來自:無痴迷,不成功
連結:http://www.cnblogs.com/justmine/p/9696160.html
寫在前面
一直在不斷地探索響應式DDD,又get到了很多新知識,解惑了很多老問題,最近讀了Martin Fowler大師一篇非常精彩的部落格The LMAX Architecture,裡面有一個術語Mechanical Sympathy,姑且翻譯成軟硬體協同程式設計(Hardware and software working together in harmony),很有感悟,說的是要把程式設計與底層硬體協同起來,這樣對於開發低延遲、高併發的系統特別地重要,為什麼呢,今天我們就來講講CPU的高速快取。
電腦的快取系統

電腦的快取系統分了很多層級,從外到內依次是主記憶體、三級高速快取、二級高速快取、一次高速快取,所以,在我們的腦海裡,覺點磁碟的讀寫速度是很慢的,而記憶體的讀寫速度確是快速的,的確如此,從上圖磁碟和記憶體距離CPU的遠近距離就看出來。
這裡要說明一個概念,主記憶體被所有CPU共享,三級快取被同一個插槽內的CPU所共享,單個CPU獨享自己的一級、二級快取。
CPU是真正處理事情的地方,它會首先從高速快取中去獲取所需的資料,如果找不到,再去三級快取中查詢,如果還是找不到最終就去會主記憶體查詢,如果每一次都這樣來來回回地取資料,那麼無疑是非常耗時。
如果能夠把資料快取到高速快取中就好了,這樣CPU第一次就可以直接從高速快取中命中資料,但是這個地方對我們而言根本不透明,腫麼辦?
探索高速快取的構造
我們先來看一張使用魯大師檢測的處理器資訊截圖,如下:

從上圖可以看到,CPU高速快取(一、二級)的儲存單元為Line,大小為64 bytes,也就是說無論我們的資料大小是多少,高速快取都是以64 bytes為單位快取資料,比如一個8位的long型別陣列,即使只有第一位有資料,每次高速快取載入資料的時候,都會順帶把後面7位資料也一起載入,這是底層硬體運作的方式,所以我們要利用這個天然的優勢,讓資料獨佔整個快取行,這樣CPU命中的快取行中就一定有我們的資料。
示例
使用不同的執行緒數,對一個long型別的數值計數500億次。
備註:統計分析圖表和總結在最後。
1、一般的實現方式
大多數程式員都會這樣子構造資料,老鐵沒毛病。
程式碼
/////
///// CPU偽共享高速快取行條目(偽共享)
/////
public class FalseSharingCacheLineEntry
{
public long Value = 0L;
}
單執行緒
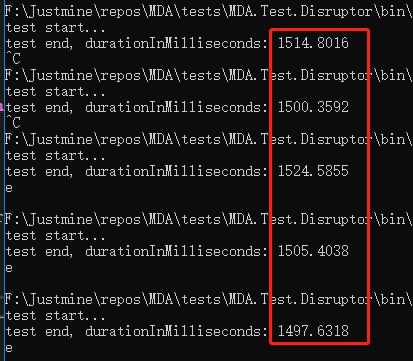
平均響應時間 = 1508.56 毫秒。
雙執行緒
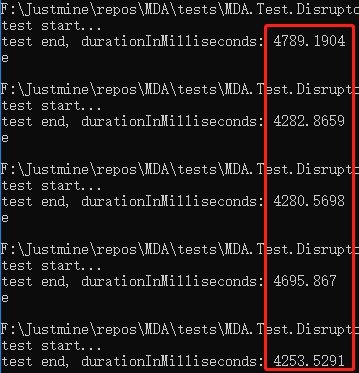
平均響應時間 = 4460.40 毫秒。
三執行緒

平均響應時間 = 7719.02 毫秒。
四執行緒
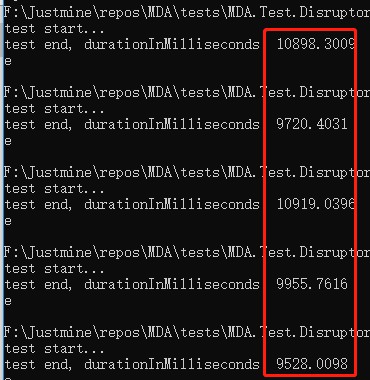
平均響應時間 = 10404.30 毫秒。
2、獨佔快取行,直接命中高速快取。
2.1 直接填充
程式碼
///
/// CPU高速快取行條目(直接填充)
///
public class CacheLineEntry
{
protected long P1, P2, P3, P4, P5, P6, P7;
public long Value = 0L;
protected long P9, P10, P11, P12, P13, P14, P15;
}
為了保證高速快取行中一定有我們的資料,所以前後都填充7個long。
單執行緒

平均響應時間 = 1516.33 毫秒。
雙執行緒
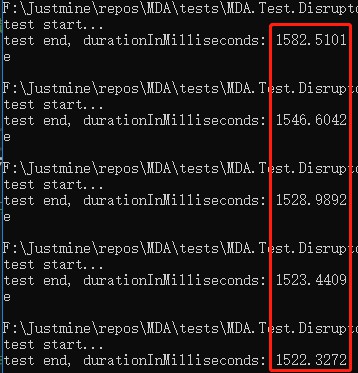
平均響應時間 = 1529.97 毫秒。
三執行緒
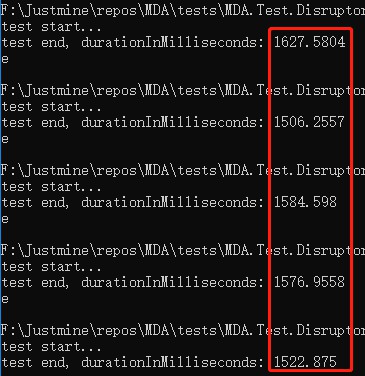
平均響應時間 = 1563.65 毫秒。
四執行緒

