剛開始寫這篇文章的時候,標的非常大,想要探索 Go 程式的一生:編碼、編譯、彙編、連結、執行、退出。它的每一步具體如何進行,力圖弄清 Go 程式的這一生。
在這個過程中,我又複習了一遍《程式員的自我修養》。這是一本講編譯、連結的書,非常詳細,值得一看!數年前,我第一次看到這本書的書名,就非常喜歡。因為它模仿了周星馳喜劇之王裡出現的一本書 ——《演員的自我修養》。心嚮往之!
在開始本文之前,先推薦一位頭條大佬的部落格——《面向信仰程式設計》,他的 Go 編譯系列文章,非常有深度,直接深入編譯器原始碼,我是看了很多遍了。部落格連結可以從參考資料裡獲取。
理想很大,實現的難度也是非常大。為了避免砸了“深度解密”這個牌子,這次起了個更溫和的名字,嘿嘿。
下麵是文章的目錄:

引入
我們從一個 HelloWorld 的例子開始:
-
package main -
-
import "fmt" -
-
func main() { -
fmt.Println("hello world") -
}
當我用我那價值 1800 元的 cherry 鍵盤瀟灑地敲完上面的 hello world 程式碼時,儲存在硬碟上的 hello.go 檔案就是一個位元組序列了,每個位元組代表一個字元。
用 vim 開啟 hello.go 檔案,在命令列樣式下,輸入命令:
-
:%!xxd
就能在 vim 裡以十六進位制檢視檔案內容:

最左邊的一列代表地址值,中間一列代表文字對應的 ASCII 字元,最右邊的列就是我們的程式碼。再在終端裡執行 man ascii:
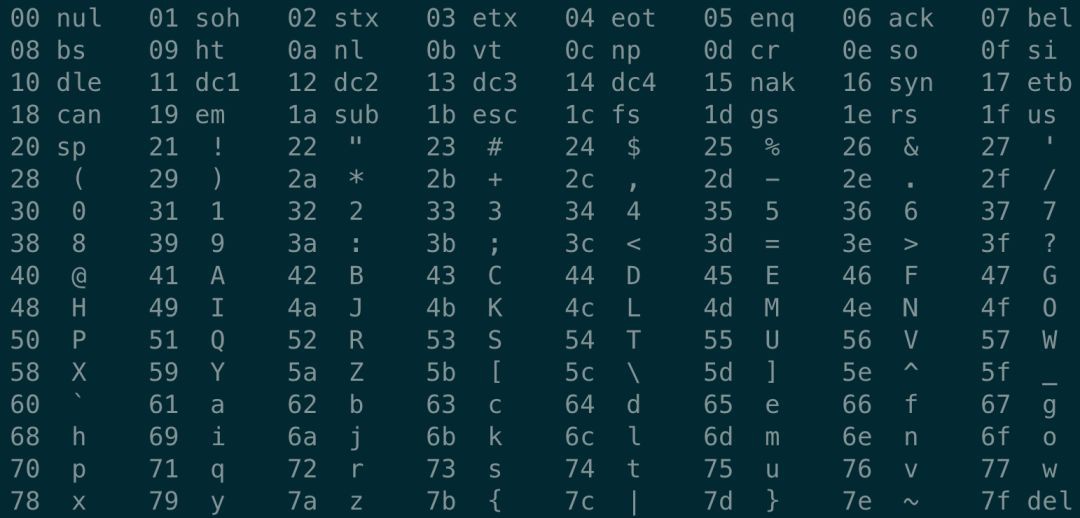
和 ASCII 字元表一對比,就能發現,中間的列和最右邊的列是一一對應的。也就是說,剛剛寫完的 hello.go 檔案都是由 ASCII 字元表示的,它被稱為 文字檔案,其他檔案被稱為 二進位制檔案。
當然,更深入地看,計算機中的所有資料,像磁碟檔案、網路中的資料其實都是一串位元位組成,取決於如何看待它。在不同的情景下,一個相同的位元組序列可能表示成一個整數、浮點數、字串或者是機器指令。
而像 hello.go 這個檔案,8 個 bit,也就是一個位元組看成一個單位(假定源程式的字元都是 ASCII 碼),最終解釋成人類能讀懂的 Go 原始碼。
Go 程式並不能直接執行,每條 Go 陳述句必須轉化為一系列的低階機器語言指令,將這些指令打包到一起,並以二進位制磁碟檔案的形式儲存起來,也就是可執行標的檔案。
從源檔案到可執行標的檔案的轉化過程:
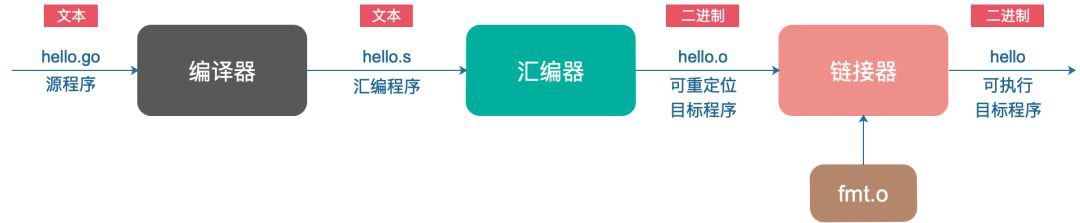
完成以上各個階段的就是 Go 編譯系統。你肯定知道大名鼎鼎的 GCC(GNU Compile Collection),中文名為 GNU 編譯器套裝,它支援像 C,C++,Java,Python,Objective-C,Ada,Fortran,Pascal,能夠為很多不同的機器生成機器碼。
可執行標的檔案可以直接在機器上執行。一般而言,先執行一些初始化的工作;找到 main 函式的入口,執行使用者寫的程式碼;執行完成後,main 函式退出;再執行一些收尾的工作,整個過程完畢。
在接下來的文章裡,我們將探索 編譯和 執行的過程。
編譯連結概述
Go 原始碼裡的編譯器原始碼位於 src/cmd/compile 路徑下,聯結器原始碼位於 src/cmd/link路徑下。
編譯過程
我比較喜歡用 IDE(整合開發環境)來寫程式碼, Go 原始碼用的 Goland,有時候直接點選 IDE 選單欄裡的“執行”按鈕,程式就跑起來了。這實際上隱含了編譯和連結的過程,我們通常將編譯和鏈接合併到一起的過程稱為構建(Build)。
編譯過程就是對源檔案進行詞法分析、語法分析、語意分析、最佳化,最後生成彙編程式碼檔案,以 .s 作為檔案字尾。
之後,彙編器會將彙編程式碼轉變成機器可以執行的指令。由於每一條彙編陳述句幾乎都與一條機器指令相對應,所以只是一個簡單的一一對應,比較簡單,沒有語法、語意分析,也沒有最佳化這些步驟。
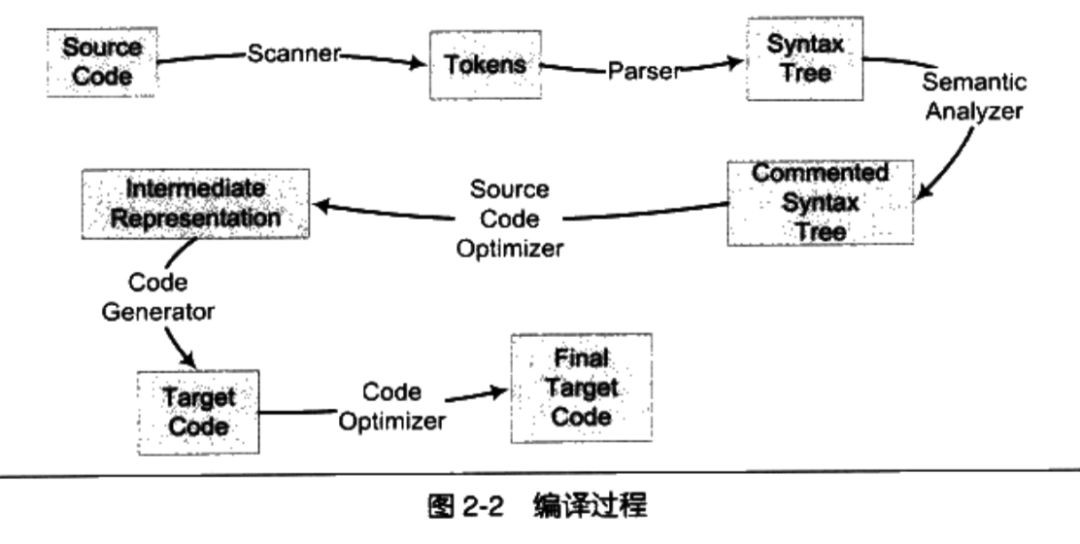
編譯器是將高階語言翻譯成機器語言的一個工具,編譯過程一般分為 6 步:掃描、語法分析、語意分析、原始碼最佳化、程式碼生成、標的程式碼最佳化。下圖來自《程式員的自我修養》:
詞法分析
透過前面的例子,我們知道,Go 程式檔案在機器看來不過是一堆二進位制位。我們能讀懂,是因為 Goland 按照 ASCII 碼(實際上是 UTF-8)把這堆二進位制位進行了編碼。例如,把 8個 bit 位分成一組,對應一個字元,透過對照 ASCII 碼表就可以查出來。
當把所有的二進位制位都對應成了 ASCII 碼字元後,我們就能看到有意義的字串。它可能是關鍵字,例如:package;可能是字串,例如:“Hello World”。
