
作者丨蘇劍林
單位丨廣州火焰資訊科技有限公司
研究方向丨NLP,神經網路
個人主頁丨kexue.fm
去年寫過一篇 WGAN-GP 的入門讀物互懟的藝術:從零直達WGAN-GP,提到透過梯度懲罰來為 WGAN 的判別器增加 Lipschitz 約束(下麵簡稱“L 約束”)。前幾天遐想時再次想到了 WGAN,總覺得 WGAN 的梯度懲罰不夠優雅,後來也聽說 WGAN 在條件生成時很難搞(因為不同類的隨機插值就開始亂了),所以就想琢磨一下能不能搞出個新的方案來給判別器增加L約束。
閉門造車想了幾天,然後發現想出來的東西別人都已經做了,果然是隻有你想不到,沒有別人做不到呀。主要包含在這兩篇論文中:Spectral Norm Regularization for Improving the Generalizability of Deep Learning [1] 和 Spectral Normalization for Generative Adversarial Networks [2]。
所以這篇文章就按照自己的理解思路,對L約束相關的內容進行簡單的介紹。註意本文的主題是 L 約束,並不只是 WGAN。它可以用在生成模型中,也可以用在一般的監督學習中。
L約束與泛化
擾動敏感
記輸入為 x,輸出為 y,模型為 f,模型引數為 w,記為:

很多時候,我們希望得到一個“穩健”的模型。何為穩健?一般來說有兩種含義,一是對於引數擾動的穩定性,比如模型變成了 fw+Δw(x) 後是否還能達到相近的效果?如果在動力學系統中,還要考慮模型最終是否能恢復到 fw(x);二是對於輸入擾動的穩定性,比如輸入從 x 變成了 x+Δx 後,fw(x+Δx) 是否能給出相近的預測結果。
讀者或許已經聽說過深度學習模型存在“對抗攻擊樣本”,比如圖片只改變一個畫素就給出完全不一樣的分類結果,這就是模型對輸入過於敏感的案例。
L約束
所以,大多數時候我們都希望模型對輸入擾動是不敏感的,這通常能提高模型的泛化效能。也就是說,我們希望 ||x1−x2|| 很小時:

也盡可能地小。當然,“盡可能”究竟是怎樣,誰也說不準。於是 Lipschitz 提出了一個更具體的約束,那就是存在某個常數 C(它只與引數有關,與輸入無關),使得下式恆成立:

也就是說,希望整個模型被一個線性函式“控制”住。這便是 L 約束了。
換言之,在這裡我們認為滿足 L 約束的模型才是一個好模型。並且對於具體的模型,我們希望估算出 C(w) 的運算式,並且希望 C(w) 越小越好,越小意味著它對輸入擾動越不敏感,泛化性越好。
神經網路
在這裡我們對具體的神經網路進行分析,以觀察神經網路在什麼時候會滿足 L 約束。
簡單而言,我們考慮單層的全連線 f(Wx+b),這裡的 f 是啟用函式,而 W,b 則是引數矩陣/向量,這時候 (3) 變為:

讓 x1,x2 充分接近,那麼就可以將左邊用一階項近似,得到:

顯然,要希望左邊不超過右邊,∂f/∂x 這一項(每個元素)的絕對值必須不超過某個常數。這就要求我們要使用“導數有上下界”的啟用函式,不過我們目前常用的啟用函式,比如sigmoid、tanh、relu等,都滿足這個條件。假定啟用函式的梯度已經有界,尤其是我們常用的 relu 啟用函式來說這個界還是 1,因此 ∂f/∂x 這一項只帶來一個常數,我們暫時忽略它,剩下來我們只需要考慮 ||W(x1−x2)||。
多層的神經網路可以逐步遞迴分析,從而最終還是單層的神經網路問題,而 CNN、RNN 等結構本質上還是特殊的全連線,所以照樣可以用全連線的結果。因此,對於神經網路來說,問題變成了:如果下式恆成立,那麼 C 的值可以是多少?

