前言
上一篇我們介紹瞭如何檢視查詢計劃,本篇將介紹在我們檢視的查詢計劃時的分析技巧,以及幾種我們常用的運運算元最佳化技巧,同樣側重基礎知識的掌握。
透過本篇可以瞭解我們平常所寫的T-SQL陳述句,在SQL Server資料庫系統中是如何分解執行的,資料結果如何透過各個運運算元組織形成的。
技術準備
基於SQL Server2008R2版本,利用微軟的一個更簡潔的案例庫(Northwind)進行解析。
一、資料連線
資料連線是我們在寫T-SQL陳述句的時候最常用的,透過兩個表之間關聯獲取想要的資料。
SQL Server預設支援三種物理連線運運算元:巢狀迴圈連線、合併連線以及雜湊連線。三種連線各有用途,各有特點,不同的場景會資料庫會為我們選擇最優的連線方式。
a、巢狀迴圈連線(nested loops join)
巢狀迴圈連線是最簡單也是最基礎的連線方式。兩張表透過關鍵字進行關聯,然後透過雙層迴圈依次進行兩張表的行進行關聯,然後透過關鍵字進行篩選。
可以參照下圖進行理解分析
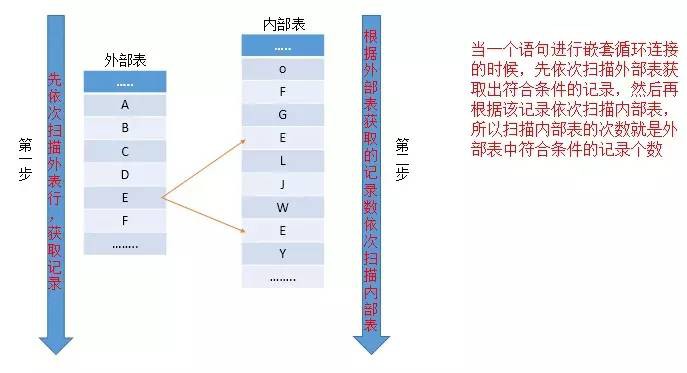
其實巢狀掃描是很簡單的獲取資料的方式,簡單點就是兩層迴圈過濾出結果值。
我們可以透過如下程式碼加深理解
for each row R1 in the outer table
for each row R2 int the inner table
if R1 join with R2return (R1,R2)
舉個列子
SELECT o.OrderID
FROM Customers C JOIN Orders O
ON C.CustomerID=O.CustomerIDWHERE C.City=N’London’
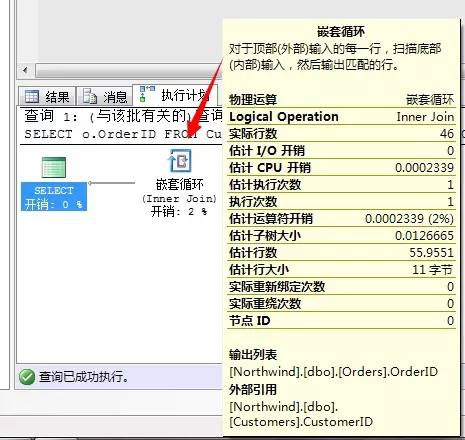
以上這個圖示就是巢狀迴圈連線的圖示了。而且解釋的很明確。

這種方法的消耗就是外表和內表的乘積,其實就是我們所稱呼的笛卡爾積。所以消耗的大小是隨著兩張表的資料量增大而增加的,尤其是內部表,因為它是多次重覆掃描的,所以我們在實踐中的採取的措施就是減少每個外表或者內表的行數來減少消耗。
對於這種演演算法還有一種提高效能的方式,因為兩張表是透過關鍵字進行關聯的,所以在查詢的時候對於底層的資料獲取速度直接關乎著此演演算法的效能,這裡最佳化的方式儘量使用兩個表關鍵字為索引查詢,提高查詢速度。
還有一點就是在巢狀迴圈連線中,在兩張表關聯的時候,對外表都是有篩選條件的,比如上面例子中【WHERE C.City=N’London’】就是對外表(Customers)的篩選,並且這裡的City列在該表中存在索引,所以該陳述句的兩個子查詢都為索引查詢(Index Seek)。
但是,有些情況我們的查詢條件不是索引所改寫的,這時候,在巢狀迴圈連線下的子運運算元就變成了索引掃描(Index scan)或者RID查詢。
