
在我們日常的機器學習、深度學習實踐過程中,具有強大處理能力的計算機在模型訓練的過程中可以學到大量的知識,但研究者自身也會犯很多的錯誤,需要修複很多的bug。
本文,我們將整理在訓練神經網路實戰過程中用到的很多有用的tips(主要基於Tensorflow平臺)。一些建議可能對你非常用有用,有些可能沒有太大的啟發意義。一些建議可能對於你不太實用,限於個人都統一整理,大家根據個人經驗、場景選擇。
常見的一些tips
1、使用Adam作為最佳化器。Adam最佳化效果非常好。與傳統的最佳化器(optimizer),如傳統的梯度下降法,它應該是首選。Tensorflow實踐筆記:當儲存和回覆模型引數時,設定AdamOptimizer之後,一定記得設定Saver,因為Adam有些state也需要恢復(即每個weight的學習率)。
2、採用ReLu作為非線性啟用函式。Relu訓練速度非常快,簡單,而且訓練效果非常好,不存在梯度消失的問題。儘管sigmoid是最常見的啟用函式,但其存在梯度消失的問題,隨著梯度反傳深度的加深,梯度傳遞效率大大降低。
3、在網路的輸出層不要使用啟用函式。這很明顯,但如果你預設在每一層都設定啟用函式就很容易犯這個錯誤,所以一定記得在輸出層取消掉啟用函式。
4、在每一層都新增偏置項(bias)。因為偏置項很重要,可以把一個平面轉換成一個best-fitting position。比如,y=mx+b,b就是偏置項,它使得一條直線上線移動,以便找到最優的position。
5、使用variance-scaled 初始化。在Tensorflow中,就是這個介面:tf.contrib.layers.variance_scaling_initializer()。在我們的經驗中,這種generalizes/scales比其他常用的初始化方法要好,如Gaussian,truncated normal和Xavier。一般來說,方差調整初始化方法基於每一層輸入和輸出的神經元(Tensorflow中預設輸入神經元數目)的數目來調整隨機初始化的權重的偏差。因此,在沒有額外的“hacks”,如clipping或batch normalization,幫助下,可以幫助signals傳遞到更深的網路中。Xavier也比較類似,除非所有的層都有相似的偏差,但網路不同的層具有非常不同的形狀(shapes)(在CNN中很常見),所有的層具有相同的偏差不能處理這樣的場景。
