點選上方“芋道原始碼”,選擇“置頂公眾號”
技術文章第一時間送達!
原始碼精品專欄
摘要: 原創出處 http://www.iocoder.cn/Elastic-Job/job-sharding-strategy/ 「芋道原始碼」歡迎轉載,保留摘要,謝謝!
本文基於 Elastic-Job V2.1.5 版本分享
-
1. 概述
-
2. 自帶作業分片策略
-
3. 自定義作業分片策略
-
666. 彩蛋
1. 概述
本文主要分享 Elastic-Job-Lite 作業分片策略。
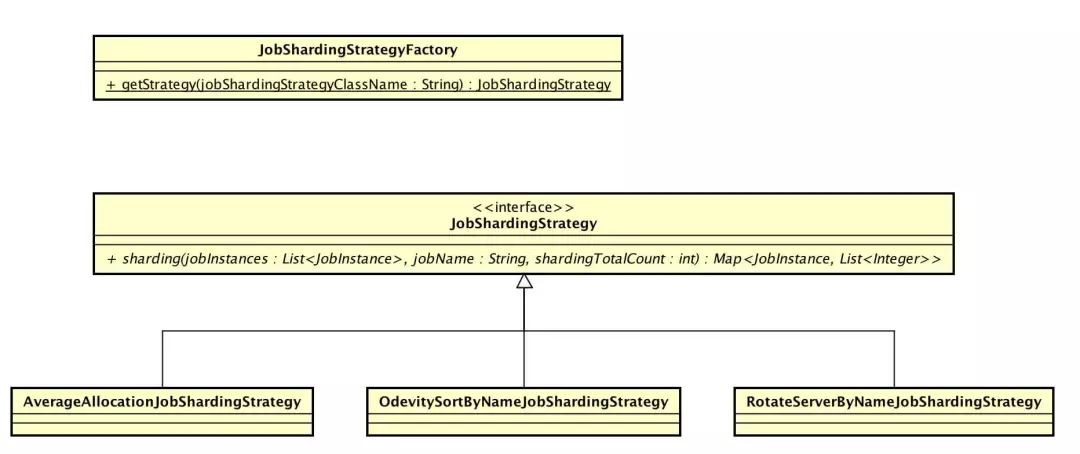
涉及到主要類的類圖如下( 開啟大圖 ):
你行好事會因為得到贊賞而愉悅
同理,開源專案貢獻者會因為 Star 而更加有動力
為 Elastic-Job 點贊!傳送門
2. 自帶作業分片策略
JobShardingStrategy,作業分片策略介面。分片策略透過實現介面的 #sharding(...) 方法提供作業分片的計算。
public interface JobShardingStrategy {
/**
* 作業分片.
*
* @param jobInstances 所有參與分片的單元串列
* @param jobName 作業名稱
* @param shardingTotalCount 分片總數
* @return 分片結果
*/
Map> sharding(List jobInstances, String jobName, int shardingTotalCount);
}
Elastic-Job-Lite 提供三種自帶的作業分片策略:
-
AverageAllocationJobShardingStrategy:基於平均分配演演算法的分片策略。
-
OdevitySortByNameJobShardingStrategy:根據作業名的雜湊值奇偶數決定IP升降序演演算法的分片策略。
-
RotateServerByNameJobShardingStrategy:根據作業名的雜湊值對作業節點串列進行輪轉的分片策略。
2.1 AverageAllocationJobShardingStrategy
AverageAllocationJobShardingStrategy,基於平均分配演演算法的分片策略。Elastic-Job-Lite 預設的作業分片策略。
如果分片不能整除,則不能整除的多餘分片將依次追加到序號小的作業節點。如:
如果有3臺作業節點,分成9片,則每臺作業節點分到的分片是:1=[0,1,2], 2=[3,4,5], 3=[6,7,8]
如果有3臺作業節點,分成8片,則每臺作業節點分到的分片是:1=[0,1,6], 2=[2,3,7], 3=[4,5]
如果有3臺作業節點,分成10片,則每臺作業節點分到的分片是:1=[0,1,2,9], 2=[3,4,5], 3=[6,7,8]
程式碼實現如下:
public final class AverageAllocationJobShardingStrategy implements JobShardingStrategy {
@Override
public Map> sharding(final List jobInstances, final String jobName, final int shardingTotalCount) {
// 不存在 作業執行實體
if (jobInstances.isEmpty()) {
return Collections.emptyMap();
}
// 分配能被整除的部分
Map> result = shardingAliquot(jobInstances, shardingTotalCount);
// 分配不能被整除的部分
addAliquant(jobInstances, shardingTotalCount, result);
return result;
}
}
-
呼叫
#shardingAliquot(...)方法分配能被整除的部分。能整除的咱就不舉例子。如果有 3 臺作業節點,分成 8 片,被整除的部分是前 6 片 [0, 1, 2, 3, 4, 5],呼叫該方法結果:1=[0,1], 2=[2,3], 3=[4,5]。private Map> shardingAliquot(final List shardingUnits, final int shardingTotalCount) {
Map> result = new LinkedHashMap<>(shardingTotalCount, 1);
int itemCountPerSharding = shardingTotalCount / shardingUnits.size(); // 每個作業執行實體分配的平均分片數
int count = 0;
for (JobInstance each : shardingUnits) {
ListshardingItems = new ArrayList<>(itemCountPerSharding + 1);
// 順序向下分配
for (int i = count * itemCountPerSharding; i 1) * itemCountPerSharding; i++) {
shardingItems.add(i);
}
result.put(each, shardingItems);
count++;
}
return result;
} -
呼叫
#addAliquant(...)方法分配能不被整除的部分。繼續上面的例子。不能被整除的部分是後 2 片 [6, 7],呼叫該方法結果:1=[0,1] + [6], 2=[2,3] + [7], 3=[4,5]。private void addAliquant(final ListshardingUnits, final int shardingTotalCount, final Map {> shardingResults)
int aliquant = shardingTotalCount % shardingUnits.size(); // 餘數
int count = 0;
for (Map.Entry> entry : shardingResults.entrySet()) {