平均響應時間 = 1616.12 毫秒。
2.2 記憶體佈局填充
作為一個C#程式員,必須寫出優雅的程式碼,可以使用StructLayout、FieldOffset來控制class、struct的記憶體佈局。
備註:就是上面直接填充的優雅實現方式而已。
程式碼
///
/// CPU高速快取行條目(控制記憶體佈局)
///
[StructLayout(LayoutKind.Explicit, Size = 120)]
public class CacheLineEntryOne
{
[FieldOffset(56)]
private long _value;
public long Value
{
get => _value;
set => _value = value;
}
}
單執行緒

平均響應時間 = 2008.12 毫秒。
雙執行緒

平均響應時間 = 2046.33 毫秒。
三執行緒
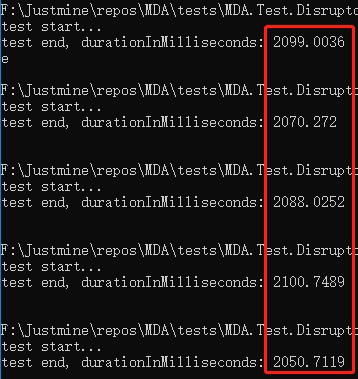
平均響應時間 = 2081.75 毫秒。
四執行緒

平均響應時間 = 2163.092 毫秒。
3、統計分析
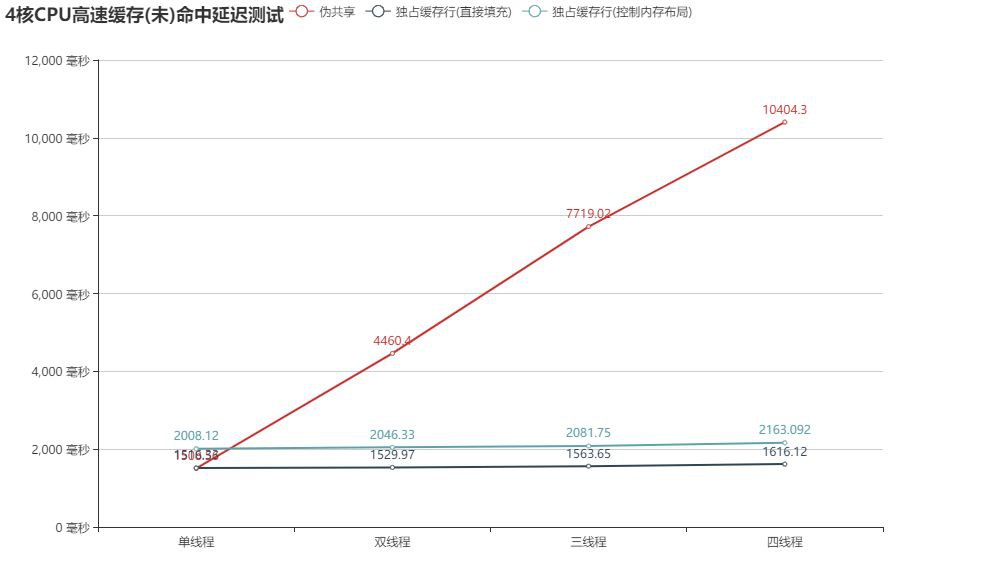
上面的圖表已經一目瞭然了吧,一般實現方式的持續時間隨執行緒數呈線性增長,多執行緒下表現的非常糟糕,而透過直接、記憶體佈局方式填充了資料後,響應時間與執行緒數的多少沒有無關,達到了真正的低延遲。
其中直接填充資料的方式,效率最高,記憶體佈局方式填充次之,在四執行緒的情況下,一般實現方式持續時間為10.4秒多,直接填充資料的方式為1.6秒,記憶體佈局填充方式為2.2秒,延遲還是比較明顯,為什麼會有這麼大的差距呢?
刨根問底
在C#下,一個long型別佔8 byte,對於一般的實現方式,在多執行緒的情況下,隸屬於每個獨立執行緒的資料會共用同一個快取行,所以只要有一個執行緒更新了快取行的資料,那麼整個快取行就自動失效,這樣就導致CPU永遠無法直接從高速快取中命中資料,每次都要經過一、二、三級快取到主記憶體中重新獲取資料,時間就是被浪費在了這樣的來來回回中。
而對資料進行填充後,隸屬於每個獨立執行緒的資料不僅被快取到了CPU的高速快取中,而且每個資料都獨佔整個快取行,其他的執行緒更新資料,並不會導致自己的快取行失效,所以每次CPU都可以直接命中,不管是單執行緒也好,還是多執行緒也好,只要執行緒數小於等於CPU的核數都和單執行緒一樣的快速,正如我們經常在一些效能測試軟體,都會看到的建議,執行緒數最好小於等於CPU核數,最多為CPU核數的兩倍,這樣壓測的結果才是比較準確的,現在明白了吧。
最後來看一下大師們總結的未命中快取的測試結果

原始碼參考:https://github.com/justmine66/MDA/blob/master/tests/MDA.Test.Disruptor/FalseSharingTest.cs
●編號158,輸入編號直達本文
●輸入m獲取文章目錄

Web開發
更多推薦《18個技術類公眾微信》
涵蓋:程式人生、演演算法與資料結構、駭客技術與網路安全、大資料技術、前端開發、Java、Python、Web開發、安卓開發、iOS開發、C/C++、.NET、Linux、資料庫、運維等。
