
導讀:現有的機器學習系統種類繁多,根據以下內容將它們進行分類有助於我們理解:
-
是否在人類監督下訓練(監督式學習、無監督式學習、半監督式學習和強化學習)
-
是否可以動態地進行增量學習(線上學習和批次學習)
-
是簡單地將新的資料點和已知的資料點進行匹配,還是像科學家那樣,對訓練資料進行樣式檢測,然後建立一個預測模型(基於實體的學習和基於模型的學習)
這些標準之間互相並不排斥,你可以以你喜歡的方式將其任意組合。例如,現在最先進的垃圾郵件過濾器可能是使用深度神經網路模型對垃圾郵件和常規郵件進行訓練,完成動態學習。這使其成為一個線上的、基於模型的、監督式學習系統。
作者:奧雷利安·傑龍(Aurélien Géron)
本文摘編自《機器學習實戰:基於Scikit-Learn和TensorFlow》,如需轉載請聯絡我們
我們來看看這幾個標準。
01 監督式/無監督式學習
根據訓練期間接受的監督數量和監督型別,可以將機器學習系統分為以下四個主要類別:監督式學習、無監督式學習、半監督式學習和強化學習。
1. 監督式學習
在監督式學習中,提供給演演算法的包含所需解決方案的訓練資料,稱之為標簽或標記(圖1-5)。

▲圖1-5:監督式學習中被標記的訓練集(例如,垃圾郵件分類)
分類任務是一個典型的監督式學習任務。垃圾郵件過濾器就是個很好的例子:透過大量的電子郵件示例及其所屬的類別(垃圾郵件或是常規郵件)進行訓練,然後學習如何對新郵件進行分類。
還有典型的任務,是透過預測變數——也就是一組給定的特徵(里程、使用年限、品牌等)——來預測一個標的數值,例如汽車的價格。這種型別的任務被稱為回歸任務(圖1-6)。要訓練這樣一個系統,你需要提供大量的汽車示例,包括它們的預測變數和它們的標簽(也就是它們的價格)。
在機器學習裡,屬性是一種資料型別(例如“里程”);而特徵取決於背景關係,可能有多個含義,但是通常狀況下,特徵意味著一個屬性加上其值(例如,“里程=15,000”)。儘管如此,許多人還是會交替使用屬性和特徵這兩個名詞。

▲圖1-6:回歸任務
值得註意的是,一些回歸演演算法也可以用於分類任務,反之亦然。例如,邏輯回歸就被廣泛地用於分類,因為它可以輸出“屬於某個給定類別的機率”的值(例如,20%的機率是垃圾郵件)。
這裡是一些最重要的監督式學習的演演算法:
-
K-近臨演演算法(k-Nearest Neighbors)
-
線性回歸(Linear Regression)
-
邏輯回歸(Logistic Regression)
-
支援向量機(Support Vector Machines,簡稱SVMs)
-
決策樹和隨機森林(Decision Trees and Random Forests)
-
神經網路(Neural networks)
2. 無監督式學習
無監督式學習,顧名思義,你可能已經猜到,訓練資料都是未經標記的(圖1-7)。系統會在沒有老師的情況下進行學習。

▲圖1-7:無監督式學習的未標記訓練集
這裡有一些最重要的無監督式學習的演演算法:
聚類演演算法
-
k-平均演演算法(k-Means)
-
系統聚類分析(Hierarchical Cluster Analysis,簡稱HCA)
-
最大期望演演算法(Expectation Maximization)
視覺化和降維
-
主成分分析(PCA)
-
核主成分分析(Kernel PCA)
-
區域性線性嵌入(LLE)
-
t-分佈隨機近臨嵌入(t-SNE)
關聯規則學習
-
Apriori
-
Eclat
例如,假設你現在擁有大量的自己部落格訪客的資料。你想透過一個聚類演演算法來檢測相似訪客的分組(圖1-8)。你不大可能告訴這個演演算法每個訪客屬於哪個分組——而是要它自己去尋找這種關聯,無需你的幫助。
比如說,它可能會註意到40%的訪客是喜歡漫畫的男性,並且通常是在夜晚閱讀你的部落格,20%的訪客是年輕的科幻愛好者,通常是在週末訪問,等等。如果你使用的是層次聚類的演演算法,它還可以將每組細分為更小的組。這可能有助於你針對不同的分組來釋出部落格內容。

