

在碎片化閱讀充斥眼球的時代,越來越少的人會去關註每篇論文背後的探索和思考。
在這個欄目裡,你會快速 get 每篇精選論文的亮點和痛點,時刻緊跟 AI 前沿成果。
點選本文底部的「閱讀原文」即刻加入社群,檢視更多最新論文推薦。
作者丨盧靖宇
學校丨西安電子科技大學碩士
研究方向丨自然語言處理
本期推薦的論文筆記來自 PaperWeekly 社群使用者 @hawksilent。本文創造性地將 Bootstrapping 關係提取中的自動選種任務,以及遠端監督關係提取中的降噪任務看成是根據不同的排序標準進行排序的問題,提出了多種兼具自動選種和資料降噪功能的策略。
文章的貢獻主要有以下幾點:
1. 創造性的將關係提取中的自動選種和資料降噪任務轉換成排序問題;
2. 提出多種既可用於 Bootstrapping 關係提取自動選種,又能用於遠端監督關係提取降噪的策略;
3. 在收集自 Wikipedia 和 ClueWeb 的資料集上,透過實驗證實提出的演演算法的實用性和先進性。


引言
最近閱讀了 Ranking-Based Automatic Seed Selection and Noise Reduction for Weakly Supervised Relation Extraction 這篇文章,該工作來自於 Nara Institute of Science and Technology,發表在 ACL 2018。
這篇文章主要對弱監督關係提取中兩個相關的任務展開研究:
-
Bootstrapping 關係提取(Bootstrapping RE)的自動選種任務;
-
遠端監督關係提取(Distantly Supervise RE)的降噪任務。
文章受到 Web 結構挖掘中最具有權威性、使用最廣泛的 Hypertext-induced topic search(HITS)演演算法,以及 K-means、潛在語意分析(LSA)、非負矩陣分解(NMF)等聚類中心選擇演演算法的啟發,提出一種能夠從現有資源中選擇初始化種子、並降低遠端標註資料噪聲的演演算法。
實驗證明,該演演算法的效能要好於上述兩個任務的基線系統。下麵是我對這篇文章的閱讀筆記。
問題引入
Bootstrapping RE 演演算法是機器學習中一種比較常用的弱監督學習方法。首先,利用一個稱作“seeds”的小實體集合進行初始化,用以表示特定的語意關係;然後,透過在大規模語料庫上迭代獲取實體和樣式,以發現與初始化種子相似的實體。該演演算法效能的主要制約因素在於語意漂移問題,而解決語意漂移問題的一種有效手段就是選擇出高質量的“seeds”。
Distantly Supervise 技術是一種用於構建大規模關係提取語料庫的有效方法。然而,由於錯誤標註問題的存在,遠端監督獲取的語料常常包含噪聲資料,這些噪聲會對監督學習演演算法效能造成不良影響。因此,如何降低錯誤標註帶來的資料噪聲,就成為了遠端監督技術的一個研究熱點。
問題轉化
用![]() 表示標的關係的集合,每一種標的關係
表示標的關係的集合,每一種標的關係 由一個三元組集合 Dr= {(e1, p, e2)} 來表示。其中,e1 和 e2 表示物體,物體對 (e1,e2) 被稱為實體,p 表示連線兩個物體的樣式。例如,三元組 (Barack Obama, was born in, Honolulu),(BarackObama, Honolulu) 表示一個實體,“was born in”表示樣式。
由一個三元組集合 Dr= {(e1, p, e2)} 來表示。其中,e1 和 e2 表示物體,物體對 (e1,e2) 被稱為實體,p 表示連線兩個物體的樣式。例如,三元組 (Barack Obama, was born in, Honolulu),(BarackObama, Honolulu) 表示一個實體,“was born in”表示樣式。
結合上述概念文章將所研究的兩個關係提取任務分別定義如下:
Bootstrapping RE 的自動選種任務:以標的關係集合![]() 為輸入,針對每一個,從由資料集中提取出的三元組集合 Dr 的實體中,選出能使 Bootstrapping RE 演演算法高效工作的種子。
為輸入,針對每一個,從由資料集中提取出的三元組集合 Dr 的實體中,選出能使 Bootstrapping RE 演演算法高效工作的種子。
Distantly Supervised RE 的降噪任務:從由 DS 自動為每個關係生成的三元組集合 Dr 中,過濾出所包含的噪聲三元組(錯誤標註三元組)。
由以上兩個任務的描述可以發現,無論是選種還是降噪都是從給定的集合中選出三元組。從排序的角度來看,這兩個任務實質上擁有相似的標的。
因此,文章將這兩個任務分別轉換為:在給定三元組集合 Dr(可能包含噪聲)的情況下,實體 (e1,e2 )的排序任務(選種)和三元組 (e1, p, e2 ) 的排序任務(降噪)。
在選種任務中,使用排名最高的 k 個實體作為 bootstrapping RE 的種子。同理,在降噪任務中,對於 DS 生成的三元組,使用其中排名最高的 k 個三元組來訓練分類器(降噪任務中的 k 值可能遠遠小於選種任務中的 k 值)。
自動選種和降噪演演算法
文章提出的演演算法受到了 Hypertext-induced topic search(HITS)演演算法,以及 K-means、潛在語意分析(LSA)、非負矩陣分解(NMF)等聚類中心選擇演演算法的啟發。
該演演算法根據具體的任務來決定是選擇實體還是選擇三元組:實體用於自動選種任務,三元組用於降噪任務。由於實體即為物體對,而物體對又包含在三元組中,因而可以透過實體和三元組之間的轉換,靈活的將提出的方法分別應用到兩個任務中。
基於K-means的演演算法
文章提出的基於 K-means 的演演算法具體描述如下:
1. 確定需要選擇的實體/三元組的數目 k;
2. 執行 K-means 聚類演演算法將輸入的三元組中的所有實體劃分為 k 個簇,每個資料點透過其對應物體間的嵌入向量差來表示。例如,實體 I=(Barack Obama,Honolulu) 對應於 vec(I)=vec(“Barack Obama”)-vec(“Honolulu”);
3. 從每個簇中選出最接近質心的實體。
基於HITS的演演算法
Hypertext-induced topic search(HITS)演演算法又稱為 hubs-and-authorities 演演算法,它是一種廣泛用於對 web 頁面排序的連結分析方法。
該演演算法的基本思想是:利用 Hub 頁面(包含了很多指向 Authority 頁面的連結的網頁)和 Authority 頁面(指與某個主題相關的高質量網頁)構成的二部圖,計算每個節點的樞紐度(hubness)得分,然後據此對網頁內容的質量和網頁連結的質量做出評價。
對於第 2 節描述的兩個任務,可透過實體 (e1,e2) 和樣式 p 的共生矩陣 A 生成兩者的二部圖,進而即可利用 HITS 演演算法的思想計算兩者的 hubness 得分。
文章提出的基於 HITS 思想的選種策略描述如下:
1. 確定要選擇的三元組的數目 k;
2. 基於實體-樣式的共生矩陣 A 構建實體和樣式的二部圖。下圖所示為構建二部圖的三種可能思路。思路一:將每一個實體/樣式均作為圖中的一個節點。思路二:將實體和樣式分別作為邊和節點。思路三:將實體和樣式分別作為節點和邊;

