作者:loveis715
網址:http://www.cnblogs.com/loveis715/p/4681643.html
點選“閱讀原文”可檢視本文網頁版
在Web服務開發中,服務端快取是服務實現中所常常採用的一種提高服務效能的方法。其透過記錄某部分計算結果來嘗試避免再次執行得到該結果所需要的複雜計算,從而提高了服務的執行效率。
除了能夠提高服務的執行效率之外,服務端快取還常常用來提高服務的擴充套件性。因此一些大規模的Web應用,如Facebook,常常構建一個龐大的服務端快取。而它們所最常使用的就是Memcached。
在本文中,我們就將對Memcached進行簡單地介紹。
Memcached簡介
在介紹Memcached之前,讓我們首先透過一個示例瞭解什麼是服務端快取。
相信大家都玩過一些網路聯機遊戲吧。在我那個年代(03年左右),這些遊戲常常添加了對戰功能,並提供了天梯來顯示具有最優秀戰績的玩家以及當前玩家在天梯系統中的排名。這是遊戲開發商所常常採用的一種聚攏玩家人氣的手段。而希望在遊戲中證明自己的玩家則會由此激發鬥志,進而花費更多時間來在天梯中取得更好的成績。
就天梯系統來說,其最主要的功能就是為玩家提供天梯排名的資訊,而並不允許玩家對該系統中所記錄的資料作任何修改。這樣設定的結果就是,整個天梯系統的讀操作居多,而寫操作很少。反過來,由於一個遊戲中的玩家可能有上千萬甚至上億人,而且線上人數常常達到上萬人,因此對天梯的訪問也會是非常頻繁的。這樣的話,即使每秒鐘只有10個人訪問天梯中的排名,對這上億個玩家的天梯排名進行讀取及排序也是一件非常消耗效能的事情。
一個自然而然的想法就是:在對天梯排名進行一次計算後,我們在服務端將該天梯排名快取起來,併在其它玩家訪問的時候直接傳回該快取中所記錄的結果。而在一定時間段之後,如一個小時,我們再對快取中的資料進行更新。這樣我們就不再需要每個小時執行成千上萬次的天梯排名計算了。
而這就是服務端快取所提供的最重要功能。其既可以提高單個請求的響應速度,又可以降低服務層及資料庫層的壓力。除此之外,多個服務實體都可以讀取該服務端快取所快取的資訊,因此我們也不再需要擔心這些資料在各個服務實體中都儲存了一份進而需要彼此同步的問題,也即是提高了擴充套件性。
而Memcached就是一個使用了BSD許可的服務端快取實現。但是與其它服務端快取實現不同的是,其主要由兩部分組成:獨立執行的Memcached服務實體,以及用於訪問這些服務實體的客戶端。因此相較於普通服務端快取實現中各個快取都執行在服務實體之上的情況,Memcached服務實體則是在服務實體之外獨立執行的:
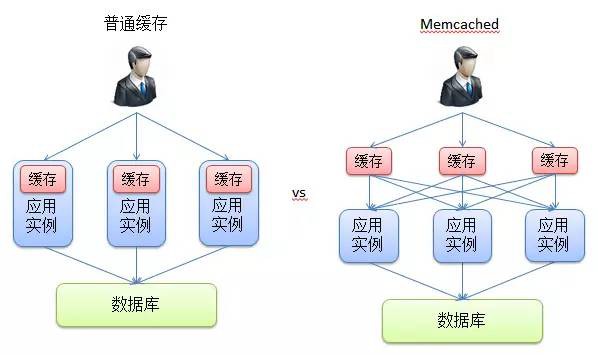
從上圖中可以看出,由於Memcached快取實體是獨立於各個應用伺服器實體執行的,因此應用服務實體可以訪問任意的快取實體。而傳統的快取則與特定的應用實體系結,因此每個應用實體將只能訪問特定的快取。這種系結一方面會導致整個應用所能夠訪問的快取容量變得很小,另一方面也可能導致不同的快取實體中存在著冗餘的資料,從而降低了快取系統的整體效率。
在執行時,Memcached服務實體只需要消耗非常少的CPU資源,卻需要使用大量的記憶體。因此在決定如何組織您的服務端快取結構之前,您首先需要搞清當前服務中各個服務實體的負載情況。如果一個伺服器的CPU使用率非常高,卻存在著非常多的空餘記憶體,那麼我們就完全可以在其上執行一個Memcached實體。而如果當前服務中的所有服務實體都沒有過多的空餘記憶體,那麼我們就需要使用一系列獨立的服務實體來搭建服務端快取。一個大型服務常常擁有上百個Memcached實體。而在這上百個Memcached實體中所儲存的資料則不盡相同。由於這種資料的異構性,我們需要在訪問由Memcached所記錄的資訊之前決定在該服務端快取系統中到底由哪個Memcached實體記錄了我們所想要訪問的資料:
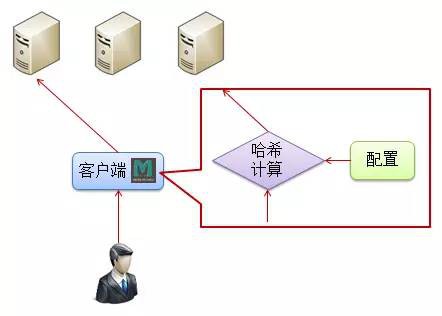
如上圖所示,使用者需要透過一個Memcached客戶端來完成對快取服務所記錄資訊的訪問。該客戶端知道服務端快取系統中所包含的所有Memcached服務實體。在需要訪問具有特定鍵值的資料時,該客戶端內部會根據所需要讀取的資料的鍵值,如“foo”,以及當前Memcached快取服務的配置來計算相應的雜湊值,以決定到底是哪個Memcached實體記錄了使用者所需要訪問的資訊。在決定記錄了所需要資訊的Memcached實體之後,Memcached客戶端將從配置中讀取該Memcached服務實體所在地址,並向該Memcached實體傳送資料訪問請求,以從該Memcached實體中讀取具有鍵值“foo”的資訊。在各個論壇的討論中,這被稱為是Memcached的兩階段雜湊(Two-stage hash)。
而對資料的記錄也使用了類似的流程:假設使用者希望透過服務端快取記錄資料“bar”,併為其指定鍵值“foo”。那麼Memcached客戶端將首先對使用者所賦予的鍵值“foo”及當前服務端快取所記錄的可用服務實體個數執行雜湊計算,並根據雜湊計算結果來決定儲存該資料的Memcached服務實體。接下來,客戶端就會向該實體傳送請求,以在其中記錄具有鍵值“foo”的資料“bar”。
這樣做的好處則在於,每個Memcached服務實體都是獨立的,而彼此之間並沒有任何互動。在這種情況下,我們可以省略很多複雜的功能邏輯,如各個節點之間的資料同步以及結點之間訊息的廣播等等。這種輕量級的架構可以簡化很多操作。如在一個節點失效的時候,我們僅僅需要使用一個新的Memcached節點替代老節點即可。而在對快取進行擴容的時候,我們也只需要新增額外的服務並修改客戶端配置。
這些記錄在服務端快取中的資料是全域性可見的。也就是說,一旦在Memcached服務端快取中成功添加了一條新的記錄,那麼其它使用該快取服務的應用實體將同樣可以訪問該記錄:
在Memcached中,每條記錄都由四部分組成:記錄的鍵,有效期,一系列可選的標記以及表示記錄內容的資料。由於記錄內容的資料中並不包含任何資料結構,因此我們在Memcached中所記錄的資料需要是經過序列化之後的表示。
記憶體管理
在使用快取時,我們不得不考慮的一個問題就是如何對這些快取資料的生存期進行管理。這其中包括如何使一個記錄在快取中的資料過期,如何在快取空間不夠時執行資料的替換等。因此在本節中,我們將對Memcached的記憶體管理機制進行介紹。
首先我們來看一看Memcached的記憶體管理模型。通常情況下,一個記憶體管理演演算法所最需要考慮的問題就是記憶體的碎片化(Fragmentation):在長時間地分配及回收之後,被系統所使用的記憶體將趨向於散落在不連續的空間中。這使得系統很難找到連續記憶體空間,一方面增大了記憶體分配失敗的機率,另一方面也使得記憶體分配工作變得更為複雜,降低了執行效率。
為瞭解決這個問題,Memcached使用了一種叫Slab的結構。在該分配演演算法中,記憶體將按照1MB的大小劃分為頁,而該頁記憶體則會繼續被分割為一系列具有相同大小的記憶體塊:
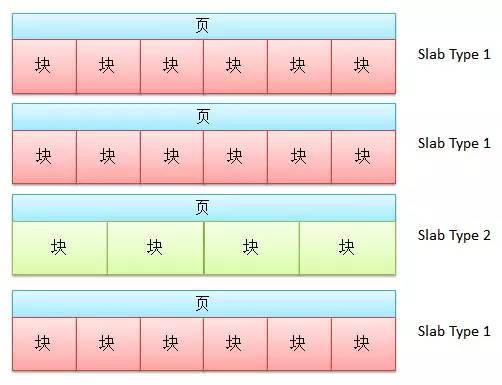
因此Memcached並不是直接根據需要記錄的資料的大小來直接分配相應大小的記憶體。在一條新的記錄到來時,Memcached會首先檢查該記錄的大小,並根據記錄的大小選擇記錄所需要儲存到的Slab型別。接下來,Memcached就會檢查其內部所包含的該型別Slab。如果這些Slab中有空餘的塊,那麼Memcached就會使用該塊記錄該條資訊。如果已經沒有Slab擁有空閑的具有合適大小的塊,那麼Memcached就會建立一個新的頁,並將該頁按照標的Slab的型別進行劃分。
