前言
前面我們的幾篇文章介紹了一系列關於運運算元的介紹,以及各個運運算元的最佳化方式和技巧。其中涵蓋:檢視執行計劃的方式、幾種資料集常用的連線方式、聯合運運算元方式、並行運運算元等一系列的我們常見的運運算元。有興趣的童鞋可以點選檢視。
本篇我們介紹關於子查詢陳述句的一系列內容,子查詢一般是我們形成複雜查詢的一些基礎性操作,所以關於子查詢的應用方式就非常重要。
廢話少說,開始本篇的正題。
技術準備
資料庫版本為SQL Server2008R2,利用微軟的一個更簡潔的案例庫(Northwind)進行分析。
一、獨立的子查詢方式
所謂的獨立的子查詢方式,就是說子查詢和主查詢沒有相關性,這樣帶來的好處就是子查詢不依賴於外部查詢,所以可以獨立外部查詢而被評估,形成自己的執行計劃執行。
舉個例子
SELECT O1.OrderID,O1.Freight
FROM Orders O1
WHERE O1.Freight>
(
SELECT AVG(O2.Freight)
FROM Orders O2
)
這句SQL執行的標的是查詢訂單中運費大於平均運費數的訂單。
這裡提取平均運費的子句就是一個完全獨立的子查詢,完全不依賴主查詢而獨立執行。同時這裡我們這裡利用利用一個標量計算(AVG),因此正好傳回一行。
檢視一下該陳述句的查詢計劃:
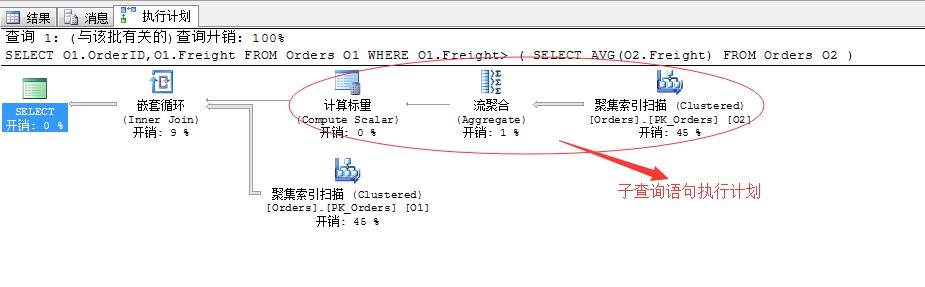
這個查詢計劃沒啥好介紹的,關於子查詢的執行計劃形成可以參照我的第二篇:SQL Server調優系列基礎篇(常用運運算元總結)
不過這裡需要提示一下就是,關於流聚合和計算標量形成的結果值(AVG)只包含一個結果值,所以該陳述句能正常的執行。
我們再來看另外一種情況
SELECT O.OrderID
FROM Orders O
WHERE O.CustomerID=
(
SELECT C.CustomerID
FROM Customers C
WHERE C.ContactName=N’Maria Anders’
)
該陳述句的也是獲取名字為’Maria Anders’的顧客有多少訂單。這句T-SQL陳述句能否執行的前提是在顧客表裡存不存在同名的“’Maria Anders’”顧客,如果存在同名情況,該陳述句就不能正確執行,而如果恰巧只有一名顧客為’Maria Anders’,則能正常執行。