舉個例子
SELECT E1.EmployeeID,COUNT(*)
FROM Employees E1 JOIN Employees E2
ON E1.HireDateGROUP BY E1.EmployeeID
以上程式碼是從職工表中獲取出每位職工入職前的人員數。我們看一下該查詢的執行計劃
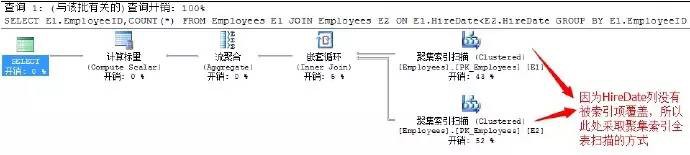
這裡很顯然兩個表的關聯透過的是HireDate列進行,而此列又不為索引項所改寫,所以兩張表的獲取只能透過全表的聚集索引掃描進行,如果這兩張表資料量特別大的話,無疑又是一個非常耗效能的查詢。

透過文字可以看出,該T-SQL的查詢結果的獲取是透過在巢狀迴圈運運算元中,對兩個表經過全表掃描之後形成的笛卡兒積進行過濾篩選的。這種方式其實不是一個最優的方式,因為我們獲取的結果其實是可以先透過兩個表過濾之後,再透過巢狀迴圈運運算元獲取結果,這樣的話效能會好很多。
我們嘗試改一下這個陳述句
SELECT E1.EmployeeID,ECNT.CNT
FROM Employees E1 CROSS APPLY
(
SELECT COUNT(*) CNT
FROM Employees E2
WHERE E1.HireDate)ECNT
透過上述程式碼查詢的結果項,和上面的是一樣的,只是我們根據外部表的結果對內部表進行了過濾,這樣執行的時候就不需要獲取全部資料項了。
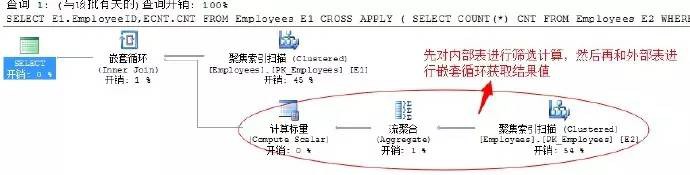
我們檢視下文字執行計劃

我們比較一下,前後兩條陳述句的執行消耗,對比一下執行效率
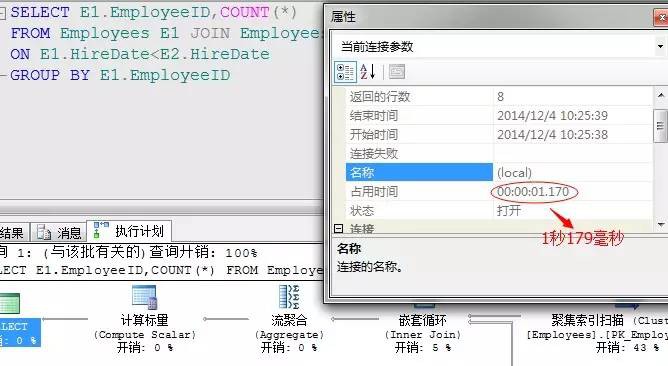
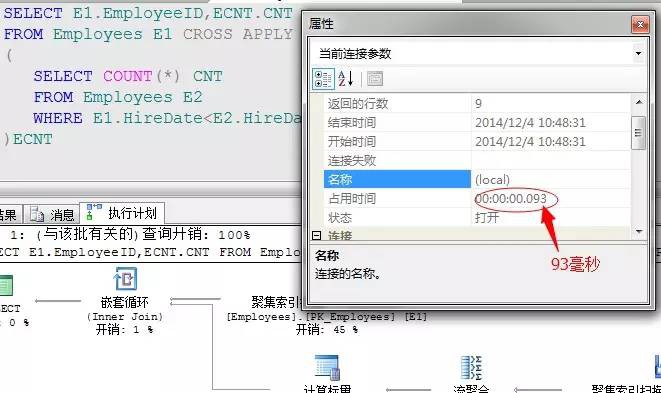
執行時間從1秒179毫秒減少至93毫秒。效果明顯。
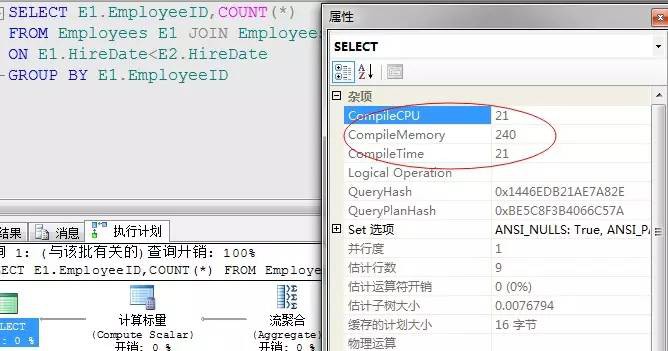
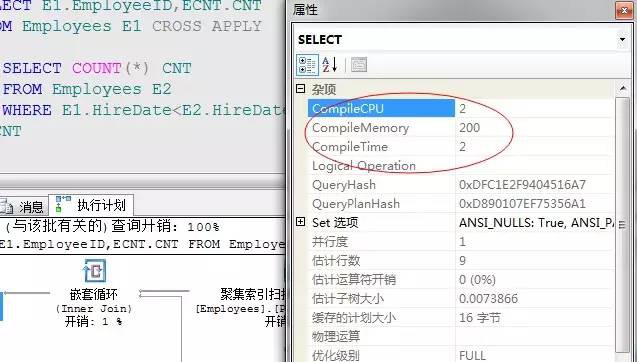
對比CPU消耗、記憶體、編譯時間等總體消耗都有所降低,參考上圖。
所以對巢狀迴圈連線連線的最佳化方式就是集中在這幾點:對兩張表資料量的減少、連線關鍵字上建立索引、謂詞查詢條件上改寫索引最好能減少符合謂詞條件的記錄數。
b、合併連線(merge join)
上面提到的巢狀迴圈連線方式存在著諸多的問題,尤其不適合兩張表都是大表的情況下,因為它會產生N多次的全表掃描,很顯然這種方式會嚴重的消耗資源。
鑒於上述原因,在資料庫裡又提供了另外一種連線方式:合併連線。記住這裡沒有說SQL Server所提供的,是因為此連線演演算法是市面所有的RDBMS所共同使用的一種連線演演算法。
合併連線是依次讀取兩張表的一行進行對比。如果兩個行是相同的,則輸出一個連線後的行並繼續下一行的讀取。如果行是不相同的,則捨棄兩個輸入中較少的那個並繼續讀取,一直到兩個表中某一個表的行掃描結束,則執行完畢,所以該演演算法執行只會產生每張表一次掃描,並且不需要整張表掃描完就可以停止。
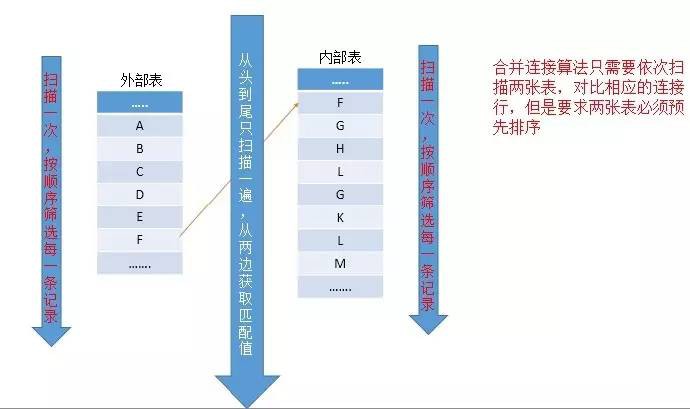
該演演算法要求按照兩張表進行依次掃描對比,但是有兩個前提條件:1、必須預先將兩張表的對應列進行排序;2、對兩張表進行合併連線的條件必須存在等值連線。
我們可以透過以下程式碼進行理解
get first row R1 from input1
get first row R2 from input2
while not at the end of either input
begin
if R1 joins with R2
begin
output(R1,R2)
get next row R2 from input2
end
else if R1get next row R1 from input1
else
get next row R2 from input2end
合併連線運運算元總的消耗是和輸入表中的行數成正比的,而且對錶最多讀取一次,這個和巢狀迴圈連線不一樣。因此,合併連線對於大表的連線操作是一個比較好的選擇項。
對於合併連線可以從如下幾點提高效能:
1.兩張表間的連線值內容列型別,如果兩張表中的關聯列都為唯一列,也就說都不存在重覆值,這種關聯效能是最好的,或者有一張表存在唯一列也可以,這種方式關聯為一對多關聯方式,這種方式也是我們最常用的,比我們經常使用的主從表關聯查詢;如果兩張表中的關聯列存在重覆值,這樣在兩表進行關聯的時候還需要藉助第三張表來暫存重覆的值,這第三張表叫做”worktable “是存放在Tempdb或者記憶體中,而這樣效能就會有所影響。所以鑒於此,我們常做的最佳化方式有:關聯連儘量採用聚集索引(唯一性)
2.我們知道採用該種演演算法的前提是,兩張表都經過排序,所以我們在應用的時候,最好優先使用排序後的表關聯。如果沒有排序,也要選擇的關聯項為索引改寫項,因為大表的排序是一個很耗資源的過程,我們選擇索引改寫列進行排序效能要遠遠好於普通列的排序。
我們來舉個例子
SELECT O.CustomerID,C.CustomerID,C.ContactName
FROM Orders O JOIN Customers C
ON O.CustomerID=C.CustomerID
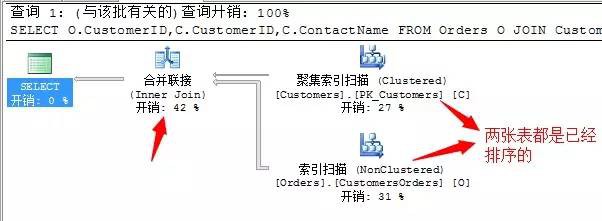
我們知道這段T-SQL陳述句中關聯項用的是CustomerID,而此列為主鍵聚集索引,都是唯一的並且經過排序的,所以這裡面沒有顯示的排序操作。
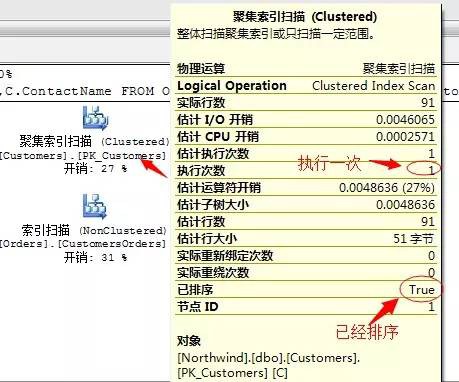