一個需要考慮的特殊情況就是對記錄的更新。在對一個記錄進行更新的時候,記錄的大小可能會發生變化。在這種情況下,其所對應的Slab型別也可能會發生變化。因此在更新時,記錄在記憶體中的位置可能會發生變化。只不過從使用者的角度來說,這並不可見。
Memcached使用這種方式來分配記憶體的好處則在於,其可以降低由於記錄的多次讀寫而導致的碎片化。反過來,由於Memcached是根據記錄的大小選擇需要插入到的塊型別,因此為每個記錄所分配的塊的大小常常大於該記錄所實際需要的記憶體大小,進而造成了記憶體的浪費。當然,您可以透過Memcached的配置檔案來指定各個塊的大小,從而盡可能地減少記憶體的浪費。
但是需要註意的是,由於預設情況下Memcached中每頁的大小為1MB,因此其單個塊最大為1MB。除此之外,Memcached還限制每個資料所對應的鍵的長度不能超過250個位元組。
一般來說,Slab中各個塊的大小以及塊大小的遞增倍數可能會對記錄所載位置的選擇及記憶體利用率有很大的影響。例如在當前的實現下,各個Slab中塊的大小預設情況下是按照1.25倍的方式來遞增的。也就是說,在一個Memcached實體中,某種型別Slab所提供的塊的大小是80K,而提供稍大一點空間的Slab型別所提供的塊的大小就將是100K。如果現在我們需要插入一條81K的記錄,那麼Memcached就會選擇具有100K塊大小的Slab,並嘗試找到一個具有空閑塊的Slab以存入該記錄。
同時您也需要註意到,我們使用的是100K塊大小的Slab來記錄具有81K大小的資料,因此記錄該資料所導致的記憶體浪費是19K,即19%的浪費。而在需要儲存的各條記錄的大小平均分佈的情況下,這種記憶體浪費的幅度也在9%左右。該幅度實際上取決於我們剛剛提到的各個Slab中塊大小的遞增倍數。在Memcached的初始實現中,各個Slab塊的遞增倍數在預設情況下是2,而不是現在的1.25,從而導致了平均25%左右的記憶體浪費。而在今後的各個版本中,該遞增倍數可能還會發生變化,以最佳化Memcached的實際效能。
如果您一旦知道了您所需要快取的資料的特徵,如通常情況下資料的大小以及各個資料的差異幅度,那麼您就可以根據這些資料的特徵來設定上面所提到的各個引數。如果資料在通常情況下都比較小,那麼我們就需要將最小塊的大小調整得小一些。如果資料的大小變動不是很大,那麼我們可以將塊大小的遞增倍數設定得小一些,從而使得各個塊的大小儘量地貼近需要儲存的資料,以提高記憶體的利用率。
還有一個值得註意的事情就是,由於Memcached在計算到底哪個服務實體記錄了具有特定鍵的資料時並不會考慮用來組成快取系統中各個伺服器的差異性。如果每個伺服器上只安裝了一個Memcached實體,那麼各個Memcached實體所擁有的可用記憶體將存在著數倍的差異。但是由於各個實體被選中的機率基本相同,因此具有較大記憶體的Memcached實體將無法被充分利用。我們可以透過在具有較大記憶體的伺服器上部署多個Memcached實體來解決這個問題:
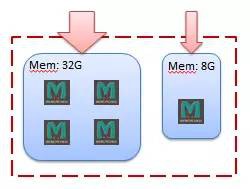
例如上圖所展示的快取系統是由兩個伺服器組成。這兩個伺服器中的記憶體大小並不相同。第一個伺服器的記憶體大小為32G,而第二個伺服器的記憶體大小僅僅有8G。為了能夠充分利用這兩個伺服器的記憶體,我們在具有32G記憶體的伺服器上部署了4個Memcached實體,而在只有8G記憶體的伺服器上部署了1個Memcached實體。在這種情況下,32G記憶體伺服器上的4個Memcached實體將總共得到4倍於8G伺服器所得到的負載,從而充分地利用了32G記憶體伺服器上的記憶體。