我們來分析一下對於這種執行的時候才能判斷能否正確執行的SQL Server如何判斷的。
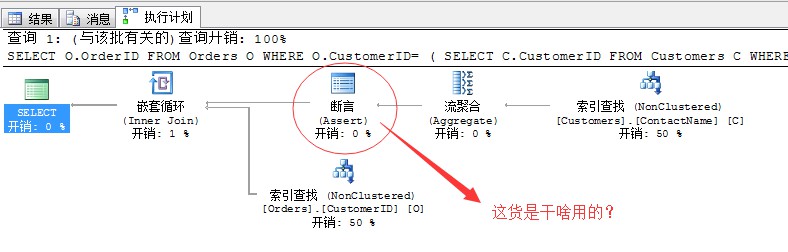
在這裡出現了一個新的運運算元,名字是:斷言。我們用文字執行計劃來檢視一下,這個運運算元的主要功能是什麼

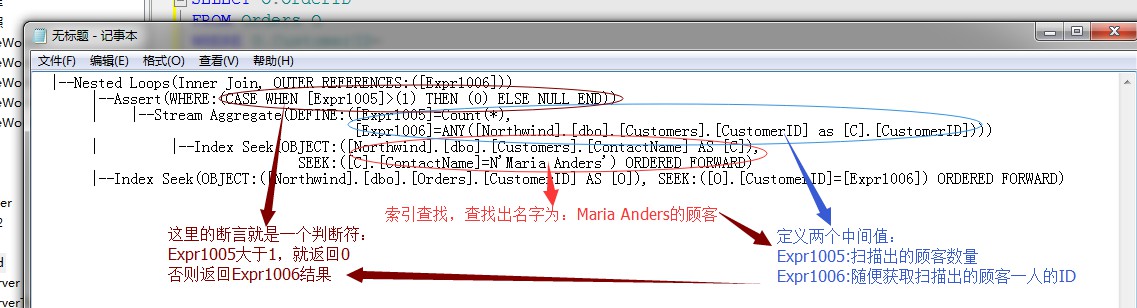
經過上面的分析,我們已經分析出了上面的“斷言”運運算元的作用,因為我們的子查詢陳述句不能保證傳回的結果為一行,所以,這裡引入了一個斷言運運算元來做判斷。
所以,斷言的作用就是根據下文的條件,判斷子查詢句的查詢結果是否滿足主陳述句的查詢要求。
如果,斷言發現子陳述句不滿足,就會直接報錯,比如上面的Expr1005>1
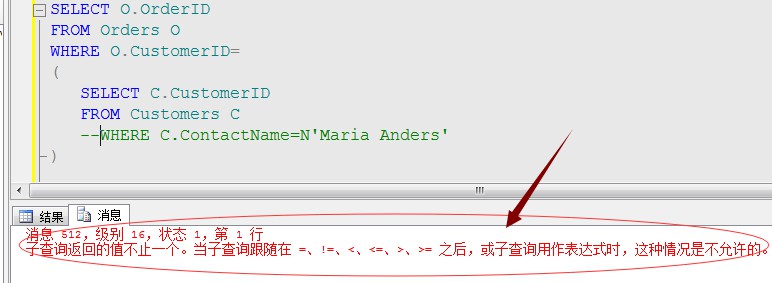
並且,斷言運運算元還經常用來檢測其它條件是否滿足,比如:約束條件、引數型別、值長度等。
其實,這裡斷言要解決的問題就是判斷我們的篩選條件中ContactName中的值是否存在重覆值的,對於這種判斷相對效能消耗還是比較小的,有時候對於別的複雜的斷言操作需要消耗大量資源,所以我們就可以根據適當情況情況避免斷言操作。
比如,上面的陳述句我們可以明確的告訴SQL Server在表Customers中ContactName列就不存在重覆值,它就不需要斷言了。我們在上面建立一個:唯一、非聚集索引實現。
CREATE UNIQUE INDEX ContactNameIndex ON Customers(ContactName)
GO
SELECT O.OrderID
FROM Orders O
WHERE O.CustomerID=
(
SELECT C.CustomerID
FROM Customers C
WHERE C.ContactName=N’Maria Anders’
)
drop index Customers.ContactNameIndex
GO

