1. 背景
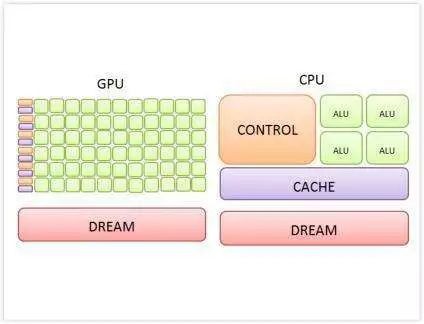
GPU在高效能運算和深度學習加速中扮演著非常重要的角色, GPU的強大的平行計算能力,大大提升了運算效能。隨著運算元據量的不斷攀升,GPU間需要大量的交換資料,GPU通訊效能成為了非常重要的指標。
NVIDIA推出的GPUDirect就是一組提升GPU通訊效能的技術。但GPUDirect受限於PCI Expresss匯流排協議以及拓撲結構的一些限制,無法做到更高的頻寬,為瞭解決這個問題,NVIDIA提出了NVLink匯流排協議。
這個系列文章會對以上GPU通訊技術做詳細的介紹,旨在幫助開發者更好的利用這些技術對自己的應用做相應的最佳化。
本篇文章會先介紹一下GPUDirect技術,並著重介紹GPUDirect Peer-to-Peer(P2P)技術。
2. GPUDirect介紹
2.1 簡介
GPUDirect技術有如下幾個關鍵特性:
- 加速與網路和儲存裝置的通訊:
- GPU之間的Peer-to-Peer Transers
- GPU之間的Peer-to-Peer memory access
- RDMA支援
- 針對Video的最佳化
下麵對最主要的幾個技術做分別介紹。
2.2 Shared Memory
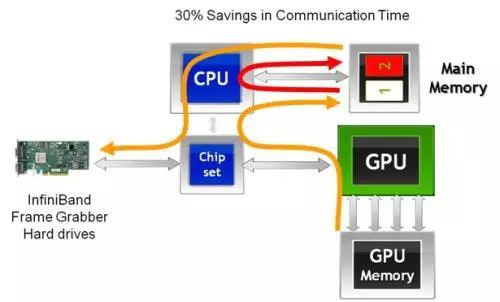
2010年6月最先引入的是GPUDirect Shared Memory 技術,支援GPU與第三方PCI Express裝置透過共享的pin住的host memory實現共享記憶體訪問從而加速通訊。
2.3 P2P
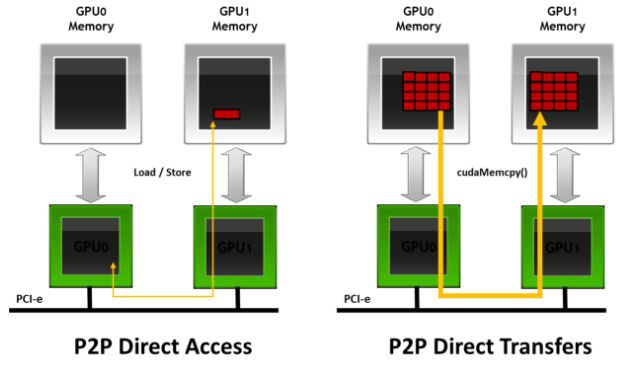
2011年,GPUDirect增加了相同PCI Express root complex 下的GPU之間的Peer to Peer(P2P) Direct Access和Direct Transers的支援。
2.4 RDMA
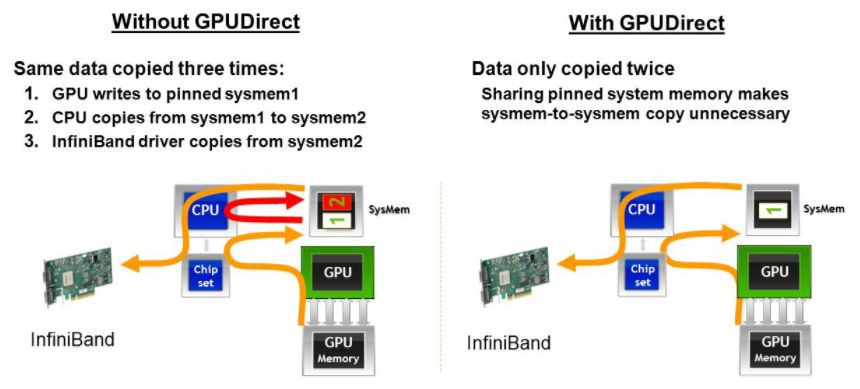
2013年,GPUDirect增加了RDMA支援,使得第三方PCI Express裝置可以bypass CPU host memory直接訪問GPU。
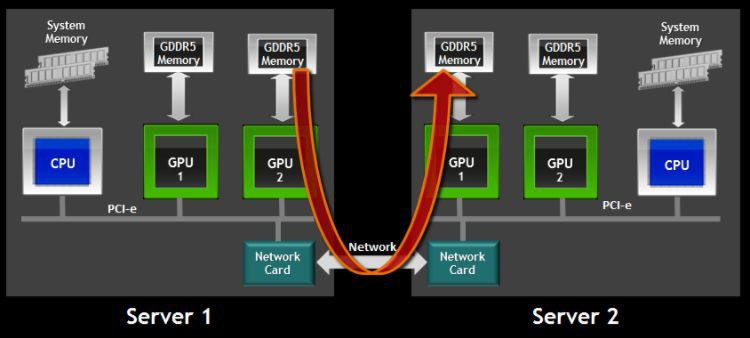
3. GPUDirect P2P
3.1 P2P簡介
GPUDirect Peer-to-Peer(P2P) 技術主要用於單機GPU間的高速通訊,它使得GPU可以透過PCI Express直接訪問標的GPU的視訊記憶體,避免了透過複製到CPU host memory作為中轉,大大降低了資料交換的延遲。