詞法分析其實幹的就是這個。輸入是原始的 Go 程式檔案,在詞法分析器看來,就是一堆二進位制位,根本不知道是什麼東西,經過它的分析後,變成有意義的記號。簡單來說,詞法分析是電腦科學中將字元序列轉換為標記(token)序列的過程。
我們來看一下維基百科上給出的定義:
詞法分析(lexical analysis)是電腦科學中將字元序列轉換為標記(token)序列的過程。進行詞法分析的程式或者函式叫作詞法分析器(lexical analyzer,簡稱lexer),也叫掃描器(scanner)。詞法分析器一般以函式的形式存在,供語法分析器呼叫。
.go 檔案被輸入到掃描器(Scanner),它使用一種類似於 有限狀態機的演演算法,將原始碼的字元系列分割成一系列的記號(Token)。
記號一般分為這幾類:關鍵字、識別符號、字面量(包含數字、字串)、特殊符號(如加號、等號)。
例如,對於如下的程式碼:
-
slice[i] = i * (2 + 6)
總共包含 16 個非空字元,經過掃描後,
| 記號 | 型別 |
|---|---|
| slice | 識別符號 |
| [ | 左方括號 |
| i | 識別符號 |
| ] | 右方括號 |
| = | 賦值 |
| i | 識別符號 |
| * | 乘號 |
| ( | 左圓括號 |
| 2 | 數字 |
| + | 加號 |
| 6 | 數字 |
| ) | 右圓括號 |
上面的例子源自《程式員的自我修養》,主要講解編譯、連結相關的內容,很精彩,推薦研讀。
Go 語言(本文的 Go 版本是 1.9.2)掃描器支援的 Token 在原始碼中的路徑:
-
src/cmd/compile/internal/syntax/token.go
感受一下:
-
var tokstrings = [...]string{ -
// source control -
_EOF: "EOF", -
-
// names and literals -
_Name: "name", -
_Literal: "literal", -
-
// operators and operations -
_Operator: "op", -
_AssignOp: "op=", -
_IncOp: "opop", -
_Assign: "=", -
_Define: ":=", -
_Arrow: ", -
_Star: "*", -
-
// delimitors -
_Lparen: "(", -
_Lbrack: "[", -
_Lbrace: "{", -
_Rparen: ")", -
_Rbrack: "]", -
_Rbrace: "}", -
_Comma: ",", -
_Semi: ";", -
_Colon: ":", -
_Dot: ".", -
_DotDotDot: "...", -
-
// keywords -
_Break: "break", -
_Case: "case", -
_Chan: "chan", -
_Const: "const", -
_Continue: "continue", -
_Default: "default", -
_Defer: "defer", -
_Else: "else", -
_Fallthrough: "fallthrough", -
_For: "for", -
_Func: "func", -
_Go: "go", -
_Goto: "goto", -
_If: "if", -
_Import: "import", -
_Interface: "interface", -
_Map: "map", -
_Package: "package", -
_Range: "range", -
_Return: "return", -
_Select: "select", -
_Struct: "struct", -
_Switch: "switch", -
_Type: "type", -
_Var: "var", -
}
還是比較熟悉的,包括名稱和字面量、運運算元、分隔符和關鍵字。
而掃描器的路徑是:
-
src/cmd/compile/internal/syntax/scanner.go
其中最關鍵的函式就是 next 函式,它不斷地讀取下一個字元(不是下一個位元組,因為 Go 語言支援 Unicode 編碼,並不是像我們前面舉得 ASCII 碼的例子,一個字元只有一個位元組),直到這些字元可以構成一個 Token。
-
func (s *scanner) next() { -
// …… -
-
redo: -
// skip white space -
c := s.getr() -
