
當然,根據這本真實存在的暢銷書,他們真的能想到的話題也不多?

開個玩笑,不過今天確實要給大家介紹一個不太一樣有點羞羞的機器學習專案,也就是嘿嘿嘿的時候,最加深感情的某種動作的分析,英文俗稱“blowjob”或者“oral sex”。
編譯:蔣寶尚、魏子敏
來源:大資料文摘(ID:BigDataDigest)

儘管內容敏感,整體來看,這是個頗為學術的研究專案,由柏林一家公司Very Intelligent Ecommerce Inc所委託開啟。這個專案的最終目的也很有趣,是為一項名為Autoblow AI的專案設計進行的調研工作。
關於這個專案Autoblow AI,讀者可以自行谷歌……
在這個機器學習專案中,研究者研究包括108小時的色情影片的訓練資料,並基於這些資料建立了一個模型(當然這也就意味著,研究者需要對這108個小時的影片進行詳細標註)。

之後,模型對影片中的口情色內容分成了十六種不同的經典型別。模型的核心是採用深度學習在程式上生成模擬動作。經過驗證,該模型的效果優於馬爾科夫鏈。
據悉,用機器學習對這一類情色內容進行分析,屬於前無古人的專案。分析結果為未來為未來的研究奠定了基礎。
先把這份神奇的paper獻上:
https://www.autoblow.com/bjpaper/
儘管整體研究頗為嚴謹,但基於專案的敏感性,此專案的作者選擇保持匿名。仍然感興趣的同學可以繼續往下讀,以下是這位研究者的論文,或者說一份研究自述?
機器學習和大資料分析在數字世界中變得越來越重要。性產業也不例外。
例如:與過濾色情片完全相同的技術可以很容易地對其進行分類和標記。一些網站也使用類似Netflix的推薦系統推薦影片。這些只是人工智慧的一些實際應用。
在這項工作中,對這個未經探索的專案進行研究,特別側重於對男性的口情色動作分析是非常有勇氣的。
該專案的具體操作過程為:
首先,量化了口情色動作中最“常見”或“典型”的動作,從而改善了Autoblow AI所使用的樣式的真實性。具體來說,使用量化技術來識別16種“典型”或“常見”運動,從而構建更加複雜的運動模組。
其次,研究者使用以前的結果來研究運動的過程生成。設計一個基於深度學習的模型,用於從隨機噪聲中產生獨特但真實的序列。然後將該模型與一個簡單的馬爾可夫鏈模型進行了定量比較,證明瞭設計的正確性。
最後,研究者討論了未來的研究是可能的,在同一資料集的背景下,繼續改進的奧託布洛人工智慧和性玩具在總體上。
最後,在繼續改進Autoblow AI和性玩具的背景下,將討論如何使用相同資料集進行未來研究。
01 資料集
對AAA級色情影片進行分析時,只採用男性口情色部分。具體資料的標準,有審查員手工標記,然後使用自定義的使用者介面記錄口與***的距離。該位置記錄為整數,其中1000表示軸的尖端,0表示基部。

▲自定義的使用者介面
為了分析,使用線性插值將影片和註釋標準化為每秒16幀。最終將109小時的影片資料集處理成6270467個標準化幀。
02 動作分析
進行這種分析,有助於對Autoblow AI的程式設計方式有一個基本的瞭解。Autoblow AI有十種樣式,每種樣式代表一系列動作。
動作的不同只是上或者下運動的速度的不同。瞭解這些之後,對性產品的最佳化非常有幫助,因為速度的不同可以由為電機控制。
兩個到三個不同的動作連續釋放也可以創造複雜的動作樣式。下麵的圖表描述了基於三動作樣式的分析。
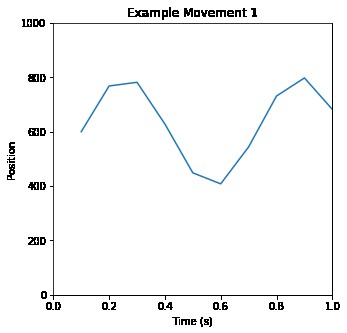
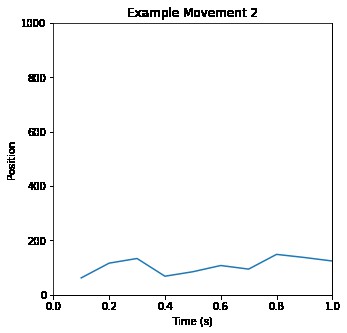

