(點選上方快速關註並設定為星標,一起學Python)
來源:Python專欄 連結:
https://mp.weixin.qq.com/s/iOMEWLmIebcrGT4pWnBuwg
目錄
0 引言
1 環境
2 需求分析
3 程式碼實現
4 後記
0 引言
紙巾再濕也是乾垃圾?瓜子皮再乾也是濕垃圾??最近大家都被垃圾分類折磨的不行,傻傻的你是否拎得清????自2019.07.01開始,上海已率先實施垃圾分類制度,違反規定的還會面臨罰款。
為了避免巨額損失,我決定來b站學習下垃圾分類的技巧。為什麼要來b站,聽說這可是當下年輕人最流行的學習途徑之一。
開啟b站,搜尋了下垃圾分類,上來就被這個標題嚇(吸)到(引)了:在上海丟人的正確姿勢。
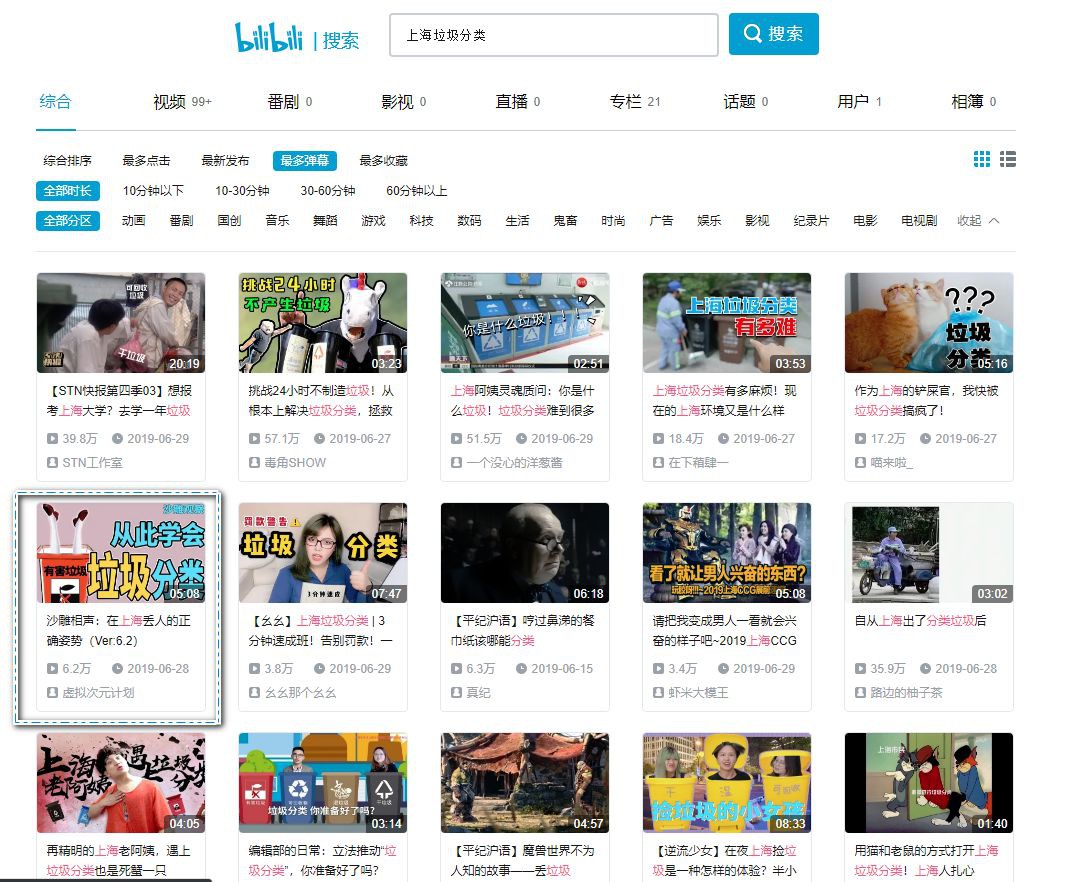
當然,這裡的丟人非彼丟人,指的是丟垃圾的丟。
點開發現,原來是一段對口相聲啊,還是兩個萌妹子(AI)的對口相聲,瞬間就來了興趣,闡述的是關於如何進行垃圾分類的。



原影片連結:https://www.bilibili.com/video/av57129646?from=search&seid;=9101123388170190749
看完一遍又一遍,簡直停不下來了,已經開啟了洗腦樣式,畢竟影片很好玩,影片中的彈幕更是好玩!
獨樂樂不如眾樂樂,且不如用Python把彈幕儲存下來,做個詞雲圖?就這麼愉快地決定了!