if (count entry.getValue().add(shardingTotalCount / shardingUnits.size() * shardingUnits.size() + count);
}
count++;
}
}
如何實現主備
透過作業配置設定總分片數為 1 ( JobCoreConfiguration.shardingTotalCount = 1 ),只有一個作業分片能夠分配到作業分片項,從而達到一主N備。
2.2 OdevitySortByNameJobShardingStrategy
OdevitySortByNameJobShardingStrategy,根據作業名的雜湊值奇偶數決定IP升降序演演算法的分片策略。
作業名的雜湊值為奇數則IP 降序.
作業名的雜湊值為偶數則IP 升序.
用於不同的作業平均分配負載至不同的作業節點.
如:
如果有3臺作業節點, 分成2片, 作業名稱的雜湊值為奇數, 則每臺作業節點分到的分片是: 1=[ ], 2=[1], 3=[0].
如果有3臺作業節點, 分成2片, 作業名稱的雜湊值為偶數, 則每臺作業節點分到的分片是: 1=[0], 2=[1], 3=[ ].
實現程式碼如下:
@Override
public Map> sharding(final List jobInstances, final String jobName, final int shardingTotalCount) {
long jobNameHash = jobName.hashCode();
if (0 == jobNameHash % 2) {
Collections.reverse(jobInstances);
}
return averageAllocationJobShardingStrategy.sharding(jobInstances, jobName, shardingTotalCount);
}
-
從實現程式碼上,彷彿和 IP 升降序沒什麼關係?答案在傳遞進來的引數
jobInstances。jobInstances已經是按照 IP 進行降序的陣列。所以當判斷到作業名的雜湊值為偶數時,進行陣列反轉(Collections#reverse(...))實現按照 IP 升序。下麵看下為什麼說jobInstances已經按照 IP 進行降序:// ZookeeperRegistryCenter.java
@Override
public ListgetChildrenKeys(final String key) {
try {
Listresult = client.getChildren().forPath(key);
Collections.sort(result, new Comparator() { @Override
public int compare(final String o1, final String o2) {
return o2.compareTo(o1);
}
});
return result;} catch (final Exception ex) {
RegExceptionHandler.handleException(ex);
return Collections.emptyList();
}
} -
呼叫
AverageAllocationJobShardingStrategy#sharding(…)方法完成最終作業分片計算。
2.3 RotateServerByNameJobShardingStrategy
RotateServerByNameJobShardingStrategy,根據作業名的雜湊值對作業節點串列進行輪轉的分片策略。這裡的輪轉怎麼定義呢?如果有 3 臺作業節點,順序為 [0, 1, 2],如果作業名的雜湊值根據作業分片總數取模為 1, 作業節點順序變為 [1, 2, 0]。
分片的目的,是將作業的負載合理的分配到不同的作業節點上,要避免分片策略總是讓固定的作業節點負載特別大,其它工作節點負載特別小。這個也是為什麼官方對比 RotateServerByNameJobShardingStrategy、AverageAllocationJobShardingStrategy 如下:
AverageAllocationJobShardingStrategy的缺點是,一旦分片數小於作業作業節點數,作業將永遠分配至IP地址靠前的作業節點,導致IP地址靠後的作業節點空閑。如:
OdevitySortByNameJobShardingStrategy則可以根據作業名稱重新分配作業節點負載。
如果有3臺作業節點,分成2片,作業名稱的雜湊值為奇數,則每臺作業節點分到的分片是:1=[0], 2=[1], 3=[]
如果有3臺作業節點,分成2片,作業名稱的雜湊值為偶數,則每臺作業節點分到的分片是:3=[0], 2=[1], 1=[]
實現程式碼如下:
public final class RotateServerByNameJobShardingStrategy implements JobShardingStrategy {
private AverageAllocationJobShardingStrategy averageAllocationJobShardingStrategy = new AverageAllocationJobShardingStrategy();
@Override
public Map> sharding(final List jobInstances, final String jobName, final int shardingTotalCount) {
return averageAllocationJobShardingStrategy.sharding(rotateServerList(jobInstances, jobName), jobName, shardingTotalCount);
}
private List rotateServerList(final List shardingUnits, final String jobName) {
int shardingUnitsSize = shardingUnits.size();
int offset = Math.abs(jobName.hashCode()) % shardingUnitsSize; // 輪轉開始位置