for c == ' ' || c == '\t' || c == '\n' && !nlsemi || c == '\r' { -
c = s.getr() -
} -
-
// token start -
s.line, s.col = s.source.line0, s.source.col0 -
-
if isLetter(c) || c >= utf8.RuneSelf && s.isIdentRune(c, true) { -
s.ident() -
return -
} -
-
switch c { -
// …… -
-
case '\n': -
s.lit = "newline" -
s.tok = _Semi -
-
case '0', '1', '2', '3', '4', '5', '6', '7', '8', '9': -
s.number(c) -
-
// …… -
-
default: -
s.tok = 0 -
s.error(fmt.Sprintf("invalid character %#U", c)) -
goto redo -
return -
-
assignop: -
if c == '=' { -
s.tok = _AssignOp -
return -
} -
s.ungetr() -
s.tok = _Operator -
}
程式碼的主要邏輯就是透過 c:=s.getr() 獲取下一個未被解析的字元,並且會跳過之後的空格、回車、換行、tab 字元,然後進入一個大的 switch-case 陳述句,匹配各種不同的情形,最終可以解析出一個 Token,並且把相關的行、列數字記錄下來,這樣就完成一次解析過程。
當前包中的詞法分析器 scanner 也只是為上層提供了 next 方法,詞法解析的過程都是惰性的,只有在上層的解析器需要時才會呼叫 next 獲取最新的 Token。
語法分析
上一步生成的 Token 序列,需要經過進一步處理,生成一棵以 運算式為結點的 語法樹。
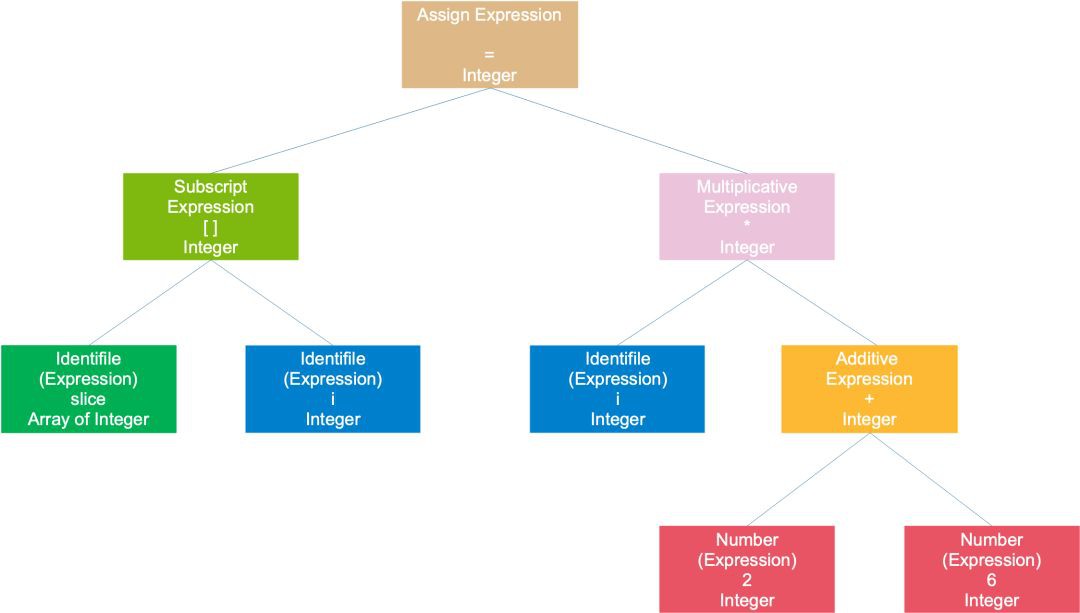
比如最開始的那個例子, slice[i]=i*(2+6),得到的一棵語法樹如下:
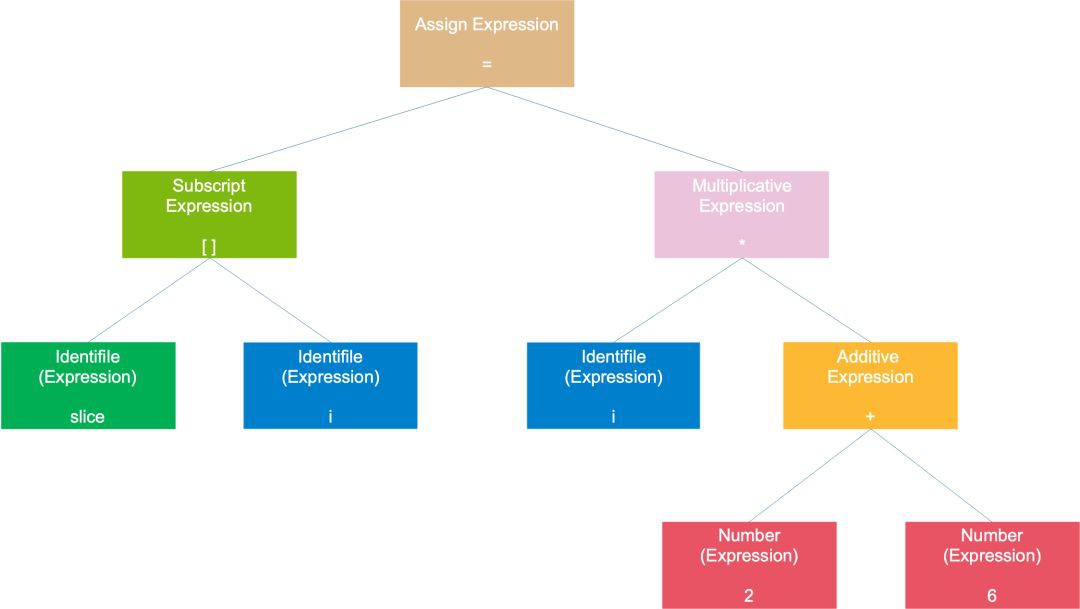
整個陳述句被看作是一個賦值運算式,左子樹是一個陣列運算式,右子樹是一個乘法運算式;陣列運算式由 2 個符號運算式組成;乘號運算式則是由一個符號運算式和一個加號運算式組成;加號運算式則是由兩個數字組成。符號和數字是最小的運算式,它們不能再被分解,通常作為樹的葉子節點。
語法分析的過程可以檢測一些形式上的錯誤,例如:括號是否缺少一半, + 號運算式缺少一個運算元等。
語法分析是根據某種特定的形式文法(Grammar)對 Token 序列構成的輸入文字進行分析並確定其語法結構的一種過程。
語意分析
語法分析完成後,我們並不知道陳述句的具體意義是什麼。像上面的 * 號的兩棵子樹如果是兩個指標,這是不合法的,但語法分析檢測不出來,語意分析就是乾這個事。
編譯期所能檢查的是靜態語意,可以認為這是在“程式碼”階段,包括變數型別的匹配、轉換等。例如,將一個浮點值賦給一個指標變數的時候,明顯的型別不匹配,就會報編譯錯誤。而對於執行期間才會出現的錯誤:不小心除了一個 0 ,語意分析是沒辦法檢測的。
語意分析階段完成之後,會在每個節點上標註上型別:
Go 語言編譯器在這一階段檢查常量、型別、函式宣告以及變數賦值陳述句的型別,然後檢查雜湊中鍵的型別。實現型別檢查的函式通常都是幾千行的巨型 switch/case 陳述句。
型別檢查是 Go 語言編譯的第二個階段,在詞法和語法分析之後我們得到了每個檔案對應的抽象語法樹,隨後的型別檢查會遍歷抽象語法樹中的節點,對每個節點的型別進行檢驗,找出其中存在的語法錯誤。
在這個過程中也可能會對抽象語法樹進行改寫,這不僅能夠去除一些不會被執行的程式碼對編譯進行最佳化提高執行效率,而且也會修改 make、new 等關鍵字對應節點的操作型別。
例如比較常用的 make 關鍵字,用它可以建立各種型別,如 slice,map,channel 等等。到這一步的時候,對於 make 關鍵字,也就是 OMAKE 節點,會先檢查它的引數型別,根據型別的不同,進入相應的分支。如果引數型別是 slice,就會進入 TSLICE case 分支,檢查 len 和 cap 是否滿足要求,如 len <= cap。最後節點型別會從 OMAKE 改成 OMAKESLICE。
中間程式碼生成
我們知道,編譯過程一般可以分為前端和後端,前端生成和平臺無關的中間程式碼,後端會針對不同的平臺,生成不同的機器碼。
前面詞法分析、語法分析、語意分析等都屬於編譯器前端,之後的階段屬於編譯器後端。
編譯過程有很多最佳化的環節,在這個環節是指原始碼級別的最佳化。它將語法樹轉換成中間程式碼,它是語法樹的順序表示。
