作者:yuanxiaosc
來源:Github、大資料文摘
原文:
https://github.com/yuanxiaosc/DeepNude-an-Image-to-Image-technology
上週,又一AI偏門應用DeepNude爆出,一鍵直接“脫掉”女性的衣服,火爆全球。
應用也很容易上手,只需要給它一張照片,即可藉助神經網路技術,自動“脫掉”衣服。原理雖然理解門檻高,但是應用起來卻毫不費力,因為對於使用者來說,無需任何技術知識,一鍵即可獲取。
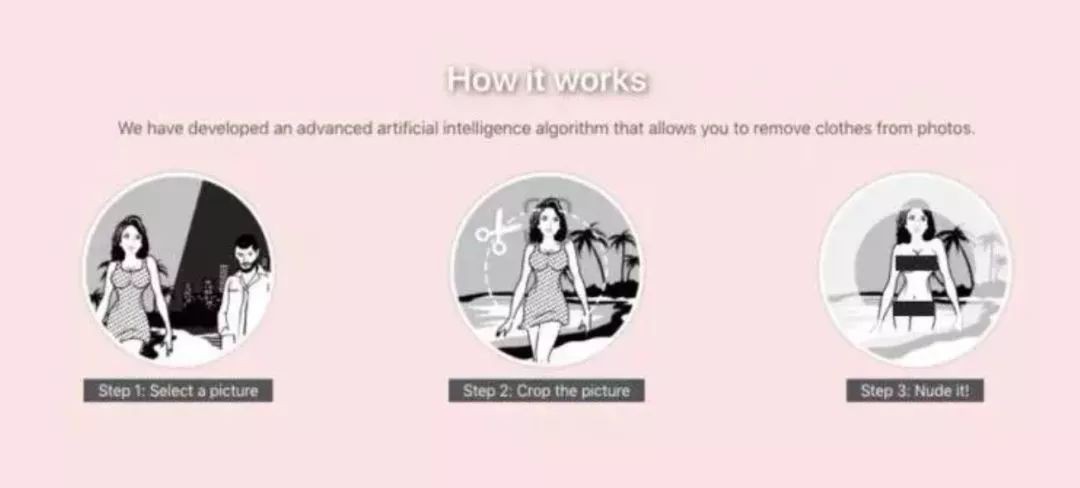
據釋出者表示,研發團隊是個很小的團隊,相關技術顯然也還很不成熟,多數照片(尤其是低解析度照片)經過DeepNude處理後,得出的影象會有人工痕跡;而輸入卡通人物照片,得出的影象是完全扭曲的,大多數影象和低解析度影象會產生一些視覺偽像。
這一應用瞬間引發了社群的各類聲討,表示是對AI利用的反例。
連吳恩達也出面發聲,聲討這一專案。
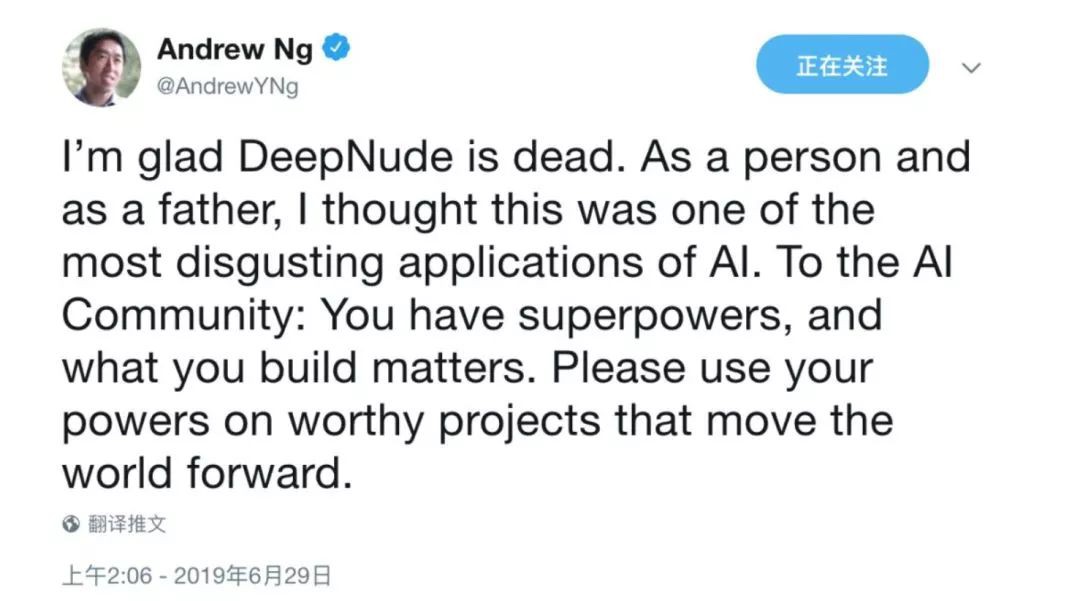
該應用在一片討伐聲中很快下線,但是,餘震猶存。
尤其是對這一應用背後技術的探討還一直在持續。
本週,一個名為“研究DeepNude使用的影象生成和影象修複相關的技術和論文“的GitHub升至一週熱榜,獲得了不少星標。
專案創始人顯然對於這一專案背後的技術很有研究,提出了其生成需要的一系列技術框架,以及哪些技術可能有更好的實現效果。在此我們進行轉載,希望各位極客在滿足技術好奇心的同時,也可以正確使用自己手中的技術力量。
以下為原文內容:
接下來我會開源一些image/text/random-to-image的神經網路模型,僅供學習交流之用,也歡迎分享你的技術解決方案。
01 Image-to-Image Demo影象到影象demo