3. 對於思路一和思路三,僅保留 hubness 得分最高的 top k 個實體作為輸出。對於思路二,選擇與得分最高的樣式相關聯的 k 個實體作為輸出。
基於HITS和K-means的方法
該方法將 HITS 演演算法和 K-means 演演算法組合使用。首先,基於實體和樣式的二部圖對這兩者進行排序;然後,在標註資料集上執行 K-means 演演算法對實體進行聚類。之後,與常規思路不同,這裡不選擇距離質心最近的實體,而是選擇每個簇中 HITS 演演算法 hubness 得分最高的實體。
基於LSA的演演算法
潛在語意分析(LSA)是一種被廣泛應用的多維資料自動聚類方法,該方法利用奇異值分解(Singular value decomposition,SVD)演演算法構建實體-樣式共生矩陣 A 的等價低秩矩陣。
所謂 SVD,是將矩陣 分解為三個矩陣的乘積:SVD 實體矩陣
分解為三個矩陣的乘積:SVD 實體矩陣 ,奇異值對角矩陣
,奇異值對角矩陣 ,SVD樣式矩陣
,SVD樣式矩陣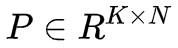 :
:

本文提出的基於 LSA 的選種策略具體描述如下:
1. 指定需要的三元組數目 k;
2. 利用 LSA 演演算法將實體-樣式的共生矩陣 A 分解為矩陣 I、S、P。將 LSA 的維度設定為 K=k;
3. 將 LSA 看作軟聚類的一種形式,其中 SVD 實體矩陣 I 的每一列對應一個簇。之後,從矩陣 I 的每一列選出絕對值最高的 k 個實體。
基於NMF的方法
非負矩陣分解(Non-negative matrix factorization,NMK)是另外一種用於近似非負矩陣分解的方法。非負矩陣 可以近似表示為
可以近似表示為 和
和 這兩個因子的乘積:
這兩個因子的乘積:
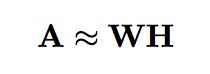
非負約束(non-negativity constraint)是 NMF 與 LSA 之間的主要區別。與基於 LSA 的方法類似,NMF 演演算法先將期望選擇的實體數目設定為 K=k。之後,從矩陣 W 的每一列中選出值最大的 k 個實體。
實驗
資料集與設定
文章使用了一個局整關係的標註資料集做為種子選擇的來源。該資料集提取自 Wikipedia 和 ClueWeb。這裡,所謂的局整關係並不是指某一種具體的關係,而是指一種型別的關係集合,如下表所示。