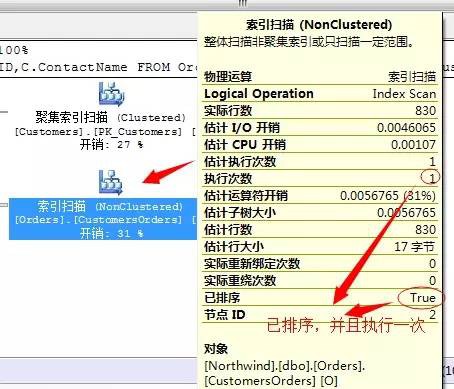
而且凡是採用合併連線的所有輸出結果項,都是已經經過排序的。
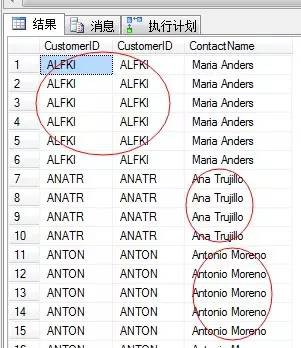
我們找一個稍複雜的情況,沒有提前排序的利用合併查詢的T-SQL
SELECT O.OrderID,C.CustomerID,C.ContactName
FROM Orders O JOIN Customers C
ON O.CustomerID=C.CustomerID AND O.ShipCity<>C.CityORDER BY C.CustomerID
上述程式碼傳回那些客戶的發貨訂單不在客戶本地的。
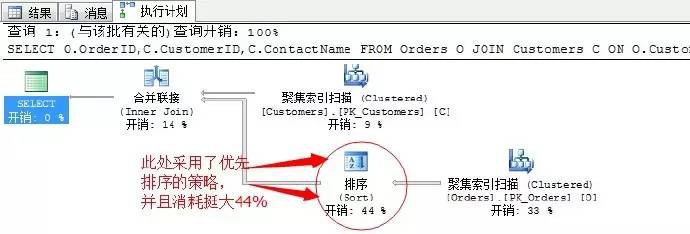
上面的查詢計劃可以看出,排序的消耗總是巨大的,其實我們上面的陳述句按照邏輯應該是在合併連線獲取資料後,才採用顯示的按照CustomerID進行排序。
但是因為合併連線運運算元之前本身就需要排序,所以此處SQL Server採取了優先排序的策略,把排序操作提前到了合併連線之前進行,並且在合併連線之後,就不需要在做額外的排序了。
這其實這裡我們要求對查詢結果排序,正好也利用了合併連線的特點。
c、雜湊連線(hash join)
我們分析了上面的兩種連線演演算法,兩種演演算法各有特點,也各有自己的應用場景:巢狀迴圈連線適合於相對小的資料集連線,合併連線則應對與中型的資料集,但是又有它自己的缺點,比如要求必須有等值連線,並且需要預先排序等。
那對於大型的資料集合的連線資料庫是怎麼應對的呢?那就是雜湊連線演演算法的應用場景了。
雜湊連線對於大型資料集合的並行操作上都比其它方式要好很多,尤其適用於OLAP資料倉庫的應用場景中。
雜湊連線很多地方和合併連線類似,比如都需要至少一個等值連線,同樣支援所有的外連線操作。但不同於合併連線的是,雜湊連線不需要預先對輸入資料集合排序,我們知道對於大表的排序操作是一個很大的消耗,所以去除排序操作,雜湊操作效能無疑會提升很多。
雜湊連線在執行的時候分為兩個階段:
構建階段
在構建階段,雜湊連線從一個表中讀入所有的行,將等值連線鍵的行機型雜湊話處理,然後建立形成一個記憶體雜湊表,而將原來列中行資料依次放入不同的雜湊桶中。
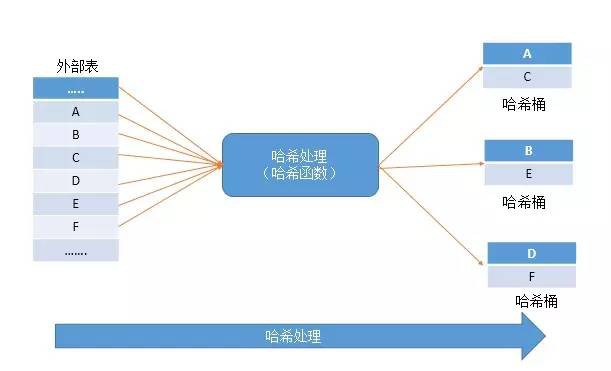
探索階段
在第一個階段完成之後,開始進入第二個階段探索階段,該階段雜湊連線從第二個資料表中讀入所有的行,同樣也是在相同的等值連線鍵上進行雜湊。雜湊過程桶上一階段,然後再從雜湊表中探索匹配的行。
上述的過程中,在第一個階段的構建階段是阻塞的,也就是說在,雜湊連線必須讀入和處理所有的構建輸入,之後才能傳回行。而且這一過程是需要一塊記憶體儲存提供支援,並且利用的是雜湊函式,所以相應的也會消耗CPU等。
