
精品專欄

作者:莫那·魯道
出處:併發程式設計之執行緒池的使用及擴充套件和最佳化
多執行緒的軟體設計方法確實可以最大限度的發揮現代多核處理器的計算能力,提高生產系統的吞吐量和效能。但是,如果一個系統同時建立大量執行緒,執行緒間頻繁的切換背景關係導致的系統開銷將會拖慢整個系統。嚴重的甚至導致記憶體耗盡導致OOM異常。因此,在實際的生產環境中,執行緒的數量必須得到控制,盲目的建立大量新車對系統是有傷害的。
那麼,怎麼才能最大限度的利用CPU的效能,又能保持系統的穩定性呢?其中有一個方法就是使用執行緒池。
簡而言之,在使用執行緒池後,建立執行緒便處理從執行緒池獲得空閑執行緒,關閉執行緒變成了向池子歸還執行緒。也就是說,提高了執行緒的復用。
而 JDK 在 1.5 之後為我提供了現成的執行緒池工具,我們今天就來學習看看如何使用他們。
-
Executors 執行緒池工廠能建立哪些執行緒池
-
如何手動建立執行緒池
-
如何擴充套件執行緒池
-
如何最佳化執行緒池的異常資訊
-
如何設計執行緒池中的執行緒數量
1. Executors 執行緒池工廠能建立哪些執行緒池
先來一個最簡單的執行緒池使用例子:
static class MyTask implements Runnable {
@Override
public void run() {
System.out
.println(System.currentTimeMillis() + ": Thread ID :" + Thread.currentThread().getId());
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) {
MyTask myTask = new MyTask();
ExecutorService service1 = Executors.newFixedThreadPool(5);
for (int i = 0; i < 10; i++) {
service1.submit(myTask);
}
service1.shutdown();
}
執行結果:

我們建立了一個執行緒池實體,並設定預設執行緒數量為5,並向執行緒池提交了10任務,分別列印當前毫秒時間和執行緒ID,從結果中,我們可以看到結果中有5個相同 id 的執行緒列印了毫秒時間。
這是最簡單的例子。
接下來我們講講其他的執行緒建立方式。
1. 固定執行緒池 ExecutorService service1 = Executors.newFixedThreadPool(5); 該方法傳回一個固定執行緒數量的執行緒池。該執行緒池中的執行緒數量始終不變。當有一個新的任務提交時,執行緒池中若有空閑執行緒,則立即執行,若沒有,則新的任務會被暫存在一個任務佇列(預設無界佇列 int 最大數)中,待有執行緒空閑時,便處理在任務佇列中的任務。
2. 單例執行緒池 ExecutorService service3 = Executors.newSingleThreadExecutor(); 該方法傳回一個只有一個執行緒的執行緒池。若多餘一個任務被提交到該執行緒池,任務會被儲存在一個任務佇列(預設無界佇列 int 最大數)中,待執行緒空閑,按先入先出的順序執行佇列中的任務。
3. 快取執行緒池 ExecutorService service2 = Executors.newCachedThreadPool(); 該方法傳回一個可根據實際情況調整執行緒數量的執行緒池,執行緒池的執行緒數量不確定,但若有空閑執行緒可以復用,則會優先使用可復用的執行緒,所有執行緒均在工作,如果有新的任務提交,則會建立新的執行緒處理任務。所有執行緒在當前任務執行完畢後,將傳回執行緒池進行復用。
4. 任務呼叫執行緒池 ExecutorService service4 = Executors.newScheduledThreadPool(2); 該方法也傳回一個 ScheduledThreadPoolExecutor 物件,該執行緒池可以指定執行緒數量。
前3個執行緒的用法沒什麼差異,關鍵是第四個,雖然執行緒任務排程框架很多,但是我們仍然可以學習該執行緒池。如何使用呢?下麵來個例子:
class A {
public static void main(String[] args) {
ScheduledThreadPoolExecutor service4 = (ScheduledThreadPoolExecutor) Executors
.newScheduledThreadPool(2);
// 如果前面的任務沒有完成,則排程也不會啟動
service4.scheduleAtFixedRate(new Runnable() {
@Override
public void run() {
try {
// 如果任務執行時間大於間隔時間,那麼就以執行時間為準(防止任務出現堆疊)。
Thread.sleep(10000);