中間程式碼一般和標的機器以及執行時環境無關,它有幾種常見的形式:三地址碼、P-程式碼。例如,最基本的 三地址碼是這樣的:
-
x = y op z
表示變數 y 和 變數 z 進行 op 操作後,賦值給 x。op 可以是數學運算,例如加減乘除。
前面我們舉的例子可以寫成如下的形式:
-
t1 = 2 + 6 -
t2 = i * t1 -
slice[i] = t2
這裡 2 + 6 是可以直接計算出來的,這樣就把 t1 這個臨時變數“最佳化”掉了,而且 t1 變數可以重覆利用,因此 t2 也可以“最佳化”掉。最佳化之後:
-
t1 = i * 8 -
slice[i] = t1
Go 語言的中間程式碼表示形式為 SSA(Static Single-Assignment,靜態單賦值),之所以稱之為單賦值,是因為每個名字在 SSA 中僅被賦值一次。。
這一階段會根據 CPU 的架構設定相應的用於生成中間程式碼的變數,例如編譯器使用的指標和暫存器的大小、可用暫存器串列等。中間程式碼生成和機器碼生成這兩部分會共享相同的設定。
在生成中間程式碼之前,會對抽象語法樹中節點的一些元素進行替換。這裡取用《面向信仰程式設計》編譯原理相關部落格裡的一張圖:
例如對於 map 的操作 m[i],在這裡會被轉換成 mapacess 或 mapassign。
Go 語言的主程式在執行時會呼叫 runtime 中的函式,也就是說關鍵字和內建函式的功能其實是由語言的編譯器和執行時共同完成的。
中間程式碼的生成過程其實就是從 AST 抽象語法樹到 SSA 中間程式碼的轉換過程,在這期間會對語法樹中的關鍵字在進行一次更新,更新後的語法樹會經過多輪處理轉變最後的 SSA 中間程式碼。
標的程式碼生成與最佳化
不同機器的機器字長、暫存器等等都不一樣,意味著在不同機器上跑的機器碼是不一樣的。最後一步的目的就是要生成能在不同 CPU 架構上執行的程式碼。
為了榨乾機器的每一滴油水,標的程式碼最佳化器會對一些指令進行最佳化,例如使用移位指令代替乘法指令等。
這塊實在沒能力深入,幸好也不需要深入。對於應用層的軟體開發工程師來說,瞭解一下就可以了。
連結過程
編譯過程是針對單個檔案進行的,檔案與檔案之間不可避免地要取用定義在其他模組的全域性變數或者函式,這些變數或函式的地址只有在此階段才能確定。
連結過程就是要把編譯器生成的一個個標的檔案連結成可執行檔案。最終得到的檔案是分成各種段的,比如資料段、程式碼段、BSS段等等,執行時會被裝載到記憶體中。各個段具有不同的讀寫、執行屬性,保護了程式的安全執行。
這部分內容,推薦看《程式員的自我修養》和《深入理解計算機系統》。
Go 程式啟動
仍然使用 hello-world 專案的例子。在專案根目錄下執行:
-
go build -gcflags "-N -l" -o hello src/main.go
-gcflags"-N -l" 是為了關閉編譯器最佳化和函式行內,防止後面在設定斷點的時候找不到相對應的程式碼位置。
得到了可執行檔案 hello,執行:
-
[qcrao@qcrao hello-world]$ gdb hello
進入 gdb 除錯樣式,執行 info files,得到可執行檔案的檔案頭,列出了各種段:
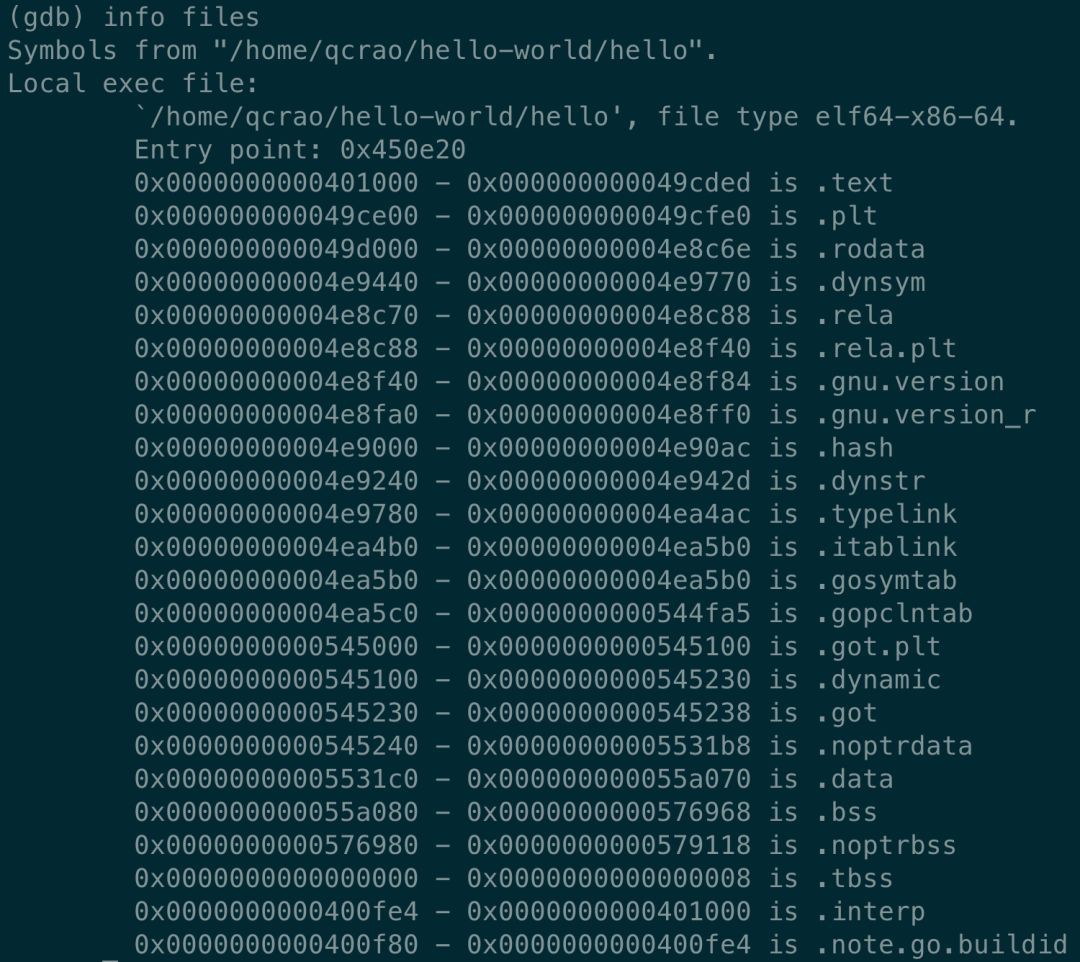
同時,我們也得到了入口地址:0x450e20。
-
(gdb) b *0x450e20 -
Breakpoint 1 at 0x450e20: file /usr/local/go/src/runtime/rt0_linux_amd64.s, line 8.
這就是 Go 程式的入口地址,我是在 linux 上執行的,所以入口檔案為 src/runtime/rt0_linux_amd64.s,runtime 目錄下有各種不同名稱的程式入口檔案,支援各種作業系統和架構,程式碼為:
-
TEXT _rt0_amd64_linux(SB),NOSPLIT,$-8 -
LEAQ 8(SP), SI // argv -
MOVQ 0(SP), DI // argc -
MOVQ $main(SB), AX -
JMP AX
主要是把 argc,argv 從記憶體拉到了暫存器。這裡 LEAQ 是計算記憶體地址,然後把記憶體地址本身放進暫存器裡,也就是把 argv 的地址放到了 SI 暫存器中。最後跳轉到:
-
TEXT main(SB),NOSPLIT,$-8 -
MOVQ $runtime·rt0_go(SB), AX -
JMP AX
繼續跳轉到 runtime·rt0_go(SB),位置:/usr/local/go/src/runtime/asm_amd64.s,程式碼:
-
TEXT runtime·rt0_go(SB),NOSPLIT,$0 -