▲圖1-8:聚類
視覺化演演算法也是無監督式學習演演算法的好例子:你提供大量複雜的、未標記的資料,得到輕鬆繪製而成的2D或3D的資料呈現作為輸出(圖1-9)。這些演演算法會盡其所能地保留儘量多的結構(譬如,嘗試保持讓輸入的單獨叢集在視覺化中不會被重疊),以便於你理解這些資料是怎麼組織的,甚至識別出一些未知的樣式。

▲圖1-9:一個使用t-SNE演演算法的視覺化示例,突顯了各種語意叢
與之相關的另一種任務是降維,降維的目的是在不丟失太多資訊的前提下簡化資料。方法之一是將多個相關特徵合併為一個。例如,汽車的里程與其使用年限存在很大的相關性,所以降維演演算法會將它們合併成一個代表汽車磨損的特徵。這個過程被稱之為特稱提取。
通常比較好的做法是,先使用降維演演算法減少訓練資料的維度,再將其提供給另一個機器學習演演算法(例如監督式學習演演算法)。這會使它執行得更快,資料佔用的磁碟空間和記憶體都會更小,在某些情況下,執行效能也會更好。
另一個很重要的無監督式任務是異常檢測——例如,檢測異常信用卡交易從而防止欺詐,捕捉製造缺陷,或者是在提供資料給一種機器學習演演算法之前,自動從資料集中移除異常值。系統用正常實體進行訓練,然後當它看到新的實體時,它就可以判斷出這個新實體看上去是正常還是異常(見圖1-10)。
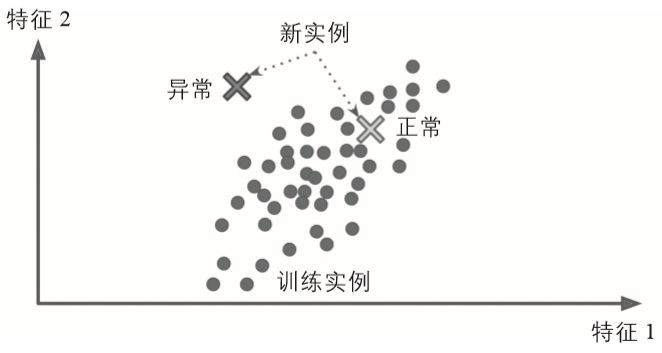
▲圖1-10:異常檢測
最後,還有一個常見的無監督式任務是關聯規則學習,其目的是挖掘大量資料,發現屬性之間的有趣聯絡。比如說,假設你開了一家超市,在銷售日誌上執行關聯規則之後發現買燒烤醬和薯片的人,也傾向於購買牛排。那麼,你可能會將這幾樣商品擺放得更為靠近一些。
3. 半監督式學習
有些演演算法可以處理部分標記的訓練資料——通常是大量未標記資料和少量的標記資料。這被稱為半監督式學習(圖1-11)。
有些照片託管服務(例如 Google 相簿)就是很好的例子。一旦你將所有的家庭照片上傳到服務後,它會自動識別出人物A出現在照片1、5和11中,另一個人B出現在照片2、5和7中。這是演演算法中無監督的部分(聚類)。現在系統需要你做的只是,告訴它這些人都是誰。給每個人一個標簽之後,它就可以給每張照片中的每個人命名,這對於搜尋圖片非常重要。