if (0 == offset) {
return shardingUnits;
}
List result = new ArrayList<>(shardingUnitsSize);
for (int i = 0; i int index = (i + offset) % shardingUnitsSize;
result.add(shardingUnits.get(index));
}
return result;
}
}
-
呼叫
#rotateServerList(…)實現作業節點陣列輪轉。 -
呼叫
AverageAllocationJobShardingStrategy#sharding(…)方法完成最終作業分片計算。
3. 自定義作業分片策略
可能在你的業務場景下,需要實現自定義的作業分片策略。透過定義類實現 JobShardingStrategy 介面即可:
public final class OOXXShardingStrategy implements JobShardingStrategy {
@Override
public Map> sharding(final List jobInstances, final String jobName, final int shardingTotalCount) {
// 實現邏輯
}
}
實現後,配置實現類的全路徑到 Lite作業配置( LiteJobConfiguration )的 jobShardingStrategyClass 屬性。
作業進行分片計算時,作業分片策略工廠( JobShardingStrategyFactory ) 會建立作業分片策略實體:
public final class JobShardingStrategyFactory {
/**
* 獲取作業分片策略實體.
*
* @param jobShardingStrategyClassName 作業分片策略類名
* @return 作業分片策略實體
*/
public static JobShardingStrategy getStrategy(final String jobShardingStrategyClassName) {
if (Strings.isNullOrEmpty(jobShardingStrategyClassName)) {
return new AverageAllocationJobShardingStrategy();
}
try {
Class> jobShardingStrategyClass = Class.forName(jobShardingStrategyClassName);
if (!JobShardingStrategy.class.isAssignableFrom(jobShardingStrategyClass)) {
throw new JobConfigurationException("Class '%s' is not job strategy class", jobShardingStrategyClassName);
}
return (JobShardingStrategy) jobShardingStrategyClass.newInstance();
} catch (final ClassNotFoundException | InstantiationException | IllegalAccessException ex) {
throw new JobConfigurationException("Sharding strategy class '%s' config error, message details are '%s'", jobShardingStrategyClassName, ex.getMessage());
}
}
}
666. 彩蛋
旁白君:霧草,剛誇獎你,就又開始水更。
芋道君:咳咳咳,作業分片策略炒雞重要的好不好!嘿嘿嘿,為《Elastic-Job-Lite 原始碼分析 —— 作業分片》做個鋪墊嘛。
道友,趕緊上車,分享一波朋友圈!
如果你對 Dubbo / Netty 等等原始碼與原理感興趣,歡迎加入我的知識星球一起交流。長按下方二維碼噢:
目前在知識星球更新了《Dubbo 原始碼解析》目錄如下:
01. 除錯環境搭建
02. 專案結構一覽
03. 配置 Configuration
04. 核心流程一覽
05. 拓展機制 SPI
06. 執行緒池
07. 服務暴露 Export
08. 服務取用 Refer
09. 註冊中心 Registry
10. 動態編譯 Compile
11. 動態代理 Proxy
12. 服務呼叫 Invoke
13. 呼叫特性
14. 過濾器 Filter
15. NIO 伺服器
16. P2P 伺服器
17. HTTP 伺服器
18. 序列化 Serialization
19. 叢集容錯 Cluster
20. 優雅停機
21. 日誌適配
22. 狀態檢查
23. 監控中心 Monitor
24. 管理中心 Admin
25. 運維命令 QOS
26. 鏈路追蹤 Tracing
… 一共 69+ 篇
目前在知識星球更新了《Netty 原始碼解析》目錄如下:
01. 除錯環境搭建
02. NIO 基礎
03. Netty 簡介
04. 啟動 Bootstrap
05. 事件輪詢 EventLoop
06. 通道管道 ChannelPipeline
07. 通道 Channel
08. 位元組緩衝區 ByteBuf
09. 通道處理器 ChannelHandler
10. 編解碼 Codec
11. 工具類 Util
… 一共 61+ 篇
目前在知識星球更新了《資料庫物體設計》目錄如下:
01. 商品模組
02. 交易模組
03. 營銷模組
04. 公用模組
… 一共 17+ 篇
目前在知識星球更新了《Spring 原始碼解析》目錄如下:
01. 除錯環境搭建
02. IoC Resource 定位
03. IoC BeanDefinition 載入
04. IoC BeanDefinition 註冊
05. IoC Bean 獲取
06. IoC Bean 生命週期
… 一共 35+ 篇
原始碼不易↓↓↓↓↓
點贊支援老艿艿↓↓
