(點選上方快速關註並設定為星標,一起學Python)
來源:超哥的雜貨鋪 連結:
https://mp.weixin.qq.com/s/x3R4mU4z6-lyK6rp9RBluA
寫在前面:本文從北京公交路線資料的獲取和預處理入手,記錄使用python中requests庫獲取資料,pandas庫預處理資料的過程。文章在保證按照一定處理邏輯的前提下,以自問自答的方式,對其中每一個環節進行詳細闡述。本次程式碼均在jupyter notebook中測試透過,希望對大家有所啟示。
資料獲取:
本次我們從公交網獲取北京公交的資料。
(http://beijing.gongjiao.com/lines_all.html)
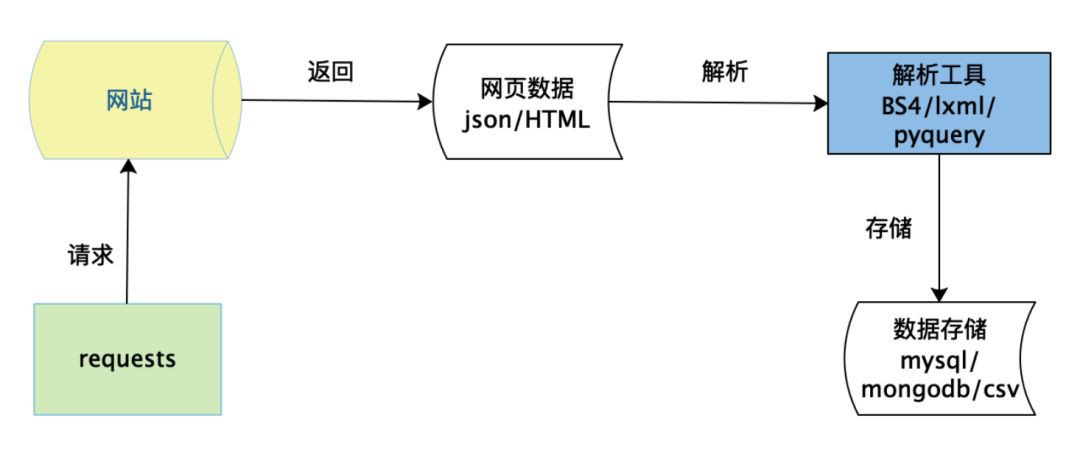
如上圖所示,資料獲取分為請求,解析,儲存三個最主要的步驟。
1.如何用python模擬網路請求?
使用request庫可以模擬不同的請求,例如requests.get()模擬get請求,requests.post()模擬post請求。必要的時候可以新增請求頭essay-header,essay-header通常包括user-agent,cookie,refer等資訊,還可以增加請求引數data和代理資訊。主要程式碼形式為:response = requests.request("GET", url, essay-headers=essay-headers, params=querystring)response是網站傳回的響應資訊,可以呼叫其text方法獲取網站的HTML原始碼。本次我們的標的網站比較簡單,獲取網頁原始碼的程式碼如下:
1url = 'http://beijing.gongjiao.com/lines_all.html'
2text = requests.get(url).text
2.如何對網頁進行解析?
