來自:高效運維(微訊號:greatops)
作者:鄭松寬

本文整理自 GOPS2017.北京站演講《去哪兒網應用運維自動化演進之路》,高效運維社群致力於陪伴您共同成長。
作者簡介

鄭松寬
去哪兒網 高階運維工程師。2013年加入去哪兒網平臺事業部,從事運維開發工作。工作中主要負責公司監控系統的開發,應用管理平臺Portal的設計、開發和運維
前言
我今天分享的主題是“去哪兒網應用運維自動化演進之路”。我們在自動化構建過程中所遇到的障礙以及我們是怎麼樣跨越這些障礙,我們遇到了哪些坑,以及怎麼填平這些坑的過程。
我是2013年加入去哪兒網,加入之後一直在從事運維開發工作。去哪兒網運維開發有一個特點,我們所有開發既當PM,又當QA,也沒有區分前端工作還是後端工作,用現在比較流行的話說,我們都是全棧工程師。加入去哪兒這幾年做的工作也是比較零碎的,哪裡有需求就去哪裡。
概括起來主要涉及到主機管理、應用管理、監控、報警平臺等設計,開發和運維這幾方面的工作。下麵簡單介紹一下我們的運維團隊。

-
第一個方面,我們的運維團隊負責公司所有的伺服器、網路等硬體平臺的運維工作;
-
第二個方面,部分人員從事日常運維,包括QVS的部署,Nginx的配置,應用上線的支援,還有儲存的部署等日常的運維工作,這些運維工作還包括報警的告知、故障的通報和跟蹤;
-
第三個方面,2013年左右我們開始研發自己的運維平臺;
-
第四個方面,負責公司內網的應用,這些內網包括OA系統、HR系統,還有IT資產管理平臺等等。
1、去哪兒網應用運維平臺介紹
首先簡單介紹一下去哪兒網應用運維平臺。

我們知道一個應用從開發到線上執行,它的生命週期主要涉及到四個部分:
-
第一部分,應用的資源管理,這些資源包括應用部署需要的主機、應用的圖片、檔案,物件儲存所需要的儲存資源,應用通訊和其他的網路頻寬,還有應用所需要的計算資源等等。
-
第二部分,為了提高應用開發的效率,並且去保證應用開發的規範,我們公司會提供公共的中介軟體,這些中介軟體包括日誌收集、應用配置註冊、監控報警指標的收集,還有應用呼叫路徑。
-
第三部分,為了將我們的應用釋出到線上,我們需要對應用進行程式碼管理和構建測試到釋出到線上,這需要 CI/CD 持續釋出和持續整合。
-
第四部分,當一個應用釋出到線上之後,我們需要對這個應用的效能指標和業務指標進行監控、報警和分析,這樣我們就需要大家應用相關的監控、報警和日誌分析平臺。
去哪兒網的業務也是一步步發展起來的,機器從幾十臺到上萬臺,在發展的過程中我們遇到了很多問題,在不同的階段我們也提出了不同的解決方案。
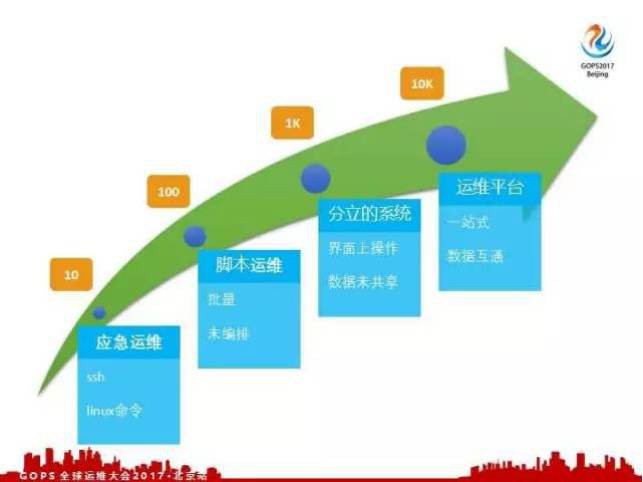
概括來說,去哪兒網經歷的階段分為四個部分:
-
第一個階段,運維機器數量比較少,大部分的工作都是應急運維。比如我們發現一個應用有問題了,我們登入到這個應用的相關機器上,手動執行Linux命令,去檢視這個機器的資源使用情況。比如CPU是不是太高了,是不是磁碟佔滿了,這個階段也沒有用到太複雜的指令碼,基本上都是手動操作,幾十臺左右。
-
第二個階段,隨著規模擴大,手動寫了很多指令碼,有了這些指令碼之後我們就可以批次去執行任務,可以在多臺機器上批次部署應用和監控。這個階段,我們稱為指令碼運維的階段,這個階段我們是利用指令碼並且結合開源的系統,我們可以完成對數百臺機器的運維。
-
第三個階段,隨著規模越來越大,指令碼運維也不夠了,指令碼運維遠遠不能滿足,指令碼可能都是分類的指令碼,並沒有經過合理的編排,這樣指令碼的執行順序就比較重要,沒有合理編排可能會導致一些問題。
我們開發一些相關的系統,用系統把相關的指令碼串聯起來,編排好組成一個一個分離的操作。比如說一臺機器的新建和刪除就是單獨的操作,把這些做成系統,運維人員可以在介面上操作。
這個階段,稱之為分立系統,他們的資料基本上在各個系統之間沒有實現一個比較好的共享。這個階段能運維的主機數量也比較有限,數千臺的主機是比較好的。
-
第四個階段,緊接著去哪兒網的機器規模突破了萬臺以上,這時候我們考慮能不能從一個比較高的角度去合理設計一下我們的運維平臺。為我們的運維工作提供一站式的服務,在一站服務的基礎上我們實現資料互通,這樣就可以互動起來,做一些自動化的工作。在這個時期也是今天我主要要講的內容,就是運維平臺的建設。
2、應用運維平臺的三個關鍵點
運維平臺的建設過程中我們遭遇了很多困難也遇到了很多坑,在這些困難之中總結出來三個關鍵點,主機管理、監控報警和資料互通。
2.1 主機管理

去哪兒網的主機管理系統是以 OpenStack 和 DNSDB 為核心的, OpenStack 是排程建立虛擬機器, DNSDB 是我們公司的域名管理系統。透過 DNSDB 我們就可以將一個機器的名稱、部門、用途和它所在的機房組成一個唯一的域名,我們用這個唯一的域名來標識我們這臺主機。
在 OpenStack 、 DNSDB 之上,我們寫了大量的指令碼檔案和工具,將這些指令碼檔案和工具編排起來,封裝成一個一個的操作,並且我們給這些操作賦予一些相關的許可權。我們把主機的資訊、流通的管理、許可權的配置還有操作日誌的查詢都會存在日誌庫裡。最後我們會把一個主機管理系統的介面暴露給運維人員,運維人員透過這個介面來管理我們的主機。
有了主機管理平臺之後,運維人員就可以非常方便的在這個平臺上建立、銷毀主機,檢視主機的相關資訊,比如說它的配置、過保資訊等等。我們在新加每臺機器的過程中都會預設給這個機器加上監控報警,機器有報警的時候也會通知到相關的負責人。
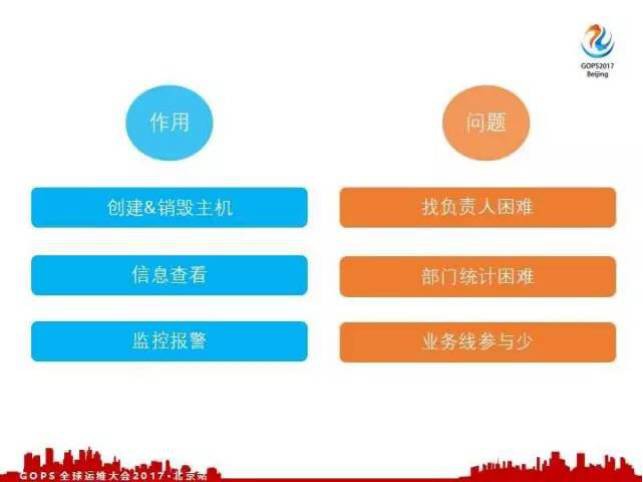
這樣做其實還是有一個問題,一個比較大的問題是,我們這個系統是怎麼開發給運維人員使用的,開發人員並沒有許可權登入這個系統。假如說開發人員提出來一個需求,我要建立一臺主機,就需要給OPS發郵件,OPS建立這臺主機的時候,其實並沒有非常準確的記錄到這個負責人是誰,他可能會寫在備註裡,這個備註隨著時間的推移,有可能不準了。因為當時的負責人可能離職了或者轉崗,這種情況都是經常發生的。
這個機器所負責的部門也沒有去很好的記錄,因為這個部門很多隻是體現在主機這個名稱上,但是有可能這臺機器在使用的過程中可能會轉給其他業務線的部門使用,這樣我們拿到的部門資訊也是不準確的。還有一個問題DB系統只對運維人員開放,業務線參與很少,導致整個主機的相關資訊其實是不夠準確的,因為OPS人員畢竟有限,不可能非常準確的維護這些資訊。
這樣我們就想到一個方案,透過應用樹去解決。
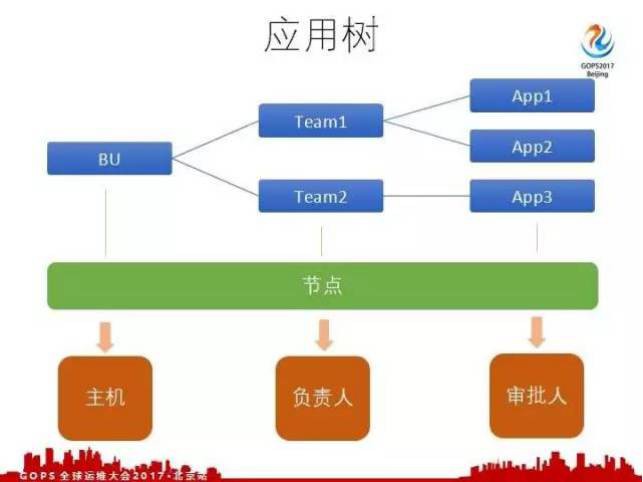
去哪兒網把業務線按照功能區劃分到各個BU,應用樹BU作為第一級,下麵有部門,部門下麵還有更小的部門,這個層級可能是多個的。最後一級是部門下麵所負責的應用,應用是作為最後一級的。我們把所有的級別都作為一個節點,在每個節點上都可以系結主機,給節點新增負責人,給節點新增審批人,下麵我會介紹審批人的許可權和角色。有了這個應用樹之後,業務線開發參與進來,參與管理主機,他們的負責人和部門資訊更加準確。
一臺機器出現異常,我想非常迅速找到這個機器的負責人也非常容易。假如說宿主機馬上要過保了,它上面的所有的虛機我都需要找到這個虛機的負責人,通知這些人去執行相關的操作,比如像虛機下線、應用下線,這樣可以避免很多運維宿主機過保而導致的故障。因為機器的負責人比較精確了,我們的報警通知會預設把機器的監控報警都通知給相關的負責人,由負責人來處理機器相關的基礎硬體報警。