6、Whiten(規範化,normalize)輸入資料。訓練時,減去輸入資料的均值,然後除以輸入資料的方差。模型的權重延伸和拓展的角度越小,網路學習更容易且速度越快。保持輸入資料是零均值的(mean-centered)且具有恆大的方差,可以幫助實現這一點。對於所有的測試資料也需要執行這一點,所以一定要確保你的訓練資料與真實資料高度相似。
7、在保留輸入資料dynamic range的情況下,對輸入資料進行尺度變換。這個操作與normalization相關,但應先於normalization執行。舉個例子,資料X實際的變化範圍是[0, 140000000],這可以被啟用函式tanh(x)或tanh(x/c)所馴服(c是一個常量,延展曲線,在輸入資料的變化範圍匹配(fit)輸入的動態特性,即tanh函式傾斜(啟用)部分)。特別是你的輸入資料根本沒有一個上下限變化範圍時,神經網路可以在(0,1)範圍內,學得更好。
8、不要影響learning rate的衰減。學習速率的衰減在SGD中很常見,而且ADAM中也會自然調整它。如果你想直接一點點的調整學習速率,比如,在訓練一段時間後,減小學習速率,誤差曲線可能會突然drop一點點,隨後很快恢復平整。
9、如果你使用的摺積層使用64或128的摺積核,這已經足夠了。特別是對於深度網路,確實,128已經很大了。如果你已經有了一個更大的摺積核了,增加更多的摺積核,並不會帶來效果的提升。
10、Pooling(池化)以保持轉移不變性。Pooling主要是讓網路對於圖片輸入的“該部分”具有一個“普適的作用”。比如說,最大池化(Max pooling)可以幫助CNN對於發生旋轉、偏置和特徵尺度變換的輸入影象,也能夠具有的魯棒性。
神經網路診斷tips
如果網路不學習(意思是:loss/accuracy在訓練過程中不收斂,或者沒有得到你預期的結果),嘗試下麵的tips:
1、過擬合。如果你的模型不學習,首先應該想到模型是否陷入了過擬合情況。在一個很小的資料集上訓練模型,準確率達到了100%或99.99%,或者error接近於0。如果你的神經網路不能實現過擬合,說明你的網路結構存在一些嚴重的問題,但也可能不是很明顯。如果你的模型在小資料上過擬合,但在大資料集上任然不收斂,試一試下麵的suggestion。
2、減小學習速率。模型的學習速度會變慢,但模型可以到達一個更小的區域性極小值,這個點因為之前的步長過大而跳不進來。
3、增大學習速率。這可以加速模型的訓練,儘快收斂,幫助模型跳出區域性極小值。儘管神經網路很快就收斂了,但是其結果並不是最好的,其“收斂”得到的結果可能會及其穩定,即不同訓練,得到結果差別很大。(使用Adam,我們發現0.001是一個很好的初始值)。
4、減小(mini)batch size。減小batch size至1可以得到模型引數調整最細粒度的變化,你可以在Tensorboard(或其他debugging/視覺化工具)中觀察到,確定梯度更新是否存在問題。
5、去除batch normalization。當你把batch size減小至1時,起初BN可以幫助你發現模型是否存在梯度爆炸或梯度消失的問題。曾經,我們有一個神經網路不收斂,僅當我們去除BN之後我們才發現模型的輸入在第二個iteration是變成了NaN。BN是一種錦上添花的措施,它只有在你確定你的模型不存在其他問題時才能正常發揮其強大的功能。
6、增大(mini-)batch size。增加batch size是必須的,越大的batch size可以減小梯度更新的方差,使得每一輪的梯度更新更加準確。換句話說,梯度更新會沿著準確的方向移動。但是!我們不可能無限制的增加batch size,因為計算機的物理記憶體是有限的。經驗證明,這一點沒有之前提出的兩個suggestion重要,即減小batch size和去除BN。
7、檢查你的reshape操作。頻繁的進行reshape操作(比如,改變影象X和Y的維度)可能會破環空間的區域性特性(spatially local features),使得神經網路幾乎不能準確學習,因為它們必須學習錯誤的reshape。(自然的features變得破碎不堪,因為CNN的摺積操作高度依賴這些自然情況下的區域性空間特徵)同時對多個圖片/channels進行reshape操作時必須非常的小心,使用numpy.stack()進行正確的對齊。
8、監視你loss函式的變化。如果使用的時一個複雜的函式作為標的函式,儘量使用L1或L2約束去去簡化它。我們發現,L1對於邊界沒有那麼敏感,當模型遇到噪聲訓練資料時,模型引數調整沒有那麼劇烈。
9、盡可能的進行模型訓練視覺化。如果你有視覺化的工具,如matplotlib、OpenCV、Tensorboard等等,儘量視覺化網路中值得scale、clipping等得變化,並保證不同引數著色策略得一致性。
給出一些實際得例子
為了幫助你理解上面所講得tips,我們這裡給出我們構建了CNN網路,得到的一些loss得圖(透過TensorBoard給出)來輔助說明。
首先,模型根本沒有學習情況:
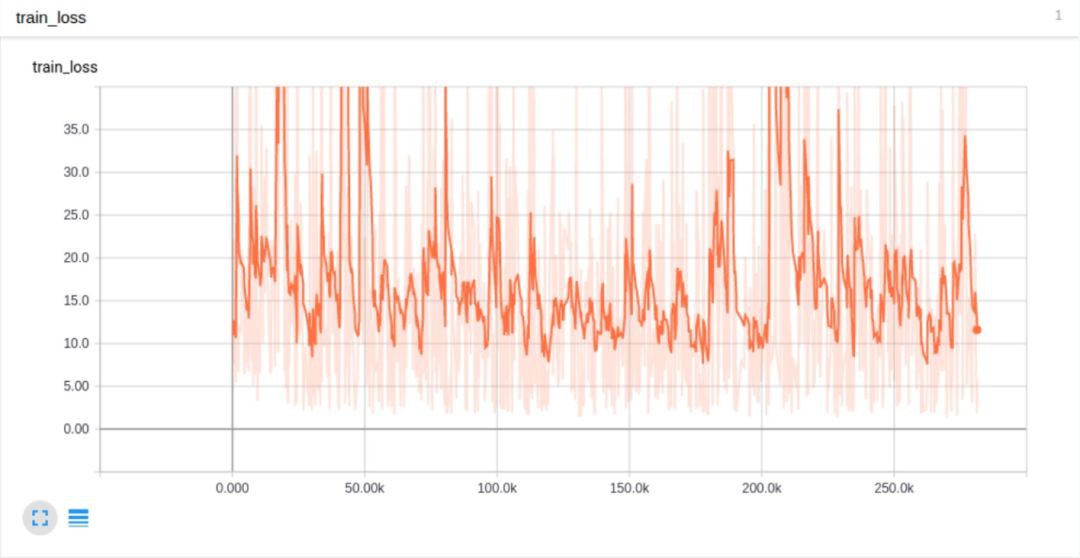
我們嘗試著對value進行clipping(裁剪)操作,保證它們不會超過一個固定得bounds,得到以下結果:
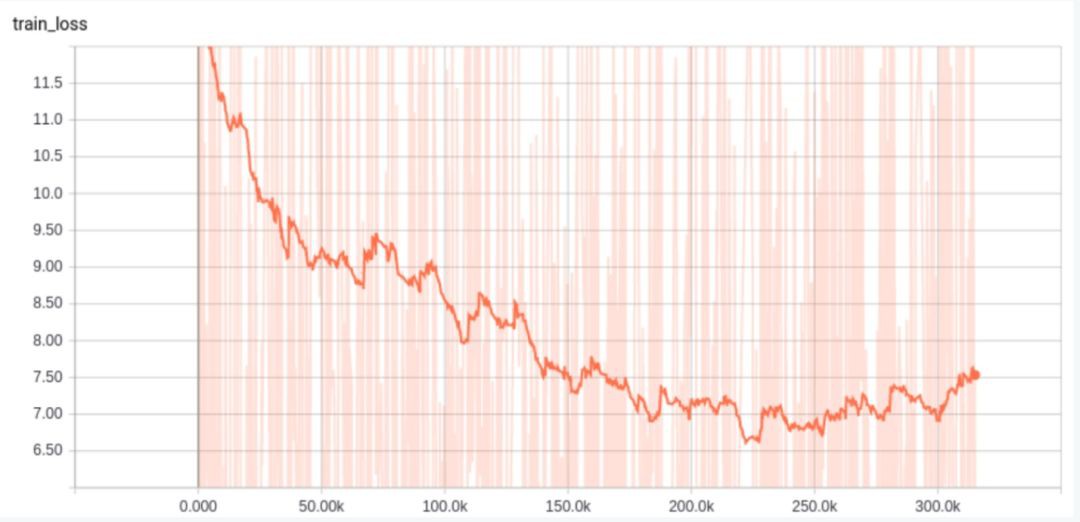
然而,loss曲線仍然不夠平滑。學習速率是否任然過大呢?我們又嘗試對學習速率進行衰減操作,同時採用一個訓練樣本進行訓練:
可以發現,大約在第300和3000 steps時,學習速率的變化情況。很明顯,學習速率下降太快了。所以,需要讓學習速率每一次衰減的時間間隔變得更長,這樣得到的結果更好:

可以發現,在step 2000和5000的時候,進行decay,這樣得到的結果更好,但也並不非常理想,loss並沒有下降至0。
下麵,我們去除掉LR衰減策略,把輸入經過一個tanh函式處理,把輸入資料最大最小值壓縮到一個更小的範圍。儘管很明顯,這個操作對於小於1的值會帶來一些誤差,但我們人道沒能實現達到過擬合的標的。

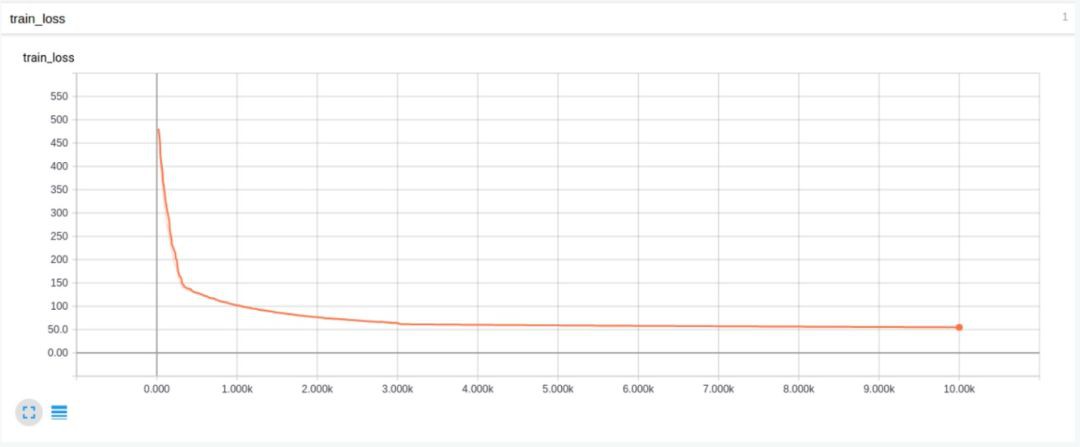
透過實踐我們發現,去掉BN之後,在1或2個iteration之後,網路的輸出就變成了NaN。我們去除了BN,同時對引數初始化策略新增方差幅度進行約束(variance scaling)。這一操作使得結果發生了巨大變化。對於幾個輸入訓練樣本,模型終於過擬合了。儘管誤差值超過了5,但是最終的誤差降低了4個數量級。


上面這張圖得loss曲線非常平滑,可以發現它在測試資料上過擬合了,在訓練資料上得loss曲線只是降到了0.01。這是因為沒有對學習速率進行衰減操作,所以loss降不下去了。隨後我們把學習速率降低了一個數量級,得到了更好得結果:
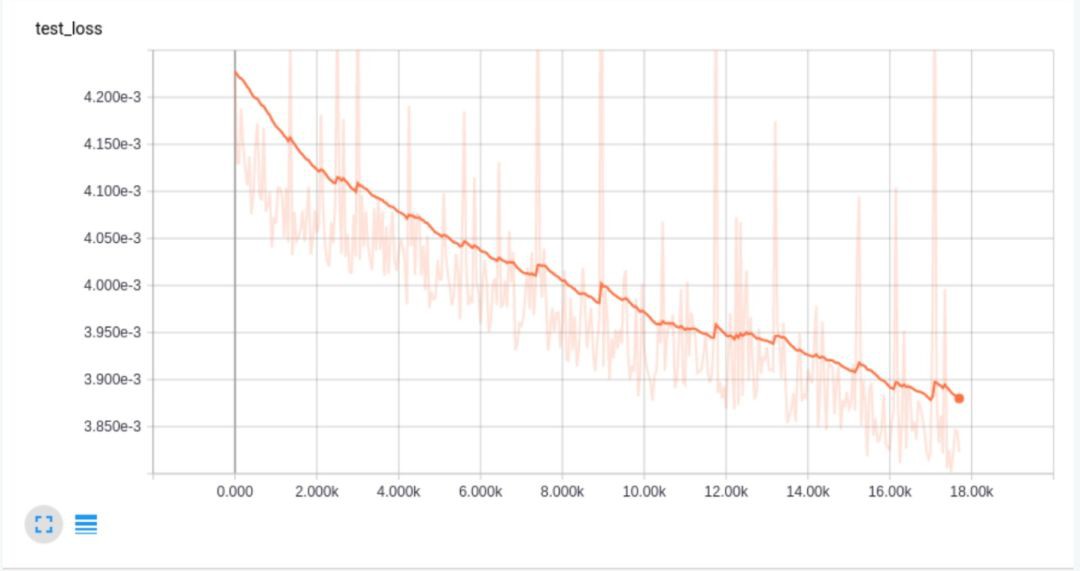
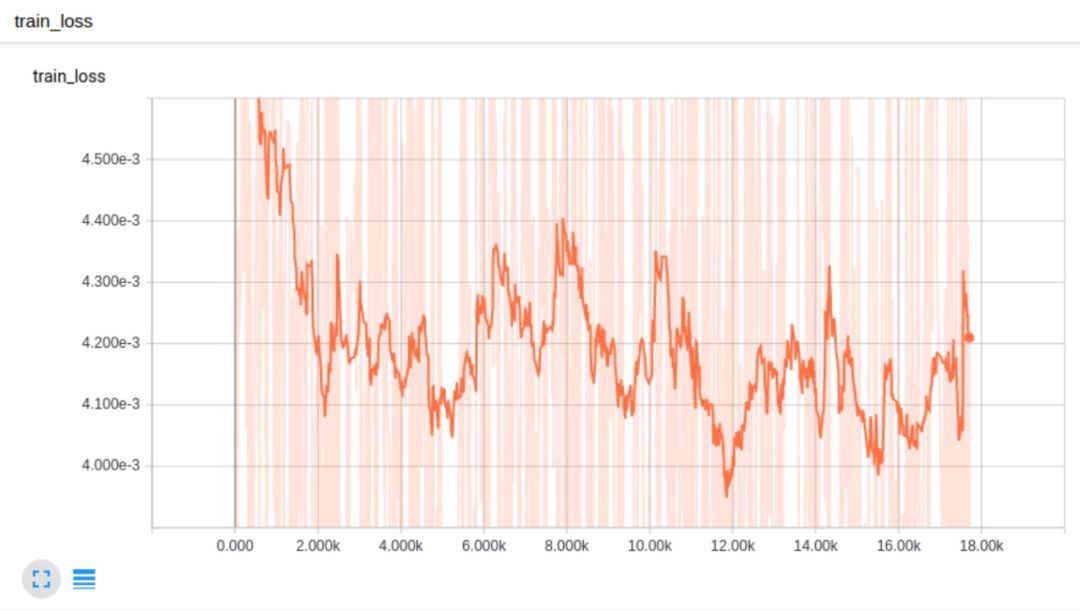
可以發現,上面得結果更好了!但倘若只是衰減學習速率,而不把訓練分為兩個部分呢?