DeepNude軟體主要使用Image Inpainting for Irregular Holes Using Partial Convolutions 中提出的Image-to-Image技術,該技術有很多其它的應用,比如把黑白的簡筆畫轉換成色彩豐富的彩圖,你可以點選下方的連結在瀏覽器中嘗試Image-to-Image技術。
https://affinelayer.com/pixsrv/
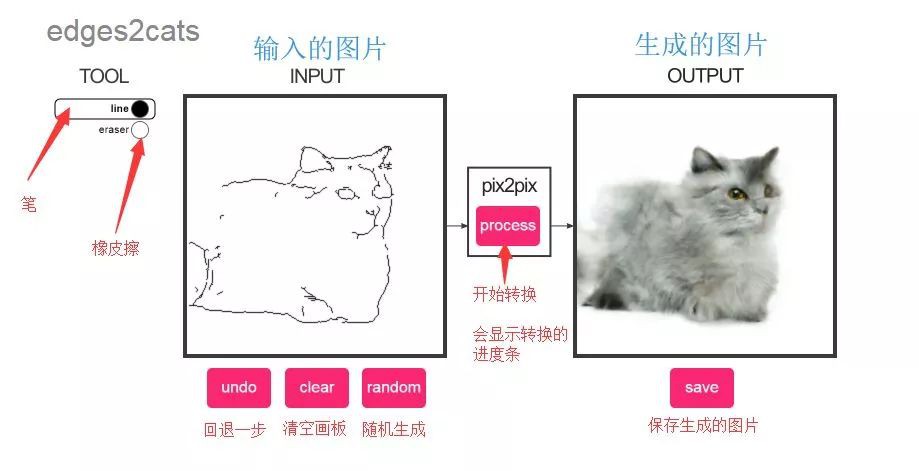
在左側框中按照自己想象畫一個簡筆畫的貓,再點選pix2pix按鈕,就能輸出一個模型生成的貓。
02 Deep Computer Vision in DeepNude
1. Image Inpainting影象修複
-
論文:
NVIDIA 2018 paper Image Inpainting for Irregular Holes Using Partial Convolutions and Partial Convolution based Padding.
-
程式碼:Paper code partialconv

▲效果
在Image_Inpainting(NVIDIA_2018).mp4影片中左側的操作介面,只需用工具將影象中不需要的內容簡單塗抹掉,哪怕形狀很不規則,NVIDIA的模型能夠將影象“複原”,用非常逼真的畫面填補被塗抹的空白。可謂是一鍵P圖,而且“毫無ps痕跡”。
該研究來自Nvidia的Guilin Liu等人的團隊,他們釋出了一種可以編輯影象或重建已損壞影象的深度學習方法,即使影象穿了個洞或丟失了畫素。這是目前2018 state-of-the-art的方法。
2. Pix2Pix(need for paired train data)
DeepNude mainly uses this Pix2Pix technology.
-
論文 :
Berkeley 2017 paper Image-to-Image Translation with Conditional Adversarial Networks.
