作者:Kartik Singh
翻譯:王雨桐
來源:資料派THU(ID:DatapiTHU)
技術的不斷進步使得資料和資訊的產生速度今非昔比,並且呈現出繼續增長的趨勢。此外,目前對解釋、分析和使用這些資料的技術人員需求也很高,這在未來幾年內會呈指數增長。這些新角色涵蓋了從戰略、運營到管理的所有方面。
因此, 當前和未來的需求將需要更多的資料科學家、資料工程師、資料戰略家和首席資料官這樣類似的角色。
本文將著眼於不同型別的面試問題。如果您計劃向資料科學領域轉行,這些問題一定會有所幫助。
01
在統計學研究中,統計學中最常見的三個“平均值”是均值,中位數和眾數。
1. 算術平均值
它是統計學中的一個重要概念。算術平均值也可稱為平均值,它是透過將兩個或多個數字/變數相加,然後將總和除以數字/變數的總數而獲得的數量或變數。
2. 中位數
中位數也是觀察一組資料平均情況的一種方法。它是一組數字的中間數字。結果有兩種可能性,因為資料總數可能是奇數,也可能是偶數。
如果總數是奇數,則將組中的數字從最小到最大排列。中位數恰好是位於中間的數,兩側的數量相等。如果總數是偶數,則按順序排列數字並選擇兩個中間數字並加上它們然後除以2,它將是該組的中位數。
3. 眾數
眾數也是觀察平均情況的方法之一。眾數是一個數字,指在一組數字中出現最多的數字。有些數列可能沒有任何眾數;有些可能有兩個眾數,稱為雙峰數列。
4. 標準差(Sigma,s)
標準差用於衡量資料在統計資料中的離散程度。
5. 回歸
回歸是統計建模中的一種分析方法。這是衡量變數間關係的統計過程;它決定了一個變數和一系列其他自變數之間關係的強度。

02
統計學的兩個主要分支是描述性統計和推斷性統計。
6. 描述性統計
描述性統計使用類似均值或標準差的指數來總結樣本資料。
描述性統計方法包括展示、組織和描述資料。
7. 推斷性統計
推斷統計得出的結論來自隨機變化的資料,如觀察誤差和樣本變異。
8. 統計的應用領域
結合資料分析,統計可以用於分析資料,並幫助企業做出正確的決策。預測性“分析”和“統計”對於分析當前資料和歷史資料以預測未來事件非常有用。
統計資料可用於許多研究領域。以下列舉了統計的應用領域:
-
科學
-
技術
-
商業
-
生物學
-
電腦科學
-
化學
-
支援決策
-
提供比較
-
解釋已經發生的行為
-
預測未來
-
估計未知數量
9. 線性回歸
線性回歸是預測分析中使用的統計技術之一,該技術將確定自變數對因變數的影響強度。
10. 樣本
在統計研究中,透過結構化和統一處理,樣本是從統計總體中收集或處理的一組或部分資料,並且樣本中的元素被稱為樣本點。
11. 抽樣方法
-
聚類抽樣:在聚類抽樣方法中,總體將被分為群組或群集。
-
簡單隨機抽樣:這種抽樣方法僅僅遵循隨機分配。
-
分層抽樣:在分層抽樣中,資料將分為組或分層。
-
系統抽樣:根據系統抽樣方法,每隔k個成員,從總體中抽取一個。
12. p值
當我們在統計中進行假設檢驗時,p值有助於我們確定結果的顯著性。這些假設檢驗僅僅是為了檢驗關於總體假設的有效性。零假設是指假設和樣本沒有顯著性差異,這種差異指抽樣或實驗本身造成的差異。
13. 資料科學
資料科學是資料驅動的科學,它還涉及自動化科學方法、演演算法、系統和過程的跨學科領域,以任何形式(結構化或非結構化)從資料中提取資訊和知識。此外,它與資料挖掘有相似之處,它們都從資料中抽象出有用的資訊。
資料科學包括數理統計以及電腦科學和應用。此外,結合了統計學、視覺化、應用數學、電腦科學等各個領域,資料科學將海量資料轉化為洞見。
