

1. 背景
前兩篇文章我們介紹的GPUDirect P2P和NVLink技術可以大大提升GPU伺服器單機的GPU通訊效能,當前深度學習模型越來越複雜,計算資料量暴增,對於大規模深度學習訓練任務,單機已經無法滿足計算要求,多機多卡的分散式訓練成為了必要的需求,這個時候多機間的通訊成為了分散式訓練效能的重要指標。
本篇文章我們就來談談GPUDirect RDMA技術,這是用於加速多機間GPU通訊的技術。
2. RDMA介紹
我們先來看看RDMA技術是什麼?RDMA即Remote DMA,是Remote Direct Memory Access的英文縮寫。
2.1 DMA原理
在介紹RDMA之前,我們先來複習下DMA技術。
我們知道DMA(直接記憶體訪問)技術是Offload CPU負載的一項重要技術。DMA的引入,使得原來裝置記憶體與系統記憶體的資料交換必須要CPU參與,變為交給DMA控制來進行資料傳輸。
直接記憶體訪問(DMA)方式,是一種完全由硬體執行I/O交換的工作方式。在這種方式中, DMA控制器從CPU完全接管對匯流排的控制,資料交換不經過CPU,而直接在記憶體和IO裝置之間進行。DMA工作時,由DMA 控制器向記憶體發出地址和控制訊號,進行地址修改,對傳送字的個數計數,並且以中斷方式向CPU 報告傳送操作的結束。
使用DMA方式的目的是減少大批次資料傳輸時CPU 的開銷。採用專用DMA控制器(DMAC) 生成訪存地址並控制訪存過程。優點有操作均由硬體電路實現,傳輸速度快;CPU 基本不幹預,僅在初始化和結束時參與,CPU與外設並行工作,效率高。
