

在碎片化閱讀充斥眼球的時代,越來越少的人會去關註每篇論文背後的探索和思考。
在這個欄目裡,你會快速 get 每篇精選論文的亮點和痛點,時刻緊跟 AI 前沿成果。
點選本文底部的「閱讀原文」即刻加入社群,檢視更多最新論文推薦。
作者丨武廣
學校丨合肥工業大學碩士生
研究方向丨影象生成
本期推薦的論文筆記來自 PaperWeekly 社群使用者 @TwistedW。本文將“圖靈思想”用在 GAN 的框架下,這個思想在 RSGAN 中最先提出——將以往判別器逐個判斷資料真假換為將真假樣本混合後再做判斷,同時在生成器下引入真實樣本做參考,增加了生成器的生成能力。本文對該思想做了更一般化的推證和應用,可以說”圖靈思想“適用於任何一種 GAN 模型。


引言
利用 GAN 做實驗的學者一定為其訓練不穩定感到痛苦,如何去控制超引數,如何去平衡判別器和生成器間的迭代都是操碎了心。儘管 WGAN [1]、LSGAN [2] 對於 GAN 的梯度消失做瞭解釋和改進,但是在實際的訓練中模型的不穩定一直存在。SNGAN [3] 可以有效地約束判別器的能力,但是隨著生成精度的增加,仍然不可避免訓練的不穩定。
T-GANs 是蘇劍林的一篇在 RSGAN 的基礎上對相對判別器做一般化改進的文章,論文現已掛在 arXiv,程式碼已開源。文章中出現了較多的數學公式,筆者儘量用簡潔的話語闡述清楚文章觀點。
原始碼連結:
https://github.com/bojone/T-GANs
論文引入
由於 GAN 的文章更新太多,現將原始 GAN 稱為 Standard GAN,簡稱 SGAN,文章後續的 SGAN 就是大家最熟悉的由 Goodfellow 創作的最原始的 GAN [4]。
GAN 在訓練和分析過程中都會發現判別器 D 的能力是遠超生成器 G 的,這個理論推導在 SNGAN 中有所提及。為了較好地平衡 D 和 G 的關係,在 GAN 剛開始的階段,大多數學者是控制判別器和生成器的更新比例。由於 WGAN 和 LSGAN 等一系列改進文章的提出,權重裁剪、梯度懲罰得到應用,SNGAN 對判別器做譜歸一化來約束判別器的能力。
上述這些方法仍然無法完全消除 GAN 訓練過程中的不穩定,尤其是訓練特別高維資料的情況下,例如 1024 x 1024 的影象。這個觀念在最近新出的 BigGAN 中作者也是吐槽了一下。
RSGAN 將“圖靈測試”的思想引入到了 GAN 中,何謂圖靈測試,借用蘇大哥文章中的描述做解釋:
圖靈測試指的是測試者在無法預知的情況下同時跟機器人和人進行交流,如果測試者無法成功分別出人和機器人,那麼說明這個機器人已經(在某個方面)具有人的智慧了。“圖靈測試”也強調了對比的重要性,如果機器人和人混合起來後就無法分辨了,那麼說明機器人已經成功了。
RSGAN 把圖靈測試在 GAN 中的應用可以這麼理解,對於真實樣本我們將其理解為人,假樣本則理解為機器人,不再按照 SGAN 中一張張送到判別器下判斷樣本真假,而是將真假樣本混合在一起讓判別器判斷何為真何為假。
這樣判別器將不再按照記憶去判斷真假,而是在混合的資料堆中找到真假,這個無疑是增加了判別器的判別要求,在訓練階段有用的和豐富的梯度將得到保留;同時讓生成器也看到真實樣本,在生成階段更加逼真的生成高質量樣本。這種一收一放,有效地控制了 D 和 G 的能力,進而在整體上提高了 GAN 的效能。
GAN的回顧
為了保證與原文的公式一致,接下來部分的公式保持與原文一致。大部分 GAN 的目的都是為了減小真實樣本和生成樣本的分佈差異。我們定義真實樣本的分佈為 p̃(x),生成樣本分佈為 q(x),對於 SGAN 對抗下最大最小化博弈,對於判別器 T(x) 和生成器 G(z):

這裡的 σ 為 sigmoid 函式 ,其中 h 可以是任何標量函式,只要使 h(log(t)) 成為變數 t 的凸函式即可,這個後續再說。對上述的判別器最佳化公式 (1) 進行變分操作,類似於微分,可以得到:
,其中 h 可以是任何標量函式,只要使 h(log(t)) 成為變數 t 的凸函式即可,這個後續再說。對上述的判別器最佳化公式 (1) 進行變分操作,類似於微分,可以得到:

詳細證明可參看RSGAN:對抗模型中的“圖靈測試”思想。帶入到公式 (2),可以得到:

設 f(t)=h(log(t)),可以看出 SGAN 的基本標的是最小化 p(x) 和 q(x) 之間的 f- 散度,函式 f 受凸函式約束。因此,任何使 h(log(t)) 成為凸函式的函式都可以使用,例如 h(t)=−t,h(t)=−logσ(t),h(t)=log(1−σ(t))。
對於 WGAN 中的 Wasserstein distance,其目的也是為了最小化 p(x) 和 q(x) 之間的距離,詳細解釋可參看原文,這裡不再贅述。不過統一起來,這些 GAN 都是為了拉近生成分佈與真實分佈;在更新生成器時,只有來自生成分佈的假樣本可用。這種一張張輸入判斷真假的任務對於擁有強大記憶性的判別器來說是容易的,這無疑會導致越訓練判別器的能力越強,最終導致訓練的失敗。
RSGAN
RSGAN 在 SGAN 的基礎上對判別器做了一定變化,此時判別器不再是一張張判斷輸入的真假,而是將真假混合在一起來判斷,同時生成器的更新也加入了真實樣本作為指導,這就是 RSGAN 的整體思路,所對應的最佳化公式為:

繼續透過變分的思想,可以對公式 (5) 進一步分析,得到的最優解:
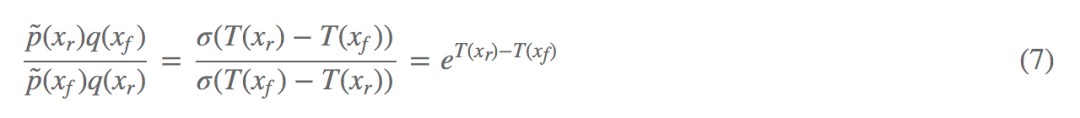
帶入到公式 (6) 可以得到:
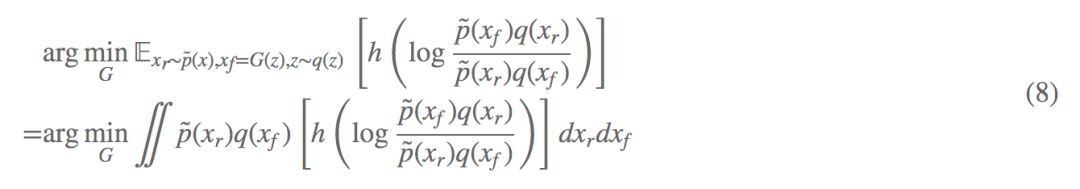
這就是 RSGAN 的目的所在,它實際上最佳化的是 p̃(Xr)q(Xf) 和 p̃(Xf)q(Xr) 的 f- 散度。我們可以進一步分析(以下觀點借鑒自蘇劍林文章):
假如我從真實樣本取樣一個 Xr 出來,從偽造樣本取樣一個 Xf 出來,然後將它們交換一下,把假的當成真,真的當成假,那麼還能分辨出來嗎?換言之:p̃(Xf)q(Xr) 有大變化嗎?
假如沒有什麼變化,那就說明真假樣本已經無法分辨了,訓練成功。假如還能分辨出來,說明還需要藉助真實樣本來改善偽造樣本。所以,式 (8) 就是 RSGAN 中“圖靈測試”思想的體現:打亂了資料,是否還能分辨出來?
T-GANs
前面說到 RSGAN 的突破性工作就是優化了 p̃(Xr)q(Xf) 和 p̃(Xf)q(Xr) 的 f- 散度,利用“圖靈測試”的思想來最佳化 GAN。為了讓這一思想更加一般化,更可以稱得上是“圖靈測試”在 GAN 中的應用,T-GANs 顯示出了更加一般化的思想。
假設聯合分佈 P(Xr,Xf)=q̃(Xr)p(Xf),Q(Xr,Xf)=q̃(Xf)p(Xr)。現在的目的是想最小化 P(Xr,Xf) 和 Q(Xr,Xf) 的距離,如果將 (Xr,Xf) 視為一個變數,並帶入 SGAN 即公式 (1) 中,可以得到:

代入公式 (2) 可以得到 G 的最佳化公式,這裡的 Xf 可以表示為 Xf=G(z),z∼q(z),最終得到一般化最佳化公式:
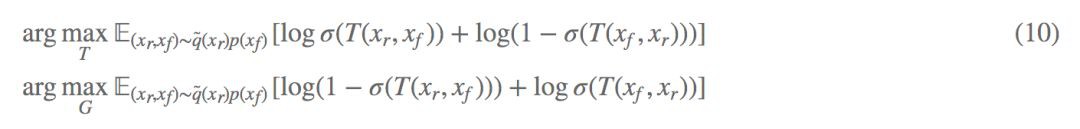
這就是利用 SGAN 實現了 p̃(Xr)q(Xf) 和 p̃(Xf)q(Xr) 分佈距離的拉近,並且也可以進一步將“圖靈測試”思想用在 WGAN 上。