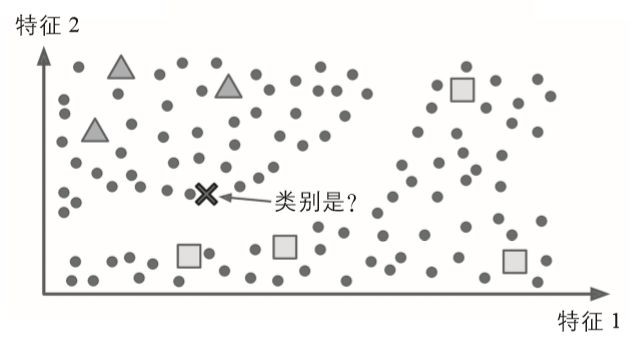
▲圖1-11:半監督式學習
大多數半監督式學習演演算法是無監督和監督式演演算法的結合。例如深度信念網路(DBNs),它基於一種互相堆疊的無監督式元件,這個元件叫做受限玻爾茲曼機(RBMs)。受限玻爾茲曼機以無監督的方式進行訓練,然後使用監督式學習對整個系統進行微調。
4. 強化學習
強化學習則是一個非常與眾不同的巨獸。它的學習系統(在其語境中被稱為智慧體)能夠觀察環境,做出選擇,執行操作,並獲得回報(rewards),或者是以負面回報的形式獲得懲罰,見圖1-12。所以它必須自行學習什麼是最好的策略 (policy),從而隨著時間推移獲得最大的回報。策略代表智慧體在特定情況下應該選擇的操作。
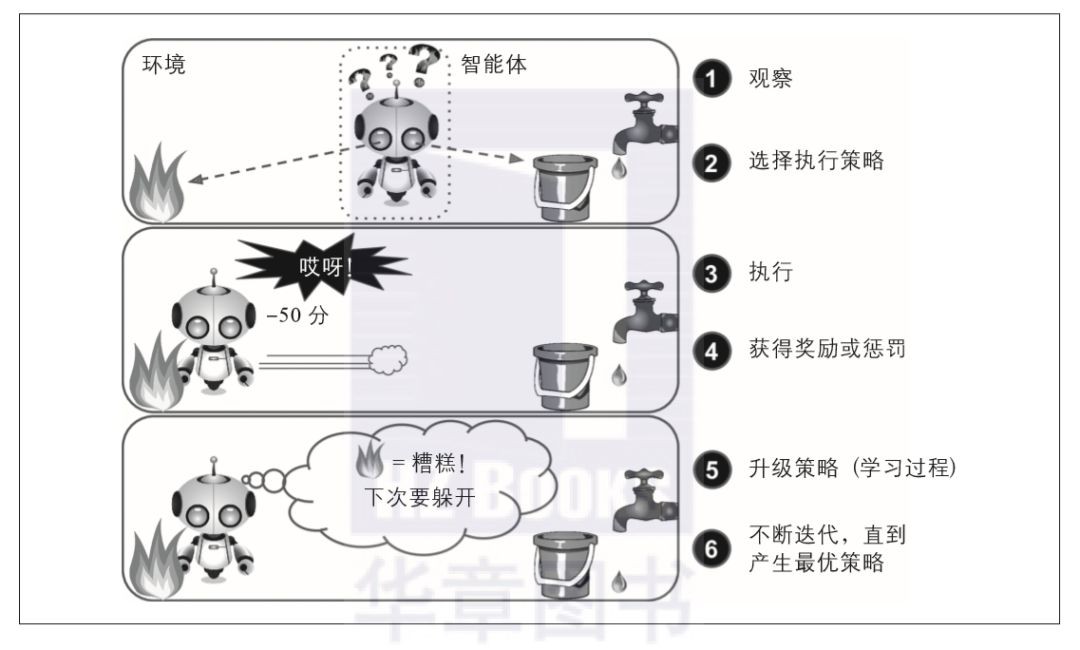
▲圖1-12:強化學習
例如,許多機器人透過強化學習演演算法來學習如何行走。DeepMind的AlphaGo專案也是一個強化學習的好例子——2016年3月,AlphaGo在圍棋比賽中擊敗世界冠軍李世乭而聲名鵲起。透過分析數百萬場比賽,然後自己跟自己下棋,它學到了它的制勝策略。要註意,在跟世界冠軍對弈的時候,AlphaGo處於關閉學習狀態下,它只是應用它所學到的策略而已。
02 批次學習和線上學習
還有一個給機器學習系統分類的標準,是看系統是否可以從傳入的資料流中進行增量學習。
1. 批次學習
批次學習中,系統無法進行增量學習——即必須使用所有可用資料進行訓練。這需要大量時間和計算資源,所以通常情形下,都是離線完成的。離線學習就是先訓練系統,然後將其投入生產環境,這時學習過程停止,它只是將其所學到的應用出來。
如果你希望批次學習系統學習新資料(例如新型垃圾郵件),你需要在完整資料集(不僅僅是新資料,還要包括舊資料)的基礎上重新訓練一個新版本的系統,然後停用舊系統,用新系統取而代之。
幸運的是,整個訓練、評估和啟動機器學習系統的過程可以很輕易地實現自動化(如圖1-13所示),所以即使是批次學習系統也能夠適應變化。只是需要不斷地更新資料,以及根據需要,頻繁地訓練新版本的系統。

