作者:託馬茲·卓巴斯(Tomasz Drabas)
如需轉載請聯絡大資料(ID:hzdashuju)
本文的原始碼與資料集都可在Github上獲取。如果要複製程式碼庫,開啟你的終端(Windows環境下的命令列、Cygwin或Git Bash,Linux/Mac環境下的Terminal),鍵入下麵這條命令:
git clone https://github.com/drabastomek/practicalDataAnalysisCookbook.git
註意,你的機器得裝好Git了。安裝指南參見:
https://git-scm.com/book/en/v2/Getting-Started-Installing-Git
本文將使用一個資料集,包含985項真實的房產交易。這些交易是連續5天內在Sacramento發生的。資料下載自:
https://support.spatialkey.com/spatialkey-sample-csv-data/
精確地說,來自:
http://samplecsvs.s3.amazonaws.com/Sacramentorealestatetransactions.csv
資料已轉成多種格式,放在GitHub程式碼庫的Data/Chapter01檔案夾中。
01 使用OpenRefine開啟並轉換資料
OpenRefine誕生時被稱作GoogleRefine。Google後來開放了原始碼。這是個優秀的工具,可用於快速篩選資料、清理資料、排重、分析時間維度上的分佈與趨勢等。
在接下來的技巧中,我們將處理Data/Chapter1檔案夾下的readEstate_trans_dirty.csv檔案。這個檔案有些問題,我們會看到解決辦法。
首先,從文字檔案中讀取資料時,OpenRefine預設轉為文字型別;本技巧將進行資料型別轉換。否則沒法針對性地處理數字列。
其次,資料中有重覆(下文“排重”部分會處理這個問題)。
再次,city_state_zip列,顧名思義,是市、州、郵編的混合體。我們還是希望拆分它們,在下文“用正則運算式與GREL清理資料”中,我們將看到如何提取這些資訊。交易價格也有缺失—我們將在“估算缺失值”中估算這些價格。
1. 準備
要完成這些例子,你得在你的計算機上安裝OpenRefine並能正常執行。OpenRefine可從這裡下載:
http://openrefine.org/download.html
安裝指導在:
https://github.com/OpenRefine/OpenRefine/wiki/Installation-Instructions
OpenRefine在瀏覽器中執行,所以你的計算機中得有一個瀏覽器。我在Chrome和Safari上測試了,沒發現問題。
Mac OS X Yosemite預裝了Java 8。但OpenRefine不支援。你需要安裝Java 6或7—參考:
https://support.apple.com/kb/DL1572?locale=en_US
然而,即便安裝了Java的歷史版本,我依然在Mac OS X Yosemite和El Capitan系統中遇到了2.5版OpenRefine的問題。使用beta版(2.6),雖然還在開發中,卻能正常使用。
2. 怎麼做
首先啟用OpenRefine,開啟瀏覽器,輸入:
http://localhost:3333
會開啟類似下圖的視窗:

你要做的第一件事就是建立一個工程。單擊Choose files,進入Data/Chapter1,選中realEstate_trans_dirty.csv。單擊OK,然後Next,最後Create Project。資料就開啟了,你會看到類似這個的介面:

註意beds、baths、sq__ft、price、latitude以及longitude資料都被當成文字處理,sale_date也是如此。用OpenRefine,轉換前面那些欄位容易,轉換sale_date可就沒那麼容易了:
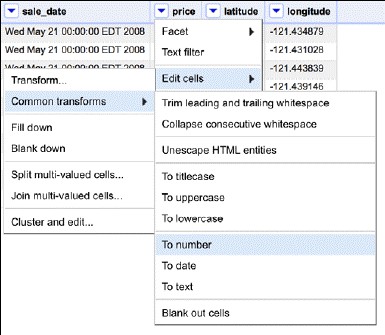
舉個例子,如果文字資料的格式類似2008-05-21這樣,我們只需呼叫GREL(Google Refine Expression Language)的.toDate()方法,OpenRefine會替我們轉換好。本例中正確轉換日期需要一些小技巧。首先選中Transform選項,如下圖所示:
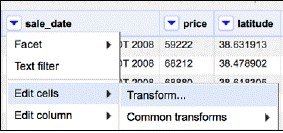
在開啟的視窗中,使用GREL轉換日期:
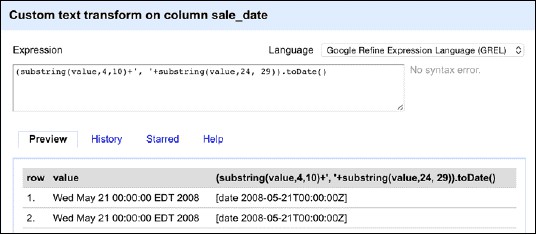
這裡的value變數代表選中列(sale_date)中每個單元格的值。運算式的第一部分從值中提取出月份和天數,也就是說,我們擷取第4個到第10個字元的子字串,得到May 21。
第二個substring(…)方法從字串中提取出年份。使用…+’,’+…運算式將兩塊以逗號分隔。最後得到May 21, 2008這樣的格式。這就方便OpenRefine處理了。也就是說,我們用括號包裝兩個substring方法,並使用了.toDate()方法,以正確轉換日期。右邊的Preview標簽頁會展示運算式的效果。
3. 參考
Ruben Verborgh和Max De Wilde合著的《Using OpenRefine》從各方面介紹了OpenRefine,深入淺出,娓娓道來:
https://www.packtpub.com/big-data-and-business-intelligence/using-openrefine
02 使用OpenRefine探索資料
理解資料是建立成功模型的前提。對資料做不到瞭如指掌,你建立的模型就可能在紙面上很美,卻在生產環境中大錯特錯。探索資料集是檢測資料是否有問題的一個好辦法。
1. 準備
要學習本技巧,你需要在計算機上裝好OpenRefine以及一個瀏覽器。至於如何安裝OpenRefine,參閱本文01部分的準備部分。
我們假設你使用了前一技巧,所以你的資料已經載入到OpenRefine,且資料型別代表著列中的資料。
2. 怎麼做
有了Facets,用OpenRefine探索資料就簡單了。一個OpenRefine Facet可以理解成一個過濾器:它讓你快速地選擇某些行,或直接探索資料。每一列都可以建立一個facet—只消單擊列旁邊的下拉箭頭,選單中選Facet組。
OpenRefine中有四種基本的facet:文字、數字、時間線以及分佈圖。
你可以自行定製facet,或者使用OpenRefine工具庫中複雜一些的facet,比如詞或文字的長度。
文字facet可以讓你快速地對資料集中文字列的分佈有一個感覺。比如,我們可以找到資料集中,2008年5月15日到5月21日之間銷售額最高的是哪個城市。
聰明的你一定猜到了,既然我們一直在分析Sacramento的資料,那估計就是Sacramento了吧,的確是這樣,其後是Elk Grove、Lincoln、Roseville,如下圖所示:
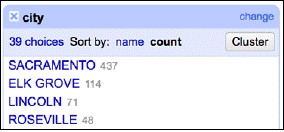
這讓你對資料是否合理有一個直觀的感受;可以充分判定提供的資料是否符合假設。
數字facet可以讓你粗略瞭解數字型資料的分佈。比如,我們可以檢查資料集中價格的分佈,如下圖所示:
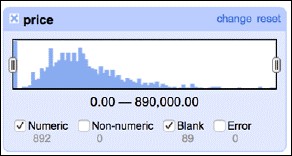
價格的分佈大體上如我們所料:左傾的分佈是合理的,落在右端的交易較少,因為那部分是有意願也有能力購置大莊園的買家。
這個facet也發現了我們資料集的一個不足:在價格列缺少89份數值。本文後面第05節中將解決這個問題。
在已知拿到7天(2008年5月15日至5月21日)資料的情況下,檢查交易的時間線是否有空白也是個好辦法:
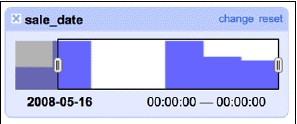
我們的資料橫跨了7天,但我們發現兩天沒有交易。翻下日曆就會發現,5月17號、18號是週末,這裡沒啥問題。時間線facet允許你使用左右兩邊的滑動條過濾資料:這裡我們過濾出2008年5月16日之後的資料。
散佈圖facet能分析資料集中數字型變數間的相互作用:
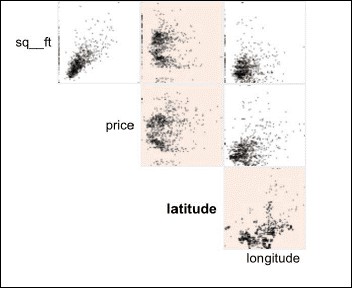
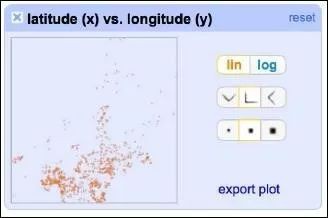
單擊某一行和列可以詳細地分析相互作用:
03 排重
我們應該預設待處理的資料是有瑕疵的(除非能證明沒有)。檢查資料是否都整理好了是一個好習慣。我首先檢查的總是重覆行。
1. 準備
要學本技巧,你需要在計算機上裝好OpenRefine以及一個瀏覽器。
我們假設你應用了前一項技巧,所以你的資料已經載入到OpenRefine,且資料型別與列中的資料相符。
2. 怎麼做
我們先假設7天的房產交易中,出現同樣的地址就意味著有重覆的行。這麼短的時間週期內,同一套房子不太可能被賣兩回。所以,我們在重覆的資料上Blank down:
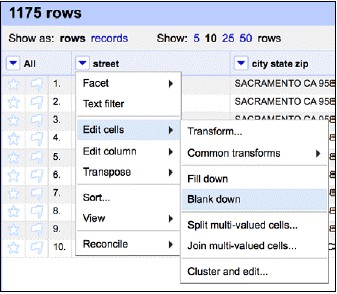
這樣做的效果就是保留了資料的第一次出現,而將重覆出現的置為空白(截圖中第四列):
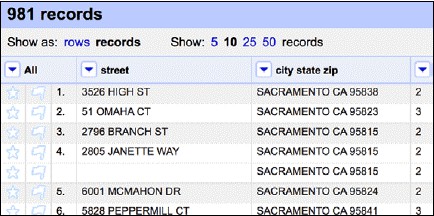
Fill down選項效果相反—它會用上一行的資料填補空白,直到出現新的資料。
現在建立一個關於空白的Facet,這樣我們可以快速選中空白行:
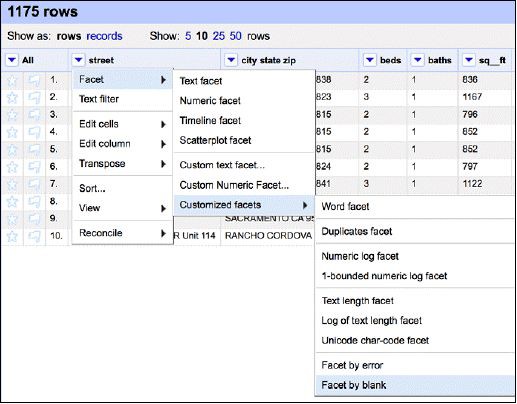
建立這樣的facet可以快速選中並移除空白行:
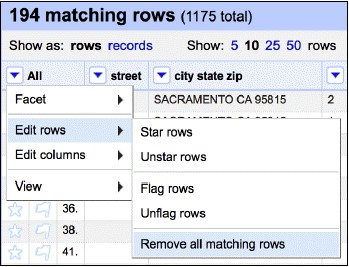
現在資料集中沒有重覆記錄了。
04 使用正則運算式與GREL清理資料
清理並準備使用資料時,可能需要從文字欄位中提取一些資訊。有些時候,我們只需要用些分隔符將文字欄位拆開。但當資料符合一些樣式,並不是簡單地拆分文字就能做到時,我們就需要求助於正則運算式了。
1. 準備
要學本技巧,你需要在計算機上裝好OpenRefine以及一個瀏覽器。
我們假設你應用了前一項技巧,所以你的資料已經載入到OpenRefine,且資料型別與列中的資料相符。此外沒有要求了。
2. 怎麼做
我們先看下city_state_zip列中的樣式。顧名思義,第一個元素是城市名,然後是州名,最後是5位數郵編。可以用空格作為分隔符拆分這個欄位。
這對很多記錄(例如Sacramento)都能起作用,而且其被解析成城市、州和郵編。不過這個方法有個問題—有些地名不止一個詞(例如Elk Grove)。這種情況下,我們就需要做些改變。
這就輪到正則運算式展示身手了。你可以在OpenRefine中使用它轉換資料。現在要將city_state_zip拆成三列:city、state和zip。單擊列名旁邊的向下按鈕,出來的選單中,根據情況選擇Edit column或Add column。會如下圖所示,出現一個視窗:
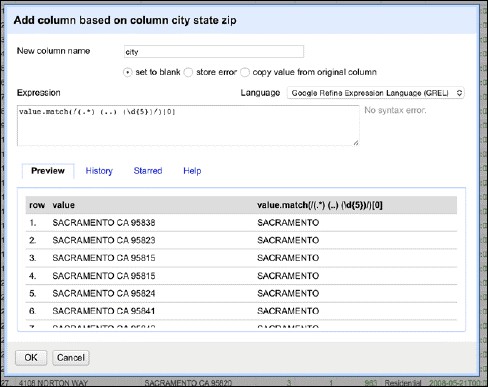
和以前一樣,值指的是每個單元格的值。.match(…)方法應用到單元格的值上。它以一個正則運算式作為引數,傳回的是匹配樣式的一列值。正則運算式被封裝在/…/之間。我們一步步解釋這個正則運算式。
我們知道city_state_zip列的樣式:首先是城市名(可能不止一個詞),然後是州名的兩字母縮寫,最後是5位數字的郵編。下麵給出了描述這個樣式的正則運算式:
(.*) (..) (\d{5})
從後往前理解這個運算式要容易些。首先用(\d{5})提取出郵編。\d表示任何數字(等價於([0-9]{5})),{5}從字串尾部開始選取5個數字。然後是(..)┐,用兩個點來提取州名的兩字母縮寫。註意我們為了閱讀方便,用┐替代空格符。
這個運算式提取兩個字元以及一個空格—不多,不少。最後(從右往左讀)是(.*),這可理解為:(如果有的話)提取出未被另兩個運算式匹配的所有字元。
總體上,這個正則運算式用普通話來表述就是:提取字串(即使是空的)中州名的兩字母縮寫(前面有一個空格),後面跟有一個空格和五位表示郵編的數字。
.match(…)方法生成一個串列。本例中得到的是包含三個元素的串列。要得到城市名,可以使用下標[0]獲取串列的第一個元素。要得到州名和郵編,可以分別使用下標[1]和下標[2]。
現在拆完city_state_zip列了,可以將工程匯出成一個檔案。在工具的右上角,你會看到Export按鈕;選擇Comma separated value。檔案預設下載到Downloads檔案夾。
3. 參考
強烈推薦Felix Lopez和Victor Romero合著的《Mastering Python Regular expressions》一書:
https://www.packtpub.com/application-development/mastering-python-regular-expressions
關於作者:託馬茲·卓巴斯(Tomasz Drabas),微軟資料科學家,致力於解決高維特徵空間的問題。他有超過13年的資料分析和資料科學經驗:在歐洲、澳大利亞和北美洲三大洲期間,工作領域遍及高新技術、航空、電信、金融和諮詢。