最終應用在最佳化公式上:
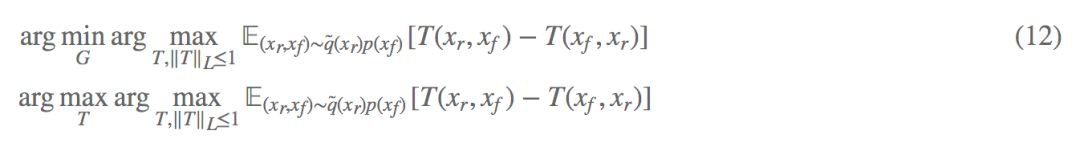
怎麼去實現 T(Xr,Xf) 呢?
可以構造一個編碼器 E,將真實樣本和生成樣本先編碼到潛在空間,再透過判別器 D 判斷 E(Xr)−E(Xf) 的真假,可以表示為:

當然這種“圖靈思想”可以用在更多的 GAN 模型上,甚至可以說對於任何一種 GAN 都是適用的,所以文章將“圖靈思想(Turing Test)”用作題目,簡稱為 T-GANs。
實驗
在不同的影象尺寸上,T-GANs 展示了更多的網路適應能力和更快的收斂速度。在私下和作者交流的過程中,64 尺寸到 128,甚至是 256 整體框架的改動不大, 這對於一般 GAN 模型是困難的,看一下實驗結果對比:


由於文章還處於初稿階段,本博文只是為了對文章做中文解釋,後續的實驗還會再豐富。
總結
在本文中,作者提出了一種新的對抗樣式,用於訓練稱為 T-GAN 的生成模型。這種對抗樣式可以解釋為 GAN 中的圖靈測試,它是訓練 GAN 而不是特定 GAN 模型的指導思想。 它可以與當前流行的 GAN(如 SGAN 和 WGAN)整合,從而實現 T-SGAN 和 T-WGAN。
實驗表明,T-GAN 在從小規模到大規模的資料集上具有良好且穩定的效能。 它表明在 GAN 中更新發生器時,實際樣本的訊號非常重要。然而,T-GAN 提高穩定性和收斂速度的機制仍有待進一步探索。
參考文獻
[1] Martin Arjovsky, Soumith Chintala, and Léon Bottou. Wasserstein generative adversarial networks. In International Conference on Machine Learning, pages 214–223, 2017.
[2] Xudong Mao, Qing Li, Haoran Xie, Raymond YK Lau, Zhen Wang, and Stephen Paul Smolley. Least squares generative adversarial networks. In 2017 IEEE International Conference on Computer Vision (ICCV), pages 2813–2821. IEEE, 2017.
[3] Takeru Miyato, Toshiki Kataoka, Masanori Koyama, and Yuichi Yoshida. Spectral normalization for generative adversarial networks. arXiv preprint arXiv:1802.05957, 2018.
[4] Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative Adversarial Networks. Advances in Neural Information Processing Systems 27, pages 2672–2680. Curran Associates, Inc., 2014.
本文由 AI 學術社群 PaperWeekly 精選推薦,社群目前已改寫自然語言處理、計算機視覺、人工智慧、機器學習、資料挖掘和資訊檢索等研究方向,點選「閱讀原文」即刻加入社群!

點選標題檢視更多論文解讀:
 #投 稿 通 道#
#投 稿 通 道#
讓你的論文被更多人看到
如何才能讓更多的優質內容以更短路徑到達讀者群體,縮短讀者尋找優質內容的成本呢? 答案就是:你不認識的人。
總有一些你不認識的人,知道你想知道的東西。PaperWeekly 或許可以成為一座橋梁,促使不同背景、不同方向的學者和學術靈感相互碰撞,迸發出更多的可能性。
PaperWeekly 鼓勵高校實驗室或個人,在我們的平臺上分享各類優質內容,可以是最新論文解讀,也可以是學習心得或技術乾貨。我們的目的只有一個,讓知識真正流動起來。
? 來稿標準:
• 稿件確系個人原創作品,來稿需註明作者個人資訊(姓名+學校/工作單位+學歷/職位+研究方向)
• 如果文章並非首發,請在投稿時提醒並附上所有已釋出連結
• PaperWeekly 預設每篇文章都是首發,均會新增“原創”標誌
? 投稿郵箱:
• 投稿郵箱:hr@paperweekly.site
• 所有文章配圖,請單獨在附件中傳送
• 請留下即時聯絡方式(微信或手機),以便我們在編輯釋出時和作者溝通
?
現在,在「知乎」也能找到我們了
進入知乎首頁搜尋「PaperWeekly」
點選「關註」訂閱我們的專欄吧
關於PaperWeekly
PaperWeekly 是一個推薦、解讀、討論、報道人工智慧前沿論文成果的學術平臺。如果你研究或從事 AI 領域,歡迎在公眾號後臺點選「交流群」,小助手將把你帶入 PaperWeekly 的交流群裡。

▽ 點選 | 閱讀原文 | 下載論文 & 原始碼