System.out.println(System.currentTimeMillis() / 1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}// initialDelay(初始延遲) 表示第一次延時時間 ; period 表示間隔時間
}, 0, 2, TimeUnit.SECONDS);
service4.scheduleWithFixedDelay(new Runnable() {
@Override
public void run() {
try {
Thread.sleep(5000);
System.out.println(System.currentTimeMillis() / 1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}// initialDelay(初始延遲) 表示延時時間;delay + 任務執行時間 = 等於間隔時間 period
}, 0, 2, TimeUnit.SECONDS);
// 在給定時間,對任務進行一次排程
service4.schedule(new Runnable() {
@Override
public void run() {
System.out.println("5 秒之後執行 schedule");
}
}, 5, TimeUnit.SECONDS);
}
}
}
上面的程式碼建立了一個 ScheduledThreadPoolExecutor 任務排程執行緒池,分別呼叫了3個方法,需要著重解釋 scheduleAtFixedRate 和 scheduleWithFixedDelay 方法,這兩個方法的作用很相似,唯一的區別就是他們執行人物的間隔時間的計算方式,前者時間間隔演演算法是根據指定的 period 時間和任務執行時間中取時間長的,後者取的是指定的 delay 時間 + 任務執行時間。如果同學們有興趣,可以將上面的程式碼跑跑看。一樣便能看出端倪。
好了,JDK 給我們封裝了建立執行緒池的 4 個方法,但是,請註意,由於這些方法高度封裝,因此,如果使用不當,出了問題將無從排查,因此,我建議,程式員應到自己手動建立執行緒池,而手動建立的前提就是高度瞭解執行緒池的引數設定。那麼我們就來看看如何手動建立執行緒池。
2. 如何手動建立執行緒池
下麵是一個手動建立執行緒池的範本:
/**
* 預設5條執行緒(預設數量,即最少數量),
* 最大20執行緒(指定了執行緒池中的最大執行緒數量),
* 空閑時間0秒(當執行緒池梳理超過核心數量時,多餘的空閑時間的存活時間,即超過核心執行緒數量的空閑執行緒,在多長時間內,會被銷毀),
* 等待佇列長度1024,
* 執行緒名稱[MXR-Task-%d],方便回溯,
* 拒絕策略:當任務佇列已滿,丟擲RejectedExecutionException
* 異常。
*/
private static ThreadPoolExecutor threadPool = new ThreadPoolExecutor(5, 20, 0L,
TimeUnit.MILLISECONDS, new LinkedBlockingQueue<>(1024)
, new ThreadFactoryBuilder().setNameFormat("My-Task-%d").build()
, new AbortPolicy()
);
我們看到,ThreadPoolExecutor 也就是執行緒池有 7 個引數,我們一起來好好看看:
-
corePoolSize 執行緒池中核心執行緒數量
-
maximumPoolSize 最大執行緒數量
-
keepAliveTime 空閑時間(當執行緒池梳理超過核心數量時,多餘的空閑時間的存活時間,即超過核心執行緒數量的空閑執行緒,在多長時間內,會被銷毀)
-
unit 時間單位
-
workQueue 當核心執行緒工作已滿,需要儲存任務的佇列
-
threadFactory 建立執行緒的工廠
-
handler 當佇列滿了之後的拒絕策略
前面幾個引數我們就不講了,很簡單,主要是後面幾個引數,佇列,執行緒工廠,拒絕策略。
我們先看看佇列,執行緒池預設提供了 4 個佇列。
-
無界佇列: 預設大小 int 最大值,因此可能會耗盡系統記憶體,引起OOM,非常危險。
-
直接提交的佇列 : 沒有容量,不會儲存,直接建立新的執行緒,因此需要設定很大的執行緒池數。否則容易執行拒絕策略,也很危險。
-
有界佇列:如果core滿了,則儲存在佇列中,如果core滿了且佇列滿了,則建立執行緒,直到maximumPoolSize 到了,如果佇列滿了且最大執行緒數已經到了,則執行拒絕策略。
-
優先順序佇列:按照優先順序執行任務。也可以設定大小。
樓主在自己的專案中使用了無界佇列,但是設定了任務大小,1024。如果你的任務很多,建議分為多個執行緒池。不要把雞蛋放在一個籃子裡。
再看看拒絕策略,什麼是拒絕策略呢?當佇列滿了,如何處理那些仍然提交的任務。JDK 預設有4種策略。
-
AbortPolicy :直接丟擲異常,阻止系統正常工作.
