱為DNS輪詢。實際上DNS輪詢僅僅是一種特殊的負載均衡技術,本身並不具有檢測服務狀態、提供後端服務高可用的功能。但一些新出現的開源DNS產品,例如SkyDNS和Consul將DNS服務與服務發現技術進行了結合,具有自動移除不可訪問的解析地址的功能,這使得DNS負載均衡也可以被用於實現服務的高可用了。
服務發現是一種基於註冊和查詢服務資訊的鍵值資料庫服務。提供服務的一方將自己的名稱和IP地址註冊到服務發現的服務端,使用服務的一方則透過服務發現的服務端進行查詢,然後將實際請求傳送給查詢到的標的IP地址。服務發現的服務端會負責檢測每個註冊服務的執行狀態,及時移除出現故障的服務,併在每次收到查詢時從符合名稱的服務中任意傳回一個作為結果。
不離線部署是確保服務隨時能釋出的必要措施,也是微服務架構團隊需要關註的一種能力。在實際應用中,除了一些天生支援不離線部署的技術棧,如Erlang,多數的服務是原生不支援熱升級的。對於這些服務,通常來說可根據服務『是否能遞進式升級』和『是否具有長任務』的特性,分成三種型別:『不能遞進升級的服務』,『能遞進升級、無長任務的服務』,以及『能遞進升級、有長任務的服務』,分別採用不同策略進行。
這裡先介紹一下服務的『遞進式升級』和『具有長任務』。
遞進式升級(Rolling Update)是指將叢集中的服務劃成多個分組,每次只升級其中的一個分組,然後依次進行,直到所有服務都升級完成的過程。採用遞進式升級會使得叢集中的服務有一段時間同時存在新舊兩個版本。
長任務指是接收到請求後需要花費幾秒、甚至幾小時才能執行完的任務,例如一些涉及大量計算或需要遠端同步呼叫的事務。具有長任務的服務都有『執行中』和『空閑』這樣的執行狀態。當服務處於『執行中』的時候,中斷它可能導致意外的結果。一般來說在Linux中停止服務的流程是先向服務傳送一個TERM訊號,使其正常結束,若是訊號傳送幾秒後,服務仍然在執行,才會傳送KILL訊號將它強行終止。處理短任務的服務通常可以在接收到TERM訊號後及時停止,因此不存在這種風險。這裡應該將『無長任務的服務』與『無狀態的服務』加以區分,後者指的是服務對每次請求的處理,不依賴於其他請求。即服務處理一次請求所需的全部資訊,要麼都包含在這個請求裡,要麼可以從外部獲取到(比如說資料庫),伺服器本身不儲存任何資訊。通常來說,微服務架構中的服務一定是無狀態的,但不一定是無長任務的。
如果服務不能採用遞進式的升級,不論其是否具有長任務,藍綠部署都是一種十分推薦的部署方式。藍綠部署的做法是同時準備一組線上執行的伺服器,以及一組用於下次部署的伺服器,兩組伺服器具有相同的數量和配置。執行部署時,先將新的服務部署到沒有放到線上執行的那組伺服器上,等到部署全部完成,直接將負載均衡的流量導向到剛剛這組伺服器上,從而使得兩組伺服器的角色互換。下一次進行部署的時候,則換用另外一組伺服器執行部署,然後將負載均衡切換回來。這個過程如下圖所示:
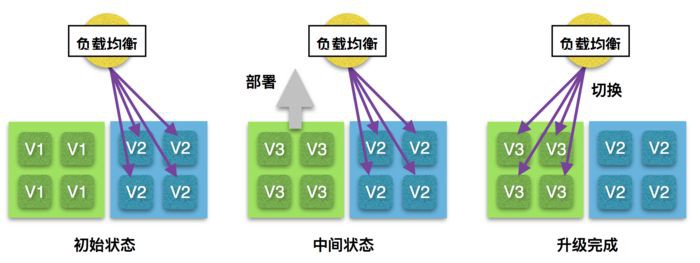
藍綠部署的優點在於新舊服務的切換是瞬間完成的,並且當流量切換到另一組伺服器上之後,原先的那組伺服器可以繼續執行,這樣即使上面有未完成的任務也不會被強行中斷,如果升級後的版本發現了比較嚴重的問題,也可以快速的切換回原先的版本。而它的缺點也十分明顯,那就是會佔用比實際需要多一倍的伺服器作為下次部署的備用機器。
一些前端服務可能會屬於這類情況,我們也許不希望在升級的過程中,一部分使用者看到是新的頁面,另一部分看到還是舊的頁面。另外對於Nginx這類負載均衡工具,後端服務的健康檢查並非是實時生效的,有可能出現服務已經離線,但請求仍然被分發到這個主機的情況,因此採用負載均衡作為高可用方案的服務,藍綠部署也是比較可取的方式。
如果服務的數量比較多,並且允許同時存在兩個執行的版本,那麼採用遞進式升級方式則會更加節省資源。以每次升級一個節點的遞進方式為例,當升級開始後,我們首先停止所有服務節點中的任意一個,將它進行升級,然後讓它重新加入叢集,接著從剩下的服務節點從再任意選擇一個,直到最後一個服務也被升級完成。這個過程不需要增加額外的伺服器資源,只要待升級的服務具有兩個以上的節點,就不會對服務的整體功能造成中斷。遞進式升級的過程如下圖所示:
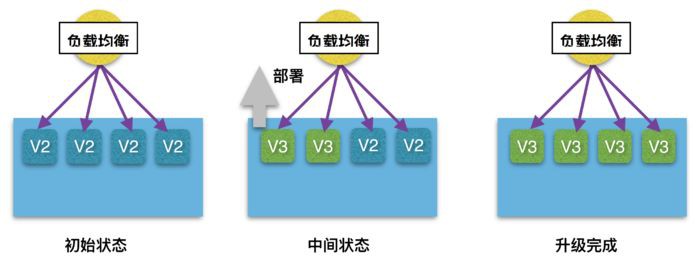
顯然如果服務本身是不能被隨時停止的,那麼這種簡單的遞進升級就不能很好的滿足了。此時我們需要對服務的排程進行干涉,以採用服務發現的高可用方式為例,下圖展示了一種『帶狀態檢查的遞進式升級』策略進行服務部署。

這種升級方法具有普通遞進式升級的相似優勢,但在叢集中有個別服務執行任務時間很長,始終處於『執行中』狀態的情況下,將使得升級過程阻塞,大大的延長服務部署的時間。事實上,長任務的服務通常都可以被改造成為批處理式的服務(Batch-Task Service),批處理式服務的升級只需要直接將服務執行檔案替換,從根本上簡化了升級難度。
記憶體不足、磁碟耗盡、網路中斷、服務失效,這些天災人禍隨時可能殃及產品的服務叢集。很難想象,在一個龐大的微服務系統中,如果沒有合適的監控和告警設施,服務的運營會變得多麼混亂不堪。
對微服務系統進行監控主要需要考慮兩個方面:基礎設施的監控和應用服務的監控。
基礎設施的監控通常由部署在每個節點上的資料採集端、集中式的資料匯聚端、以及資料展示、資料分析和告警通知等部分組成。而監控告警系統的實施中,還需要結合團隊的運維自動化能力,選擇合適的技術棧進行。開源的Promethus和InfluxDB都是值得考慮的工具。
容器是一種能夠加速促進團隊DevOps水平的虛擬化技術。它透過把服務和系統依賴全量打包的映象格式,將執行環境的設計提前到了開發階段,並且實現了開發、測試、線上環境的高度一致。由於容器遮蔽了不同服務執行時的差異性,使得基於這種方式進行服務的大規模部署和排程變得簡單。具體來說體現在以下幾個方面:
首先是執行環境的隔離。在虛擬機器時代,由於每個業務依賴的系統環境不同,伺服器之間無法通用。各個業務都需要獨立管理服務執行環境,還往往造成多個服務同時執行的衝突,和各個執行環境不一致等問題。容器為每個服務提供隔離的執行環境,即使在同一個伺服器上執行多種執行時相互有衝突的服務也不會出問題。
其次是精細的資源分配。透過虛擬機器分配服務資源時,為了簡化管理,通常不論服務實際使用多少CPU和記憶體資源,都只能從固定的主機型別中挑選一種,按主機的個數計費。容器能夠很好的實現面向資源池的服務管理,各個服務可以根據併發行程數、CPU和記憶體用量等資源計費,實現更加精細的資源管理。
此外,容器還有利於資源的動態調整。過去企業裡的伺服器資源一般是按計劃分配的,有的部門為了避開繁瑣的資源申請流程,一次性申請大量資源囤積備用,造成浪費。容器的面向資源池特性,使得企業能夠將所有計算資源進行執行時動態調整,實現按計劃分配到按需分配的轉變。業務只需適應流量負載的變化。在負載高峰期快速增加資源,保證業務服務質量,在負載低峰期釋放資源給其它服務,提高叢集資源利用率。
成功的實施微服務架構需要設計的不僅僅是架構本身,還有圍繞整個服務叢集的所有基礎設施和團隊的自主性文化。
從實踐的角度上說,本文所提到的這些方面也遠不是微服務所需要考慮的全部。還有很多沒有提到的實踐,同樣是值得採納的,只是它們相對而言並非那麼要緊。比如灰度釋出,在微服務體系中也具有很大的運用空間。
每一個精心設計的企業級架構背後,都蘊含了相當的複雜性,微服務亦是如此。優秀的架構並不能讓軟體的複雜度憑空消失,而是透過更加合理的拆分和約束,使得軟體結構更加容易匹配業務、適應變化,從而在規模化的同時保持高度的響應力。架構不是銀彈,離開了必要的實踐前提,空談微服務,猶如東施效顰,期望拆了服務就能為企業帶來受益,無疑於空中樓閣的笑話而已。
基於Kubernetes的容器雲平臺實踐培訓

本次培訓包含:Kubernetes核心概念;Kubernetes叢集的安裝配置、運維管理、架構規劃;Kubernetes元件、監控、網路;針對於Kubernetes API介面的二次開發;DevOps基本理念;Docker的企業級應用與運維等,點選識別下方二維碼加微信好友瞭解具體培訓內容。