並且上述流程過程中一般採用的是併發處理,充分利用資源,當然系統會對雜湊的數量有所限制,如果資料量超大,也會發生記憶體上限溢位等問題,而對於這些問題的解決,SQL Server有它自身的處理方式。
我們可透過以下程式碼進行理解
–構建階段
for each row R1 in the build table
begin
calculate hash value on R1 join key(s)
insert R1 into the appropriate hash bucket
end
–探索階段
for each row R2 in the probe table
begin
calculate hash value on R2 join key(s)
for each row R1 in the corresponding hash bucket
if R1 joins with R2
output(R1,R2)end
在雜湊連線執行之前,SQL Server會估算需要多少記憶體來構建雜湊表。基本估算的方式就是透過表的統計資訊來估算,所以有時候統計資訊不準確,會直接影響其運算效能。
SQL Server預設會儘力預留足夠的記憶體來保證雜湊連線成功的構建,但是有時候記憶體不足的情況下,就必須採取將一小部分的雜湊表分配到硬碟中,這裡就存入到了tempdb庫中,而這一過程會反覆多次迴圈執行。
舉個列子來看看
SELECT O.OrderID,O.OrderDate,C.CustomerID,C.ContactName
FROM Orders O JOIN Customers C
ON O.CustomerID=C.CustomerID
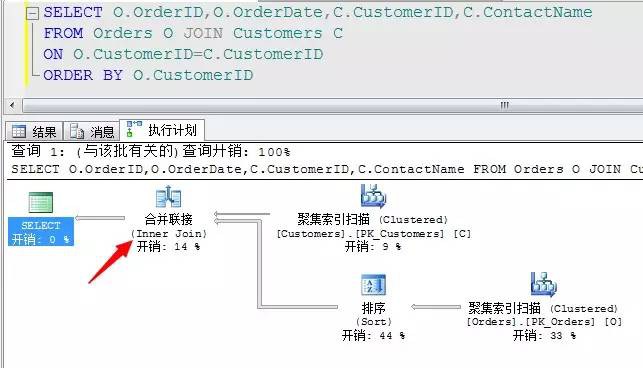
我們來分析上面的執行陳述句,上面的執行結果透過CustomerID列進行關聯,理論將最合適的應該是採用合併連線操作,但是合併連線需要排序,但是我們在陳述句中沒有指定Order by 選項,所以經過評估,此陳述句採用了雜湊連線的方式進行了連線。
我們給它加上一個顯示的排序,它就選用合併連線作為最優的連線方式
我們來總結一下這個演演算法的特點
- 和合併連線一樣演演算法複雜度基本就是分別遍歷兩邊的資料集各一遍
- 它不需要對資料集事先排序,也不要求上面有什麼索引,透過的是雜湊演演算法進行處理
- 基本採取並行的執行計劃的方式
但是,該演演算法也有它自身的缺點,因為其利用的是雜湊函式,所以執行時對CPU消耗高,同樣對記憶體也比較大,但是它可以採用並行處理的方式,所以該演演算法用於超大資料表的連線查詢上顯示出自己獨有的優勢。
關於雜湊演演算法在雜湊處理過程的時候對記憶體的佔用和分配方式,是有它自己獨有雜湊方法,比如:左深度樹、右深度樹、濃密雜湊連線樹等,這裡不做詳細介紹了,只需要知道其使用方式就可以了。