python中提供了多種庫用於網頁解析,例如lxml,BeautifulSoup,pyquery等。每一個工具都有相應的解析規則,但都是把HTML檔案當做一個DOM樹,透過選擇器進行節點和屬性的定位。本次我們使用lxml對網頁進行解析,主要用到了xpath的語法。lxml的執行效率通常也比BeautifulSoup更高一些。
1doc = etree.HTML(text)
2all_lines = doc.xpath("//div[@class='list']/ul/li")
3for line in all_lines:
4 line_name = line.xpath("./a/text()")[0].strip()
5 line_url = line.xpath("./a/@href")[0]

我們將圖和程式碼結合起來看。第一行程式碼將上一步傳回的HTML文字轉換為xpath可以解析的物件。第二行程式碼定位到class=list的div下麵所有的li標簽,即右圖中的紅色框的部分,得到的是一個串列。從第三行開始對其進行遍歷,處理每一個li下麵的a標簽。第4行取出a標簽下的文字,用到了xpath的text()方法,對應到第一個li就是“北京1路公交車路線”,第5行取出a標簽下對應的連結,用到了xpath的@href取出a標簽下的href屬性值。直接取都是串列的形式,所以需要用索引取出具體的值。
這樣我們就可以得到整個公交線路串列中的線路名稱和線路url。然後從線路url出發,就可以獲取每條線路的具體資訊。如下麵程式碼和圖片所示,雖然資料略多,但主要的邏輯和上面類似,可以檢視程式碼中的註釋。

註:左右滑動檢視詳細程式碼
1url = 'http://beijing.gongjiao.com/xianlu_38753'#先以一個url為例,進行頁面的分析
2text = requests.get(url).text
3print(len(text))
4doc = etree.HTML(text)
5infos = doc.xpath("//div[@class='gj01_line_essay-header clearfix']")#定位到相應的div塊
6for info in infos:
7 start_stop = info.xpath("./dl/dt/a/text()")#獲取起點站和終點站的文字,xpath的邏輯為:div->dl->dt->a
8 op_times = info.xpath("./dl/dd[1]/b/text()")#獲取運營時間的文字,xpath的邏輯為:div->dl->第一個dd->b
9 interval = info.xpath("./dl/dd[2]/text()")#獲取發車間隔的文字,xpath的邏輯為:div->dl->第二個dd
10 price = info.xpath("./dl/dd[3]/text()")#獲取票價資訊的文字,xpath的邏輯為:div->dl->第三個dd
11 company = info.xpath("./dl/dd[4]/text()")#獲取汽車公司的文字,xpath的邏輯為:div->dl->第四個dd
12 up_times = info.xpath("./dl/dd[5]/text()")#獲取更新時間的文字,xpath的邏輯為:div->dl->第五個dd
13 all_stations_up = doc.xpath('//ul[@class="gj01_line_img JS-up clearfix"]')#定位到相應的div塊
14 for station in all_stations_up:
15 station_name = station.xpath('./li/a/text()')#遍歷取出該條線路上的站點名稱
16 all_stations_down = doc.xpath('//ul[@class="gj01_line_img JS-down clearfix"]')#定位到返程線路相應的div塊
17 for station in all_stations_down:
18 station_name = station.xpath('./li/a/text()')#遍歷取出該條線路上返程的站點名稱
19如果將獲取的文字都輸出(請自行新增相應的print陳述句)執行結果如下:
20['老山公交場站(1)', '四惠樞紐站(27)']
21['5:00-23:00']
22['5:00-23:00']
23['發車間隔:未知']
24['票價資訊:10公里以內票價2元,每增加5公里以內加價1元,最高票價6元']
25['汽車公司:北京公交集團第六客運分公司']
26['更新時間:2015-04-05 03:32:16']
27['老山公交場站(1)', '老山南路東口(2)', '地鐵八寶山站(3)', '玉泉路口西(4)', '五棵松橋西(6)', '翠微路口(8)', '公主墳(9)', '軍事博物館(10)', '木樨地西(11)', '工會大樓(12)', '南禮士路(13)', '復興門內(13)', '西單路口東(15)', '天安門西(16)', '天安門東(17)', '東單路口西(18)', '北京站口東(19)', '日壇路(20)', '永安里路口西(21)', '大北窯西(22)', '大北窯東(23)', '郎家園(23)', '四惠樞紐站(27)']
28['四惠樞紐站(27)', '八王墳西(24)', '郎家園(23)', '大北窯東(23)', '大北窯西(22)', '永安里路口西(21)', '日壇路(20)', '北京站口東(19)', '東單路口西(18)', '天安門東(17)', '天安門西(16)', '西單路口東(15)', '復興門內(13)', '南禮士路(13)', '工會大樓(12)', '木樨地西(11)', '軍事博物館(10)', '公主墳(9)', '翠微路口(8)', '五棵松橋東(6)', '玉泉路口西(4)', '地鐵八寶山站(3)', '老山南路東口(2)', '老山公交場站(1)']
3.如何儲存獲取的資料?