透過給學習率每一個step都乘以一個衰減繫數0.9995,得到的結果並不是很好:
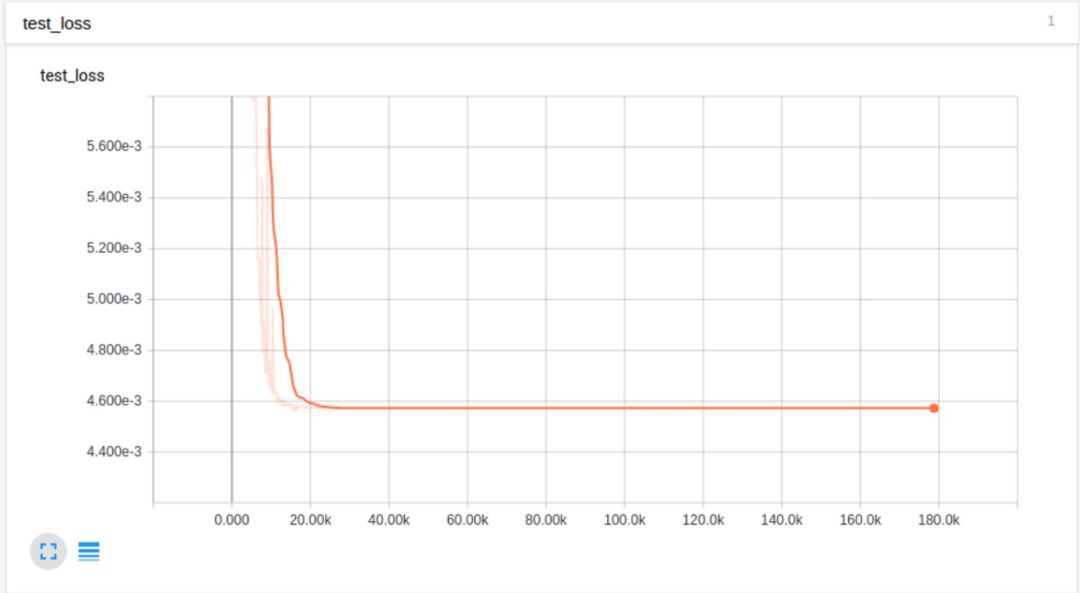

出現這種情況,可能是因為衰減過快了。因此我們把衰減繫數變成0.999995,結果則更好一點,但最終的結果也基本類似,loss並沒有繼續減小。透過這一些列的實驗,我們推測可能是因為BN掩蓋了由於poor引數初始化導致的梯度爆炸問題。而且,對於Adam最佳化器來說,衰減學習速率並不能帶來很大的幫助,除非是在訓練快結束時進行deliberate的衰減。當使用BN時,對權值等value進行裁減只會掩蓋真正的問題。我們同樣可以使用tanh來處理具有high-variance的輸入資料。
我們希望上面tips可以對你有所幫助,助你掌握構建深度神經網路的一些基本方法。很多時候,僅僅一些簡單的操作就能導致巨大的差別。
往期精彩內容
AI實戰聖經《Machine Learning Yearning》第1-52章中英文版pdf分享
2018/2019/校招/春招/秋招/自然語言處理/深度學習/機器學習知識要點及面試筆記
合成註意力推理神經網路-Christopher Manning-ICLR2018
基於深度學習的文字分類6大演演算法-原理、結構、論文、原始碼打包分享



DeepLearning_NLP


深度學習與NLP
商務合作請聯絡微訊號:lqfarmerlq