// 省略很多 CPU 相關的特性標誌位檢查的程式碼 -
// 主要是看不懂,^_^ -
-
// ……………………………… -
-
// 下麵是最後呼叫的一些函式,比較重要 -
// 初始化執行檔案的絕對路徑 -
CALL runtime·args(SB) -
// 初始化 CPU 個數和記憶體頁大小 -
CALL runtime·osinit(SB) -
// 初始化命令列引數、環境變數、gc、棧空間、記憶體管理、所有 P 實體、HASH演演算法等 -
CALL runtime·schedinit(SB) -
-
// 要在 main goroutine 上執行的函式 -
MOVQ $runtime·mainPC(SB), AX // entry -
PUSHQ AX -
PUSHQ $0 // arg size -
-
// 新建一個 goroutine,該 goroutine 系結 runtime.main,放在 P 的本地佇列,等待排程 -
CALL runtime·newproc(SB) -
POPQ AX -
POPQ AX -
-
// 啟動M,開始排程goroutine -
CALL runtime·mstart(SB) -
-
MOVL $0xf1, 0xf1 // crash -
RET -
-
-
DATA runtime·mainPC+0(SB)/8,$runtime·main(SB) -
GLOBL runtime·mainPC(SB),RODATA,$8
參考文獻裡的一篇文章【探索 golang 程式啟動過程】研究得比較深入,總結下:
檢查執行平臺的CPU,設定好程式執行需要相關標誌。
TLS的初始化。
runtime.args、runtime.osinit、runtime.schedinit 三個方法做好程式執行需要的各種變數與排程器。
runtime.newproc建立新的goroutine用於系結使用者寫的main方法。
runtime.mstart開始goroutine的排程。
最後用一張圖來總結 go bootstrap 過程吧:
main 函式裡執行的一些重要的操作包括:新建一個執行緒執行 sysmon 函式,定期垃圾回收和排程搶佔;啟動 gc;執行所有的 init 函式等等。
上面是啟動過程,看一下退出過程:
當 main 函式執行結束之後,會執行 exit(0) 來退出行程。若執行 exit(0) 後,行程沒有退出,main 函式最後的程式碼會一直訪問非法地址:
-
exit(0) -
for { -
var x *int32 -
*x = 0 -
}
正常情況下,一旦出現非法地址訪問,系統會把行程殺死,用這樣的方法確保行程退出。
關於程式退出這一段的闡述來自群聊《golang runtime 閱讀》,又是一個高階的讀原始碼的組織,github 主頁見參考資料。
當然 Go 程式啟動這一部分其實還會涉及到 fork 一個新行程、裝載可執行檔案,控制權轉移等問題。還是推薦看前面的兩本書,我覺得我不會寫得更好,就不敘述了。
GoRoot 和 GoPath
GoRoot 是 Go 的安裝路徑。mac 或 unix 是在 /usr/local/go 路徑上,來看下這裡都裝了些什麼:
bin 目錄下麵:

pkg 目錄下麵:
Go 工具目錄如下,其中比較重要的有編譯器 compile,聯結器 link:

GoPath 的作用在於提供一個可以尋找 .go 原始碼的路徑,它是一個工作空間的概念,可以設定多個目錄。Go 官方要求,GoPath 下麵需要包含三個檔案夾:
-
src -
pkg -
bin
src 存放源檔案,pkg 存放源檔案編譯後的庫檔案,字尾為 .a;bin 則存放可執行檔案。
Go 命令詳解
直接在終端執行:
-
go
就能得到和 go 相關的命令簡介:
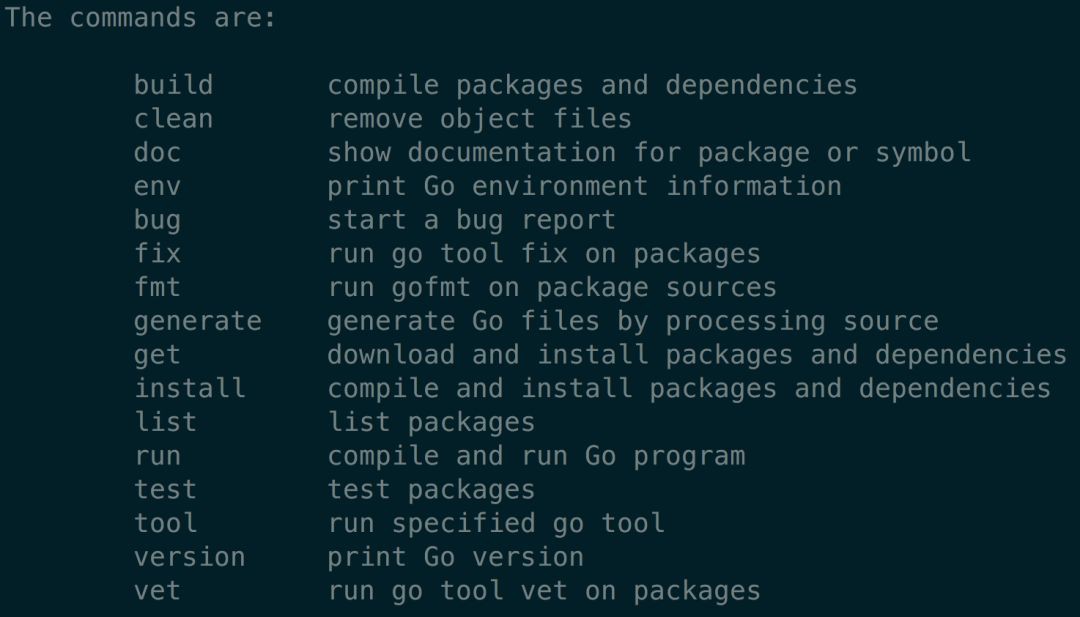
和編譯相關的命令主要是:
-
go build -
go install -
go run
go build
go build 用來編譯指定 packages 裡的原始碼檔案以及它們的依賴包,編譯的時候會到 $GoPath/src/package 路徑下尋找原始碼檔案。go build 還可以直接編譯指定的原始碼檔案,並且可以同時指定多個。
透過執行 go help build 命令得到 go build 的使用方法:
-
usage: go build [-o output] [-i] [build flags] [packages]
-o 只能在編譯單個包的時候出現,它指定輸出的可執行檔案的名字。
-i 會安裝編譯標的所依賴的包,安裝是指生成與程式碼包相對應的 .a 檔案,即靜態庫檔案(後面要參與連結),並且放置到當前工作區的 pkg 目錄下,且庫檔案的目錄層級和原始碼層級一致。
