
佔小狼【公眾號:佔小狼的部落格】 轉載請註明原創出處,謝謝!

前言
Java中volatile這個熱門的關鍵字,在面試中經常會被提及,在各種技術交流群中也經常被討論,但似乎討論不出一個完美的結果,帶著種種疑惑,準備從JVM、C++、彙編的角度重新梳理一遍。
volatile的兩大特性:禁止重排序、記憶體可見性,這兩個概念,不太清楚的同學可以看這篇文章 -> java volatile關鍵字解惑
概念是知道了,但還是很迷糊,它們到底是如何實現的?
本文會涉及到一些彙編方面的內容,如果多看幾遍,應該能看懂。
重排序
為了理解重排序,先看一段簡單的程式碼
public class VolatileTest {
int a = 0;
int b = 0;
public void set() {
a = 1;
b = 1;
}
public void loop() {
while (b == 0) continue;
if (a == 1) {
System.out.println("i'm here");
} else {
System.out.println("what's wrong");
}
}
}
VolatileTest類有兩個方法,分別是set()和loop(),假設執行緒B執行loop方法,執行緒A執行set方法,會得到什麼結果?
答案是不確定,因為這裡涉及到了編譯器的重排序和CPU指令的重排序。
編譯器重排序
編譯器在不改變單執行緒語意的前提下,為了提高程式的執行速度,可以對位元組碼指令進行重新排序,所以程式碼中a、b的賦值順序,被編譯之後可能就變成了先設定b,再設定a。
因為對於執行緒A來說,先設定哪個,都不影響自身的結果。
CPU指令重排序
CPU指令重排序又是怎麼回事? 在深入理解之前,先看看x86的cpu快取結構。
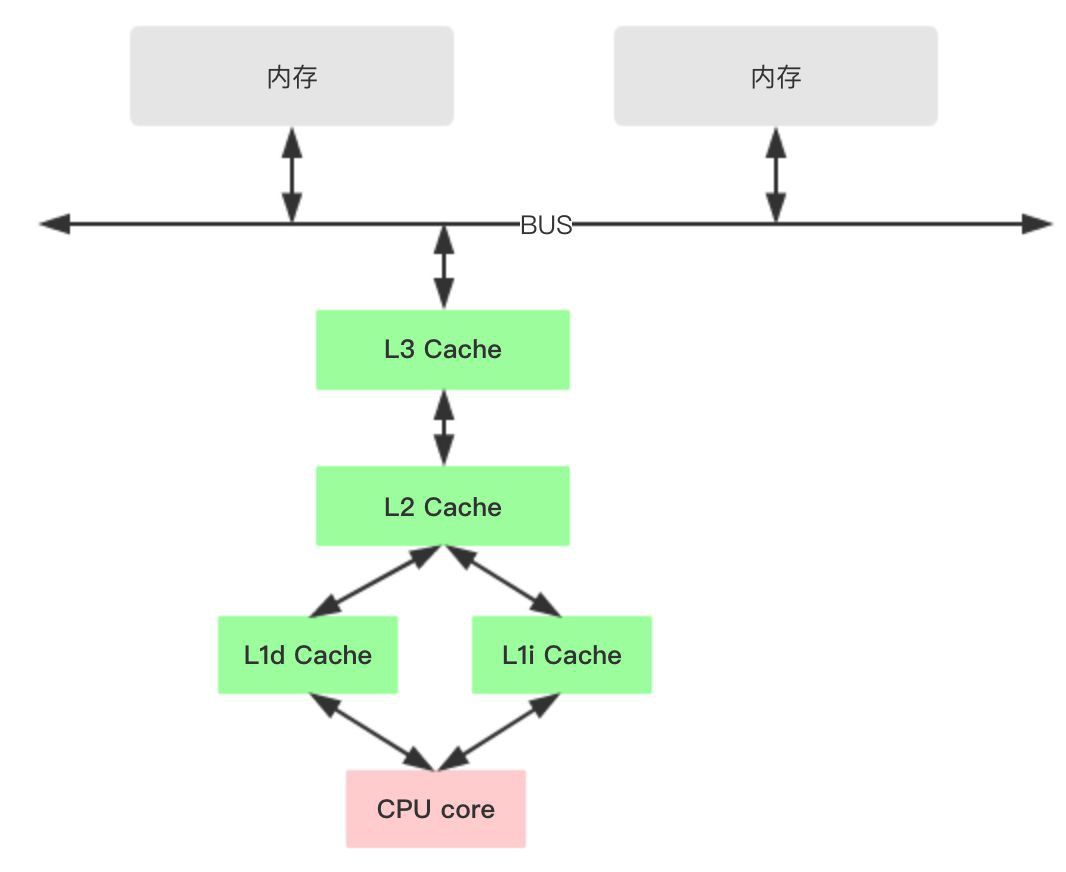
1、各種暫存器,用來儲存本地變數和函式引數,訪問一次需要1cycle,耗時小於1ns;
2、L1 Cache,一級快取,本地core的快取,分成32K的資料快取L1d和32k指令快取L1i,訪問L1需要3cycles,耗時大約1ns;
3、L2 Cache,二級快取,本地core的快取,被設計為L1快取與共享的L3快取之間的緩衝,大小為256K,訪問L2需要12cycles,耗時大約3ns;
4、L3 Cache,三級快取,在同插槽的所有core共享L3快取,分為多個2M的段,訪問L3需要38cycles,耗時大約12ns;
當然了,還有平時熟知的DRAM,訪問記憶體一般需要65ns,所以CPU訪問一次記憶體和快取比較起來顯得很慢。
對於不同插槽的CPU,L1和L2的資料並不共享,一般透過MESI協議保證Cache的一致性,但需要付出代價。
在MESI協議中,每個Cache line有4種狀態,分別是:
1、M(Modified) 這行資料有效,但是被修改了,和記憶體中的資料不一致,資料只存在於本Cache中
2、E(Exclusive) 這行資料有效,和記憶體中的資料一致,資料只存在於本Cache中
3、S(Shared) 這行資料有效,和記憶體中的資料一致,資料分佈在很多Cache中
4、I(Invalid) 這行資料無效
每個Core的Cache控制器不僅知道自己的讀寫操作,也監聽其它Cache的讀寫操作,假如有4個Core:
1、Core1從記憶體中載入了變數X,值為10,這時Core1中快取變數X的cache line的狀態是E;
2、Core2也從記憶體中載入了變數X,這時Core1和Core2快取變數X的cache line狀態轉化成S;
3、Core3也從記憶體中載入了變數X,然後把X設定成了20,這時Core3中快取變數X的cache line狀態轉化成M,其它Core對應的cache line變成I(無效)
當然了,不同的處理器內部細節也是不一樣的,比如Intel的core i7處理器使用從MESI中演化出的MESIF協議,F(Forward)從Share中演化而來,一個cache line如果是F狀態,可以把資料直接傳給其它核心,這裡就不糾結了。
CPU在cache line狀態的轉化期間是阻塞的,經過長時間的最佳化,在暫存器和L1快取之間添加了LoadBuffer、StoreBuffer來降低阻塞時間,Buffer與L1進行資料傳輸時,CPU無須等待。
1、CPU執行load讀資料時,把讀請求放到LoadBuffer,這樣就不用等待其它CPU響應,先進行下麵操作,稍後再處理這個讀請求的結果。
2、CPU執行store寫資料時,把資料寫到StoreBuffer中,待到某個適合的時間點,把StoreBuffer的資料刷到主存中。
因為StoreBuffer的存在,CPU在寫資料時,真實資料並不會立即表現到記憶體中,所以對於其它CPU是不可見的;同樣的道理,LoadBuffer中的請求也無法拿到其它CPU設定的最新資料;
由於StoreBuffer和LoadBuffer是非同步執行的,所以在外面看來,先寫後讀,還是先讀後寫,沒有嚴格的固定順序。
記憶體可見性如何實現
從上面的分析可以看出,其實是CPU執行load、store資料時的非同步性,造成了不同CPU之間的記憶體不可見,那麼如何做到CPU在load的時候可以拿到最新資料呢?
設定volatile變數
寫一段簡單的java程式碼,宣告一個volatile變數,並賦值
public class VolatileTest {
static volatile int i;
public static void main(String[] args){
i = 10;
}
}
這段程式碼本身沒什麼意義,只是想看看加了volatile之後,編譯出來的位元組碼有什麼不同,執行 javap-verboseVolatileTest 之後,結果如下:

讓人很失望,沒有找類似關鍵字synchronize編譯之後的位元組碼指令(monitorenter、monitorexit),volatile編譯之後的賦值指令putstatic沒有什麼不同,唯一不同是變數i的修飾flags多了一個 ACC_VOLATILE標識。
不過,我覺得可以從這個標識入手,先全域性搜下 ACC_VOLATILE,無從下手的時候,先看看關鍵字在哪裡被使用了,果然在accessFlags.hpp檔案中找到類似的名字。

透過 is_volatile()可以判斷一個變數是否被volatile修飾,然後再全域性搜"is_volatile"被使用的地方,最後在 bytecodeInterpreter.cpp檔案中,找到putstatic位元組碼指令的直譯器實現,裡面有 is_volatile()方法。

當然了,在正常執行時,並不會走這段邏輯,都是直接執行位元組碼對應的機器碼指令,這段程式碼可以在debug的時候使用,不過最終邏輯是一樣的。
其中cache變數是java程式碼中變數i在常量池快取中的一個實體,因為變數i被volatile修飾,所以 cache->is_volatile()為真,給變數i的賦值操作由 release_int_field_put方法實現。
再來看看 release_int_field_put方法

內部的賦值動作被包了一層,OrderAccess::release_store究竟做了魔法,可以讓其它執行緒讀到變數i的最新值。

奇怪,在OrderAccess::release_store的實現中,第一個引數強制加了一個volatile,很明顯,這是c/c++的關鍵字。
c/c++中的volatile關鍵字,用來修飾變數,通常用於語言級別的 memory barrier,在"The C++ Programming Language"中,對volatile的描述如下:
A volatile specifier is a hint to a compiler that an object may change its value in ways not specified by the language so that aggressive optimizations must be avoided.
volatile是一種型別修飾符,被volatile宣告的變數表示隨時可能發生變化,每次使用時,都必須從變數i對應的記憶體地址讀取,編譯器對操作該變數的程式碼不再進行最佳化,下麵寫兩段簡單的c/c++程式碼驗證一下
#include
int foo = 10;
int a = 1;
int main(int argc, const char * argv[]) {
// insert code here...
a = 2;
a = foo + 10;
int b = a + 20;
return b;
}
程式碼中的變數i其實是無效的,執行 g++-S-O2 main.cpp得到編譯之後的彙編程式碼如下:
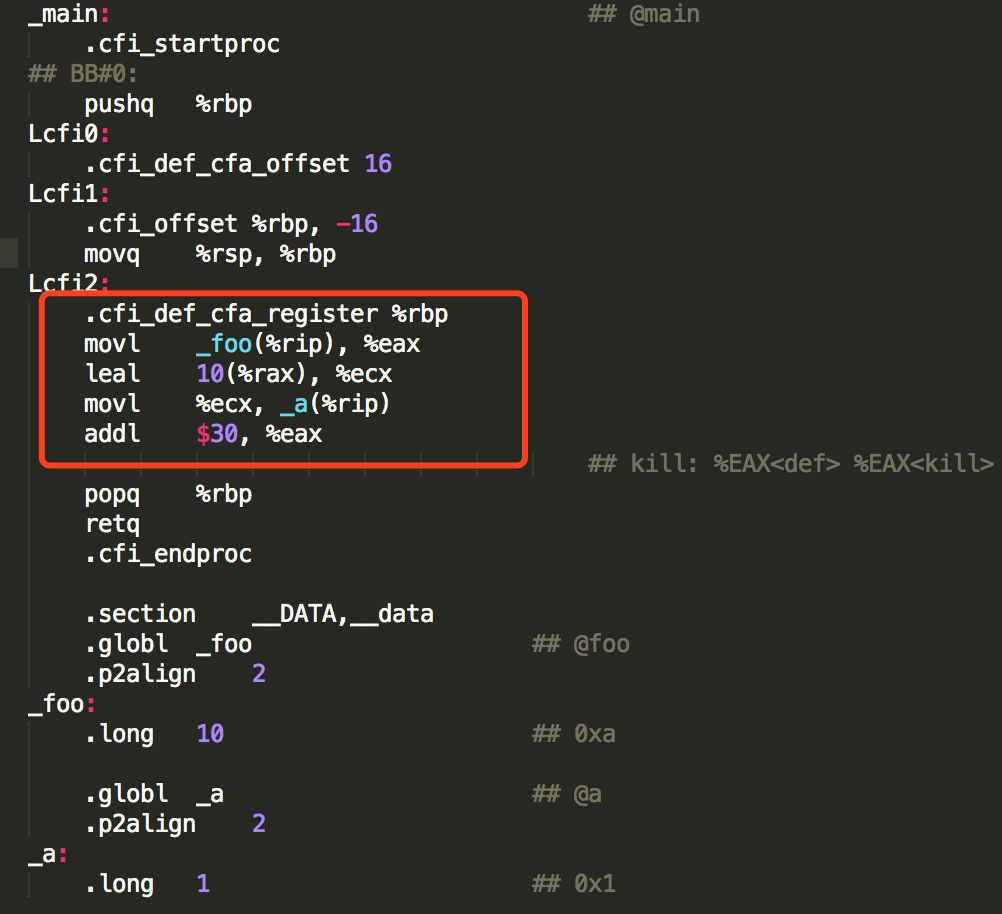
可以發現,在生成的彙編程式碼中,對變數a的一些無效負責操作果然都被最佳化掉了,如果在宣告變數a時加上volatile
#include
int foo = 10;
volatile int a = 1;
int main(int argc, const char * argv[]) {
// insert code here...
a = 2;
a = foo + 10;
int b = a + 20;
return b;
}
再次生成彙編程式碼如下:

和第一次比較,有以下不同:
1、對變數a賦值2的陳述句,也保留了下來,雖然是無效的動作,所以volatile關鍵字可以禁止指令最佳化,其實這裡發揮了編譯器屏障的作用;
編譯器屏障可以避免編譯器最佳化帶來的記憶體亂序訪問的問題,也可以手動在程式碼中插入編譯器屏障,比如下麵的程式碼和加volatile關鍵字之後的效果是一樣
#include
int foo = 10;
int a = 1;
int main(int argc, const char * argv[]) {
// insert code here...
a = 2;
__asm__ volatile ("" : : : "memory"); //編譯器屏障
a = foo + 10;
__asm__ volatile ("" : : : "memory");
int b = a + 20;
return b;
}
編譯之後,和上面類似

2、其中 _a(%rip)是變數a的每次地址,透過 movl $2,_a(%rip)可以把變數a所在的記憶體設定成2,關於RIP,可以檢視 x64下PIC的新定址方式:RIP相對定址
所以,每次對變數a的賦值,都會寫入到記憶體中;每次對變數的讀取,都會從記憶體中重新載入。
感覺有點跑偏了,讓我們回到JVM的程式碼中來。

執行完賦值操作後,緊接著執行 OrderAccess::storeload(),這又是啥?
其實這就是經常會唸叨的記憶體屏障,之前只知道念,卻不知道是如何實現的。從CPU快取結構分析中已經知道:一個load操作需要進入LoadBuffer,然後再去記憶體載入;一個store操作需要進入StoreBuffer,然後再寫入快取,這兩個操作都是非同步的,會導致不正確的指令重排序,所以在JVM中定義了一系列的記憶體屏障來指定指令的執行順序。
JVM中定義的記憶體屏障如下,JDK1.7的實現

1、loadload屏障(load1,loadload, load2)
2、loadstore屏障(load,loadstore, store)
這兩個屏障都透過 acquire()方法實現

其中 __asm__,表示彙編程式碼的開始。 volatile,之前分析過了,禁止編譯器對程式碼進行最佳化。 把這段指令編譯之後,發現沒有看懂....最後的"memory"是編譯器屏障的作用。
在LoadBuffer中插入該屏障,清空屏障之前的load操作,然後才能執行屏障之後的操作,可以保證load操作的資料在下個store指令之前準備好
3、storestore屏障(store1,storestore, store2),透過"release()"方法實現:
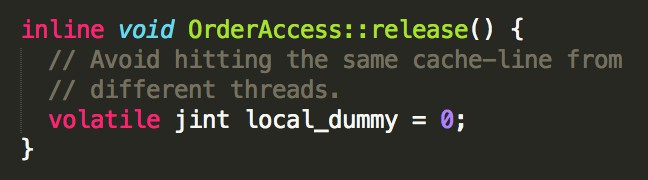
在StoreBuffer中插入該屏障,清空屏障之前的store操作,然後才能執行屏障之後的store操作,保證store1寫入的資料在執行store2時對其它CPU可見。
4、storeload屏障(store,storeload, load) 對java中的volatile變數進行賦值之後,插入的就是這個屏障,透過"fence()"方法實現:
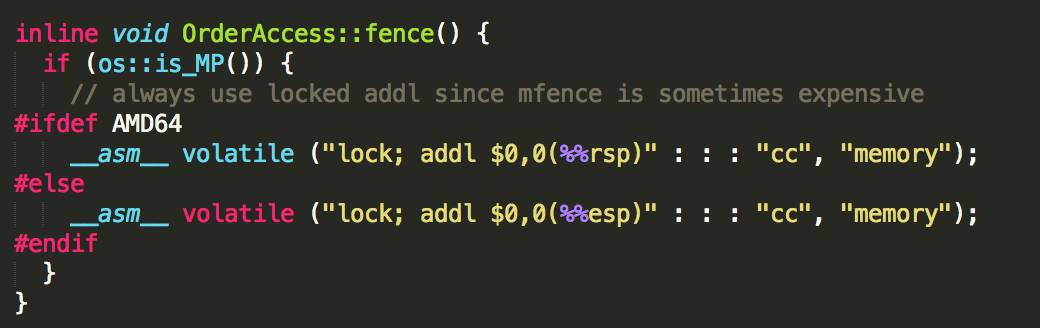
看到這個有沒有很興奮?
先透過 os::is_MP()判斷是不是多核,如果只有一個CPU的話,就不存在這些問題了。
storeload屏障由下麵這些指令實現
__asm__ volatile ("lock; addl $0,0(%%rsp)" : : : "cc", "memory");
為了試驗這些指令到底有什麼用,我們再寫點c++程式碼編譯一下
#include
int foo = 10;
int main(int argc, const char * argv[]) {
// insert code here...
volatile int a = foo + 10;
// __asm__ volatile ("lock; addl $0,0(%%rsp)" : : : "cc", "memory");
volatile int b = foo + 20;
return 0;
}
為了變數a和b不被編譯器最佳化掉,這裡使用了volatile進行修飾,編譯後的彙編指令如下:
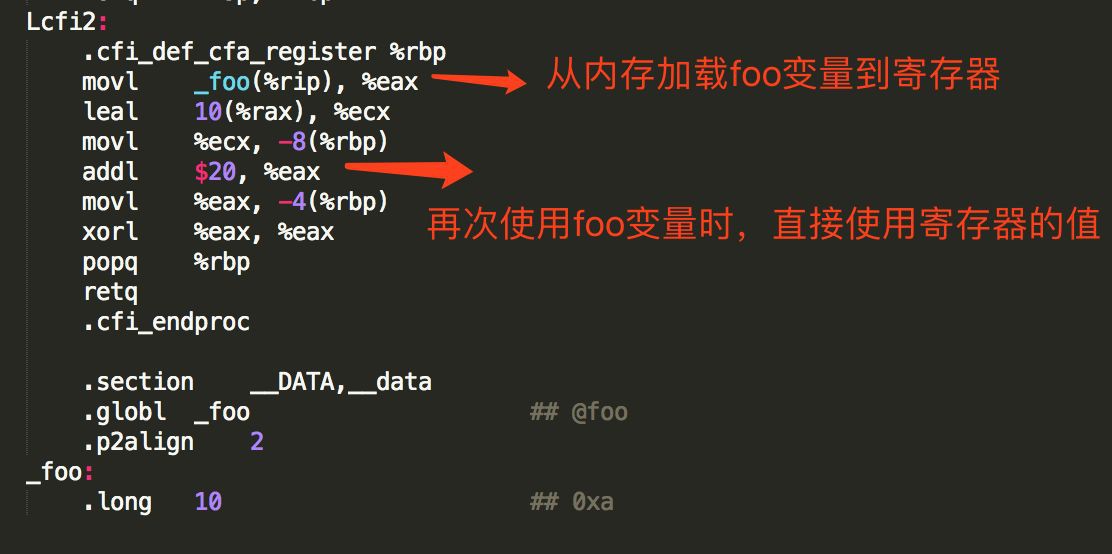
從編譯後的程式碼可以發現,第二次使用foo變數時,並沒有從記憶體重新載入,而是使用了暫存器的值。
把 __asm__volatile***指令加上之後重新編譯,結果如下

相比之前,這裡多了兩個指令,一個lock,一個addl。
lock指令的作用是:在執行lock後面指令時,會設定處理器的LOCK#訊號(這個訊號會鎖定匯流排,阻止其它CPU透過匯流排訪問記憶體,直到這些指令執行結束),這條指令的執行變成原子操作,之前的讀寫請求都不能越過lock指令進行重排,相當於一個記憶體屏障。
另一個不同的是:第二次使用foo變數時,從記憶體中重新載入,保證可以拿到foo變數的最新值,這是由如下指令實現
__asm__ volatile ( : : : "cc", "memory");
這個在之前已經提過,是一個編譯器屏障,通知編譯器重新生成載入指令(不可以從快取暫存器中取)。
讀取volatile變數
同樣在 bytecodeInterpreter.cpp檔案中,找到getstatic位元組碼指令的直譯器實現。
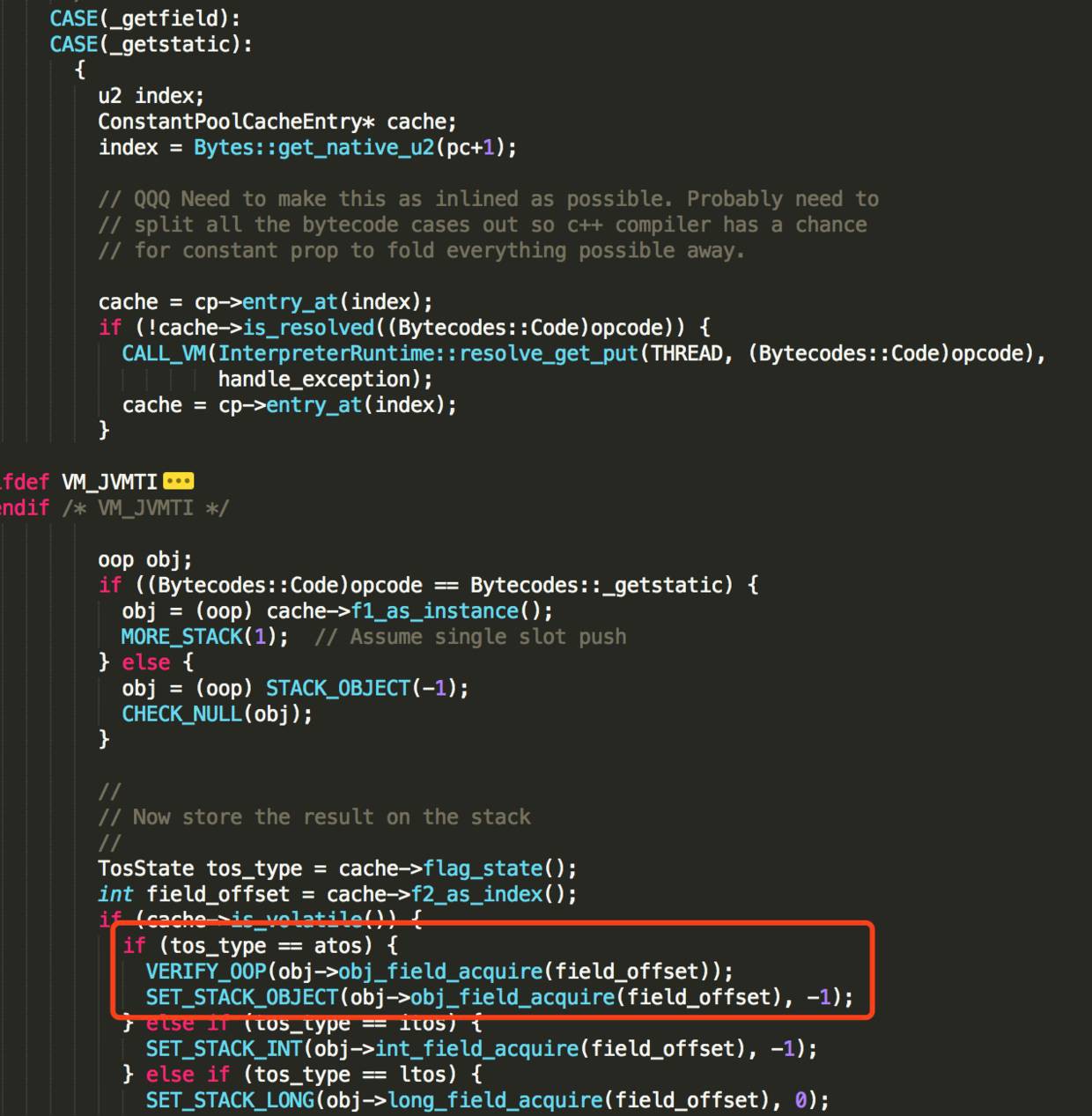
透過 obj->obj_field_acquire(field_offset)獲取變數值

最終透過 OrderAccess::load_acquire實現
inline jint OrderAccess::load_acquire(volatile jint* p) { return *p; }
底層基於C++的volatile實現,因為volatile自帶了編譯器屏障的功能,總能拿到記憶體中的最新值。
END