-
CallerRunsPolicy : 只要執行緒池未關閉,該策略直接在呼叫者執行緒中,執行當前被丟棄的任務。顯然這樣做不會真的丟棄任務,但是,任務提交執行緒的效能極有可能會急劇下降。
-
DiscardOldestPolicy: 該策略將丟棄最老的一個請求,也就是即將被執行的一個任務,並嘗試再次提交當前任務.
-
DiscardPolicy: 該策略默默地丟棄無法處理的任務,不予任何處理,如果允許任務丟失,我覺得這是最好的方案.
當然,如果你不滿意JDK提供的拒絕策略,可以自己實現,只需要實現 RejectedExecutionHandler 介面,並重寫 rejectedExecution 方法即可。
最後,執行緒工廠,執行緒池的所有執行緒都由執行緒工廠來建立,而預設的執行緒工廠太過單一,我們看看預設的執行緒工廠是如何建立執行緒的:
/**
* The default thread factory
*/
static class DefaultThreadFactory implements ThreadFactory {
private static final AtomicInteger poolNumber = new AtomicInteger(1);
private final ThreadGroup group;
private final AtomicInteger threadNumber = new AtomicInteger(1);
private final String namePrefix;
DefaultThreadFactory() {
SecurityManager s = System.getSecurityManager();
group = (s != null) ? s.getThreadGroup() :
Thread.currentThread().getThreadGroup();
namePrefix = "pool-" +
poolNumber.getAndIncrement() +
"-thread-";
}
public Thread newThread(Runnable r) {
Thread t = new Thread(group, r,
namePrefix + threadNumber.getAndIncrement(),
0);
if (t.isDaemon())
t.setDaemon(false);
if (t.getPriority() != Thread.NORM_PRIORITY)
t.setPriority(Thread.NORM_PRIORITY);
return t;
}
}
可以看到,執行緒名稱為 pool- + 執行緒池編號 + -thread- + 執行緒編號 。設定為非守護執行緒。優先順序為預設。
如果我們想修改名稱呢?對,實現 ThreadFactory 介面,重寫 newThread 方法即可。但是已經有人造好輪子了, 比如我們的例子中使用的 google 的 guaua 提供的 ThreadFactoryBuilder 工廠。可以自定義執行緒名稱,是否守護,優先順序,異常處理等等,功能強大。
3. 如何擴充套件執行緒池
那麼我們能擴充套件執行緒池的功能嗎?比如記錄執行緒任務的執行時間。實際上,JDK 的執行緒池已經為我們預留的介面,在執行緒池核心方法中,有2 個方法是空的,就是給我們預留的。還有一個執行緒池退出時會呼叫的方法。我們看看例子:
/**
* 如何擴充套件執行緒池,重寫 beforeExecute, afterExecute, terminated 方法,這三個方法預設是空的。
*
* 可以監控每個執行緒任務執行的開始和結束時間,或者自定義一些增強。
*
* 在 Worker 的 runWork 方法中,會呼叫這些方法
*/
public class ExtendThreadPoolDemo {
static class MyTask implements Runnable {
String name;
public MyTask(String name) {
this.name = name;
}
@Override
public void run() {
System.out
.println("正在執行:Thread ID:" + Thread.currentThread().getId() + ", Task Name = " + name);
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) throws InterruptedException {
ExecutorService es = new ThreadPoolExecutor(5, 5, 0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<>()) {
@Override
protected void beforeExecute(Thread t, Runnable r) {
System.out.println("準備執行:" + ((MyTask) r).name);
}
@Override
protected void afterExecute(Runnable r, Throwable t) {
System.out.println("執行完成: " + ((MyTask) r).name);
}
@Override
protected void terminated() {
System.out.println("執行緒池退出");
}
};
for (int i = 0; i < 5; i++) {
MyTask myTask = new MyTask("TASK-GEYM-" + i);
es.execute(myTask);
Thread.sleep(10);
}
es.shutdown();
}
}
我們重寫了 beforeExecute 方法,也就是執行任務之前會呼叫該方法,而 afterExecute 方法則是在任務執行完畢後會呼叫該方法。還有一個 terminated 方法,在執行緒池退出時會呼叫該方法。執行結果是什麼呢?
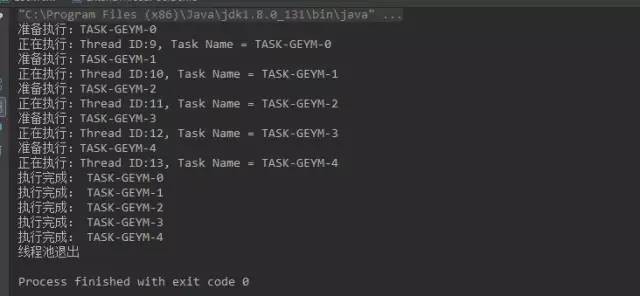
可以看到,每個任務執行前後都會呼叫 before 和 after 方法。相當於執行了一個切麵。而在呼叫 shutdown 方法後則會呼叫 terminated 方法。
4. 如何最佳化執行緒池的異常資訊
如何最佳化執行緒池的異常資訊? 在說這個問題之前,我們先說一個不容易發現的bug:
看程式碼:
public static void main(String[] args) throws ExecutionException, InterruptedException {
ThreadPoolExecutor executor = new ThreadPoolExecutor(0, Integer.MAX_VALUE, 0L,
TimeUnit.MILLISECONDS, new SynchronousQueue<>());
for (int i = 0; i < 5; i++) {
executor.submit(new DivTask(100, i));
}
}
static class DivTask implements Runnable {
int a, b;
public DivTask(int a, int b) {
this.a = a;
this.b = b;
}
@Override
public void run() {
double re = a / b;
System.out.println(re);
}
}
執行結果:

註意:只有4個結果,其中一個結果被吞沒了,並且沒有任何資訊。為什麼呢?如果仔細看程式碼,會發現,在進行 100 / 0 的時候肯定會報錯的,但是卻沒有報錯資訊,令人頭痛,為什麼呢?實際上,如果你使用 execute 方法則會列印錯誤資訊,當你使用 submit 方法卻沒有呼叫它的get 方法,異常將會被吞沒,因為,如果發生了異常,異常是作為傳回值傳回的。
怎麼辦呢?我們當然可以使用 execute 方法,但是我們可以有另一種方式:重寫 submit 方法,樓主寫了一個例子,大家看一下:
static class TraceThreadPoolExecutor extends ThreadPoolExecutor {
public TraceThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime,
TimeUnit unit, BlockingQueue<Runnable> workQueue) {
super(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue);
}
@Override
public void execute(Runnable command) {
// super.execute(command);
super.execute(wrap(command, clientTrace(), Thread.currentThread().getName()));
}
@Override
public Future> submit(Runnable task) {
// return super.submit(task);
return super.submit(wrap(task, clientTrace(), Thread.currentThread().getName()));
}
private Exception clientTrace() {
return new Exception("Client stack trace");
}
private Runnable wrap(final Runnable task, final Exception clientStack,
String clientThreaName) {
return new Runnable() {
@Override
public void run() {
try {
task.run();
} catch (Exception e) {
e.printStackTrace();
clientStack.printStackTrace();
throw e;
}
}
};
}
}
我們重寫了 submit 方法,封裝了異常資訊,如果發生了異常,將會列印堆疊資訊。我們看看使用重寫後的執行緒池後的結果是什麼?

從結果中,我們清楚的看到了錯誤資訊的原因:by zero!並且堆疊資訊明確,方便排錯。優化了預設執行緒池的策略。
5. 如何設計執行緒池中的執行緒數量
執行緒池的大小對系統的效能有一定的影響,過大或者過小的執行緒數量都無法發揮最優的系統效能,但是執行緒池大小的確定也不需要做的非常精確。因為只要避免極大和極小兩種情況,執行緒池的大小對效能的影響都不會影響太大,一般來說,確定執行緒池的大小需要考慮CPU數量,記憶體大小等因素,在《Java Concurrency in Practice》 書中給出了一個估算執行緒池大小的經驗公式:

公式還是有點複雜的,簡單來說,就是如果你是CPU密集型運算,那麼執行緒數量和CPU核心數相同就好,避免了大量無用的切換執行緒背景關係,如果你是IO密集型的話,需要大量等待,那麼執行緒數可以設定的多一些,比如CPU核心乘以2.
至於如何獲取 CPU 核心數,Java 提供了一個方法:
Runtime.getRuntime().availableProcessors();
傳回了CPU的核心數量。
總結
好了,到這裡,我們已經對如何使用執行緒池有了一個認識,這裡,樓主建議大家手動建立執行緒池,這樣對執行緒池中的各個引數可以有精準的瞭解,在對系統進行排錯或者調優的時候有好處。比如設定核心執行緒數多少合適,最大執行緒數,拒絕策略,執行緒工廠,佇列的大小和型別等等,也可以是G家的執行緒工廠自定義執行緒。
END

>>>>>> 加群交流技術 <<<<<<