至於 build flags 引數, build,clean,get,install,list,run,test 這些命令會共用一套:
| 引數 | 作用 |
|---|---|
| -a | 強制重新編譯所有涉及到的包,包括標準庫中的程式碼包,這會重寫 /usr/local/go 目錄下的 .a 檔案 |
| -n | 列印命令執行過程,不真正執行 |
| -p n | 指定編譯過程中命令執行的並行數,n 預設為 CPU 核數 |
| -race | 檢測並報告程式中的資料競爭問題 |
| -v | 列印命令執行過程中所涉及到的程式碼包名稱 |
| -x | 列印命令執行過程中所涉及到的命令,並執行 |
| -work | 列印編譯過程中的臨時檔案夾。通常情況下,編譯完成後會被刪除 |
我們知道,Go 語言的原始碼檔案分為三類:命令原始碼、庫原始碼、測試原始碼。
命令原始碼檔案:是 Go 程式的入口,包含
func main()函式,且第一行用packagemain宣告屬於 main 包。庫原始碼檔案:主要是各種函式、介面等,例如工具類的函式。
測試原始碼檔案:以
_test.go為字尾的檔案,用於測試程式的功能和效能。
註意, go build 會忽略 *_test.go 檔案。
我們透過一個很簡單的例子來演示 go build 命令。我用 Goland 新建了一個 hello-world專案(為了展示取用自定義的包,和之前的 hello-world 程式不同),專案的結構如下:
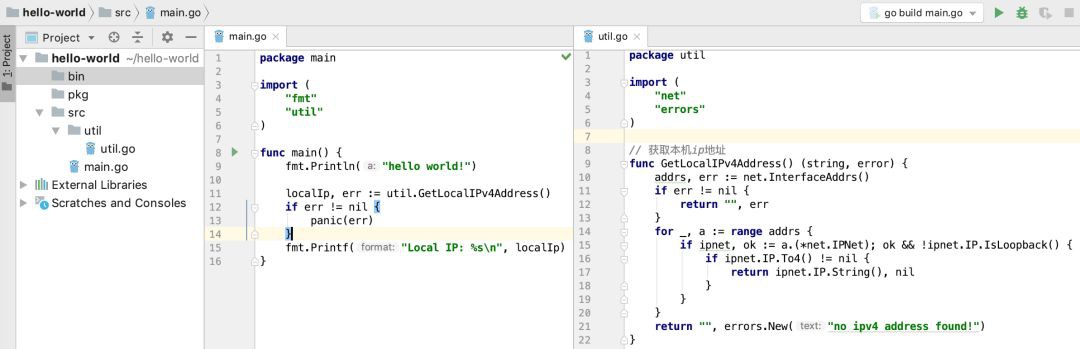
最左邊可以看到專案的結構,包含三個檔案夾:bin,pkg,src。其中 src 目錄下有一個 main.go,裡面定義了 main 函式,是整個專案的入口,也就是前面提過的所謂的命令原始碼檔案;src 目錄下還有一個 util 目錄,裡面有 util.go 檔案,定義了一個可以獲取本機 IP 地址的函式,也就是所謂的庫原始碼檔案。
中間是 main.go 的原始碼,取用了兩個包,一個是標準庫的 fmt;一個是 util 包,util 的匯入路徑是 util。所謂的匯入路徑是指相對於 Go 的原始碼目錄 $GoRoot/src 或者 $GoPath/src 的下的子路徑。例如 main 包裡取用的 fmt 的原始碼路徑是 /usr/local/go/src/fmt,而 util 的原始碼路徑是 /Users/qcrao/hello-world/src/util,正好我們設定的 GoPath = /Users/qcrao/hello-world。
最右邊是庫函式的原始碼,實現了獲取本機 IP 的函式。
在 src 目錄下,直接執行 go build 命令,在同級目錄生成了一個可執行檔案,檔案名為 src,使用 ./src 命令直接執行,輸出:
-
hello world! -
Local IP: 192.168.1.3
我們也可以指定生成的可執行檔案的名稱:
-
go build -o bin/hello
這樣,在 bin 目錄下會生成一個可執行檔案,執行結果和上面的 src 一樣。
其實,util 包可以單獨被編譯。我們可以在專案根目錄下執行:
-
go build util
編譯程式會去 $GoPath/src 路徑找 util 包(其實是找檔案夾)。還可以在 ./src/util 目錄下直接執行 go build 編譯。
當然,直接編譯庫原始碼檔案不會生成 .a 檔案,因為:
go build 命令在編譯只包含庫原始碼檔案的程式碼包(或者同時編譯多個程式碼包)時,只會做檢查性的編譯,而不會輸出任何結果檔案。
為了展示整個編譯連結的執行過程,我們在專案根目錄執行如下的命令:
-
go build -v -x -work -o bin/hello src/main.go
-v 會列印所編譯過的包名字, -x 列印編譯期間所執行的命令, -work 列印編譯期間生成的臨時檔案路徑,並且編譯完成之後不會被刪除。
執行結果:
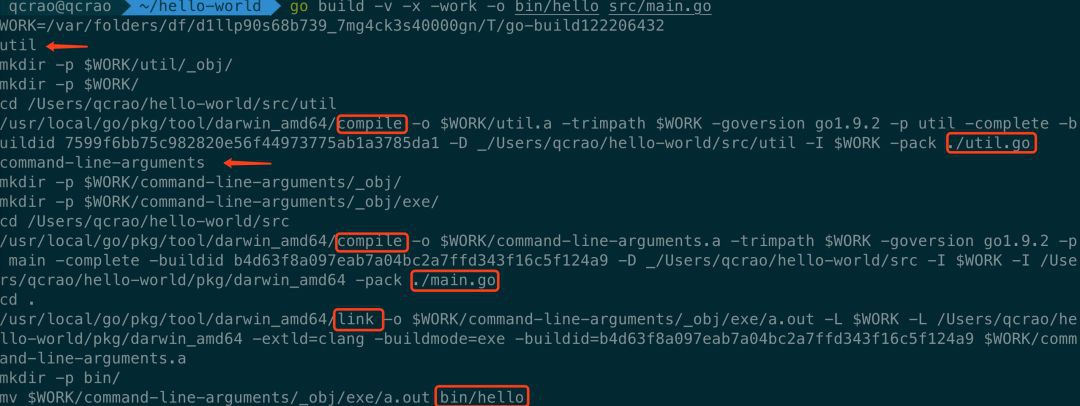
從結果來看,圖中用箭頭標註了本次編譯過程涉及 2 個包:util,command-line-arguments。第二個包比較詭異,原始碼里根本就沒有這個名字好嗎?其實這是 go build 命令檢測到 [packages] 處填的是一個 .go 檔案,因此建立了一個虛擬的包:command-line-arguments。
同時,用紅框圈出了 compile, link,也就是先編譯了 util 包和 main.go 檔案,分別得到 .a檔案,之後將兩者進行連結,最終生成可執行檔案,並且移動到 bin 目錄下,改名為 hello。
另外,第一行顯示了編譯過程中的工作目錄,此目錄的檔案結構是:

可以看到,和 hello-world 目錄的層級基本一致。command-line-arguments 就是虛擬的 main.go 檔案所處的包。exe 目錄下的可執行檔案在最後一步被移動到了 bin 目錄下,所以這裡是空的。
整體來看, go build 在執行時,會先遞迴尋找 main.go 所依賴的包,以及依賴的依賴,直至最底層的包。這裡可以是深度優先遍歷也可以是寬度優先遍歷。如果發現有迴圈依賴,就會直接退出,這也是經常會發生的迴圈取用編譯錯誤。
正常情況下,這些依賴關係會形成一棵倒著生長的樹,樹根在最上面,就是 main.go 檔案,最下麵是沒有任何其他依賴的包。編譯器會從最左的節點所代表的包開始挨個編譯,完成之後,再去編譯上一層的包。
這裡,取用郝林老師幾年前在 github 上發表的 go 命令教程,可以從參考資料找到原文地址。
從程式碼包編譯的角度來說,如果程式碼包 A 依賴程式碼包 B,則稱程式碼包 B 是程式碼包 A 的依賴程式碼包(以下簡稱依賴包),程式碼包 A 是程式碼包 B 的觸發程式碼包(以下簡稱觸發包)。
執行
go build命令的計算機如果擁有多個邏輯 CPU 核心,那麼編譯程式碼包的順序可能會存在一些不確定性。但是,它一定會滿足這樣的約束條件:依賴程式碼包 -> 當前程式碼包 -> 觸發程式碼包。
順便推薦一個瀏覽器外掛 Octotree,在看 github 專案的時候,此外掛可以在瀏覽器裡直接展示整個專案的檔案結構,非常方便:
到這裡,你一定會發現,對於 hello-wrold 檔案夾下的 pkg 目錄好像一直沒有涉及到。
其實,pkg 目錄下麵應該存放的是涉及到的庫檔案編譯後的包,也就是一些 .a 檔案。但是 go build 執行過程中,這些 .a 檔案放在臨時檔案夾中,編譯完成後會被直接刪掉,因此一般不會用到。
前面我們提到過,在 go build 命令裡加上 -i 引數會安裝這些庫檔案編譯的包,也就是這些 .a 檔案會放到 pkg 目錄下。
在專案根目錄執行 go build-i src/main.go 後,pkg 目錄裡增加了 util.a 檔案:
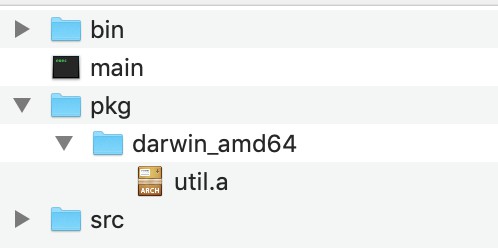
darwin_amd64 表示的是:
GOOS 和 GOARCH。這兩個環境變數不用我們設定,系統預設的。
GOOS 是 Go 所在的作業系統型別,GOARCH 是 Go 所在的計算架構。
Mac 平臺上這個目錄名就是 darwin_amd64。
生成了 util.a 檔案後,再次編譯的時候,就不會再重新編譯 util.go 檔案,加快了編譯速度。
同時,在根目錄下生成了名稱為 main 的可執行檔案,這是以 main.go 的檔案名命令的。
hello-world 這個專案的程式碼已經上傳到了 github 專案 Go-Questions,這個專案由問題匯入,企圖串連 Go 的所有知識點,正在完善,期待你的 star。地址見參考資料【Go-Questions hello-world專案】。
go install
go install 用於編譯並安裝指定的程式碼包及它們的依賴包。相比 go build,它只是多了一個“安裝編譯後的結果檔案到指定目錄”的步驟。
還是使用之前 hello-world 專案的例子,我們先將 pkg 目錄刪掉,在專案根目錄執行:
-
go install src/main.go -
-
或者 -
-
go install util
兩者都會在根目錄下新建一個 pkg 目錄,並且生成一個 util.a 檔案。
並且,在執行前者的時候,會在 GOBIN 目錄下生成名為 main 的可執行檔案。
所以,執行 go install 命令,庫原始碼包對應的 .a 檔案會被放置到 pkg 目錄下,命令原始碼包生成的可執行檔案會被放到 GOBIN 目錄。
go install 在 GoPath 有多個目錄的時候,會產生一些問題,具體可以去看郝林老師的 Go命令教程,這裡不展開了。
go run
go run 用於編譯並執行命令原始碼檔案。
在 hello-world 專案的根目錄,執行 go run 命令:
-
go run -x -work src/main.go
-x 可以列印整個過程涉及到的命令,-work 可以看到臨時的工作目錄:
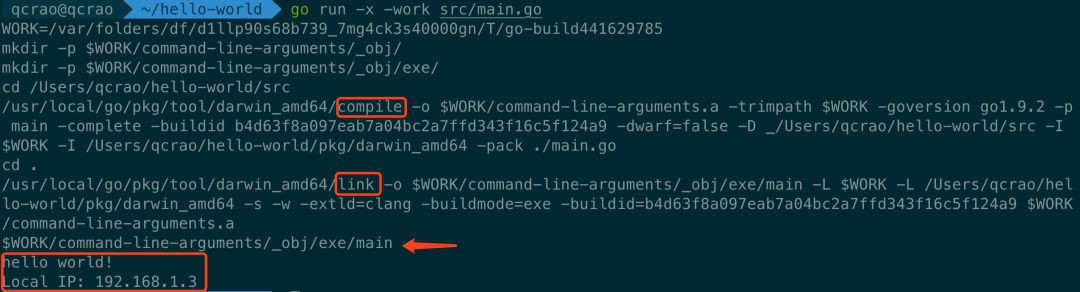
從上圖中可以看到,仍然是先編譯,再連線,最後直接執行,並打印出了執行結果。
第一行列印的就是工作目錄,最終生成的可執行檔案就是放置於此:

main 就是最終生成的可執行檔案。
總結
這次的話題太大了,困難重重。從編譯原理到 go 啟動時的流程,到 go 命令原理,每個話題單獨抽出來都可以寫很多。
幸好有一些很不錯的書和部落格文章可以去參考。這篇文章就作為一個引子,你可以跟隨參考資料裡推薦的一些內容去發散。