資料儲存的載體通常有檔案(例如csv,excel)和資料庫(例如mysql,MongoDB)。我們這裡選擇了csv檔案的形式,一方面是資料量不是太大,另一方面也不需要進行資料庫安裝,只需將資料整理成dataframe的格式,直接呼叫pandas的to_csv方法就可以將dataframe寫入csv檔案中。主要程式碼如下:
註:左右滑動檢視詳細程式碼
1#準備一個儲存資料的字典
2df_dict = {
3 'line_name': [], 'line_url': [], 'line_start': [], 'line_stop': [],
4 'line_op_time': [], 'line_interval': [], 'line_price': [], 'line_company': [],
5 'line_up_times': [], 'line_station_up': [], 'line_station_up_len': [],
6 'line_station_down': [], 'line_station_down_len': []
7}
8#將上面獲取的資料寫入到字典中,註意這裡只是示例,實際執行時候要將下麵的程式碼放到迴圈中,每解析一條線路就需要append一次。
9df_dict['line_name'].append(line_name)
10df_dict['line_url'].append(line_url)
11df_dict['line_start'].append(start_stop[0])
12df_dict['line_stop'].append(start_stop[1])
13df_dict['line_op_time'].append(op_times[0])
14df_dict['line_interval'].append(interval[0][5:])#為了把前面的文字“發車間隔”截掉,其餘的類似
15df_dict['line_company'].append(company[0][5:])
16df_dict['line_price'].append(price[0][5:])
17df_dict['line_up_times'].append(up_times[0][5:])
18df_dict['line_station_up'].append(station_up_name)
19df_dict['line_station_up_len'].append(len(station_up_name))
20df_dict['line_station_down'].append(station_down_name)
21df_dict['line_station_down_len'].append(len(station_down_name))
22#將資料儲存成csv檔案
23df = pd.DataFrame(df_dict)
24df.to_csv('bjgj_lines_utf8.csv', encoding='utf-8', index=None)
4.看一看完整程式碼?
以上我們分模擬請求,網頁解析,資料儲存3個步驟,學習了資料獲取的流程。實際執行過程中,還需要增加一些保證程式碼“健壯性”的邏輯。例如,控制爬取的頻率,處理請求失敗的情況,處理不同的線路網頁結構可能有差異的情況等等。本次的資料源沒有做很多反扒限制,因此前兩種情況我們可以不處理。至於第三種,有的路線會出現線路運營時間是空值的情況,需要進行判斷。另外還可以增加一些爬蟲執行過程的提示資訊,讓我們知道爬取進度,當然你也可以增加多執行緒,代理,ua切換等程式碼,此處我們還用不上這些。完整的程式碼可以在後臺回覆“北京公交”進行獲取。
資料預處理
在上一步獲取資料之後,我們就可以使用pandas進行資料的分析工作。在正式的分析之前,資料預處理非常重要,它保證了資料的質量,也為後續的工作奠定了重要的基礎。通常資料預處理在實際工作中都會佔用比較多的時間。雖然我們這裡的資料已經足夠“結構化”,但仍然不可避免存在一些問題。下麵我們就來一探究竟。
5.如何讀取資料?
使用pandas提供的read_csv方法,該方法有很多可選的引數,例如指定索引,列名,編碼等。對於本次資料,直接使用預設的即可。讀取的ori_data是dataframe型別,呼叫head方法可以輸出前5行的樣例資料。
1ori_data = pd.read_csv('bjgj_lines_utf8.csv')
2ori_data.head()
6.如何檢視每一列資料的唯一值的個數?(如何檢視有多少條線路)
可以使用dataframe的nunique方法,該方法輸出每一列有幾個唯一的值。
1ori_data.nunique()
2輸出結果如下:
3line_name 1986
4line_url 2002
5line_start 989
6line_stop 1123
7line_op_time 560
8line_interval 4
9line_price 126
10line_company 82
11line_up_times 650
12line_station_up 1928
13line_station_up_len 80
14line_station_down 1700
15line_station_down_len 80
16dtype: int64
由於線路很多,我們在原始網頁中很難發現是否會有重覆的線路。但從上面觀察line_name和line_url兩個欄位,line_name有1986個唯一值,line_url有2002個唯一值。說明line_name存在重覆:會有名稱相同的線路對應不同的line_url。所以接下來我們需要進行重覆值的剔除。
7.如何找出重覆的值?