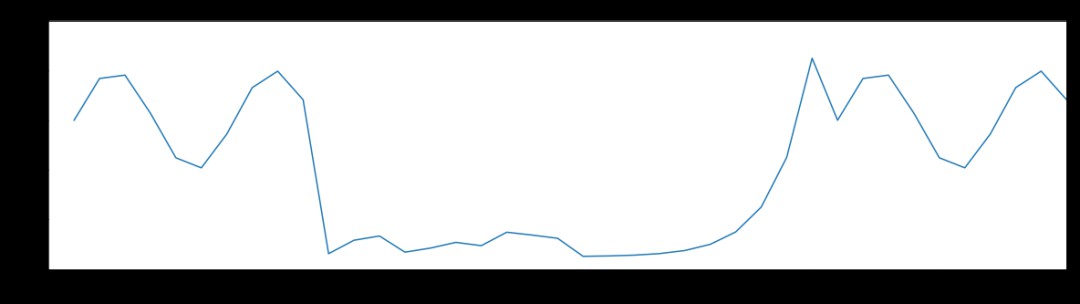
可以清楚地看到運動具有周期性。也可以看到隨著時間變化動作的狀態,包括停頓和中斷。基於上千個這樣的片段,然後就可以建立機器學習模型從而識別出“常見”或“典型”的動作。
接下來,是驗證時間。
03 K均值聚類演演算法
研究者開始了對K-均值演演算法的研究,也就是Lloyd’s演演算法。這個演演算法雖然有很多缺點,但是它執行速度也很快。
將每個影片分割成一秒的視窗,每個視窗的位置順序給出一組16維向量。然後用K-均值找到16個聚類。產生的結果和每個叢集的100個樣本如下所示:

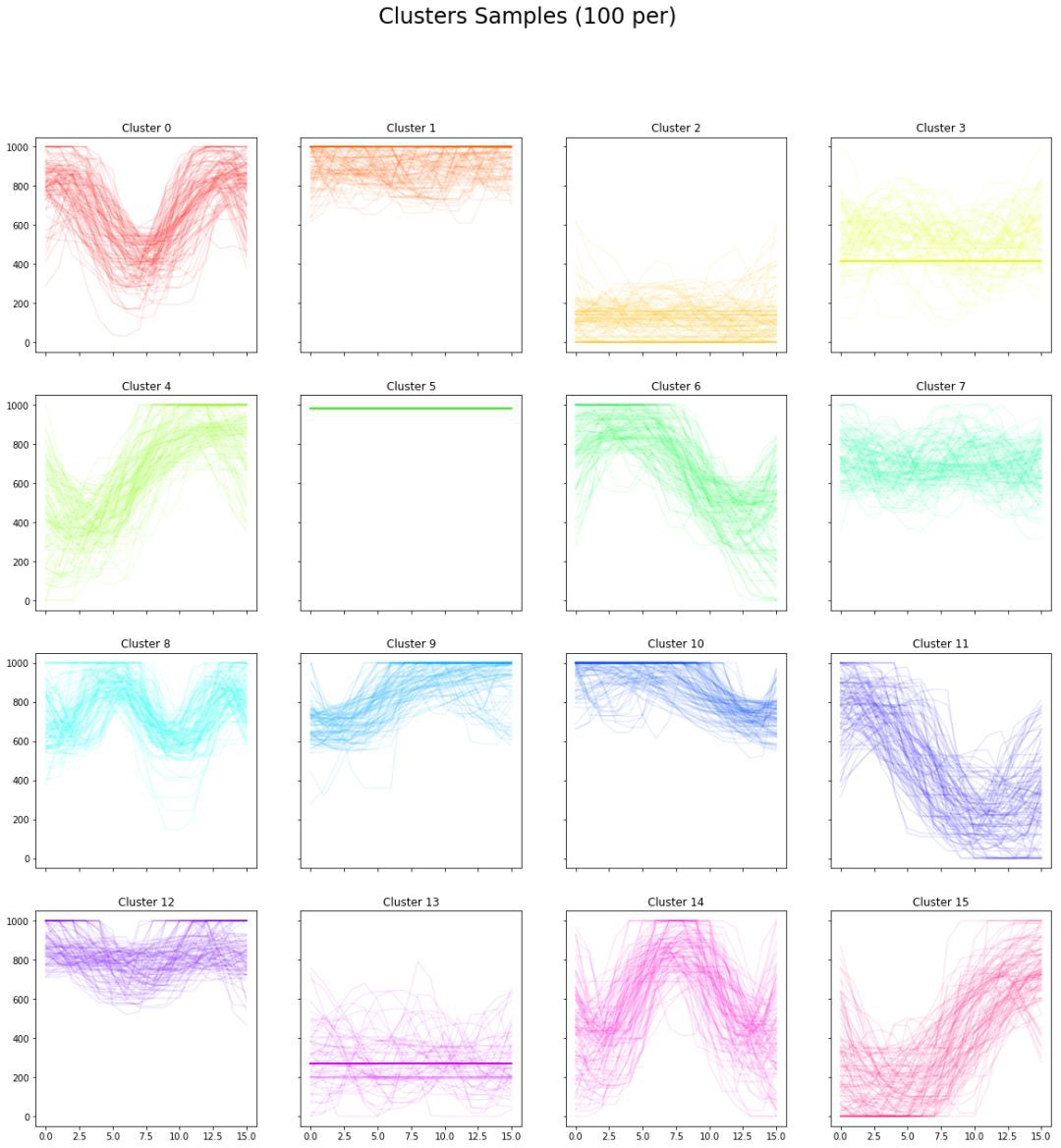
為了進一步驗證假設,研究者使用了一種最近發展起來的資料降維技術,即UMA。可以使使資料在2維空間和3維空間中視覺化。

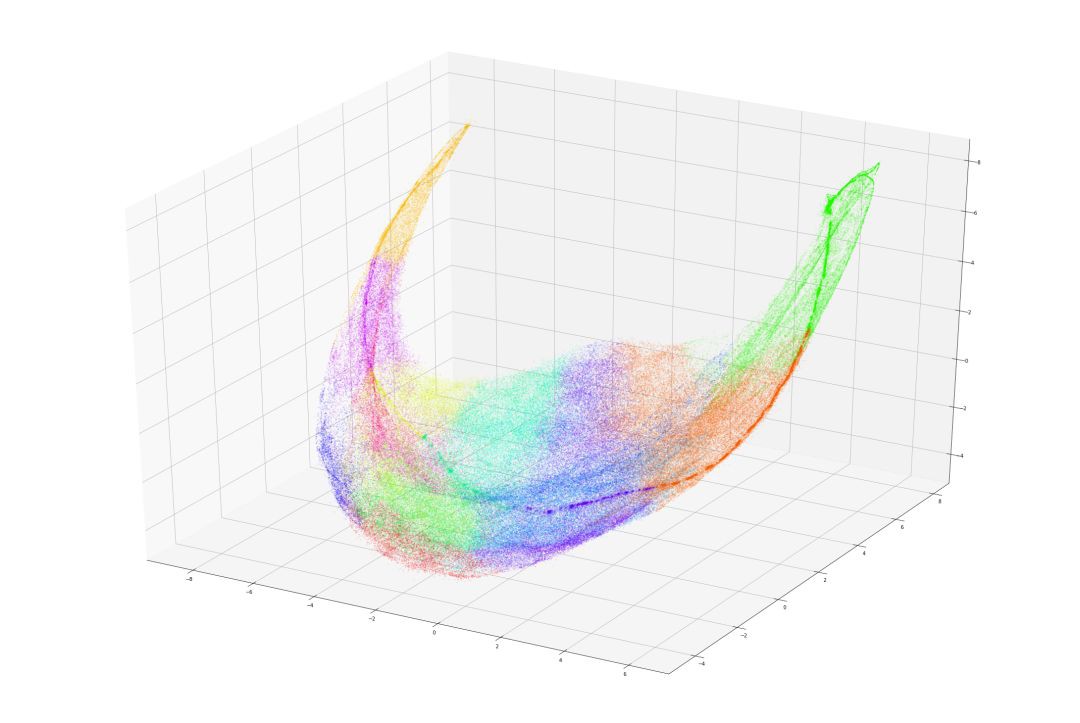
註意類別5和2的資料,它們分別代表頂部和底部附近的小活動點,這些小活動位於相對的“點”。另外類別1和5(它們都代表頂部附近的動作)彼此相鄰。在每一端的“點”之間也有一條密集的線,這條線似乎貫穿所有代表低強度動作(5,1,12,7,3,13,2)的資料點。
可以花很多時間來分析這個圖表,目前,這些驗證足以讓我們相信資料之間呈現某種趨勢。因此可以使用這些資料建立更加複雜的動作模型。
04 程式生成
如上所述,一個完整的樣式是從一系列的動作中建立的。研究者確定了在一秒鐘內發生的典型動作。
因此,下一步是找到共同的運動順序。
這個問題與自然語言問題的處理有很多相似之處,例如“你猜下一個詞是什麼意思”。下麵的漫畫最能說明這個問題。