參考資料
【《程式員的自我修養》全書】https://book.douban.com/subject/3652388/
【面向信仰程式設計 編譯過程概述】https://draveness.me/golang-compile-intro
【golang runtime 閱讀】https://github.com/zboya/golangruntimereading
【Go-Questions hello-world專案】https://github.com/qcrao/Go-Questions/tree/master/examples/hello-world
【雨痕大佬的 Go 語言學習筆記】https://github.com/qyuhen/book
【vim 以 16 進位制文字】https://www.cnblogs.com/meibenjin/archive/2012/12/06/2806396.html
【Go 編譯命令執行過程】https://halfrost.com/go_command/
【Go 命令執行過程】https://github.com/hyper0x/gocommandtutorial
【Go 詞法分析】https://ggaaooppeenngg.github.io/zh-CN/2016/04/01/go-lexer-%E8%AF%8D%E6%B3%95%E5%88%86%E6%9E%90/
【曹大部落格 golang 與 ast】http://xargin.com/ast/
【Golang 詞法解析器,scanner 原始碼分析】https://blog.csdn.net/zhaoruixiang1111/article/details/89892435
【Gopath Explained】https://flaviocopes.com/go-gopath/
【Understanding the GOPATH】https://www.digitalocean.com/community/tutorials/understanding-the-gopath
【討論】https://stackoverflow.com/questions/7970390/what-should-be-the-values-of-gopath-and-goroot
【Go 官方 Gopath】https://golang.org/cmd/go/#hdr-GOPATHenvironmentvariable
【Go package 的探索】https://mp.weixin.qq.com/s/OizVLXfZ6EC1jI-NL7HqeA
【Go 官方 關於 Go 專案的組織結構】https://golang.org/doc/code.html
【Go modules】https://www.melvinvivas.com/go-version-1-11-modules/
【Golang Installation, Setup, GOPATH, and Go Workspace】https://www.callicoder.com/golang-installation-setup-gopath-workspace/
【編譯、連結過程連結】https://mikespook.com/2013/11/%E7%BF%BB%E8%AF%91-go-build-%E5%91%BD%E4%BB%A4%E6%98%AF%E5%A6%82%E4%BD%95%E5%B7%A5%E4%BD%9C%E7%9A%84%EF%BC%9F/
【1.5 編譯器由 go 語言完成】https://www.infoq.cn/article/2015/08/go-1-5
【Go 編譯過程系列文章】https://www.ctolib.com/topics-3724.html
【曹大 go bootstrap】https://github.com/cch123/golang-notes/blob/master/bootstrap.md
【golang 啟動流程】https://blog.iceinto.com/posts/go/start/
【探索 golang 程式啟動過程】http://cbsheng.github.io/posts/%E6%8E%A2%E7%B4%A2golang%E7%A8%8B%E5%BA%8F%E5%90%AF%E5%8A%A8%E8%BF%87%E7%A8%8B/
【探索 goroutine 的建立】http://cbsheng.github.io/posts/%E6%8E%A2%E7%B4%A2goroutine%E7%9A%84%E5%88%9B%E5%BB%BA/
朋友會在“發現-看一看”看到你“在看”的內容