▲圖1-13:線上學習
這個解決方法比較簡單,通常情況下也都能正常工作,只是每次都使用全套資料集進行訓練可能需要花上好幾個小時,所以,你很有可能會選擇每天甚至每週訓練一次新系統。如果你的系統需要應對快速變化的資料(例如,預測股票價格),那麼你需要一個更具響應力的解決方案。
此外,使用完整資料訓練需要耗費大量的計算資源(CPU、記憶體空間、磁碟空間、磁碟I/O、網路I/O等等)。如果你的資料量非常大,並且每天自動執行重新訓練系統,那最終你將為此花費大量的金錢。而假如資料量更海量一些,你甚至可能無法再應用批次學習演演算法。
所以如果你的資源有限(例如,智慧手機應用程式或者是火星上的漫遊器),而系統需要實現自主學習,那麼像這樣攜帶大量訓練資料,佔用大量資源,動輒每天耗費幾小時來進行訓練的方式,肯定是心有餘而力不足。
幸運的是,在所有這些情況下,我們有了一個更好的選擇——也就是能夠進行增量學習的演演算法。
2. 線上學習
在線上學習中,你可以循序漸進地給系統提供訓練資料,逐步積累學習成果。這種提供資料的方式可以是單獨地,也可以採用小批次(mini-batches)的小組資料來進行訓練。每一步學習都很快速並且便宜,所以系統就可以根據飛速寫入的最新資料進行學習(見圖1-13)。
對於這類系統——需要接收持續的資料流(例如股票價格)同時對資料流的變化做出快速或自主的反應,使用線上學習系統是一個非常好的方式。如果你的計算資源有限,它同樣也是一個很好的選擇:新的資料實體一旦經過系統的學習,就不再需要,你可以將其丟棄(除非你想要回滾到前一個狀態,再“重新學習”資料),這可以節省大量的空間。
對於超大資料集——超出一臺計算機的主儲存器的資料,線上學習演演算法也同樣適用(這被稱為out-of-core核外學習)。演演算法每次只加載部分資料,並針對這部分資料進行訓練,然後不斷重覆這個過程,直到完成所有資料的訓練(見圖1-14)。

▲圖1-14:使用線上學習處理超大資料集
整個過程通常是離線完成的(也就是不在live系統上),因此線上學習這個名字很容易讓人產生誤解。可以將其視為增量學習。
線上學習系統的一個重要引數,是看它能夠多快適應不斷變化的資料,這就是所謂的學習率。如果設定的學習率很高,那麼系統將會迅速適應新資料,但同時也很快忘記舊資料(你肯定不會希望垃圾郵件過濾器只對最新顯示的郵件進行標記)。
反過來,如果學習率很低,系統會有更高的惰性,也就是說,它學習會更緩慢,同時也會對新資料中的噪聲或者非典型資料點的序列更不敏感。
線上學習面臨的一個重大挑戰是,如果給系統輸入不良資料,系統的效能將會逐漸下降。現在某些實時系統的客戶,說不定已經註意到了這個現象。不良資料的來源可能是,例如,機器上發生故障的感測器,或者是有人對搜尋引擎惡意刷屏以提高搜尋結果排名等等。
為了降低這種風險,你需要密切監控你的系統,一旦檢測到效能下降,要及時中斷學習(可能還需要恢復到之前的工作狀態)。當然,你同時還需要監控資料輸入,並對異常資料做出響應(例如,使用異常檢測演演算法)。
03 基於實體與基於模型的學習
另一種對機器學習系統進行分類的方法是看它們如何泛化。大多數機器學習任務是要做出預測。這意味著,系統需要透過給定的訓練示例,在它此前並未見過的示例上進行泛化。在訓練資料上實現良好的效能指標固然重要,但是還不夠充分;真正的目的是要在新的物件實體上表現出色。
泛化的主要方法有兩種:基於實體的學習和基於模型的學習。
1. 基於實體的學習
我們最司空見慣的學習方法就是簡單的死記硬背。如果你以這種方式建立一個垃圾郵件過濾器,那它可能只會標記那些跟已被使用者標記為垃圾郵件完全相同的郵件——這雖然不是最差的解決方案,但肯定也不是最好的。
除了完全相同的,你還可以透過程式設計讓系統標記與已知的垃圾郵件非常相似的郵件。這裡需要兩封郵件之間的相似度度量。有一種(基本的)相似度度量方式,是計算它們之間相同的單詞數目。如果一封新郵件與一封已知的垃圾郵件有許多字句相同,系統就可以將其標記為垃圾郵件。
這便是基於實體的學習:系統先完全記住學習示例(examples),然後透過某種相似度度量方式將其泛化到新的實體(圖1-15)。