每個季度都會統計資源的消耗,也會對下個季度機器的採購做規劃和預算。拿到比較上級的部門,比如拿到一個BU節點,可以透過應用樹很容易拿到這個部門下都有哪些機器,他這個月的增長量是多少,我們就可以很方便的預測下個季度我們需要採購多少量的機器,從而制定更加合理的預算。有了使用者之後,負責人、部門和機器的關係都是比較明確的。
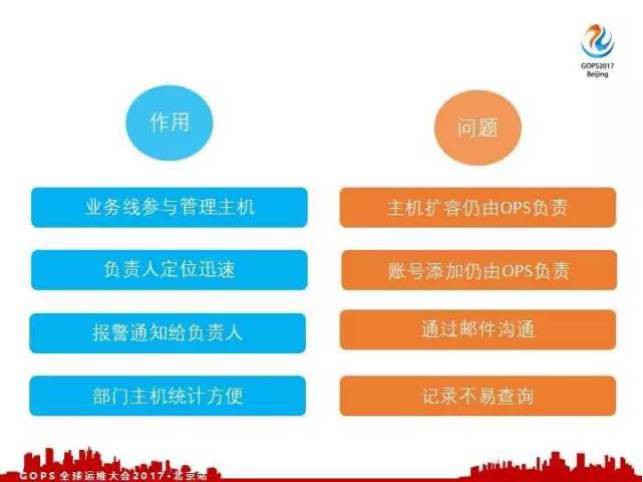
但是存在一個問題,申請資源的時候,仍然需要有OPS操作的,賬號新增也是由OPS負責,一個開發人員想要擴容一臺機器或者給一個機器去新增賬號,要怎麼做?他就需要給操作OPS的 team 發郵件,說我要給應用擴容兩主機,或者給哪臺主機新增一個賬號。這樣做有什麼壞處,一是OPS不可能實時線上也不可能盯著系統,這樣OPS響應非常慢,郵件查詢起來非常不方便,郵件時間長了可能丟失,定位問題也不容易。
怎麼解決這個問題接下來又做了兩個系統,第一個是主機申請系統,第二是賬號申請系統。
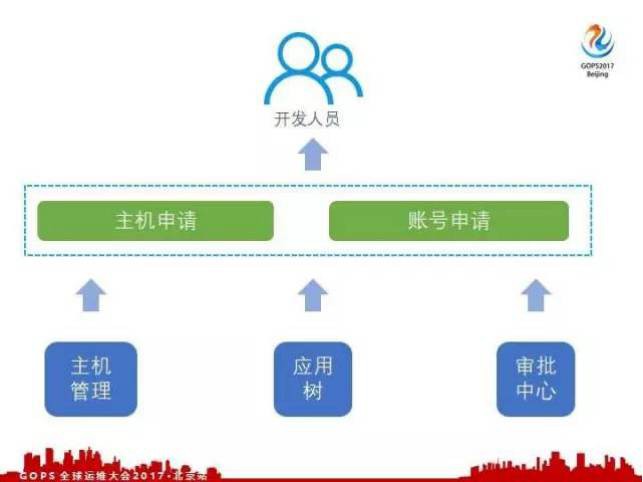
這兩個系統以主機管理、應用樹和審批中心為基礎,呼叫主機管理、應用樹和審批中心為介面,透過呼叫介面去編排一些合理的主機申請和賬號申請的流程。剛才我們提到主機申請的時候,誰有許可權申請,應用樹上的每個節點的負責人都有許可權去申請這個部門的主機或者這個應用的主機,節點上的審批人他就有許可權去審批這個節點下的主機。這樣OPS就不用參與太多,他們可以自動申請主機和賬號。
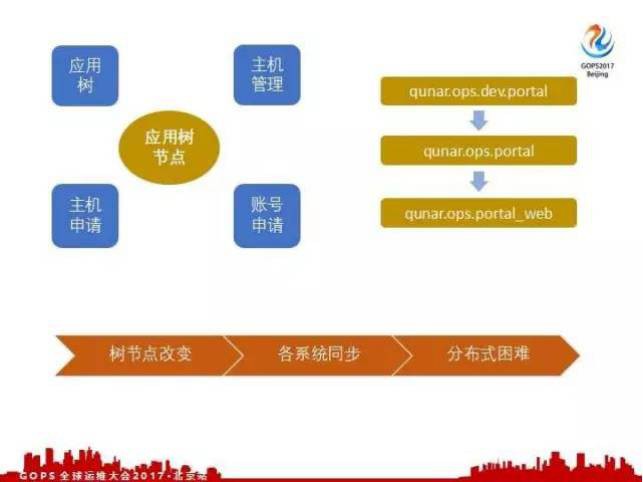
最後我們做了一個介面,把這個介面暴露給開發人員,開發人員可以去申請主機申請賬號。透過應用樹、主機管理、主機申請、賬號申請這四個平臺做了閉環,核心是應用樹節點,應用樹節點把四個部分串聯起來。
應用樹節點有什麼問題,我們會改變它,比如剛開始有個 portal 應用放在OPS開發下,有一天發現這個放的位置不太對,需要直接放在OPS下麵就可以了,這樣就需要把 portal 從運維開發移動到OPS下麵。
還有一個, portal 隨著業務增長,應用越來越大,需要拆分成幾個部分,比如需要拆分成 portal-web 和 portal-api ,這種樹節點改變會導致什麼?我們每個系統記錄的都是應用樹節點,每個應用樹節點的改變各個系統都需要去同步,這就相當於在一個分散式系統裡有一個有狀態的模組,就是應用樹節點這個模組。其實它是有狀態的,有狀態就導致我們分散式比較困難,我們想把應用樹節點推廣到更多的系統中,那就會非常困難,就會不斷面臨同步的問題。
這個問題怎麼解決,比如說對於一個普通的居民來說,怎麼在各個系統之間共享資料,比如我一個人怎麼在公安系統在戶籍系統在銀行系統等等各個系統之間,怎麼樣共享我的資訊。現實中就有一個非常好的實踐,那就是使用身份證,身份證有唯一的ID,透過這樣一個唯一的ID,就可以標識這個應用,並且這個ID永遠不會改變。