當然,由於快取系統擁有有限的資源,因此其會在某一時刻被服務所產生的資料填滿。如果此時快取系統再次接收到一個快取資料的請求,那麼它就會根據LRU(Least recently used)演演算法以及資料的過期時間來決定需要從快取系統中移除的資料。而Memcached所使用的過期演演算法比較特殊,又被稱為延遲過期(Lazy expiration):當使用者從Memcached實體中讀取資料的時候,其將首先透過配置中所設定的過期時間來決定該資料是否過期。如果是,那麼在下一次寫入資料卻沒有足夠空間的時候,Memcached會選擇該過期資料所在的記憶體塊作為新資料的標的地址。如果在寫入時沒有相應的記錄被標記為過期,那麼LRU演演算法才被執行,從而找到最久沒有被使用的需要被替換的資料。
這裡的LRU是在Slab範圍內的,而不是全域性的。假設Memcached快取系統中的最常用的資料都儲存在100K的塊中,而該系統中還存在著另外一種型別的Slab,其塊大小是300K,但是存在於其中的資料並不常用。當需要插入一條99K的資料而Memcached已經沒有足夠的記憶體再次分配一個Slab實體的時候,其並不會釋放具有300K塊大小的Slab,而是在100K塊大小的各個Slab中找到需要釋放的塊,並將新資料新增到該塊中。
高可用性
在企業級應用中,我們常常強調一個系統需要擁有高可用性和高可靠性。而對於一個組成而言,其需要能夠穩定地執行,併在出現異常的時候儘量使得異常的影響限制在某個特定的範圍內,而不會導致整個系統不能正常工作。而且在出現異常之後,該組成需要能較為容易地恢復到正常的工作狀態。
那麼Memcached需要什麼樣的高可用性呢?在講解這個問題之前,我們先來看看在一個大型服務中Memcached所組成的服務端快取是什麼樣的:
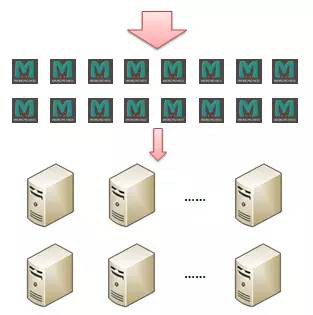
從上圖中可以看到,在一個大型服務中,由Memcached所組成的服務端快取實際上是由非常多的Memcached實體組成的。在前面我們已經介紹過,Memcached實體實際上是完全獨立的,不存在Memcached實體之間的相互互動。因此在其中一個發生了故障的時候,其它的各個Memcached服務實體並不會受到影響。如果一個擁有了16個Memcached實體的服務端快取系統中的一個Memcached實體發生了故障,那麼整個系統將還有93.75%的快取容量可以繼續工作。雖然快取容量的減少會略微增加其後的各個服務實體的壓力,但是一個應用所經歷的負載波動常常比這個大得多,因此該服務應該還是能夠正常工作的。
而這也恰恰表明瞭Memcached所具有的獨立性的正確性。由於Memcached本身致力於建立一個高效而且簡單,卻具有較強擴充套件性的快取元件,因此其並沒有強調資料的安全性。一旦其中的一個Memcached實體發生了故障,那麼我們還可以從資料庫及服務端再次計算得到該資料,並將其記錄在其它可用的Memcached實體上。
我想您讀到這裡一定會想:“不,還有一個問題,那就是由於Memcached實體的個數變化會導致雜湊計算的結果發生變化,從而導致所有對資料的請求會導向到不正確的Memcached實體,使得由Memcached實體叢集所提供的快取服務全部失效,從而導致資料庫的壓力驟增。”
是的,這也是我曾經有所顧慮的地方。而且這不僅僅在服務端快取失效的時候存在。只要服務端快取中Memcached實體的數量發生了變化,那麼該問題就會發生。
Memcached所使用的解決方法就是Consistent Hashing。在該演演算法的幫助下,Memcached實體數量的變化將只可能導致其中的一小部分鍵的雜湊值發生改變。那該演演算法到底是怎麼執行的呢?
