
https://opensource.com/article/18/9/how-use-scikit-learn-data-science-projects
作者 | Dr.michael J.garbade
譯者 | Liang Chen (Flowsnow) ???共計翻譯:23.0 篇 貢獻時間:1049 天
靈活多樣的 Python 庫為資料分析和資料挖掘提供了強力的機器學習工具。
Scikit-learn Python 庫最初於 2007 年釋出,通常用於解決各種方面的機器學習和資料科學問題。這個多種功能的庫提供了整潔、一致、高效的 API 和全面的線上檔案。
什麼是 Scikit-learn?
Scikit-learn[1] 是一個開源 Python 庫,擁有強大的資料分析和資料挖掘工具。 在 BSD 許可下可用,並建立在以下機器學習庫上:
NumPy,一個用於操作多維陣列和矩陣的庫。它還具有廣泛的數學函式彙集,可用於執行各種計算。SciPy,一個由各種庫組成的生態系統,用於完成技術計算任務。Matplotlib,一個用於繪製各種圖表和圖形的庫。Scikit-learn 提供了廣泛的內建演演算法,可以充分用於資料科學專案。
以下是使用 Scikit-learn 庫的主要方法。
1、分類
分類[2]工具識別與提供的資料相關聯的類別。例如,它們可用於將電子郵件分類為垃圾郵件或非垃圾郵件。
Scikit-learn 中的分類演演算法包括:
2、回歸
回歸涉及到建立一個模型去試圖理解輸入和輸出資料之間的關係。例如,回歸工具可用於理解股票價格的行為。
回歸演演算法包括:
3、聚類
Scikit-learn 聚類工具用於自動將具有相同特徵的資料分組。 例如,可以根據客戶資料的地點對客戶資料進行細分。
聚類演演算法包括:
4、降維
降維降低了用於分析的隨機變數的數量。例如,為了提高視覺化效率,可能不會考慮外圍資料。
降維演演算法包括:
5、模型選擇
模型選擇演演算法提供了用於比較、驗證和選擇要在資料科學專案中使用的最佳引數和模型的工具。
透過引數調整能夠增強精度的模型選擇模組包括:
6、預處理
Scikit-learn 預處理工具在資料分析期間的特徵提取和規範化中非常重要。 例如,您可以使用這些工具轉換輸入資料(如文字)併在分析中應用其特徵。
預處理模組包括:
Scikit-learn 庫示例
讓我們用一個簡單的例子來說明如何在資料科學專案中使用 Scikit-learn 庫。
我們將使用鳶尾花花卉資料集[3],該資料集包含在 Scikit-learn 庫中。 鳶尾花資料集包含有關三種花種的 150 個細節,三種花種分別為:
資料集包括每種花種的以下特徵(以釐米為單位):
第 1 步:匯入庫
由於鳶尾花花卉資料集包含在 Scikit-learn 資料科學庫中,我們可以將其載入到我們的工作區中,如下所示:
from sklearn import datasets
iris = datasets.load_iris()
這些命令從 sklearn 匯入資料集 datasets 模組,然後使用 datasets 中的 load_iris() 方法將資料包含在工作空間中。
第 2 步:獲取資料集特徵
資料集 datasets 模組包含幾種方法,使您更容易熟悉處理資料。
在 Scikit-learn 中,資料集指的是類似字典的物件,其中包含有關資料的所有詳細資訊。 使用 .data 鍵儲存資料,該資料列是一個陣列串列。
例如,我們可以利用 iris.data 輸出有關鳶尾花花卉資料集的資訊。
print(iris.data)
這是輸出(結果已被截斷):
[[5.1 3.5 1.4 0.2]
[4.9 3. 1.4 0.2]
[4.7 3.2 1.3 0.2]
[4.6 3.1 1.5 0.2]
[5. 3.6 1.4 0.2]
[5.4 3.9 1.7 0.4]
[4.6 3.4 1.4 0.3]
[5. 3.4 1.5 0.2]
[4.4 2.9 1.4 0.2]
[4.9 3.1 1.5 0.1]
[5.4 3.7 1.5 0.2]
[4.8 3.4 1.6 0.2]
[4.8 3. 1.4 0.1]
[4.3 3. 1.1 0.1]
[5.8 4. 1.2 0.2]
[5.7 4.4 1.5 0.4]
[5.4 3.9 1.3 0.4]
[5.1 3.5 1.4 0.3]
我們還使用 iris.target 向我們提供有關花朵不同標簽的資訊。
print(iris.target)
這是輸出:
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2]
如果我們使用 iris.target_names,我們將輸出資料集中找到的標簽名稱的陣列。
print(iris.target_names)
以下是執行 Python 程式碼後的結果:
['setosa' 'versicolor' 'virginica']
第 3 步:視覺化資料集
我們可以使用箱形圖[4]來生成鳶尾花資料集的視覺描繪。 箱形圖說明瞭資料如何透過四分位數在平面上分佈的。
以下是如何實現這一標的:
import seaborn as sns
box_data = iris.data # 表示資料陣列的變數
box_target = iris.target # 表示標簽陣列的變數
sns.boxplot(data = box_data,width=0.5,fliersize=5)
sns.set(rc={'figure.figsize':(2,15)})
讓我們看看結果:
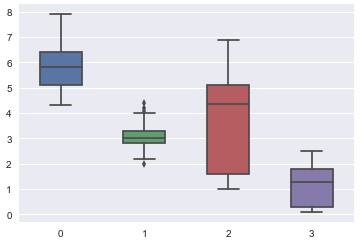
在橫軸上:
垂直軸的尺寸以釐米為單位。
總結
以下是這個簡單的 Scikit-learn 資料科學教程的完整程式碼。
from sklearn import datasets
iris = datasets.load_iris()
print(iris.data)
print(iris.target)
print(iris.target_names)
import seaborn as sns
box_data = iris.data # 表示資料陣列的變數
box_target = iris.target # 表示標簽陣列的變數
sns.boxplot(data = box_data,width=0.5,fliersize=5)
sns.set(rc={'figure.figsize':(2,15)})
Scikit-learn 是一個多功能的 Python 庫,可用於高效完成資料科學專案。
如果您想瞭解更多資訊,請檢視 LiveEdu[5] 上的教程,例如 Andrey Bulezyuk 關於使用 Scikit-learn 庫建立機器學習應用程式[6]的影片。
有什麼評價或者疑問嗎? 歡迎在下麵分享。
via: https://opensource.com/article/18/9/how-use-scikit-learn-data-science-projects
作者:Dr.Michael J.Garbade[8] 選題:lujun9972 譯者:Flowsnow 校對:wxy
本文由 LCTT 原創編譯,Linux中國 榮譽推出