-
主頁 :
homepage Image-to-Image Translation with Conditional Adversarial Nets
-
程式碼:code pix2pix
-
Run in Google Colab:pix2pix.ipynb
Image-to-Image Translation with Conditional Adversarial Networks是伯克利大學研究提出的使用條件對抗網路作為影象到影象轉換問題的通用解決方案。
3. CycleGAN(without the need for paired train data)
-
論文:
Berkeley 2017 paper Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks
-
程式碼:code CycleGAN
-
Run in Google Colab:cyclegan.ipynb

▲效果
CycleGAN使用迴圈一致性損失函式來實現訓練,而無需配對資料。換句話說,它可以從一個域轉換到另一個域,而無需在源域和標的域之間進行一對一對映。這開啟了執行許多有趣任務的可能性,例如照片增強,影象著色,樣式傳輸等。您只需要源和標的資料集。
03 未來
可能不需要Image-to-Image。我們可以使用GAN直接從隨機值生成影象或從文字生成影象。
1. Obj-GAN
微軟人工智慧研究院(Microsoft Research AI)開發的新AI技術Obj-GAN可以理解自然語言描述、繪製草圖、合成影象,然後根據草圖框架和文字提供的個別單詞細化細節。換句話說,這個網路可以根據描述日常場景的文字描述生成同樣場景的影象。
▲效果
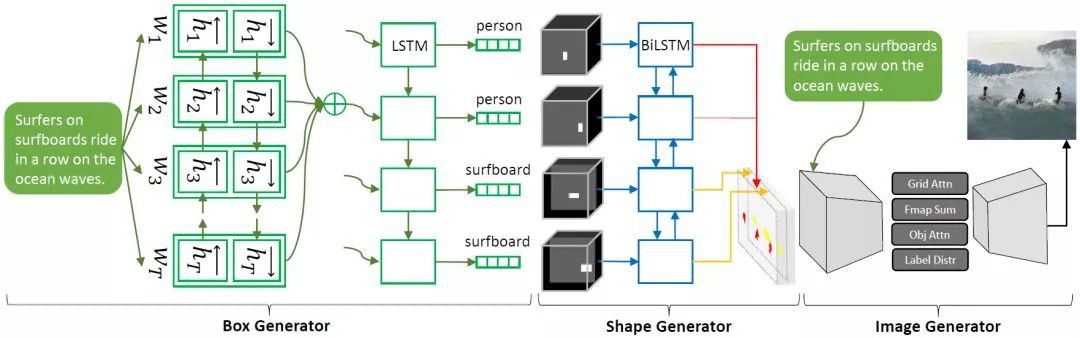
▲模型
2. StoryGAN
進階版神筆:只需一句話、一個故事,即可生成畫面。
微軟新研究提出新型GAN——ObjGAN,可根據文字描述生成複雜場景。他們還提出另一個可以畫故事的GAN——StoryGAN,輸入一個故事的文字,即可輸出「連環畫」。
當前最優的文字到影象生成模型可以基於單句描述生成逼真的鳥類影象。然而,文字到影象生成器遠遠不止僅對一個句子生成單個影象。給定一個多句段落,生成一系列影象,每個影象對應一個句子,完整地視覺化整個故事。
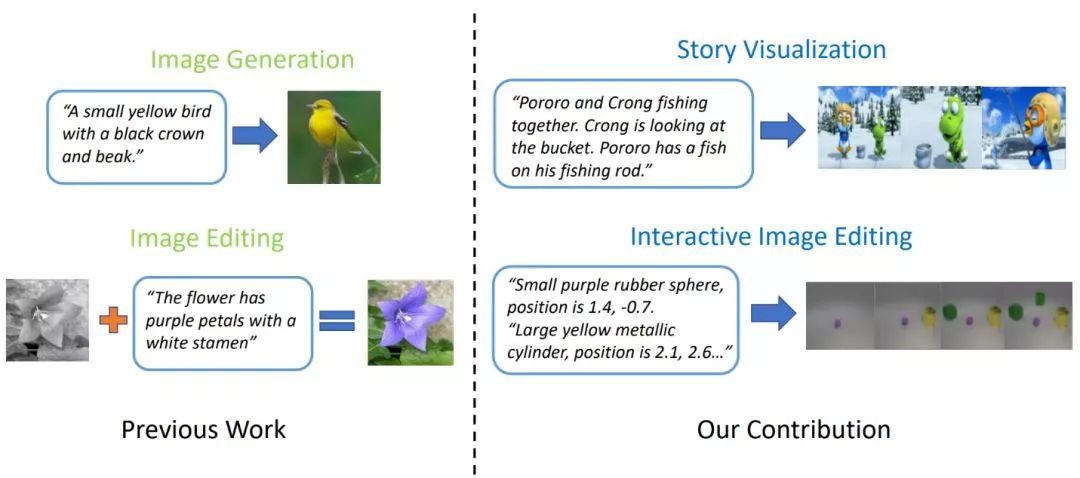
▲效果
現在用得最多的Image-to-Image技術應該就是美顏APP了,所以我們為什麼不開發一個更加智慧的美顏相機呢?
朋友會在“發現-看一看”看到你“在看”的內容