1 環境
作業系統:Windows
Python版本:3.7.3
2 需求分析
我們先需要透過開發除錯工具,查詢這條影片的彈幕的 cid 資料。
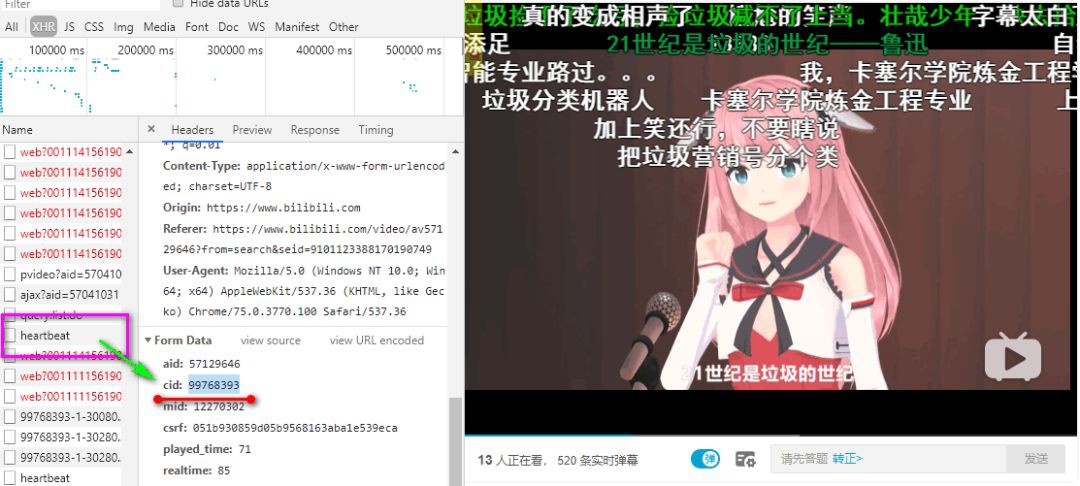
拿到 cid 之後,再填入下麵的連結中。
http://comment.bilibili.com/{cid}.xml
開啟之後,就可以看到該影片的彈幕串列。
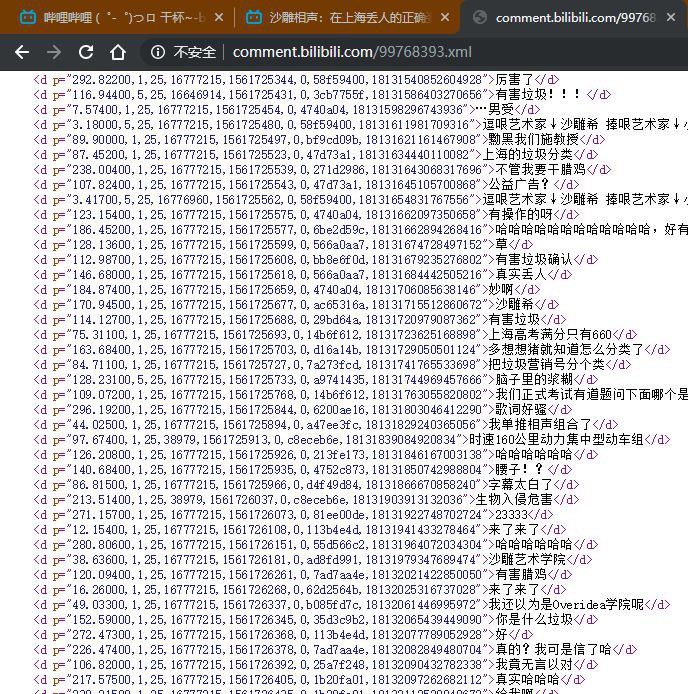
有了彈幕資料後,我們需要先將解析好,並儲存在本地,方便進一步的加工處理,如製成詞雲圖進行展示。
3 程式碼實現
在這裡,我們獲取網頁的請求使用 requests 模組;解析網址藉助 beautifulsoup4 模組;儲存為CSV資料,這裡借用 pandas 模組。因為都是第三方模組,如環境中沒有可以使用 pip 進行安裝。
pip install requests
pip install beautifulsoup4
pip install lxml
pip install pandas
模組安裝好之後,進行匯入
import requests
from bs4 import BeautifulSoup
import pandas as pd
請求、解析、儲存彈幕資料
# 請求彈幕資料
url = 'http://comment.bilibili.com/99768393.xml'
html = requests.get(url).content
# 解析彈幕資料
html_data = str(html, 'utf-8')
bs4 = BeautifulSoup(html_data, 'lxml')
results = bs4.find_all('d')
comments = [comment.text for comment in results]
comments_dict = {'comments': comments}
# 將彈幕資料儲存在本地
br = pd.DataFrame(comments_dict)
br.to_csv('barrage.csv', encoding='utf-8')
接下來,我們就對儲存好的彈幕資料進行深加工。
製作詞雲,我們需要用到 wordcloud 模組、matplotlib 模組、jieba 模組,同樣都是第三方模組,直接用 pip 進行安裝。
pip install wordcloud
pip install matplotlib
pip install jieba
模組安裝好之後,進行匯入,因為我們讀取檔案用到了 panda 模組,所以一併匯入即可
from wordcloud import WordCloud, ImageColorGenerator
import matplotlib.pyplot as plt
import pandas as pd
import jieba
我們可以自行選擇一張圖片,並基於此圖片來生成一張定製的詞雲圖。我們可以自定義一些詞雲樣式,程式碼如下:
# 解析背景圖片
mask_img = plt.imread('Bulb.jpg')
'''設定詞雲樣式'''
wc = WordCloud(
# 設定字型
font_path='SIMYOU.TTF',
# 允許最大詞彙量
max_words = 2000,
# 設定最大號字型大小
max_font_size = 80,
# 設定使用的背景圖片
mask = mask_img,
# 設定輸出的圖片背景色
background_color=None, mode="RGBA",
# 設定有多少種隨機生成狀態,即有多少種配色方案
random_state=30)
接下來,我們要讀取文字資訊(彈幕資料),進行分詞並連線起來:
# 讀取檔案內容
br = pd.read_csv('barrage.csv', essay-header=None)
# 進行分詞,並用空格連起來
text = ''
for line in br[1]:
text += ' '.join(jieba.cut(line, cut_all=False))
最後來看看我們效果圖

有沒有感受到大家對垃圾分類這個話題的熱情,莫名喜感湧上心頭。
4 後記
這兩個AI萌妹子說的相聲很不錯,就不知道郭德綱看到這個作品會作何感想。回到垃圾分類的話題,目前《上海市生活垃圾管理條例》已正式施行,不在上海的朋友們也不要太開心,住建部表示,全國其它46個重點城市也即將體驗到……
朋友會在“發現-看一看”看到你“在看”的內容