同樣,統計學是資料科學的主要組成部分之一。統計學是數學商業的一個分支,它包括資料的收集、分析、解釋、組織和展示。

03
協方差和相關性是兩個數學概念;這兩種方法在統計學中被廣泛使用。相關性和協方差都可以構建關係,並且還可測量兩個隨機變數之間的依賴關係。雖然這兩者在數學上有相似之處,但它們含義並不同。
14. 相關性
相關性被認為是測量和估計兩個變數間定量關係的最佳技術。相關性可以衡量兩個變數相關程度的強弱。
15. 協方差
協方差對應的兩個變數一同變化,它用於度量兩個隨機變數在週期中的變化程度。這是一個統計術語;它解釋了一對隨機變數之間的關係,其中一個變數的變化時,另一個變數如何變化。
04
16. R面試問題
R是資料分析軟體,主要的服務物件是分析師、量化分析人員、統計學家、資料科學家等。
R提供的函式是:
-
均值
-
中位數
-
分佈
-
協方差
-
回歸
-
非線性模型
-
混合效果
-
廣義線性模型(GLM)
-
廣義加性模型(GAM)等等
在R控制臺中輸入命令(“Rcmdr”)將啟動R Commander GUI。
使用R commander匯入R中的資料,有三種方法可以輸入資料。
-
你可以透過Data
-
從純文字(ASCII)或其他檔案(SPSS,Minitab等)匯入資料
-
透過鍵入資料集的名稱或在對話方塊中選擇資料集來讀取資料集
-
雖然R可以輕鬆連線到DBMS,但不是資料庫
-
R不包含任何圖形使用者介面
-
雖然它可以連線到Excel / Microsoft Office,但R語言不提供任何資料的電子錶格檢視
在R中,在程式的任何地方,你必須在#sign前面加上程式碼行,例如:
-
減法
-
除法
-
註意運算順序
要在R中儲存資料,有很多方法,但最簡單的方法是:
Data > Active Data Set > Export Active dataset,將出現一個對話方塊,當單擊確定時,對話方塊將根據常用的方式儲存資料。
你可以透過cor()函式傳回相關係數,cov()函式傳回協方差。
在R中,t.test()函式用於進行各種t檢驗。t檢驗是統計學中最常見的檢驗,用於確定兩組的均值是否相等。
-
With()函式類似於SAS中的DATA,它將運算式應用於資料集。
-
BY()函式將函式應用於因子的每個水平。它類似於SAS中的BY。
R 有如下這些資料結構:
-
向量
-
矩陣
-
陣列
-
資料框
通用的形式是:
Mymatrix< – matrix (vector, nrow=r, ncol=c , byrow=FALSE, dimnames = list ( char_vector_ rowname, char_vector_colnames)
在R中,缺失值由NA(Not Available)表示,不可能的值由符號NaN(not a number)表示。
為了重新整理資料,R提供了各種方法,轉置是重塑資料集的最簡單的方法。為了轉置矩陣或資料框,可以使用t()函式。
透過一個或多個BY變數,使得摺疊R中的資料變得容易。使用aggregate()函式時,BY變數應該在串列中。

05
機器學習是人工智慧的一種應用,它為系統提供了自動學習和改進經驗的能力,而無需明確的程式設計。此外,機器學習側重於開發可以訪問資料並自主學習的程式。
在很多領域,機器人正在取代人類。這是因為程式設計使得機器人可以基於從感測器收集的資料來執行任務。他們從資料中學習並智慧地運作。