找出 C 的運算式後,我們就可以希望 C 盡可能小,從而給引數帶來一個正則化項![]() 。
。
矩陣範數
定義
其實到這裡,我們已經將問題轉化為了一個矩陣範數問題(矩陣範數的作用相當於向量的模長),它定義為:

如果 W 是一個方陣,那麼該範數又稱為“譜範數”、“譜半徑”等,在本文中就算它不是方陣我們也叫它“譜範數(Spectral Norm)”好了。註意 ||Wx|| 和 ||x|| 都是指向量的範數,就是普通的向量模長。而左邊的矩陣的範數我們本來沒有明確定義的,但透過右邊的向量模型的極限定義出來的,所以這類矩陣範數稱為“由向量範數誘匯出來的矩陣範數”。
好了,文縐縐的概念就不多說了,有了向量範數的概念之後,我們就有:

呃,其實也沒做啥,就換了個記號而已,||W||2 等於多少我們還是沒有搞出來。
Frobenius範數
其實譜範數 ||W||2 的準確概念和計算方法還是要用到比較多的線性代數的概念,我們暫時不研究它,而是先研究一個更加簡單的範數:Frobenius 範數,簡稱 F 範數。
這名字讓人看著慌,其實定義特別簡單,它就是:

說白了,它就是直接把矩陣當成一個向量,然後求向量的歐氏模長。
簡單透過柯西不等式,我們就能證明:

很明顯 ||W||F 提供了 ||W||2 的一個上界,也就是說,你可以理解為 ||W||2 是式 (6) 中最準確的 C(所有滿足式 (6) 的 C 中最小的那個),但如果你不大關心精準度,你直接可以取 C=||W||F,也能使得 (6) 成立,畢竟 ||W||F 容易計算。
l2正則項
前面已經說過,為了使神經網路盡可能好地滿足L約束,我們應當希望 C=||W||2 盡可能小,我們可以把 C2 作為一個正則項加入到損失函式中。當然,我們還沒有算出譜範數 ||W||2,但我們算出了一個更大的上界 ||W||F,那就先用著它吧,即 loss 為:
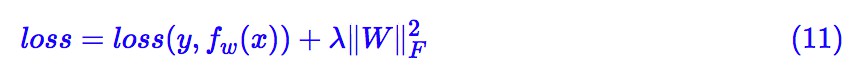
其中第一部分是指模型原來的 loss。我們再來回顧一下 ||W||F 的運算式,我們發現加入的正則項是:

這不就是 l2 正則化嗎?
終於,搗鼓了一番,我們得到了一點回報:我們揭示了 l2 正則化(也稱為 weight decay)與 L 約束的聯絡,表明 l2 正則化能使得模型更好地滿足 L 約束,從而降低模型對輸入擾動的敏感性,增強模型的泛化效能。
譜範數
主特徵根
這部分我們來正式面對譜範數 ||W||2,這是線性代數的內容,比較理論化。
事實上,譜範數 ||W||2 等於 的最大特徵根(主特徵根)的平方根,如果 W是方陣,那麼 ||W||2 等於 W 的最大的特徵根絕對值。
的最大特徵根(主特徵根)的平方根,如果 W是方陣,那麼 ||W||2 等於 W 的最大的特徵根絕對值。
對於感興趣理論證明的讀者,這裡提供一下證明的大概思路。根據定義 (7) 我們有:

假設對角化為diag(λ1,…,λn),即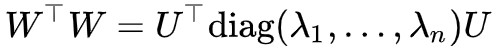 ,其中 λi 都是它的特徵根,而且非負,而 U 是正交矩陣,由於正交矩陣與單位向量的積還是單位向量,那麼:
,其中 λi 都是它的特徵根,而且非負,而 U 是正交矩陣,由於正交矩陣與單位向量的積還是單位向量,那麼:

所以![]() 等於的最大特徵根。
等於的最大特徵根。
冪迭代
也許有讀者開始不耐煩了:鬼願意知道你是不是等於特徵根呀,我關心的是怎麼算這個鬼範數!
事實上,前面的內容雖然看起來茫然,但卻是求 ‖W‖2 的基礎。前一節告訴我們![]() 就是的最大特徵根,所以問題變成了求的最大特徵根,這可以透過“冪迭代”法 [3] 來解決。
就是的最大特徵根,所以問題變成了求的最大特徵根,這可以透過“冪迭代”法 [3] 來解決。
所謂“冪迭代”,就是透過下麵的迭代格式:

迭代若干次後,最後透過:

得到範數(也就是得到最大的特徵根的近似值)。也可以等價改寫為:

這樣,初始化 u,v 後(可以用全 1 向量初始化),就可以迭代若干次得到 u,v,然後代入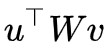 算得 ‖W‖2 的近似值。
算得 ‖W‖2 的近似值。
對證明感興趣的讀者,這裡照樣提供一個簡單的證明表明為什麼這樣的迭代會有效。
記 ,初始化為
,初始化為![]() ,同樣假設 A 可對角化,並且假設 A 的各個特徵根 λ1,…,λn 中,最大的特徵根嚴格大於其餘的特徵根(不滿足這個條件意味著最大的特徵根是重根,討論起來有點複雜,需要請讀者查詢專業證明,這裡僅僅拋磚引玉。
,同樣假設 A 可對角化,並且假設 A 的各個特徵根 λ1,…,λn 中,最大的特徵根嚴格大於其餘的特徵根(不滿足這個條件意味著最大的特徵根是重根,討論起來有點複雜,需要請讀者查詢專業證明,這裡僅僅拋磚引玉。
當然,從數值計算的角度,幾乎沒有兩個人是完全相等的,因此可以認為重根的情況在實驗中不會出現。),那麼 A 的各個特徵向量 η1,…,ηn 構成完備的基底,所以我們可以設:

每次的迭代是 Au/‖Au‖,其中分母只改變模長,我們留到最後再執行,只看 A 的重覆作用:
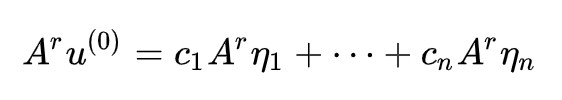
註意對於特徵向量有 Aη=λη,從而:

不失一般性設 λ1 為最大的特徵值,那麼:

根據假設 λ2/λ1,…,λn/λ1 都小於 1,所以 r→∞ 時它們都趨於零,或者說當 r 足夠大時它們可以忽略,那麼就有:
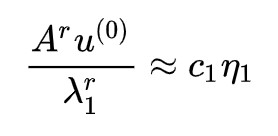
先不管模長,這個結果表明當 r 足夠大時, 提供了最大的特徵根對應的特徵向量的近似方向,其實每一步的歸一化只是為了防止上限溢位而已。這樣一來
提供了最大的特徵根對應的特徵向量的近似方向,其實每一步的歸一化只是為了防止上限溢位而已。這樣一來 就是對應的單位特徵向量,即:
就是對應的單位特徵向量,即:

因此:

這就求出了譜範數的平方。
譜正則化
前面我們已經表明瞭 Frobenius 範數與 l2 正則化的關係,而我們已經說明瞭 Frobenius 範數是一個更強(更粗糙)的條件,更準確的範數應該是譜範數。雖然譜範數沒有 Frobenius 範數那麼容易計算,但依然可以透過式 (15) 迭代幾步來做近似。
所以,我們可以提出“譜正則化(Spectral Norm Regularization)”的概念,即把譜範數的平方作為額外的正則項,取代簡單的 l2 正則項。即式 (11) 變為:

Spectral Norm Regularization for Improving the Generalizability of Deep Learning [1]一文已經做了多個實驗,表明“譜正則化”在多個任務上都能提升模型效能。
在 Keras 中,可以透過下述程式碼計算譜範數:
def spectral_norm(w, r=5):
w_shape = K.int_shape(w)
in_dim = np.prod(w_shape[:-1]).astype(int)
out_dim = w_shape[-1]
w = K.reshape(w, (in_dim, out_dim))
u = K.ones((1, in_dim))
for i in range(r):
v = K.l2_normalize(K.dot(u, w))
u = K.l2_normalize(K.dot(v, K.transpose(w)))
return K.sum(K.dot(K.dot(u, w), K.transpose(v)))生成模型
WGAN
如果說在普通的監督訓練模型中,L 約束只是起到了“錦上添花”的作用,那麼在 WGAN 的判別器中,L 約束就是必不可少的關鍵一步了。因為 WGAN 的判別器的最佳化標的是:

這裡的 Pr,Pg 分別是真實分佈和生成分佈,|f|L=1 指的就是要滿足特定的 L 約束 |f(x1)−f(x2)|≤‖x1−x2‖(那個 C=1)。所以上述標的的意思是,在所有滿足這個L約束的函式中,挑出使得 最大的那個 f,就是最理想的判別器。寫成 loss 的形式就是:
最大的那個 f,就是最理想的判別器。寫成 loss 的形式就是:

梯度懲罰
目前比較有效的一種方案就是梯度懲罰,即 ‖f′(x)‖=1 是 |f|L=1 的一個充分條件,那麼我把這一項加入到判別器的 loss 中作為懲罰項,即:
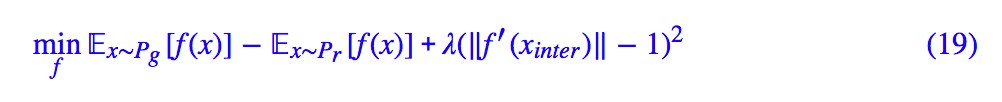
事實上我覺得加個 relu(x)=max(x,0) 會更好:
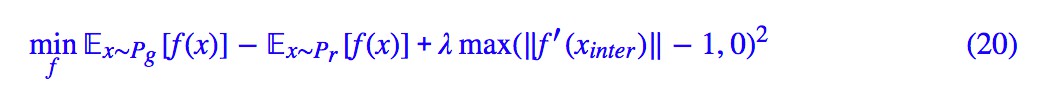
其中![]() 採用隨機插值的方式:
採用隨機插值的方式:
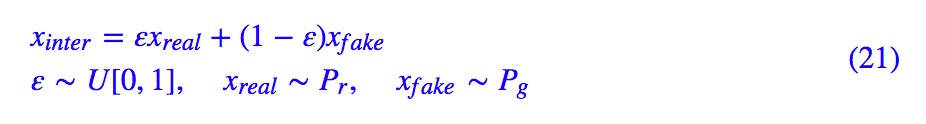
梯度懲罰不能保證 ‖f′(x)‖=1,但是直覺上它會在 1 附近浮動,所以 |f|L 理論上也在 1 附近浮動,從而近似達到 L 約束。
這種方案在很多情況下都已經 work 得比較好了,但是在真實樣本的類別數比較多的時候卻比較差(尤其是條件生成)。
問題就出在隨機插值上:原則上來說,L 約束要在整個空間滿足才行,但是透過線性插值的梯度懲罰只能保證在一小塊空間滿足。如果這一小塊空間剛好差不多就是真實樣本和生成樣本之間的空間,那勉勉強強也就夠用了,但是如果類別數比較多,不同的類別進行插值,往往不知道插到哪裡去了,導致該滿足 L 條件的地方不滿足,因此判別器就失靈了。
思考:梯度懲罰能不能直接用作有監督的模型的正則項呢?有興趣的讀者可以試驗一下。
譜歸一化
梯度懲罰的問題在於它只是一個懲罰,只能在區域性生效。真正妙的方案是構造法:構建特殊的 f,使得不管 f 裡邊的引數是什麼,f 都滿足 L 約束。
事實上,WGAN 首次提出時用的是引數裁剪——將所有引數的絕對值裁剪到不超過某個常數,這樣一來引數的 Frobenius 範數不會超過某個常數,從而 |f|L 不會超過某個常數,雖然沒有準確地實現 |f|L=1,但這隻會讓 loss 放大常數倍,因此不影響最佳化結果。引數裁剪就是一種構造法,這不過這種構造法對最佳化並不友好。
簡單來看,這種裁剪的方案最佳化空間有很大,比如改為將所有引數的 Frobenius 範數裁剪到不超過某個常數,這樣模型的靈活性比直接引數裁剪要好。如果覺得裁剪太粗暴,換成引數懲罰也是可以的,即對所有範數超過 Frobenius 範數的引數施加一個大懲罰,我也試驗過,基本有效,但是收斂速度比較慢。
然而,上面這些方案都只是某種近似,現在我們已經有了譜範數,那麼可以用最精準的方案了:將 f 中所有的引數都替換為 w/‖w‖2。這就是譜歸一化(Spectral Normalization),在 Spectral Normalization for Generative Adversarial Networks [2] 一文中被提出並實驗。
這樣一來,如果 f 所用的啟用函式的導數絕對值都不超過 1,那麼我們就有 |f|L≤1,從而用最精準的方案實現了所需要的 L 約束。
註:“啟用函式的導數絕對值都不超過 1”,這個通常都能滿足,但是如果判別模型使用了殘差結構,則啟用函式相當於是 x+relu(Wx+b),這時候它的導數就不一定不超過 1 了。但不管怎樣,它會不超過一個常數,因此不影響最佳化結果。
我自己嘗試過在 WGAN 中使用譜歸一化(不加梯度懲罰,參考程式碼見後面),發現最終的收斂速度(達到同樣效果所需要的 epoch)比 WGAN-GP 還要快,效果還要更好一些。而且,還有一個影響速度的原因:就是每個 epoch 的執行時間,梯度懲罰會比用譜歸一化要長,因為用了梯度懲罰後,在梯度下降的時候相當於要算二次梯度了,要執行整個前向過程兩次,所以速度比較慢。
Keras實現
在 Keras 中,實現譜歸一化可以說簡單也可以說不簡單。
說簡單,只需要在判別器的每一層摺積層和全連線層都傳入 kernel_constraint 引數,而 BN 層傳入 gamma_constraint 引數。constraint 的寫法是:
def spectral_normalization(w):
return w / spectral_norm(w)
參考程式碼:
https://github.com/bojone/gan/blob/master/keras/wgan_sn_celeba.py
說不簡單,是因為目前的 Keras(2.2.4 版本)中的 kernel_constraint 並沒有真正改變了 kernel,而只是在梯度下降之後對 kernel 的值進行了調整,這跟論文中 spectral_normalization 的方式並不一樣。如果只是這樣使用的話,就會發現後期的梯度不準,模型的生成質量不佳。
為了實現真正地修改 kernel,我們要不就得重新定義所有的層(摺積、全連線、BN 等所有包含矩陣乘法的層),要不就只能修改原始碼了,修改原始碼是最簡單的方案,修改檔案 keras/engine/base_layer.py 的 Layer 物件的 add_weight 方法,本來是(目前是 222 行開始):
def add_weight(self,
name,
shape,
dtype=None,
initializer=None,
regularizer=None,
trainable=True,
constraint=None):
"""Adds a weight variable to the layer.
# Arguments
name: String, the name for the weight variable.
shape: The shape tuple of the weight.
dtype: The dtype of the weight.
initializer: An Initializer instance (callable).
regularizer: An optional Regularizer instance.
trainable: A boolean, whether the weight should
be trained via backprop or not (assuming
that the layer itself is also trainable).
constraint: An optional Constraint instance.
# Returns
The created weight variable.
"""
initializer = initializers.get(initializer)
if dtype is None:
dtype = K.floatx()
weight = K.variable(initializer(shape),
dtype=dtype,
name=name,
constraint=constraint)
if regularizer is not None:
with K.name_scope('weight_regularizer'):
self.add_loss(regularizer(weight))
if trainable:
self._trainable_weights.append(weight)
else:
self._non_trainable_weights.append(weight)
return weight修改為:
def add_weight(self,
name,
shape,
dtype=None,
initializer=None,
regularizer=None,
trainable=True,
constraint=None):
"""Adds a weight variable to the layer.
# Arguments
name: String, the name for the weight variable.
shape: The shape tuple of the weight.
dtype: The dtype of the weight.
initializer: An Initializer instance (callable).
regularizer: An optional Regularizer instance.
trainable: A boolean, whether the weight should
be trained via backprop or not (assuming
that the layer itself is also trainable).
constraint: An optional Constraint instance.
# Returns
The created weight variable.
"""
initializer = initializers.get(initializer)
if dtype is None:
dtype = K.floatx()
weight = K.variable(initializer(shape),
dtype=dtype,
name=name,
constraint=None)
if regularizer is not None:
with K.name_scope('weight_regularizer'):
self.add_loss(regularizer(weight))
if trainable:
self._trainable_weights.append(weight)
else:
self._non_trainable_weights.append(weight)
if constraint is not None:
return constraint(weight)
return weight也就是把 K.variable 的 constraint 改為 None,把 constraint 放到最後執行。註意,不要看到要改原始碼就馬上來吐槽 Keras 封裝太死,不夠靈活什麼的,你要是用其他框架基本上比 Keras 複雜好多倍(相對不加 spectral_normalization 的 GAN 的改動量)。

總結
本文是關於 Lipschitz 約束的一篇總結,主要介紹瞭如何使得模型更好地滿足 Lipschitz 約束,這關係到模型的泛化能力。而難度比較大的概念是譜範數,涉及較多的理論和公式。
整體來看,關於譜範數的相關內容都是比較精巧的,而相關結論也進一步表明線性代數跟機器學習緊密相關,很多“高深”的線性代數內容都可以在機器學習中找到對應的應用。
參考文獻
[1]. Spectral Norm Regularization for Improving the Generalizability of Deep Learning. Yuichi Yoshida, Takeru Miyato. ArXiv 1705.10941.
[2]. Takeru Miyato, Toshiki Kataoka, Masanori Koyama, and Yuichi Yoshida. Spectral normalization for generative adversarial networks. In ICLR, 2018.
[3]. https://en.wikipedia.org/wiki/Power_iteration

點選以下標題檢視作者其他文章:
關於PaperWeekly
PaperWeekly 是一個推薦、解讀、討論、報道人工智慧前沿論文成果的學術平臺。如果你研究或從事 AI 領域,歡迎在公眾號後臺點選「交流群」,小助手將把你帶入 PaperWeekly 的交流群裡。

▽ 點選 | 閱讀原文 | 檢視作者部落格