表中顯示出了局整關係集中 8 種子關係出現的頻率。資料集中 8 種子關係共有 5727 個標註實體。文章透過使用 Precision@N 來衡量提出的模型效能,其中取 N=50。實驗中 k 的值在區間 [5,50] 內以 5 為步長逐步遞增,對於每個選種方法給出其 P@50 的值。
在降噪任務中,文章使用由 (Riedel et al., 2010) 開發的訓練集和測試集,該資料集是透過將 Freebase 關係與紐約時報語料庫對齊而生成的,包含53 種關係型別。在使用提出的方法從資料集中濾除噪聲三元組之後,文章使用過濾後的資料對兩種摺積神經網路模型(CNN)進行了訓練:一種是 (Zeng et al., 2014) 提出的 CNN 模型,一種是 (Zeng et al., 2015) 提出的 PCNN 模型。
表中顯示出了局整關係集中 8 種子關係出現的頻率。資料集中 8 種子關係共有 5727 個標註實體。文章透過使用 Precision@N 來衡量提出的模型效能,其中取 N=50。實驗中 k 的值在區間 [5,50] 內以 5 為步長逐步遞增,對於每個選種方法給出其 P@50 的值。
在降噪任務中,文章使用由 (Riedel et al., 2010) 開發的訓練集和測試集,該資料集是透過將 Freebase 關係與紐約時報語料庫對齊而生成的,包含 53 種關係型別。在使用提出的方法從資料集中濾除噪聲三元組之後,文章使用過濾後的資料對兩種摺積神經網路模型(CNN)進行了訓練:一種是 (Zeng et al., 2014) 提出的 CNN 模型,一種是 (Zeng et al., 2015) 提出的 PCNN 模型。
自動選種演演算法效能
選種演演算法的實驗結果如下表所示。對於基於 HITS 的演演算法和基於 HITS+K-means 的演演算法,文章給出了相應的 P@50(分別採用 3.2 節介紹的三種構圖思路),實驗中使用隨機種子選擇做為對比基線。
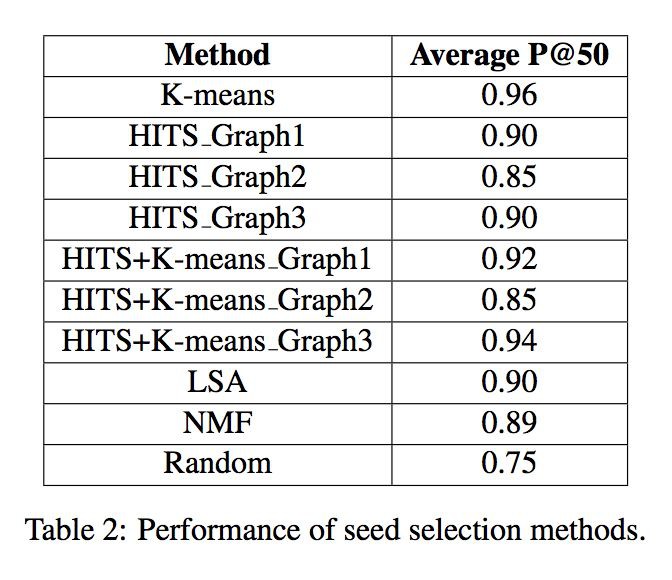
觀察實驗結果發現,隨機選種效能最差,為 0.75;基於 HITS 的策略、基於 LSA 的策略和基於 NMF 的策略,三種演演算法效能相當,都超過了基線演演算法;對於基於 HITS 的策略,三種不同的構圖思路中,思路一和思路三效能提升明顯,思路二效能雖有提升但效果明顯低於其他兩種策略;將 HITS 策略(構圖思路分別採用思路一和思路三)與 K-means 演演算法結合得到的效能在提出的演演算法中最佳。
HITS 策略中思路二效果不佳的原因在於:一個樣式可能含有歧義,因而連結到該樣式的實體可能並不與其匹配,這說明依靠實體選種要好於依靠樣式選種。
降噪演演算法效能
在降噪實驗中,文章分別採用基於 HITS、LSA 和 NMF 的演演算法,下表為各演演算法對於 CNN 和 PCNN 模型帶來的效能提升。表中最右邊一列為整合演演算法的效能,該方法結合基於 HITS 和基於 LSA 的策略,其中,一半的三元組來自基於 HITS 的演演算法,另一半三元組來自基於 LSA 的演演算法。