Hash Join並不是一種最優的連線演演算法,只是它對輸入不最佳化,因為輸入資料集特別大,並且對連線符上有沒有索引也沒要求。其實這也是一種不得已的選擇,但是該演演算法又有它適應的場景,尤其在OLAP的資料倉庫中,在一個系統資源相對充足的環境下,該演演算法就得到了它發揮的場景。
當然前面所介紹的兩種演演算法也並不是一無是處,在業務的OLTP系統庫中,這兩種輕量級的連線演演算法,以其自身的優越性也獲得了認可。
所以這三種演演算法,沒有誰好誰壞,只有合適的場景應用合適的連線演演算法,這樣才能發揮它自身的長處,而恰巧這些就是我們要掌握的技能。
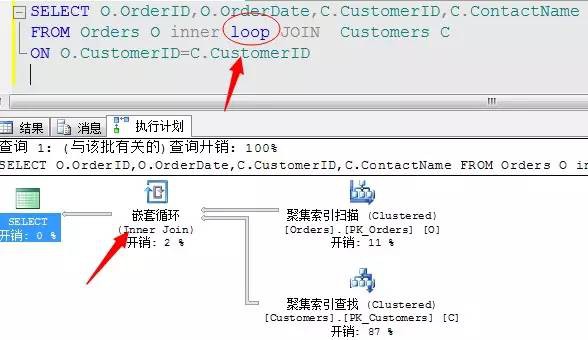
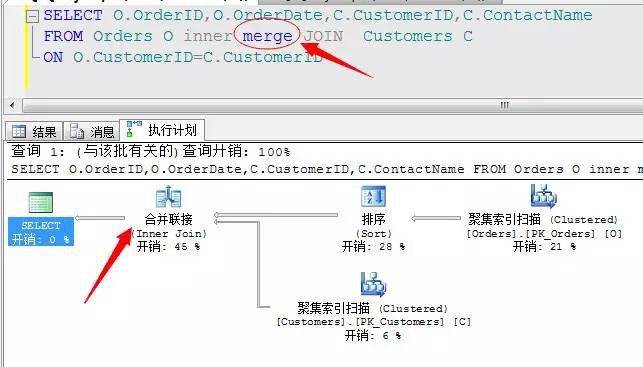
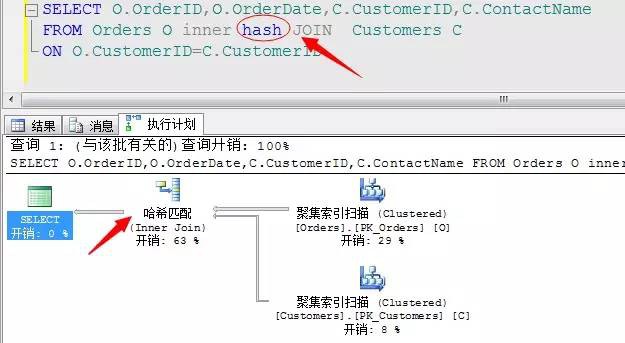
這三種連線演演算法我們也可以顯示的指定,但是一般不建議這麼做,因為預設SQL Server會為我們評估最優的連線方式進行操作,當然有時候它評估不對的時候就需要我們自己指定了,方法如下:
二、聚合操作
聚合也是我們在寫T-SQL陳述句的時候經常遇到的,我們來分析一下一些常用的聚合操作運運算元的特性和可最佳化項。
a、標量聚合
標量聚合是一種常用的資料聚合方式,比如我們寫的陳述句中利用的以下聚合函式:MAX()、MIN()、AVG()、COUNT()、SUM()
以上的這些資料結果項的輸出基本都是透過流聚合的方式產生,並且這個運運算元也被稱為:標量聚合
先來看一個列子
SELECT COUNT(*) FROM Orders
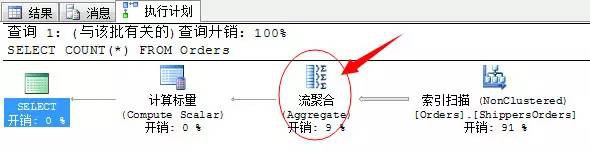
上面的圖表就是流聚合的運運算元了。
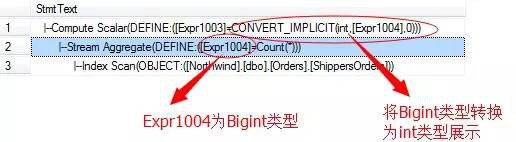
上圖還有一個計算標量的運運算元,這是因為在流聚合產生的結果項資料型別為Bigint型別,而預設輸出為int型別,所以增加了一個型別轉換的運運算元。
我們來看一個不需要轉換的
SELECT MIN(OrderDate),MAX(OrderDate) FROM Orders
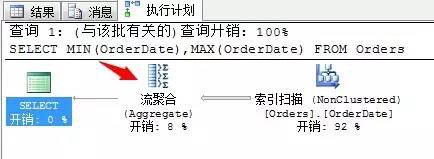
看一下求平均數的運運算元
SELECT AVG(Freight) FROM Orders

求平均數的時候,在SQL Server執行的時候也給我們添加了一個case when分類,防止分母為0的情況發生。
我們來看DISTINCT下的情況下,執行計劃
SELECT COUNT(DISTINCT ShipCity) FROM Orders
SELECT COUNT(DISTINCT OrderID) FROM Orders