我們怎樣去找到這樣一個ID,第一個方案,用資料庫裡的自增ID或者 UUID 來標識應用。這樣可以保證應用ID唯一且不改變,但是因為自增ID和 UUID 在文字上沒有明確意義,我們開發人員拿到這個ID不便於記憶,也不便於溝通。
假如要用自增ID或 UUID ,需要用另外一個系統去專門看我有多少這樣的ID,先找到這個ID,再和其他系統進行互動、溝通,非常不方便。第二個方案,借鑒身份證,用數字,比如110代表北京,後面代表縣區,代表自己的出生日期。
借鑒身份證ID,我們使用了這樣一個叫 Appcode 的來標識應用, Appcode 基本上以下滑線分割的,第一個是應用所在的部門,第二個是應用的描述,這個層級也可以非常長。用這樣一個 Appcode 去代替應用數節點,既能保證唯一且不可改變,便於大家記憶,溝通也比較方便,我們最後選的是第二套方案。
2.2 監控報警
下麵看一下我們是怎麼在運維平臺去做監控報警的。作為一個網際網路公司,保證7×24小時的提供服務是一個最基本的要求,我們要怎麼去保證7×24小時服務?假如說系統有問題的時候,我們能夠提前預警發現,等系統真正出現問題的時候,我們能夠及時的發現。要保證這兩點,我們就需要監控報警系統。

去哪兒網的監控報警系統也是經歷了很長時間的掙扎,剛開始每個部門都會維護著自己一套系統,剛開始是 Cacti 和 Nagios 這兩個模組去搭建的,這樣存在什麼問題?

-
第一Cacti 部署在單機上,不能橫向拓展,導致效能比較差。假如單機出現異常甚至宕機,那我們的監控報警系統就完全不可用,所以這是一個非高可用的方案。
-
第二是每個部門都會維護一套自己的監控系統,甚至比較大的部門,像酒店機票這種大部門,他們可能會維護很多套,每一套都需要有專門的人員來運維,運維成本也非常高。
由於之前的系統沒有很好的許可權管理,這個系統只能有專門的人來負責,因為放開給其他人許可權是比較危險的,可能有人不小心操作了什麼,把報警刪掉或者修改報警配置,所以只有把報警交給專人負責。
要定製一個報警監控溝通成本非常高,我們需要聯絡自己的相關負責人,然後再去報警配置。開發人員覺得太麻煩了,乾脆不做了,或者做得非常少,導致我們監控的面不夠全,可能有一些異常甚至是故障都沒有及時發現,效率是比較低下的。怎麼解決這個問題?我們做了一個公司級的統一監控報警平臺 Watcher 。有這樣幾個標的:
-
第一是高可用,一臺機器或幾臺機器掛了,對我們沒有影響或者影響很小。
-
第二是比較容易的讓大家去配置這個報警,我們做了一個許可權管理系統,也是借鑒應用樹做了一個樹狀的許可權管理系統,把整個 Watcher 介面開放給所有的開發人員,這樣大家就可以非常方便的配自己的報警和監控。