以深度學習應用為例,主流的開源深度學習框架如TensorFlow、MXNet都提供了對GPUDirect P2P的支援,NVIDIA開發的NCCL(NVIDIA Collective Communications Library)也提供了針對GPUDirect P2P的特別最佳化。
透過使用GPUDirect P2P技術可以大大提升深度學習應用單機多卡的擴充套件性,使得深度學習框架可以獲得接近線性的訓練效能加速比。
3.2 P2P虛擬化
隨著雲端計算的普及,越來越多技術遷移到雲上,在雲上使用GPUDirect技術,就要解決GPUDirect虛擬化的問題。
這裡我們著重討論下GPUDirect Peer-to-Peer虛擬化的問題
使用PCI Pass-through虛擬化技術可以將GPU裝置的控制權完全授權給VM,使得虛擬機器裡的GPU driver可以直接控制GPU而不需要Hypervisor參與,效能可以接近物理機。
但是同一個虛擬機器內的應用卻無法使用P2P技術與其它GPU實現通訊。下麵分析一下無法使用P2P的原因。
首先我們需要知道一個技術限制,就是不在同一個Intel IOH(IO Hub)晶片組下麵PCI-e P2P通訊是不支援的,因為Intel CPU之間是QPI協議通訊,PCI-e P2P通訊是無法跨QPI協議的。所以GPU driver必須要知道GPU的PCI拓資訊,同一個IOH晶片組下麵的GPU才能使能GPUDiret P2P。
但是在虛擬化環境下,Hypervisor虛擬的PCI Express拓撲結構是扁平的,GPU driver無法判斷真實的硬體拓撲所以無法開啟GPUDirect P2P。
為了讓GPU driver獲取到真實的GPU拓撲結構,需要在Hypervisor模擬的GPU PCI配置空間裡增加一個PCI Capability,用於標記GPU的P2P親和性。這樣GPU driver就可以根據這個資訊來使能P2P。
另外值得一提的是,在PCI Pass-through時,所有的PCI Express通訊都會被路由到IOMMU,P2P通訊同樣也需要路由到IOMMU,所以Pass-through下的P2P路徑還是會比物理機P2P長一點,延遲大一點。
4. 實測
下麵是我們在阿裡雲GN5實體(8卡Tesla P100)上對GPUDirect P2P延遲做的實測資料。
GPU P2P矩陣如下:

通訊延遲對比如下:
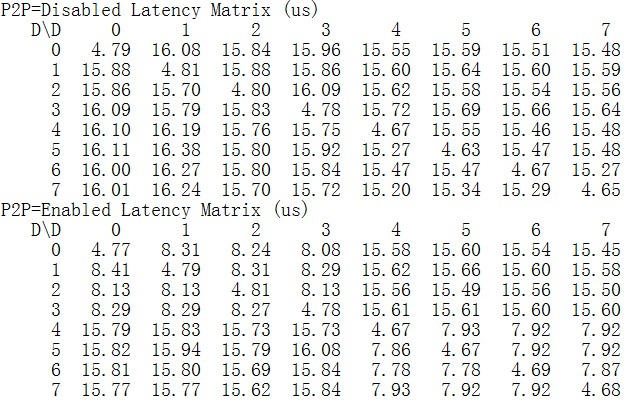
我們看到:使能GPUDirect P2P後GPU間通訊延遲相比CPU複製降低近一半。
下圖是在GN5實體上使用MXNet對經典摺積神經網路的影象分類任務的訓練效能的加速比:
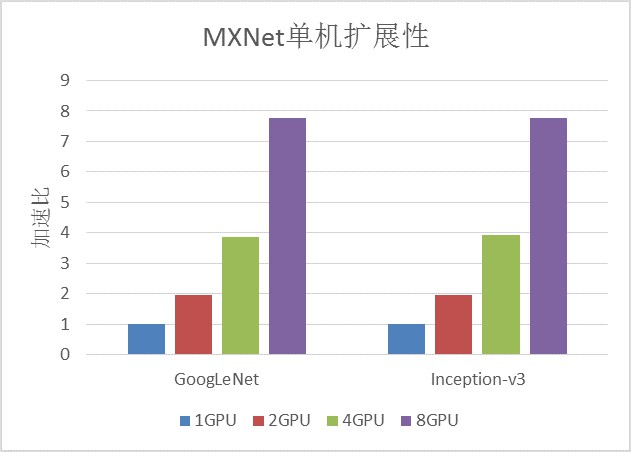
MXNet在支援P2P的GN5實體上有非常好的單機擴充套件性,訓練效能接近線性加速。