上面相同的陳述句,但是產生了不同的執行計劃,只是因為發生在不同列的數量彙總上,因為OrderID不存在重覆列,所以SQL Server不需要排序直接流聚合就可以產生彙總值,而ShipCity不同它會有重覆的值,所以只能經過排序後再流聚合依次獲取彙總值。
其實,流聚合這種演演算法最常用的方式是分組(GROUP BY)計算,上面的標量計算也是利用這個特性,只不過把整體形成了一個大組進行聚合。
我麼透過如下程式碼理解
clear the current aggredate results
clear the current group by columns
for each input row
begin
if the input row does not match the current group by columns
begin
output the current aggreagate results(if any)
clear the current aggreagate results
set the current group by columns to the input row
end
update the aggregate results with the input rowend
流聚合運運算元其實過程很簡單,維護一個聚合組和聚合值,依次掃描表中的資料,如果能匹配聚合組則忽略,如果不匹配,則加入到聚合組中並且更新聚合值結果項。
舉個例子
SELECT ShipAddress,ShipCity,COUNT(*)
FROM Orders
GROUP BY ShipAddress,ShipCity
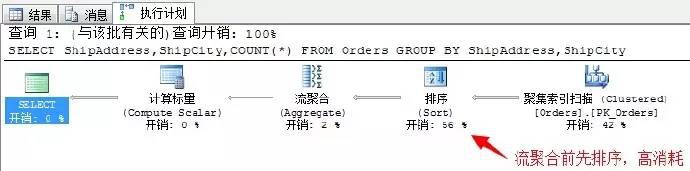
這裡使用了流聚合,並且之前先對兩列進行排序,排序的消耗總是很大。
如下程式碼就不會產生排序
SELECT CustomerID,COUNT(*)
FROM Orders
GROUP BY CustomerID
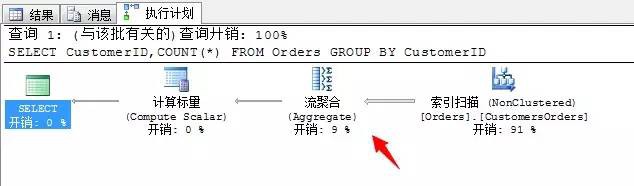
所以這裡我們已經總結出對於流聚合的一種最佳化方式:儘量避免排序產生,而要避免排序就需要將分組(Group by)欄位在索引改寫範圍內。
b、雜湊聚合
上述的流聚合的方式需要提前排序,我們知道排序是一個非常大的消耗過程,所以不適合大表的分組聚合操作,為瞭解決這個問題,又引入了另外一種聚合運算:雜湊聚合
所謂的雜湊聚合內部的方法和本篇前面提到的雜湊連線機制一樣。
雜湊聚合不需要排序和過大的記憶體消耗,並且很容易並行執行計劃,利用多CPU同步進行,但是有一個缺點就是:這一過程是阻塞的,也就說雜湊聚合不會產生任何結果直到完整的輸入。
所以在大資料表中採用雜湊聚合是一個很好的應用場景。
透過如下程式碼加深理解
for each input row
begin