首先請考慮一個圓,在該圓上分佈了多個點,以表示整數0到1023。這些整數平均分佈在整個圓上:
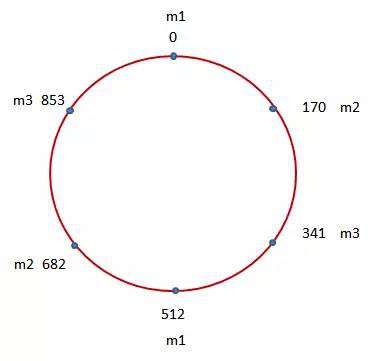
而在上圖中,我們則突出地顯示了6個藍點。這六個藍點基本上將該圓進行了六等分。而它們所對應的就是在當前Memcached快取系統中所包含的三個Memcached實體m1,m2以及m3。好,接下來我們則對當前需要儲存的資料執行雜湊計算,並找到該雜湊結果900在該圓上所對應的點:
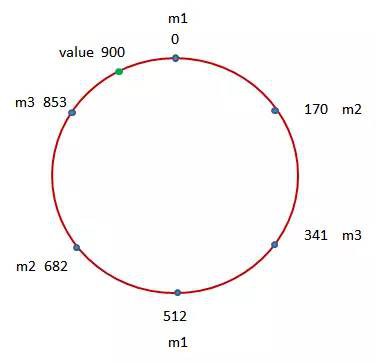
可以看到,該點在順時針距離上離表示0的那個藍點最近,因此這個具有雜湊值900的資料將記錄在Memcached實體m1中。
如果其中的一個Memcached實體失效了,那麼需要由該實體所記錄的資料將暫時失效,而其它實體所記錄的資料仍然還在:
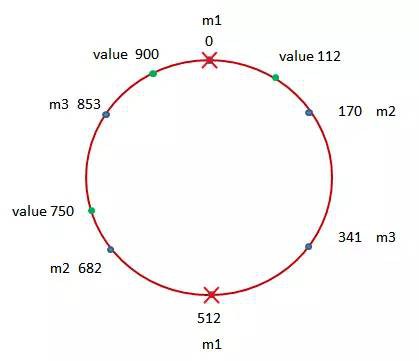
從上圖中可以看到,在Memcached實體m1失效的情況下,值為900的資料將失效,而其它的值為112和750的資料將仍然記錄在Memcached實體m2及m3上。也就是說,一個節點的失效現在將只會導致一部分資料不再在快取系統中存在,而並沒有導致其它實體上所記錄的資料的標的實體發生變化。
但是我們還不得不考慮另一個問題,那就是在一個服務的服務端快取僅僅由一個或幾個Memcached實體組成的情況。在這種情況下,其中一個Memcached實體失效是較為致命的,因為資料庫以及伺服器實體將接收到大量的需要進行複雜計算的請求,並將最終導致伺服器實體和資料庫過載。因此在設計服務端快取時,我們常常採取超出需求容量的方法來定義這些快取。例如在服務實際需要5個Memcached結點時我們設計一個包含6個節點的服務端快取系統,以增加整個系統的容錯能力。
使用Memcached搭建快取系統
OK,在對Memcached內部執行原理介紹完畢之後,我們就來看看如何使用Memcached為您的服務搭建快取系統。
首先,您需要從Memcached官方網站上下載Memcached的安裝檔案,併在您作為快取伺服器的系統上進行安裝。在安裝時,您需要對Memcached進行適當地配置,如其所需要偵聽的埠,為其所分配的記憶體大小等。在Memcached正確配置並啟動之後,我們就可以透過一系列客戶端軟體訪問這些Memcached實體並對其進行操作了。由於我並不是一個運維人員,因此在這裡我們將不再對這些配置進行詳細地介紹。
而我們要介紹的,則是如何用Memcached的Java客戶端去讀寫資料。 而一個較為常見的Memcached客戶端則是SpyMemcached。就讓我們來看一看Spy Memcached的Main函式中是如何對其所提供的功能進行使用的: