作者:雲在青天水在哪
網址:http://www.cnblogs.com/chenlinzhi/p/4648597.html
點選“閱讀原文”可檢視本文網頁版
最近在維護公司專案時,需要載入某頁面,總共載入也就4000多條資料,竟然需要35秒鐘,要是資料增長到40000條,我估計好幾分鐘都搞不定。臥槽,要我是使用者的話估計受不了,趁閑著沒事,就想把它最佳化一下,走你。
先把查詢貼上:
select Pub_AidBasicInformation.AidBasicInfoId,
Pub_AidBasicInformation.UserName,
Pub_AidBasicInformation.District,
Pub_AidBasicInformation.Street,
Pub_AidBasicInformation.Community,
Pub_AidBasicInformation.DisCard,
Pub_Application.CreateOn AS AppCreateOn,
Pub_User.UserName as DepartmentUserName,
Pub_Consult1.ConsultId,
Pub_Consult1.CaseId,
Clinicaltb.Clinical,AidNametb.AidName,
Pub_Application.IsUseTraining,
Pub_Application.ApplicationId,
tab.numFROM Pub_Consult1INNER JOIN Pub_Application ON Pub_Consult1.ApplicationId = Pub_Application.ApplicationIdINNER JOIN Pub_AidBasicInformation ON Pub_Application.AidBasicInfoId = Pub_AidBasicInformation.AidBasicInfoId
INNER JOIN(select ConsultId,dbo.f_GetClinical(ConsultId) as Clinical from Pub_Consult1) Clinicaltb on Clinicaltb.ConsultId=Pub_Consult1.ConsultIdleft join (select distinct ApplicationId, sum(TraniningNumber) as num from dbo.Review_Aid_UseTraining_Record where AidReferralId is null group by ApplicationId) tab on tab.ApplicationId=Pub_Consult1.ApplicationIdINNER JOIN(select ConsultId,dbo.f_GetAidNamebyConsult1(ConsultId) as AidName from Pub_Consult1) AidNametb on AidNametb.ConsultId=Pub_Consult1.ConsultId
LEFT OUTER JOIN Pub_User ON Pub_Application.ReviewUserId = Pub_User.UserId WHERE Pub_Consult1.Directory = 0
order by Pub_Application.CreateOn desc
執行後有圖有真相:

這麼慢,沒辦法就去看看查詢計劃是怎麼樣:
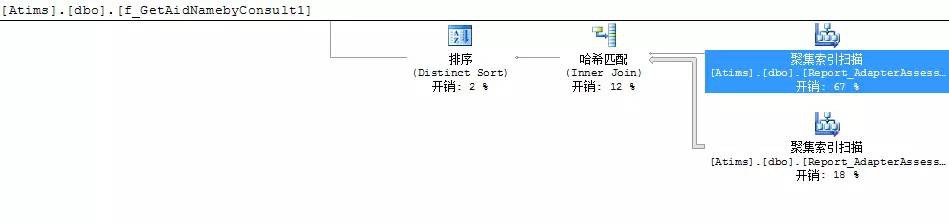


這是該sql查詢裡面執行三個函式時生成查詢計劃的截圖,一看就知道,執行時開銷比較大,而且都是花費在聚集索引掃描上,把滑鼠放到聚集索引掃描的方塊上面,依次看到如下詳細計劃:
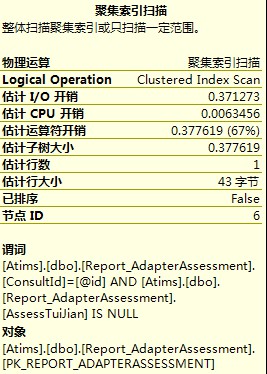
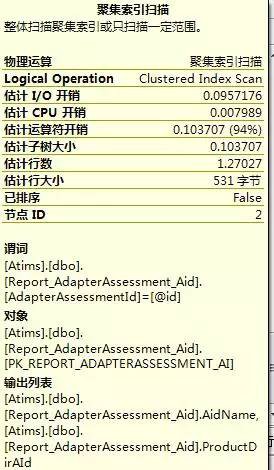
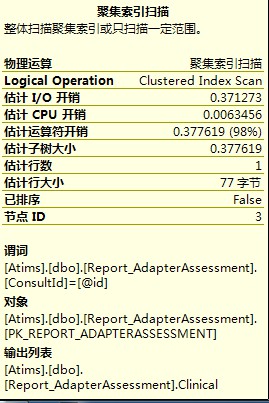
從這幾張圖裡,可以看到查詢I/O開銷,運運算元開銷,估計行數,以及操作的物件和查詢條件,這些都為最佳化查詢提供了有利證據。第1,3張圖IO開銷比較大,第2張圖估計行數比較大,再根據其它資訊,首先想到的應該是去建立索引,不行的話再去改查詢。
先看看資料庫引擎最佳化顧問能給我們提供什麼最佳化資訊,有時候它能夠幫我們提供有效的資訊,比如建立統計,索引,分割槽什麼的。
先開啟SQL Server Profiler 把剛剛執行的查詢另存為跟蹤(.trc)檔案,再開啟資料庫引擎最佳化顧問,做如下圖操作
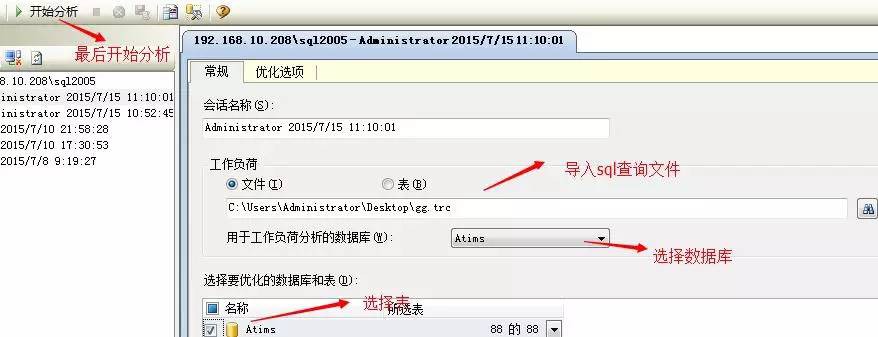
最後生成的建議報告如下:
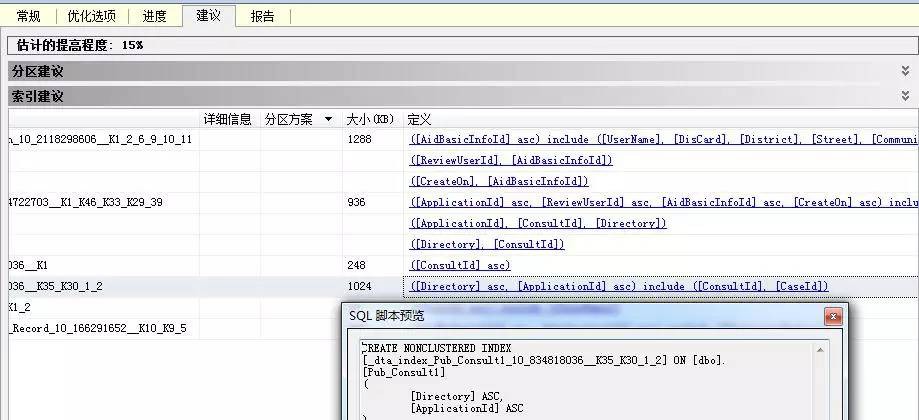
在這裡可以單擊檢視一些建議,分割槽,建立索引,根據提示建立瞭如下索引:
CREATE NONCLUSTERED INDEX index1 ON [dbo].[Pub_AidBasicInformation]( [AidBasicInfoId] ASC)CREATE NONCLUSTERED INDEX index1 ON [dbo].[Pub_Application]( [ApplicationId] ASC,[ReviewUserId] ASC,[AidBasicInfoId] ASC,[CreateOn] ASC)CREATE NONCLUSTERED INDEX index1 ON [dbo].[Pub_Consult1]( [Directory] ASC,[ApplicationId] ASC) CREATE NONCLUSTERED INDEX idnex1 ON [dbo].[Review_Aid_UseTraining_Record]( [AidReferralId] ASC,[ApplicationId] ASC)
索引建立後,再次執行查詢,原以為可提高效率,沒想到我勒個去,還是要30幾秒,幾乎沒什麼改善,最佳化引擎顧問有時候也會失靈,在這裡只是給大家演示有這種解決方案去解決問題,有時候還是靠譜的,只是這次不靠譜。沒辦法,只有開啟函式仔細瞅瞅,再結合上面的查詢計劃詳細圖,刪除先前建立的索引,然後建立瞭如下索引:
CREATE NONCLUSTERED INDEX index1 ON dbo.Report_AdapterAssessment_Aid
(
AdapterAssessmentId ASC, ProductDirAId ASC)CREATE NONCLUSTERED INDEX index1 ON dbo.Report_AdapterAssessment
(
ConsultId ASC)
再次執行查詢

好了,只需3.5秒,差不多提高10倍速度,看來這次是湊效了哈。
再來看看查詢計劃是否有改變,上張圖來說明下問題:
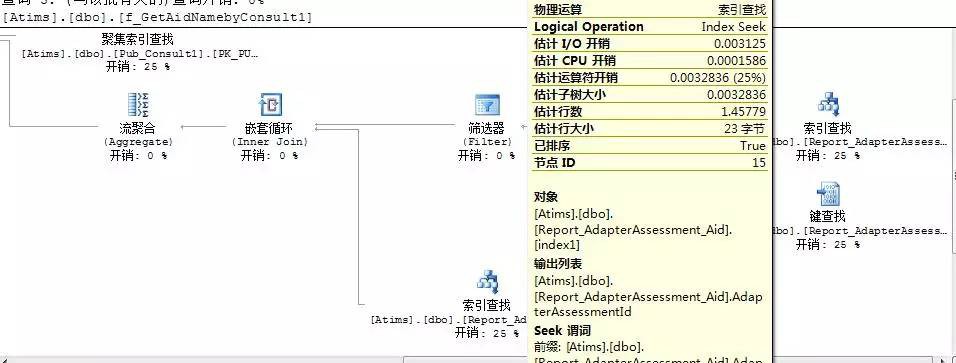
從上圖當中我們可以看到,索引掃描不見了,只有索引查詢,聚集索引查詢,鍵查詢,而且運運算元開銷,I/O開銷都降低了很多。索引掃描(Index Scan),聚集索引掃描(Clustered Index Scan)跟表掃描(Table Scan)差不多,基本上是逐行去掃描表記錄,速度很慢,而索引查詢(Index Seek),聚集索引查詢,鍵查詢都相當的快。最佳化查詢的目的就是儘量把那些帶有XXXX掃描的去掉,換成XXXX查詢。
這樣夠了嗎?但是回頭又想想,4000多條資料得3.5秒鐘,還是有點慢了,應該還能再快點,所以決定再去修改查詢。看看查詢,能最佳化的也只有那個三個函式了。
為了看函式執行效果先刪除索引,看看查詢中函式f_GetAidNamebyConsult1要乾的事情,擷取查詢中與該函式有關的子查詢:
select Pub_Consult1.ConsultId,AidName from (select ConsultId,dbo.f_GetAidNamebyConsult1(ConsultId) as AidNamefrom Pub_Consult1) AidNametb inner join Pub_Consult1on AidNametb.ConsultId=Pub_Consult1.ConsultId
得到下圖的結果:
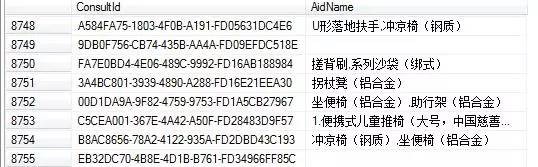
沒想到就這麼點資料竟然要46秒,看來這個函式真的是罪魁禍首。
該函式的具體程式碼就不貼出來了,而且該函式裡面還欠套的另外一個函式,本身函式執行起來就慢,更何況還函式裡子查詢還包含函式。其實根據幾相關聯的表去查詢幾個欄位,並且把一個欄位的值合併到同一行,這樣沒必要用函式或儲存過程,用子查詢再加sql for xml path就行了,把該函式改成如下查詢:
with cte1 as( select A.AdapterAssessmentId,case when B.AidName is null then A .AidName else B.AidName end AidName from Report_AdapterAssessment_Aid as A left join Pub_ProductDir as B on A.ProductDirAId=B.ProductDirAId
),
cte2 as( --根據AdapterAssessmentId分組併合並AidName欄位值
select AdapterAssessmentId,(select AidName+',' from cte1 where AdapterAssessmentId= tb.AdapterAssessmentId for xml path(''))as AidName from cte1 as tb group by AdapterAssessmentId
),
cte3 as( select ConsultId,LEFT(AidName,LEN(AidName)-1) as AidName from
( select Pub_Consult1.ConsultId,cte2.AidName from Pub_Consult1,Report_AdapterAssessment,cte2 where Pub_Consult1.ConsultId=Report_AdapterAssessment.ConsultId and Report_AdapterAssessment.AdapterAssessmentId=cte2.AdapterAssessmentId and Report_AdapterAssessment.AssessTuiJian is null
) as tb)
這樣查詢出來的結果在沒有索引的情況下不到1秒鐘就行了。再把主查詢寫了:
select distinct Pub_AidBasicInformation.AidBasicInfoId,
Pub_AidBasicInformation.UserName,
Pub_AidBasicInformation.District,
Pub_AidBasicInformation.Street,
Pub_AidBasicInformation.Community,
Pub_AidBasicInformation.DisCard,
Pub_Application.CreateOn AS AppCreateOn,
Pub_User.UserName as DepartmentUserName,
Pub_Consult1.ConsultId,
Pub_Consult1.CaseId,
Clinicaltb.Clinical,
cte3.AidName,
Pub_Application.IsUseTraining,
Pub_Application.ApplicationId,
tab.numfrom Pub_Consult1INNER JOIN Pub_Application ON Pub_Consult1.ApplicationId = Pub_Application.ApplicationIdINNER JOIN Pub_AidBasicInformation ON Pub_Application.AidBasicInfoId = Pub_AidBasicInformation.AidBasicInfoId
INNER JOIN(select ConsultId,dbo.f_GetClinical(ConsultId) as Clinical from Pub_Consult1) Clinicaltb on Clinicaltb.ConsultId=Pub_Consult1.ConsultIdleft join (select distinct ApplicationId, sum(TraniningNumber) as num from dbo.Review_Aid_UseTraining_Record where AidReferralId is null
group by ApplicationId) tab on tab.ApplicationId=Pub_Consult1.ApplicationIdleft JOIN cte3 on cte3.ConsultId=Pub_Consult1.ConsultId
LEFT OUTER JOIN Pub_User ON Pub_Application.ReviewUserId = Pub_User.UserId where Pub_Consult1.Directory = 0order by Pub_Application.CreateOn desc
這樣基本上就完事了,在沒有建立索引的情況下需要8秒鐘,比沒索取用函式還是快了27秒。

把索引放進去,就只需1.6秒了,比建立索取用函式而不用子查詢和sql for xml path快了1.9秒

查詢裡面還有個地方用了函式,估計再最佳化下還能提高執行效率,因為時間有限再加上篇幅有點長了,在這裡就不多講了。
最後做個總結吧,查詢最佳化不外乎以下這幾種辦法:
1:增加索引或重建索引。通常在外來鍵,連線欄位,排序欄位,過濾查詢的欄位建立索引,也可透過資料庫引擎最佳化顧問提供的資訊去建索引。有時候當你建立索引時,會發現查詢還是按照索引掃描或聚集索引掃描的方式去執行,而沒有去索引查詢,這時很可能是你的查詢欄位和where條件欄位沒有全部包含在索引欄位當中,解決這個問題的辦法就是多建立索引,或者在建立索引時Include相應的欄位,讓索引欄位改寫你的查詢欄位和where條件欄位。
2:調整查詢陳述句,前提要先看懂別人的查詢,搞清楚業務邏輯。
3:表分割槽,大資料量可以考慮。
4:提高伺服器硬體配置。