calculate hash value on group by columns
check for a matching row in the hash table
if maching row not found
insert a new row into the hash table
else
update the matching row with the input row
end
–最後輸出結果ouput all rows in the hash table
簡單點將就是在進行運算匹配前,先將分組列進行雜湊處理,分配至不同的雜湊桶中,然後再依次匹配,最後才輸出結果。
舉個例子
SELECT ShipCountry,COUNT(*)
FROM Orders
GROUP BY ShipCountry
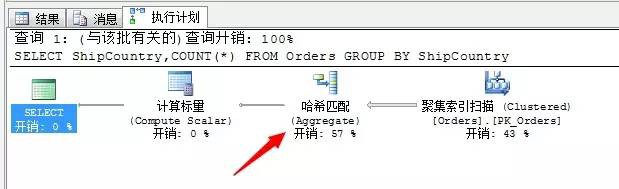
這個陳述句很有意思,我們利用了ShipCountry進行了分組,我們知道該列沒有被索引改寫,按照道理,其實選擇流聚合應該也是不錯的方式,跟上面我們列舉的列子一樣,先對這個欄位進行排序,然後利用流聚合形成結果項輸出。
但是,為什麼這個陳述句SQL Server為我們選擇了雜湊匹配作為了最優的演演算法呢!!!
我麼來比較兩個分組欄位:ShipCountry和前面的ShipAddress
前面是國家,後面是地址,國家是很多重覆的,並且只有少數的唯一值。而地址就不一樣了,離散型的分佈,我們知道排序是很耗資源的一件事情,但是利用雜湊匹配只需要將不同的列值進行提取就可以,所以相比效能而言,無疑雜湊匹配演演算法在這裡是略勝一籌的演演算法。
而上面關於這兩列內容分佈型別SQL Server是怎樣知道的?這就是SQL Server的強大的統計資訊在支撐了。
在SQL Server中並不是固定的陳述句就會形成特定的計劃,並且生成的特定計劃也不是總是最優的,這和資料庫現有資料表中的內容分佈、資料量、資料型別等諸多因素有關,而記錄這些詳細資訊的就是統計資訊。
所有的最優計劃的選擇都是基於現有統計資訊來評估,如果我們的統計資訊未及時更新,那麼所評估出來最優的執行計劃將不是最好的,有時候反而是最爛的。
參考文獻
微軟聯機叢書邏輯運運算元和物理運運算元取用
參照書籍《SQL.Server.2005.技術內幕》系列
結語
此篇文章先到此吧,本篇主要介紹了關於T-SQL陳述句調優從執行計劃下手,並介紹了三個常見的連線運運算元和聚合運運算元,下一篇將著重介紹我們其它最常用的一些運運算元和調優技巧,包括:CURD等運運算元、聯合運運算元、索引運算、並行運算等吧,關於SQL Server效能調優的內容涉及面很廣,後續文章中依次展開分析。
原文出處: 指尖流淌-吳學雷的部落格
原文連結: http://www.cnblogs.com/zhijianliutang/p/4141359.html