▲圖1-15:基於實體的學習
2. 基於模型的學習
從一組示例集中實現泛化的另一種方法,是構建這些示例的模型,然後使用該模型進行預測。這就是基於模型的學習(圖1-16)。

▲圖1-16:基於模型的學習
舉例來說,假設你想知道金錢是否讓人感到快樂,你可以從經合組織(OECD)的網站上下載“幸福指數”的資料,再從國際貨幣基金組織(IMF)的網站上找到人均GDP的統計資料,將資料併入表格,按照人均GDP排序,你會得到如表1-1顯示的摘要。
|
國家 |
人均GDP |
生活滿意度 |
|
匈牙利 |
12 240 |
4.9 |
|
韓國 |
27 195 |
5.8 |
|
法國 |
37 675 |
6.5 |
|
澳大利亞 |
50 962 |
7.3 |
|
美國 |
55 805 |
7.2 |
▲表1-1:金錢是否讓人感到快樂?
讓我們隨機繪製幾個國家的資料(圖1-17)。

▲圖1-17:看出趨勢了麼?
這裡似乎有一個趨勢!雖然資料包含噪聲(即部分隨機),但是仍然可以看出隨著國內生產總值的增加,生活滿意度或多或少呈現線性上升的趨勢。所以你可以把生活滿意度建模成一個關於人均GDP的線性函式。這個過程稱之為模型選擇:你為生活滿意度選擇了一個線性模型,該模型只有一個屬性,就是人均GDP(見以下公式)。
-
生活滿意度=θ0+θ1×人均GDP
這個模型有兩個引數,θ0和θ1。透過調整這兩個引數,你可以用這個模型來代表任意線性函式,如圖1-18所示。

▲圖1-18:可能的線性模型
在使用模型之前,需要先定義引數θ0和 θ1的值。怎麼才能知道什麼值可以使得模型表現最佳呢?要回答這個問題,需要先確定怎麼衡量模型的效能表現。要麼定義一個效用函式(或適應度函式)來衡量模型有多好,要麼定義一個成本函式來衡量模型有多差。
對於線性回歸問題,通常的選擇是使用成本函式來衡量線性模型的預測與訓練實體之間的差距,目的在於儘量使這個差距最小化。
這正是線性回歸演演算法的意義所在:透過你提供的訓練樣本,找出最符合所提供資料的線性模型的引數,這就是訓練模型的過程。在我們這個案例中,演演算法找到的最優引數值為θ0 = 4.85,θ1 = 4.91× 10-5
現在,模型基本接近訓練資料(對於線性模型而言),如圖1-19所示。

▲圖1-19:對訓練資料擬合最佳的線性模型
現在終於可以運用模型來進行預測了。例如,你想知道塞普勒斯的人民有多幸福,但是經合組織的資料沒有提供答案。幸好你有這個模型可以做出預測:先查查塞普勒斯的人均GDP是多少,22,587美元,然後應用到模型中,發現生活滿意度可能在4.85 + 22587 × 4.91 × 10-5 = 5.96。
為了激發你的興趣,下麵的示例是一段載入資料的Python程式碼,包括準備資料,建立一個視覺化的散點圖,然後訓練線性模型並作出預測。
示例:使用Scikit-Learn訓練並執行一個線性模型
import matplotlibimport matplotlib.pyplot as pltimport numpy as npimport pandas as pdimport sklearn# Load the dataoecd_bli = pd.read_csv("oecd_bli_2015.csv", thousands=',')gdp_per_capita = pd.read_csv("gdp_per_capita.csv",thousands=',',delimiter='\t', encoding='latin1', na_values="n/a")# Prepare the datacountry_stats = prepare_country_stats(oecd_bli, gdp_per_capita)X = np.c_[country_stats["GDP per capita"]]y = np.c_[country_stats["Life satisfaction"]]# Visualize the datacountry_stats.plot(kind='scatter', x="GDP per capita", y='Life satisfaction')plt.show()# Select a linear modellin_reg_model = sklearn.linear_model.LinearRegression()# Train the modellin_reg_model.fit(X, y)# Make a prediction for CyprusX_new = [[22587]] # Cyprus' GDP per capitaprint(lin_reg_model.predict(X_new)) # outputs [[ 5.96242338]]如果使用基於實體的學習演演算法,那麼你會發現斯洛維尼亞的人均GDP最接近塞普勒斯(20,732美元),而經合組織的資料告訴我們,斯洛維尼亞人民的生活滿意度是5.7,因此你很可能會預測塞普勒斯的生活滿意度為5.7。
如果稍微拉遠一些,看看兩個與之最接近的國家——葡萄牙和西班牙的生活滿意度分別為5.1和6.5。取這三個數值的平均值,得到5.77,這也非常接近你基於模型預測所得的值。這個簡單的演演算法被稱為k-近臨回歸演演算法(在本例中,k = 3)。
要將前面程式碼中的線性回歸模型替換為k-近臨回歸模型非常簡單,只需要將下麵這行程式碼:
clf = sklearn.linear_model.LinearRegression()替換為:
clf = sklearn.neighbors.KNeighborsRegressor(n_neighbors=3)如果一切順利,你的模型將能做出很棒的預測。如果不行,你可能需要使用更多的屬性(例如就業率、健康、空氣汙染等等),或者是獲得更多或更高質量的訓練資料,再或者是選擇一個更強大的模型(例如,多項式回歸模型)。
簡而言之:
-
學習資料。
-
選擇模型。
-
使用訓練資料進行訓練(即前面學習演演算法搜尋模型引數值,從而使成本函式最小化的過程)。
-
最後,應用模型對新示例進行預測(這稱之為推斷),祈禱模型的泛化結果不錯。
以上就是一個典型的機器學習專案。到目前為止,我們已經介紹了多個領域,你已經知道了機器學習系統最常見的類別有哪些,以及典型的專案工作流程。
關於作者:奧雷利安·傑龍(Aurélien Géron)是機器學習方面的顧問。他曾是Google軟體工程師,在2013年到2016年主導了YouTube影片分類工程。2002年和2012年,他還是Wifirst公司(一家法國的無線ISP)的創始人和技術長,2001年是Ployconseil公司(現在管理電動汽車共享服務Autolib)的創始人和技術長。
本文摘編自《機器學習實戰:基於Scikit-Learn和TensorFlow》,經出版方授權釋出。
延伸閱讀《機器學習實戰》
點選上圖瞭解及購買
轉載請聯絡微信:togo-maruko
推薦語:前谷歌工程師撰寫,“美亞”人工智慧圖書暢銷榜首圖書 從實踐出發,手把手教你從零開始搭建起一個神經網路。

據統計,99%的大咖都完成了這個神操作
▼
更多精彩
在公眾號後臺對話方塊輸入以下關鍵詞
檢視更多優質內容!
PPT | 報告 | 讀書 | 書單
Python | 機器學習 | 深度學習 | 神經網路
區塊鏈 | 揭秘 | 乾貨 | 數學
猜你想看
Q: 這些分類你都應用過哪些?
歡迎留言與大家分享
覺得不錯,請把這篇文章分享給你的朋友
轉載 / 投稿請聯絡:baiyu@hzbook.com
更多精彩,請在後臺點選“歷史文章”檢視

 點選閱讀原文,瞭解更多
點選閱讀原文,瞭解更多