觀察實驗結果發現,基於 HITS 的策略表現最為穩定,對於四種模型都能提升其效能;基於 LSA 的策略,與註意力機制(無論模型是 CNN 還是 PCNN)結合使用時效能提升明顯,但與多實體學習演演算法結合使用則效果變差,甚至還要低於原始模型;基於 NMF 的策略,對於 PCNN 模型(無論採用多實體學習還是註意力機制)能帶來明顯的效能提升,但對於 CNN 模型效能改善不明顯;將基於 HITS 的策略和基於 LSA 的策略整合使用,則對於四種模型不但表現穩定,且效能提升效果也十分明顯。
總結
文章創造性地將關係提取中的自動選種和資料降噪這兩個重要任務轉換為排序問題。然後,借鑒 HITS、K-means、LSA 和 NMF 等傳統演演算法策略,按照對實體-樣式三元組排序的思路,構建出了兼具自動選種和資料降噪功能的演演算法。實驗結果顯示,文章提出的演演算法能夠有效完成自動選種和資料降噪任務,並且其效能同基線演演算法相比也有較大提升。
這篇文章的啟發作用在於:對於關係提取中的不同子任務透過問題轉換歸結為本質相同的同一問題,而後借鑒已有的成熟演演算法設計出可以通用的解決策略。這種思路上的開拓創新能否應用於其他 NLP 任務,是一個值得思考和探索的方向。
參考文獻
[1] Sebastian Riedel, Limin Yao, and Andrew McCallum. 2010. Modeling relations and their mentions without labeled text. In Proceedings of the 2010 Joint European Conference on Machine Learning and Principles of Knowledge Discovery in Databases (ECML PKDD), pages 148–163. Springer.
[2] Daojian Zeng, Kang Liu, Siwei Lai, Guangyou Zhou, and Jun Zhao. 2014. Relation classification via convolutional deep neural network. In Proceedings of COLING 2014, the 25th International Conference on Computational Linguistics: Technical Papers, pages 2335–2344. Dublin City University and Association for Computational Linguistics.
[3] Daojian Zeng, Kang Liu, Yubo Chen, and Jun Zhao.2015. Distant supervision for relation extraction via piecewise convolutional neural networks. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, pages 1753–1762. Association for Computational Linguistics.
本文由 AI 學術社群 PaperWeekly 精選推薦,社群目前已改寫自然語言處理、計算機視覺、人工智慧、機器學習、資料挖掘和資訊檢索等研究方向,點選「閱讀原文」即刻加入社群!

點選標題檢視更多論文解讀:
 #投 稿 通 道#
#投 稿 通 道#
讓你的論文被更多人看到
如何才能讓更多的優質內容以更短路徑到達讀者群體,縮短讀者尋找優質內容的成本呢? 答案就是:你不認識的人。
總有一些你不認識的人,知道你想知道的東西。PaperWeekly 或許可以成為一座橋梁,促使不同背景、不同方向的學者和學術靈感相互碰撞,迸發出更多的可能性。
PaperWeekly 鼓勵高校實驗室或個人,在我們的平臺上分享各類優質內容,可以是最新論文解讀,也可以是學習心得或技術乾貨。我們的目的只有一個,讓知識真正流動起來。
? 來稿標準:
• 稿件確系個人原創作品,來稿需註明作者個人資訊(姓名+學校/工作單位+學歷/職位+研究方向)
• 如果文章並非首發,請在投稿時提醒並附上所有已釋出連結
• PaperWeekly 預設每篇文章都是首發,均會新增“原創”標誌
? 投稿郵箱:
• 投稿郵箱:hr@paperweekly.site
• 所有文章配圖,請單獨在附件中傳送
• 請留下即時聯絡方式(微信或手機),以便我們在編輯釋出時和作者溝通
?
現在,在「知乎」也能找到我們了
進入知乎首頁搜尋「PaperWeekly」
點選「關註」訂閱我們的專欄吧
關於PaperWeekly
PaperWeekly 是一個推薦、解讀、討論、報道人工智慧前沿論文成果的學術平臺。如果你研究或從事 AI 領域,歡迎在公眾號後臺點選「交流群」,小助手將把你帶入 PaperWeekly 的交流群裡。

▽ 點選 | 閱讀原文 | 下載論文