2.2 RMDA原理
RDMA則是在計算機之間網路資料傳輸時Offload CPU負載的高吞吐、低延時通訊技術。
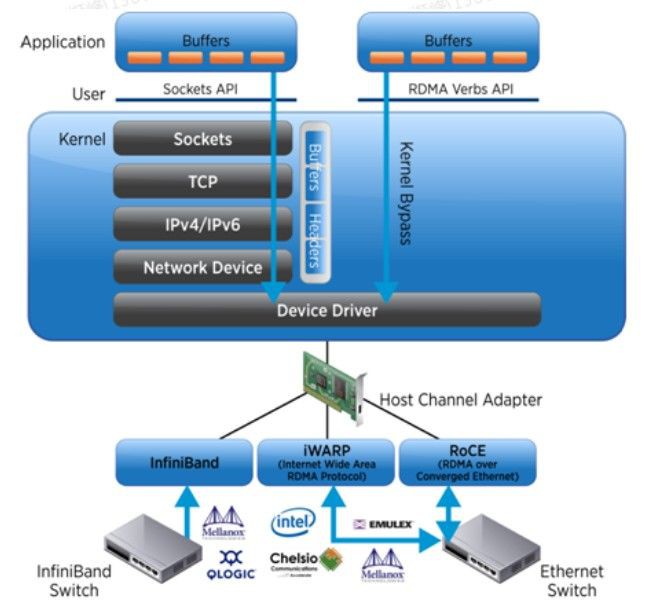
如上圖所示,傳統的TCP/IP協議,應用程式需要要經過多層複雜的協議棧解析,才能獲取到網絡卡中的資料包,而使用RDMA協議,應用程式可以直接旁路核心獲取到網絡卡中的資料包。
RDMA可以簡單理解為利用相關的硬體和網路技術,伺服器1的網絡卡可以直接讀寫伺服器2的記憶體,最終達到高頻寬、低延遲和低資源利用率的效果。如下圖所示,應用程式不需要參與資料傳輸過程,只需要指定記憶體讀寫地址,開啟傳輸並等待傳輸完成即可。
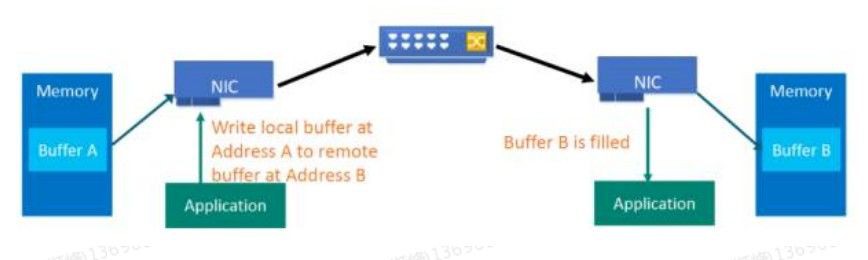
在實現上,RDMA實際上是一種智慧網絡卡與軟體架構充分最佳化的遠端記憶體直接高速訪問技術,透過在網絡卡上將RDMA協議固化於硬體,以及支援零複製網路技術和核心記憶體旁路技術這兩種途徑來達到其高效能的遠端直接資料存取的標的。
(1)零複製:零複製網路技術使網絡卡可以直接與應用記憶體相互傳輸資料,從而消除了在應用記憶體與核心之間複製資料的需要。因此,傳輸延遲會顯著減小。
(2)核心旁路:核心協議棧旁路技術使應用程式無需執行核心記憶體呼叫就可向網絡卡傳送命令。在不需要任何核心記憶體參與的條件下,RDMA請求從使用者空間傳送到本地網絡卡並透過網路傳送給遠端網絡卡,這就減少了在處理網路傳輸流時核心記憶體空間與使用者空間之間環境切換的次數。
在具體的遠端記憶體讀寫中,RDMA操作用於讀寫操作的遠端虛擬記憶體地址包含在RDMA訊息中傳送,遠端應用程式要做的只是在其本地網絡卡中註冊相應的記憶體緩衝區。遠端節點的CPU除在連線建立、註冊呼叫等之外,在整個RDMA資料傳輸過程中並不提供服務,因此沒有帶來任何負載。
2.3 RDMA實現
如下圖RMDA軟體棧所示,目前RDMA的實現方式主要分為InfiniBand和Ethernet兩種傳輸網路。而在乙太網上,又可以根據與乙太網融合的協議棧的差異分為iWARP和RoCE(包括RoCEv1和RoCEv2)。
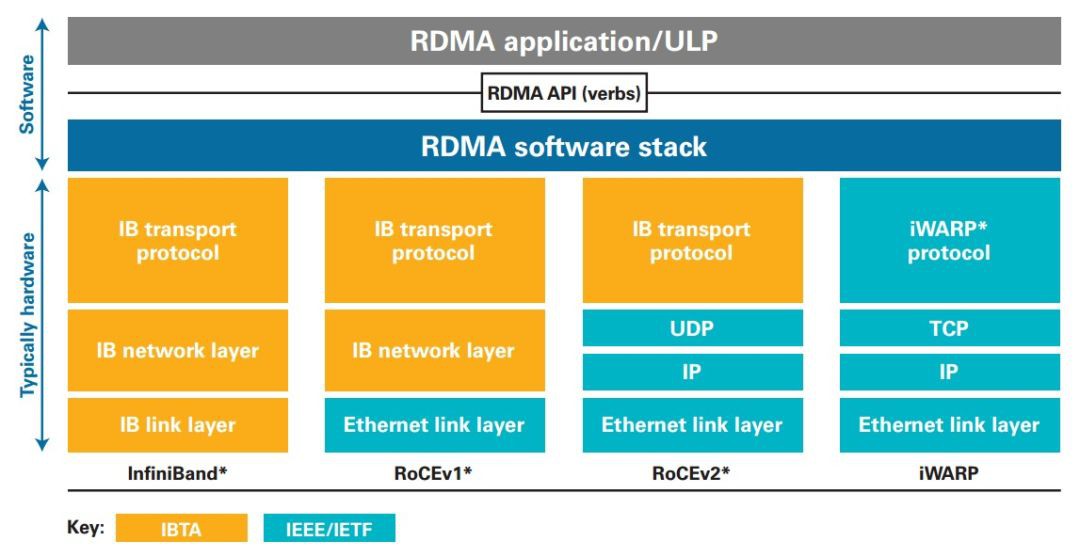
其中,InfiniBand是最早實現RDMA的網路協議,被廣泛應用到高效能運算中。但是InfiniBand和傳統TCP/IP網路的差別非常大,需要專用的硬體裝置,承擔昂貴的價格。相比之下RoCE和iWARP的硬體成本則要低的多。
3. GPUDirect RDMA介紹
3.1 原理
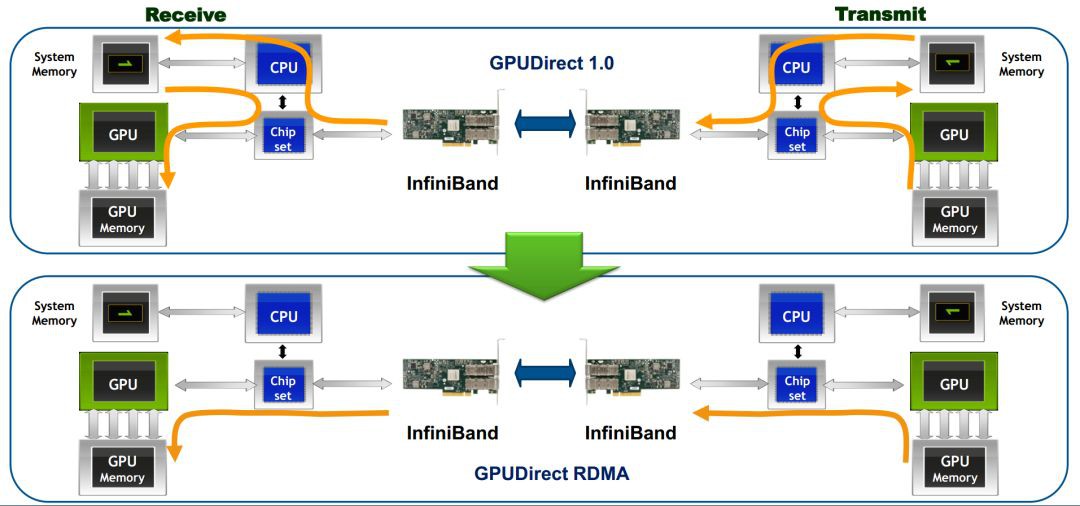
有了前文RDMA的介紹,從下圖我們可以很容易明白,所謂GPUDirect RDMA,就是計算機1的GPU可以直接訪問計算機2的GPU記憶體。而在沒有這項技術之前,GPU需要先將資料從GPU記憶體搬移到系統記憶體,然後再利用RDMA傳輸到計算機2,計算機2的GPU還要做一次資料從系統記憶體到GPU記憶體的搬移動作。GPUDirect RDMA技術使得進一步減少了GPU通訊的資料複製次數,通訊延遲進一步降低。
3.2 使用
需要註意的是,要想使用GPUDirect RDMA,需要保證GPU卡和RDMA網絡卡在同一個ROOT COMPLEX下,如下圖所示:
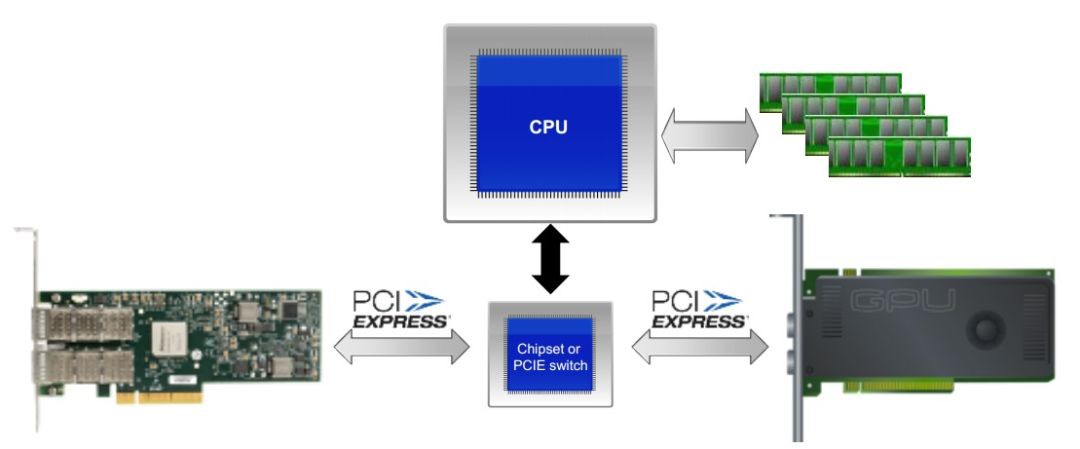
3.3 效能
Mellanox網絡卡已經提供了GPUDirect RDMA的支援(既支援InfiniBand傳輸,也支援RoCE傳輸)。
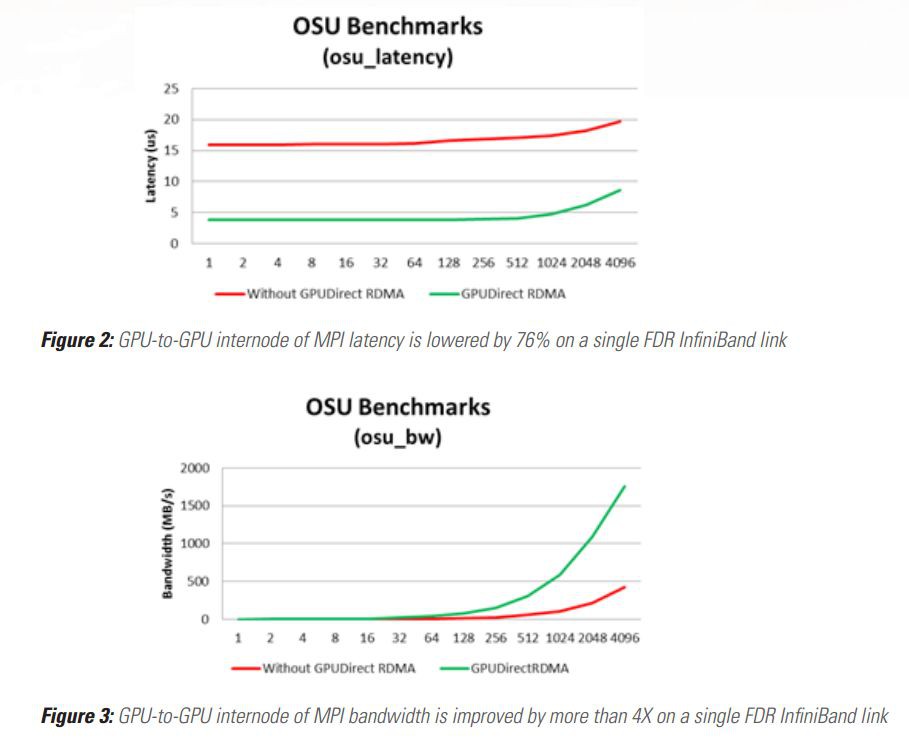
下圖分別是使用OSU micro-benchmarks在Mellanox的InfiniBand網絡卡上測試的延時和頻寬資料,可以看到使用GPUDirect RDMA技術後延時大大降低,頻寬則大幅提升:
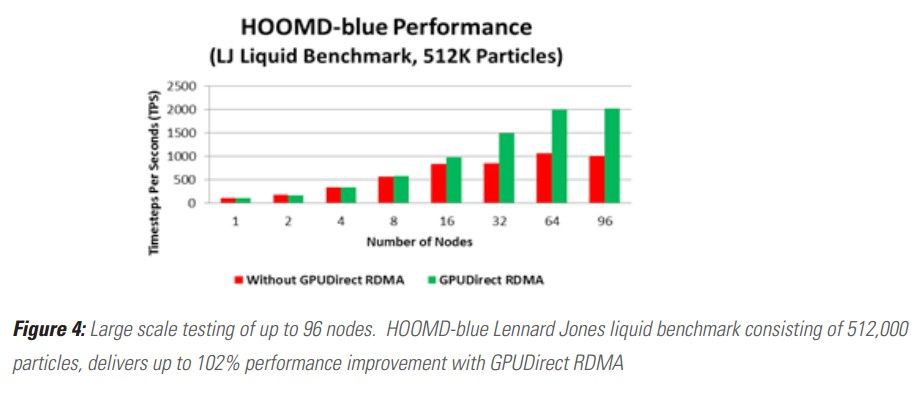
下圖是一個實際的高效能運算應用的效能資料(使用HOOMD做粒子動態模擬),可以看到隨著節點增多,使用GPUDirect RDMA技術的叢集的效能有明顯提升,最多可以提升至2倍:
本文作者:擷峰,本文來自:雲棲社群
推薦閱讀:
溫馨提示:
請識別二維碼關註公眾號,點選原文連結獲取更多RDMA技術總結。