因此,可以使用類似的技術。
首先建立一個基於馬爾可夫鏈的簡單模型作為基線。然後,研究者設計了一個深度學習模型作為替代方案,並對這兩種樣式進行了定量比較.
05 馬爾可夫鏈模型
馬爾可夫鏈背後的原理很簡單:假設下一步要去的地方只取決於我們在哪裡,而不是我們去過的地方。例如,假設我們剛剛做了運動,在此基礎上,我們知道我們再次做這個運動的機率是50%,接下來我們做另一個動作的機率是30%,第三個動作的機率是15%,等等。
然後,我們可以根據這些機率生成一個“唯一”序列,方法是根據機率隨機選擇下一個動作。
因此,採用此模型,需要計算一種樣式由另一種樣式引起的頻率,驗證機率與直覺是否一致。然後利用這些機率來生成唯一的序列,並使用簡單的移動平均進行平滑處理。結果如下:

馬爾可夫模型有自身的侷限性,它的侷限性也正是由於它的假設引起的。馬爾可夫模型下的假設是,下一狀態機率僅取決於當前狀態。事實上,這個假設並不是非常靈活。
另一個問題是,簡單的馬爾科夫鏈模型需要瞭解前幾個狀態的“最優”數來執行預測。這往往與現實不想符。如果最後3個狀態是A,B和C,也許在此之前發生的事情並不重要;但是如果它們是X,Y和Z然而情況就會不一樣。
06 Dense Neural Network (DNN) Model
在這一部分中,設計了一種基於先前狀態預測下一個狀態的DNN結構。
使用一個簡單的兩層體系結構,把最後最後16個狀態輸入進去,輸出範圍在在0到1之間,共有16個機率發生。這些機率意味著下一個狀態發生的機率。
所有狀態都是獨熱編碼,用零矢量表示“缺失”狀態(例如,在影片開始之前)。透過縱向連線先前的狀態向量來建立輸入。在此專案中只訓練80%的資料,因為剩下的20%資料要用於測試與比較。另外,使用交叉熵作為損失函式。
模型的效能取決於如何分割訓練資料和測試資料;為了處理隨機誤差帶來的影響,需要重覆10次及更多次的實驗,每次使用不同的隨機種子來分割訓練資料。這對於分析和比較是很重要的。
下麵,研究者定性地說明瞭該模型從隨機噪聲產生的一個序列:

▲DNN Sequence
07 模型比較
定性地說,DNN模型魯棒性更好,因為它被鎖定在單一狀態的可能性要小得多。
然而,通常,對於預測來說,首先要考慮的是準確性。
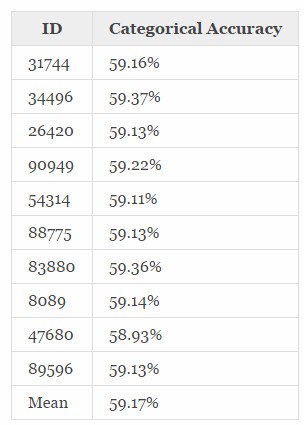
比較:如果選擇機率最高的下一個狀態作為“預測”,那麼馬爾可夫模型的分類精度是多少?如果當前狀態的最高機率是(P_S),那麼當前狀態為(S)時,平均精度顯然也是(P_S)。然後,透過乘以該狀態出現的頻率(F_S)並對所有狀態進行求和,得到總精度;或者,簡潔地:
[sum_{s=1}^{16}p_s *f_s]
這給出的準確率約為58.08%,略低於神經網路的平均精度,但還不能確定其中一個優於另一個。
然而,在這種情況下,分類的準確性是一個誤導性的指標。實際上不是在構建真正的分類器,而是一個序列生成器。不期望以前的16個狀態能唯一地識別每一個“下一個狀態”,所以不期望很高的精確度。
在這個問題中,假設是:錯誤的方式都相同。這與實際標的不相符。因此,必須使用一個引入“相對錯誤”的度量。
引入“相對錯誤”之後,對模型的比較有非常大的幫助。例如,你在試著預測是否下雨。如果你說你百分之百肯定明天會下雨,如果沒有,那麼是你預測錯了。如果你說你80%肯定明天會下雨,但你還是錯了;但你沒有完全肯定地說錯,因為至少你考慮到了你可能錯了。從某種意義上說,你只錯了80%。

用同樣的框架和前面的假設為馬爾可夫模型計算這個度量。如果給定當前狀態(S)下一個狀態(I)的機率為(p_{is}),那麼當前狀態為(S)時選擇該狀態時的錯誤是(2*(1-p_{is})).如果(n_{is})是狀態(I)跟隨狀態(S)的次數,那麼,所有當前和下一個狀態的總錯誤顯然是:
\[ 2 * \frac{\sum_{s=1}^{16} \sum_{i=1}^{16} n_{is} * (1 – p_{is})}{\sum_{s=1}^{16} \sum_{i=1}^{16} n_{is}} \]
使用本文所使用的資料,計算所得為1.126。換句話說,平均而言,馬爾可夫模型在所有類別中都有7.6個百分點的錯誤。
這看起來並不是很多,但它仍然是一個改進。因此,DNN模型有更少的錯誤率。
具體而言,由於DNN模型中的分類精度和平均絕對誤差都是優越的,可以有把握地說它是一個更棒的模型。
08 未來的研究
最後,在繼續改進Autoblow AI和性玩具的背景下,討論使用相同資料集進行的未來研究。
第一:可以改行程式生成。簡單的DNN架構的替代方案包括迴圈神經網路,摺積神經網路和生成對抗網路。打算研究更複雜的技術來改善序列的真實性。但是,這些需要與物理硬體的限制相平衡。
第二:研究者認為類似的分析可以適用於其他情色行為。
第三:希望將研究擴充套件到影象識別和影片分類。現在已經有了一種模型,可以用於識別靜止幀中是否存在口情色行為,並且正在研究更複雜的影片分析問題。接下來的研究重點可以放到將性玩具與看不見的色情內容同步方面。
我們期待著繼續探索這個未知又神秘的空間。

據統計,99%的大咖都完成了這個神操作
▼
更多精彩 在公眾號後臺對話方塊輸入以下關鍵詞 檢視更多優質內容! PPT | 報告 | 讀書 | 書單 Python | 機器學習 | 深度學習 | 神經網路 區塊鏈 | 揭秘 | 乾貨 | 數學
誰再問你“天天爬那些資料有什麼用”,就把這5本書扔給他!
Q: 你還見過哪些有趣的機器學習專案?
歡迎留言與大家分享
覺得不錯,請把這篇文章分享給你的朋友
轉載 / 投稿請聯絡:baiyu@hzbook.com
更多精彩,請在後臺點選“歷史文章”檢視