簡單介紹一下 Watcher , Watcher 是基於 Graphite 深度開發的, Watcher 平臺既支援主機基礎監控報警同時也支援業務監控報警,都在一個統一的平臺上,監控報警可以由開發人員在統一的介面上檢視和配置。
Watcher 大概2014年開始做,現在有三年時間,在公司也推廣得很好。現在 Watcher 已經接入1500個以上的應用, Watcher 目前的指標數量已經超過了2000萬,報警數量已經超過了40萬,接入了基礎監控的機器數量也超過了4萬臺。 Watcher 這麼大的規模,我們用了什麼樣一個架構呢?
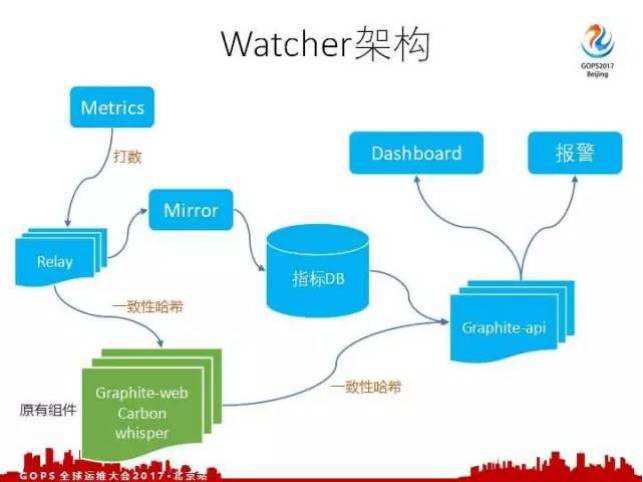
這個架構圖只是我們一個 Watcher 叢集的架構圖,我們在打數的時候會區分每個指標要打到哪個叢集上,我們怎麼區分?以 Metrics 作為標識,比如所有的測試資料測試指標都以t開頭,所有的主機資料都以h開頭,我們用s.flat就代表機票這個部門,機票這個部門所有指標打數的時候就要配置好一個伺服器,這個伺服器也是用域名來表示的,它自己本身就代表一個機票的監控報警叢集。
在上面的叢集架構圖裡,最下邊綠色的是 Graphite 原有的元件,在原有元件上我們自己開發了幾個相關的元件。第一個是 Relay ,每個指標打過來之後,我們透過 Relay 把指標分佈在多臺機器上,這個是透過一致性雜湊來實現的。
等我們取數的時候, Graphite-api 這部分也是我們自己開發的, Graphite-api 裡也有同樣的一致性雜湊演演算法,透過這個演演算法找到這個指標在這個叢集的哪一個機器上,呼叫這個機器上的 Graphite-web 下的api,然後拿相關的資料。
這是一個叢集的架構,有多個叢集,我們 Watcher 要做一個統一的介面,在這個介面上配置自己的監控的時候,選擇資料源,對於打數的人他清楚這個指標在什麼地方。能不能做一個統一的資料源,讓使用者來使用,這樣我們就在元件裡加上了一個純指標的資料庫,每次流量過來之後,我們就會把這個指標的名稱寫到我們資料庫裡一份,同時記錄它在哪個叢集。
這樣我們就可以對外報一個統一的 Graphite-api ,假如說一個指標我們要起 s.flat-xx 的指標,首先是呼叫api,去找 s.flat-xx 這個指標在什麼集群裡,發現在機票的集群裡,再透過一致性雜湊就可以把這個指標取出來了。 Graphite-api 上第一部分是借這個 Dashboard ,是借這個報警。
講完整個的 Watcher 架構,看一下主機監控怎麼做的?
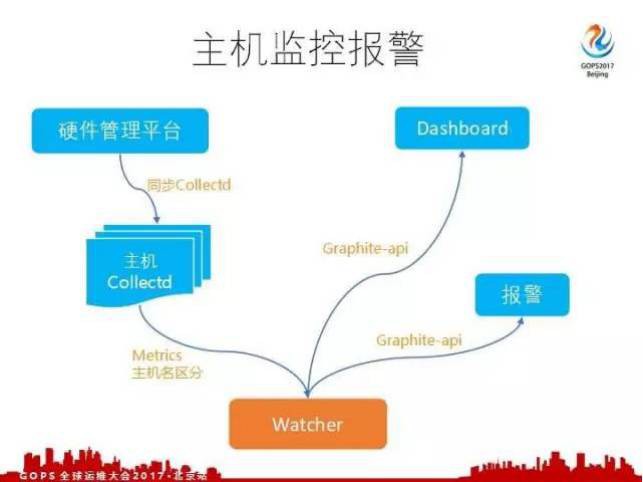
首先有一個硬體管理平臺,維護著主機監控的相關資訊。最主要的是會編排代理,去維護代理的版本配置,會不停的去掃描這個主機,往主機上部署,也會定時檢查指標是否收集了。假如這個主機指標出現斷點了或者有問題了,會報警去檢查,到底是 Collectd 出問題了還是系統出問題了還是網路出問題了。
每個主機上部署 Collectd 之後會根據不同的配置打不同的指標,比如CPU的使用情況,記憶體的使用情況,網路頻寬的使用情況,這些都將指標打成了 Watcher 。每個主機的指標可能都是相同的,怎麼區分不同主機的指標,我們就以主機的名稱作為區分。接入到 Watcher 之後,我們就可以呼叫api,在 Dashboard 上呼叫。

業務監控也是比較類似的,應用接入之後會暴露出api,裡面就是最近1分鐘之內應用的監控資料,每分鐘 Qmonitor server從所有的機器上去拉這個檔案,拿了檔案之後做集中的分析,分析完之後做相應的處理。比如說對應用進行計數,算完之後以 Appcode 作為標識來區分不同的指標,將指標推送到 Watcher 。推送到 Watcher 之後,同樣可以查詢監控,檢查應用指標的健康狀態。
2.3 資料互通
下麵講一下我們怎麼在整個運維平臺實現資料互通的。我們在監控報警和主機管理裡都提到了一個 Appcode ,在去哪兒網 Appcode 到底是什麼?

其實它就是唯一的一個標識應用,我們將一個應用進行了抽象化,意思其實是更加廣義。在去哪兒網一個應用可以是一個Web服務,也可以是一個GPU雲實體,也可以是 MySQL 實體,甚至可以是一組交換機,還可以是其他的。

為什麼要對應用做這樣的抽象化,做抽象化的好處就是我們不用去考慮服務和資源的具體細節,就用一個App代表一個服務或者代表一個資源,在這個抽象化的過程中可以不考慮這個服務到底做什麼,這個資源到底什麼樣。給廣義的應用定義共同的屬性,包括這個應用的負責人、應用的許可權、應用的賬單等等。
有了這些共同的屬性,我們就可以將 Appcode 在多個系統中進行擴充套件,分佈在各個系統中去共享資料。這樣做的作用是什麼?有了 Appcode 之後,我們就可以在我們的各個系統中形成一種共同的語言,這個共同語言就是 Appcode 。有了這個共同語言之後,我們就可以把各個系統之間的資料連線起來,最後實現一個資料的互通。實現資料互通之後有什麼好處?
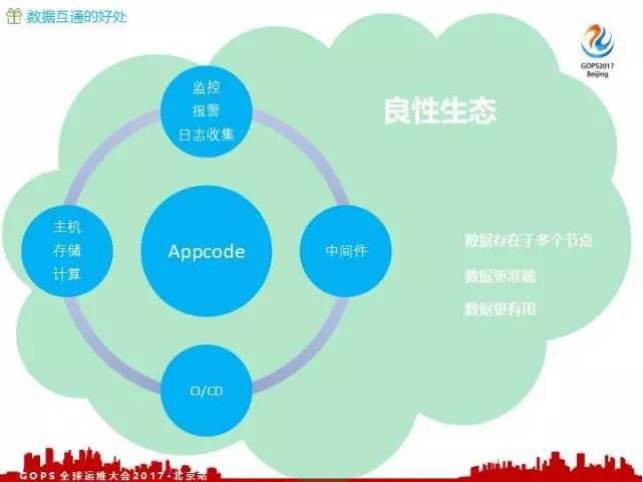
-
第一個方面,我們把 Appcode 放在各個系統之中監控,比如說主機、儲存、計算,這是應用的資源部分。 Appcode 分佈在多個系統之中,多個系統中相互作用,一個資料只有分佈的節點越多,對這個資料的準確性要求越高,因為這個資料可能在多個系統間使用,它的負責人就會更加重視這份資料,所以他們更願意讓這個資料變得更加準確。
資料更準確之後,它就變得更加有用,各個系統之間因為資料準確了,都願意使用這份資料,形成比較良性的生態迴圈。因為資料互通了,我們就可以做一個 Portal 平臺,對外暴露一個統一的介面,可以對我們應用所涉及的所有部分進行一站式管理。
Portal 平臺簡介
簡單介紹一下 Portal 平臺,現在也是正在開發中的平臺。

Portal 就是以 Appcode 為基礎,在 Appcode 的基礎上連線了各個運維繫統,比如說主機、賬號、GPU雲、ES雲,應用註冊、應用配置、應用中介軟體,環境配置、程式碼倉庫、測試、釋出、監控、報警、日誌收集,故障管理。我們把這些系統都彙總到一個 Portal 介面上暴露給開發人員,開發人員進入這個系統之後就可以一站式的把應用相關的想做的事情都做完,這樣開發人員也非常方便。

資料互通另外一個好處,剛才講主機管理,主機可能會有不同維度來解釋這個主機是不太一樣的。比如應用釋出,有釋出主機串列,算賬單的時候有個賬單主機串列,收集日誌的時候也有主機串列,收集監控報警也有主機串列。
只要資料互通之後,我們就可以將這些資料串聯起來。比如我們應用,它的主機需要擴容了,擴容兩臺主機,擴容之後我們就可以自動根據這個應用上的負責人去為主機新增對應的賬號,這樣它的負責人就可以利用這個賬號登入相應的系統,進行相應的操作。
資料庫還有其他的有IP白名單限制,有了資料互通之後,一個應用它的白名單配置就沒必要記錄每一個主機了,就記錄 Appcode 就可以了。
-
第二是CI/CD部分,應用釋出的主機也是和 Appcode 相關聯的,應有擴容之後釋出的主機也是同樣同步過來,釋出選擇這些主機直接釋出就可以了,不需要手動再在去填寫這些主機串列。
-
第三是監控分為兩個方面,一個是基礎監控,一個是業務監控。基礎監控也是透過 Appcode 維度可以檢視相關的主機的基礎監控。對於業務監控在應用監控指標的收集,也可以透過 Appcode 來拿到它的主機串列,自動去給業務監控指標收集新增這些機器串列,新增完之後收集上來這些應用相關主機的監控指標和日誌。
-
第四是報警系統,因為有了 Appcode 之後, Appcode 它會對應著一些共同的監控報警項,比如像 JAVA 裡的GC報警。我們有了 Appcode 之後,就可以給每個 Appcode 上的所有機器都預設新增GC報警。這個GC報警聯絡人就是 Appcode 一個負責人,每臺機器擴容之後它的GC報警也就自動添加了。日誌收集也是一樣的,之前我們可能還是需要在這個平臺手動維護,有了 Appcode 就可以同步這個串列。
資料互通還有另外一個好處,有 Appcode 之後我們就可以非常方便的去計算這個應用所耗費的賬單。為什麼要計算一個應用的賬單?
一方面,讓我們提高一下成本意識,成本意識在選的過程中也是需要考慮的。比如一個業務線它有一些資料需要記錄下來,它可以選擇任何系統,也可以選擇資料庫,也可以選擇 Watcher 。假如說這個業務訪問的頻率非常低,比如一天就幾次、十幾次,把這個資料記錄到 Watcher 其實成本非常高昂,因為 Watcher 資料膨脹非常厲害,選擇資料庫或者日誌其實更划算。
第二可以最佳化實現,假如你由於演演算法導致機器資源大量使用,有了賬單之後,他們會去節約成本。有了成本意識之後,我們可以更加合理的分配資源。比如有的應用本身不是很重要,還申請了特別多的機器,機器使用率也不高,拿到賬單一看,這麼一個不重要的應用竟然耗費這麼大的賬單,然後他們就會回收一部分。
目前我們也在不斷的去接入各種各樣的應用賬單,比如說主機賬單、網路頻寬賬單、監控報警、日誌收集、大量的儲存,還有計算資源賬單,還有其他的一系列的賬單,都會慢慢接入進來。
3、總結
最後做一下總結,在去哪兒網運維自動化歷程中,我們經歷了不同的階段。我們發現等應用擴大到一定規模的時候,需要運維平臺化,自動的或者半自動的方式是非常耗費人力資源的,並且它也會大致發現一些錯誤甚至是故障。去哪兒網運維自動化也是做得非常不錯的,怎麼來體現?
我2013年入職,我入職的時候日常運維的人員大概有五六個,現在我們日常運維的人員仍然是六個,我們又推了一個運維機器人,運維第七人。我們其實還是保持在六人的狀態,我們規模擴大了很多倍,從百臺到萬臺,擴大了上百倍的規模,但是我們日常運維人員並沒有增加,這是運維平臺自動化帶來的好處。
應用的可用性需要監控報警系統的保證,基本上在一個應用上線之前就會去把它所有關鍵的報警和監控架好,這樣應用有問題的話就會迅速回滾或者去 debug 。因為我們有完善的監控報警系統,所以去哪兒網的故障還算比較少的,平均來說一天也就兩三個故障。
但是去哪兒網的故障和其他的故障可能不太一樣,去哪兒網的故障要求比較苛刻,一次網路故障我們就會記錄批次的故障。比如 Watcher 的監控系統不出圖了,超過5分鐘了,我們可能會深究P1和P2的故障。在這樣的嚴格要求下,我們的故障也不會太高,我入職四年來,現在累計的故障數也就3000個左右。

要保證我們整個運維生態的發展,我們需要將資料打通,打通需要給應用一個ID,有了這個ID之後,我們就可以在各個運維繫統和平臺上共享資料,形成一個良性的生態迴圈。
END
●本文編號133,以後想閱讀這篇文章直接輸入133即可
●輸入m獲取文章目錄

Linux學習
更多推薦《18個技術類微信公眾號》
涵蓋:程式人生、演演算法與資料結構、駭客技術與網路安全、大資料技術、前端開發、Java、Python、Web開發、安卓開發、iOS開發、C/C++、.NET、Linux、資料庫、運維等。