出現了線路名稱的重覆,但卻有不同的line_url,究竟是確實是線路“重名”還是線路“重覆”?我們需要看一下資料重覆的具體情況。因此需要把重覆的行都找出來看看。可以使用pandas的duplicated方法,它可以對dataframe的指定列檢視是否重覆,傳回True和False,程式碼如下。
1d = ori_data.duplicated(subset=['line_name'])
2dup_data = ori_data[d]
3dup_data

這是所有重覆出現過的line_name值,但並不是所有重覆的值(例如22路重覆出現過,但22路在結果中只有一條,不便於觀察除了名字之外是否還有其他欄位的重覆)。為了找出所有重覆的值(例如輸出所有22路的記錄),我們可以從原資料中取line_name是這些值的所有行,程式碼和思路如下:
1#首先定義一個串列,每找出一行line_name在上面範圍內的,
2#就將這行加入串列,然後呼叫concat方法將串列拼接成#dataframe
3dup_lines = []
4for name in dup_data.line_name:
5 tmp_lines = ori_data[ori_data['line_name'] == name]
6 dup_lines.append(tmp_lines)
7 dup_data_all = pd.concat(dup_lines)
8dup_data_all

觀察dup_data_all,確實同一個線路名字存在重覆的記錄,而且其餘資訊也是幾乎都相同的,這確認了我們認為的線路”重名“現象是不存在的。但同一條線路的資訊具體以哪一個為準呢?註意到有更新時間line_up_time欄位,因此我們可以以最新時間的資訊為準。
8.如何對原資料剔除重覆值?
這裡考慮兩種思路。第一種,直接對原資料進行操作,當line_name存在重覆時,保留最近更新時間的記錄。第二種,將原資料中的dup_data_all部分完全刪除,拼接上dup_data_all去除重覆的部分。兩種思路都需要刪除line_name重覆的記錄,保留一個時間最新的。pandas本身有drop_duplicates方法,使用keep=last或keep=first引數就可以指定保留的記錄。但在這之前我們需要將line_up_time轉換為pandas可以識別的時間型別,然後對其進行排序。下麵來看程式碼:
註:左右滑動檢視詳細程式碼
1#方法1
2ori_data['line_up_times'] = pd.to_datetime(ori_data['line_up_times'], format='%Y-%m-%d %H:%M:%S')#使用to_datetime方法,指定format,將字串轉換為pandas的時間型別。
3ori_data.sort_values(by=['line_name', 'line_up_times'], ascending=[True, True], inplace=True)#使用sort_values方法,對line_name和line_up_time排序
4drop_dup_line1 = ori_data.drop_duplicates(subset=['line_name'], keep='last')#由於是升序排列,所以keep=last就可以保留最新事件的記錄
5len(drop_dup_line1)#結果是1986
6
7方法2:
8dup_data_all['line_up_times'] = pd.to_datetime(dup_data_all['line_up_times'], format='%Y-%m-%d %H:%M:%S')#使用to_datetime方法,指定format,將字串轉換為pandas的時間型別。
9dup_data_all.sort_values(by=['line_name', 'line_up_times'], ascending=[True, True], inplace=True)#使用sort_values方法,對line_name和line_up_time排序
10dup_data_all.drop_duplicates(subset=['line_name'], keep='last', inplace=True)#使用keep=last保留時間更新的記錄
11
12other_data = ori_data[~ori_data['line_name'].isin(dup_data_all.line_name)]#獲取原資料中剔除了重覆線路的資料:取名字不在dup_data_all的line_name集合中的記錄
13drop_dup_line2 = pd.concat([other_data, dup_data_all]) #拼接兩部分資料
14len(drop_dup_line2)#結果是1986
如何比較兩種方法獲得的結果線路是否一致?我們可以用下麵的程式碼進行。
1drop_dup_line2.sort_values(by=['line_name', 'line_up_times'], ascending=[True, True], inplace=True)#由於drop_dup_line1排序過,我們也對drop_dup_line2進行相同規則的排序
2res = drop_dup_line1['line_name'].values.ravel() == drop_dup_line2['line_name'].values.ravel()#ravel()方法將陣列展開,res是一個布林值組成的ndarray陣列,結果為true表示對應元素相等
3res = [1 for i in res.flat if i]
4sum(res)#使用flat方法可以對ndarray進行遍歷,sum看一下一共有多少個true,結果是1986,說明drop_dup_line1和drop_dup_line2對應每一個位置的元素都相同
這樣對於重覆資料的處理就結束了,我們使用drop_dup_line1來進行下麵的分析。
9.如何刪除地鐵線路?
雖然我們爬取的是公交路線,但程式執行過程中我也發現了地鐵的線路(其實地鐵也是廣義上的公交啦)。如果我們的目的是對純粹的公交線路進行分析,就需要將地鐵的線路刪除。直觀的思路是剔除線路名稱中含有“地鐵”的記錄。
1is_subway = drop_dup_line1.line_name.str.contains('地鐵')#使用.str將其轉換為字串就可以使用字串的contains方法。
2subway_data = drop_dup_line1[is_subway]
3subway_data

從上圖左側可以看到subway_data的結果不僅僅有地鐵,還有一些地鐵有關的通勤線路,其實是公交。因此不能直接刪除line_name中含有“地鐵”的記錄,我們使用line_conpany中含有“地鐵”來區分,效果更好。程式碼如下所示:
1is_subway2 = drop_dup_line1.line_company.str.contains('地鐵')
2subway_data2 = drop_dup_line1[is_subway2]
3subway_data2
結果如上圖右側所示,雖然最後一條也有一條“公交車路線”,但觀察整條記錄就會發現它其實是特殊的機場線地鐵。
到這裡,你會不會想到根據線路名稱中是否含有“公交車路線”將地鐵線路剔除?我們可以試一試。但其實上面的圖已經告訴了我們答案:有的公交線路是“接駁線”,並不含有“公交車路線”。
10.獲取刪除地鐵資料之後的全部資料
在drop_dup_line1的基礎上,篩選出線路名稱不在subway_data2中的線路名稱的記錄即可:
1clean_data = drop_dup_line1[~drop_dup_line1['line_name'].isin(subway_data2.line_name)]
2len(clean_data) #結果是1963,也就是北京的公交車一共有1963條線路
3
4clean_data3 = drop_dup_line1[drop_dup_line1.line_name.str.contains("公交車路線")]
5len(clean_data3) #透過是否含有“公交車線路”進行篩選,結果是1955,應該就是少了那些“接駁線”
如何比較clean_data和clean_data3。這個問題其實是如何求兩個dataframe差集的問題,我們轉化為求串列的差集,程式碼和結果如下所示。
1list(set(clean_data.line_name.values).difference(set(clean_data3.line_name.values))) #找出在clean_data的line_name中但是不在clean_data3的line_name中的資料
2list(set(clean_data3.line_name.values).difference(set(clean_data.line_name.values))) #找出在clean_data3的line_name中但是不在clean_data的line_name中的資料

至此我們將重覆資料進行了刪除,並剔除了“地鐵”線路。但其實我們的資料預處理工作還沒有結束,我們還沒有觀察資料中是否含有缺失值。
11.如何檢視資料集中的缺失值情況?
可以使用isnull().sum()方法檢視。發現票價有230個缺失值。參見後面的圖片。對於缺失值我們需要在預處理階段對其進行填充。考慮到票價資料本身不是純粹的價格資料,而是一大串的文字描述,並且在公交的這種場景下,其實不同線路的票價差別不是很大,因此我們可以使用眾數對缺失值進行填充。使用mode方法檢視眾數,使用fillna方法填補缺失值。
1#檢視眾數的方法:
2clean_data.line_price.mode()#使用mode()方法檢視line_price的眾數
3clean_data.line_price.value_counts()#使用value_counts()方法檢視每一個取值出現的次數,第一個也是眾數
4
5clean_data.line_price.fillna(clean_data.line_price.mode()[0], inplace=True)
6clean_data.isnull().sum()

至此我們基本完成了重覆值和缺失值的處理。
總結
本文我們主要藉助於北京公交資料的實體,學習了使用python進行資料獲取和資料預處理的流程。內容雖然簡單但不失完整性。資料獲取部分主要使用requests模擬了get請求,使用lxml進行了網頁解析並將資料儲存到csv檔案中。資料預處理部分我們進行了重覆值和缺失值的處理,但應該說資料預處理並沒有完成。(比如我們可以對運營時間拆分成兩列,對站點名稱進行清理等,如何進行預處理工作與後續的分析緊密相關)。文章的重點不在於例子的難度,而在於透過具體問題學習python中資料處理的方法。所處理的問題雖然有一定的特殊性,但也方便擴充套件到其他場景。希望對讀到這裡的你有一定的幫助。讀者可以在後臺回覆“北京公交”獲取本文的資料和爬取程式碼,歡迎交流學習~

朋友會在“發現-看一看”看到你“在看”的內容