17. 機器學習中不同型別的演演算法技術
-
強化學習
-
監督學習
-
無監督學習
-
半監督學習
-
轉導
-
元學習
這是面試中提出的基本機器學習面試問題。監督學習是一個需要標記訓練集資料的過程,而無監督學習則不需要資料標記。
18. 無監督學習
-
資料聚類
-
資料的降維表示
-
探索資料
-
探索坐標和相關性
-
識別異常觀測
19. 監督學習
-
分類
-
語音識別
-
回歸
-
預測時間序列
-
註釋字串
20. 樸素貝葉斯
樸素貝葉斯的優點是:
-
分類器比判別模型更快收斂
-
它可以忽略特徵之間的相互作用
樸素貝葉斯的缺點是:
-
不適用連續性特徵
-
它對資料分佈做出了非常強的假設
-
在資料稀缺的情況下不能很好地工作
樸素貝葉斯是如此的不成熟,因為它假設資料集中所有特徵同等重要且獨立。

06
21. 過擬合
這是一個受歡迎的機器學習面試問題。機器學習中的過擬合定義為:統計模型側重於隨機誤差或噪聲而不是探索關係,或模型過於複雜。
過擬合的一個重要原因和可能性是用於訓練模型的標準與用於判斷模型功效的標準不同。
我們可以透過以下方式避免過擬合:
-
大量資料
-
交叉驗證
22. 五種常用的機器學習演演算法
-
決策樹
-
機率網路
-
最近鄰
-
支援向量機
-
神經網路
23. 機器學習演演算法的使用案例
-
欺詐檢測
-
人臉識別
-
自然語言處理
-
市場細分
-
文字分類
-
生物資訊學
24. 在機器學習中構建假設或模型
引數模型是指引數有限且用於預測新資料的模型,你只需知道模型的引數即可。
非引數模型是指引數數量無限的模型,允許更大的靈活性且用於預測新資料,你需要瞭解模型的引數並熟悉已收集的觀測資料。
這是面試中經常問的機器學習面試問題。在機器學習中構建假設或模型的三個階段是:
-
模型構建
-
模型測試
-
模型應用
07
歸納邏輯程式設計(ILP)是機器學習的一個子領域,它使用代表背景知識和案例的邏輯程式。
25. 分類和回歸之間的區別
-
分類是關於識別類別的組成,而回歸涉及預測因變數。
-
這兩種技術都與預測相關。
-
分類預測類別的歸屬,而回歸預測來自連續集的值。
-
當模型需要傳回資料集中的資料點的歸屬類別時,回歸不是首選。
26. 歸納機器學習和演繹機器學習的區別
機器學習,模型透過從一組觀察實體中學習,得出一個廣義結論。而在演繹學習中,要機遇一些已知結論,得出結果。
27. 決策樹的優點是
-
決策樹易於理解
-
非引數
-
調整的引數相對較少
08
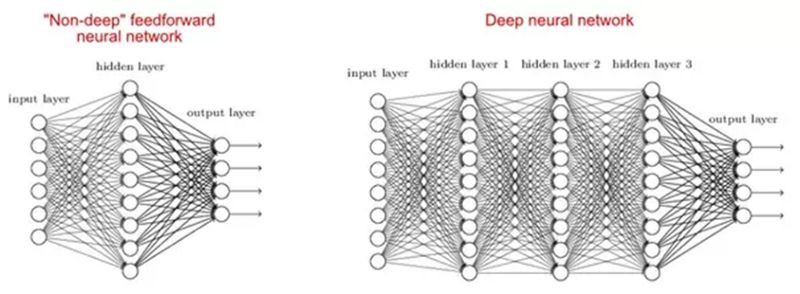
機器學習領域專註於深受大腦啟發的深度人工神經網路。Alexey Grigorevich Ivakhnenko將深度學習網路帶入大眾視野。如今它已應用於各種領域,如計算機視覺、語音識別和自然語言處理。
有研究表明,淺網和深網都可以適應任何功能,但由於深度網路有幾個不同型別的隱藏層,因此相比於引數更少的淺模型,它們能夠構建或提取更好的特徵。
代價函式是神經網路對於給定訓練樣本和預期輸出的準確度的度量。它是一個值,而非向量,因為它支撐了整個神經網路的效能。它可以計算如下平均誤差函式:

其中 和期望值Y是我們想要最小化的。
和期望值Y是我們想要最小化的。
梯度下降是一種基本的最佳化演演算法,用於學習最小化代價函式的引數值。此外,它是一種迭代演演算法,它在最陡下降的方向上移動,由梯度的負值定義。我們計算給定引數的成本函式的梯度下降,並透過以下公式更新引數:
其中 是引數向量,α 是學習率,J()是成本函式。
是引數向量,α 是學習率,J()是成本函式。
28. 反向傳播
反向傳播是一種用於多層神經網路的訓練演演算法。在此方法中,我們將誤差從網路末端移動到網路內的所有權重,從而進行梯度的高效計算。它包括以下幾個步驟:
-
訓練的前向傳播以產生輸出。
-
然後可以使用標的值和輸出值誤差導數來計算輸出啟用。
-
然後我們傳回傳播以計算前一個輸出啟用的誤差導數,並對所有隱藏層繼續此操作。
-
使用之前計算的輸出和所有隱藏層的導數,我們計算關於權重的誤差導數。
-
然後更新權重。
29. 梯度下降
隨機梯度下降:我們僅使用單個訓練樣本來計算梯度和更新引數。
批次梯度下降:我們計算整個資料集的梯度,併在每次迭代時進行更新。
小批次梯度下降:它是最流行的最佳化演演算法之一。它是隨機梯度下降的變體,但不是單個訓練示例,使用小批次樣本。
30. 小批次梯度下降的好處
-
與隨機梯度下降相比,這更有效。
-
透過找到平面最小值來提高泛化性。
-
小批次有助於估計整個訓練集的梯度,這有助於我們避免區域性最小值。
31. 資料標準化
在反向傳播期間要使用資料標準化。資料規範化背後的主要動機是減少或消除資料冗餘。在這裡,我們重新調整值以適應特定範圍,以實現更好的收斂。
32. 權重
權重初始化是非常重要的步驟之一。糟糕的權重初始化可能會阻止網路學習,但良好的權重初始化有助於更快的收斂和整體誤差最佳化。偏差通常可以初始化為零。設定權重的規則應接近於零,而不是太小。
33. 自編碼
自編碼是一種使用反向傳播原理的自主機器學習演演算法,其中標的值設定為等於所提供的輸入。在內部有一個隱藏層,用於描述用於表示輸入的程式碼。
關於自編碼的一些重要特徵如下:
-
它是一種類似於主成分分析(PCA)的無監督機器學習演演算法
-
最小化與主成分分析相同的標的函式
-
它是一個神經網路
-
神經網路的標的輸出是其輸入
34. 玻爾茲曼機
玻爾茲曼機(Boltzmann Machine)是一種問題解決方案的最佳化方法。玻爾茲曼機的工作基本是為了最佳化給定問題的權重和數量。關於玻爾茲曼機的一些要點如下:
-
它使用迴圈結構。
-
由隨機神經元組成,其中包括兩種可能的狀態之一,1或0。
-
其中的神經元處於連通狀態(自由狀態)或斷開狀態(凍結狀態)。
-
如果我們在離散Hopfield網路上應用模擬退火,那麼它將成為玻爾茲曼機。
35. 啟用函式
啟用函式是一種將非線性引入神經網路的方法,它有助於學習更複雜的函式。沒有它,神經網路只能學習線性函式。線性函式是輸入資料的線性組合。

09
現在是引領浪潮之巔的最好時機,我們應當儘量完善自己在資料科學和分析這些新興領域所需的技能。最重要的是,這不僅適用於剛開始職業生涯並決定學習的人。就連已就職的專業人士可以從資料科學的浪潮中受益,甚至可能比那些新入行的競爭者獲益更多。
關於譯者:王雨桐,UIUC統計學在讀碩士,本科統計專業,目前專註於Coding技能的提升。理論到應用的轉換中,敬畏資料,持續進化。
原文標題:
Data Science & ML : A Complete Interview Guide
原文連結:
https://www.codementor.io/divyacyclitics15/data-science-ml-a-complete-interview-guide-qlprmdc6y
朋友會在“發現-看一看”看到你“在看”的內容