經過我們唯一非聚集索引的提示,SQL Server已經明確的知道我們的子查詢陳述句不會傳回多行的情況,所以就去掉了斷言操作。
二、相關的子查詢方式
相比上面的獨立子查詢方式,這裡的相關的子查詢方式相對複雜點,就是我們的子查詢依賴於主查詢的的結果,對於這種子查詢就不能單獨執行。
我們來看個這樣的子查詢例子
SELECT O1.OrderID
FROM Orders O1
WHERE O1.Freight>
(
SELECT AVG(O2.Freight)
FROM Orders O2
WHERE O2.OrderDate)
這個陳述句就是傳回之前訂單中運費量大於平均值的頂點編號。
陳述句很簡單的邏輯,但是這裡面的子查詢就依賴於主查詢的結果項,篩選條件中 WHERE O2.OrderDate
我們來看一下這個陳述句的執行計劃
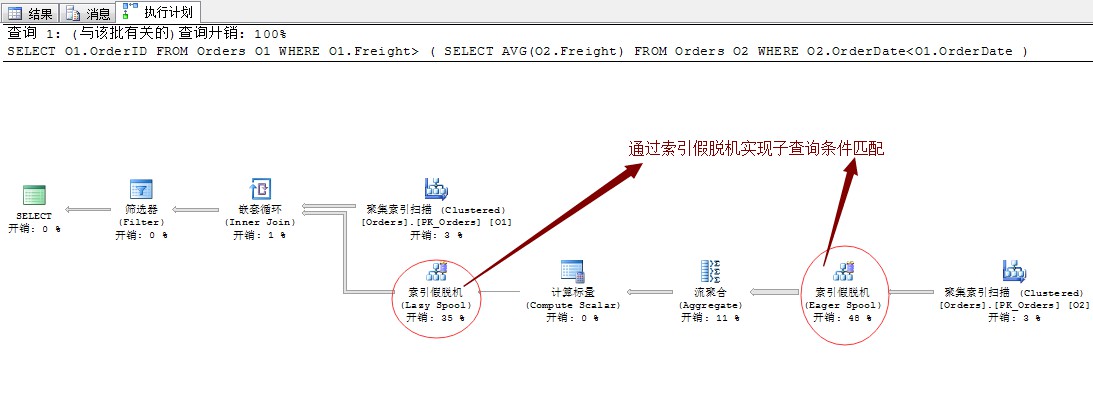
這裡的查詢計劃有出現了一個新的運運算元:索引假離線。
其實,關於索引假離線的作用主要是用於子查詢的獨立執行,因為我們知道這裡的子查詢的查詢條件是依賴於主查詢的,所以,這裡想執行的話就的先提前獲取出主查詢的結果項,而這裡獲取的主查詢的結果項需要一個中間表來暫存,這裡暫存的工具就是:(索引池)Index Spool,而對這個索引池的操作,比如:新建、增加等操作就是上面我們所標示的“索引假離線”了。
索引假離線分為兩種:Eager Spool和Lazy Spool,其實簡單點講就是需不需要立刻將結果存入Index Spool裡面,還是透過延遲操作。
而這裡形成的索引池(Index Spool)是存放於系統的臨時庫Tempdb中。
我們透過文字查詢計劃,來分析下兩個索引假離線裡面的值是什麼
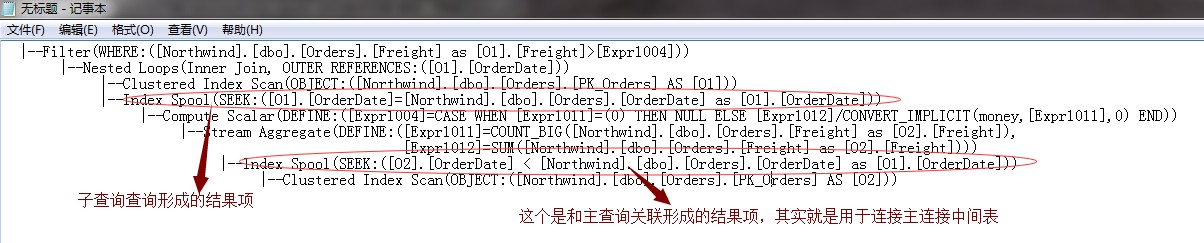
經過上面的分析,我們已經看到了,裡面的Eager Spool是和主查詢比較形成的結果值,因為這個必須要及時的形成,以便於子查詢的進行,所以它的型別為Eager Spool,
而子查詢外面的那個Index Spool為Lazy Spool,這個結果項的儲存不需要那麼及時了,這個儲存的就是子查詢的形成的結果項了,就是相對每個訂單運費的平均值。
我上面的分析,希望各位看官能看懂了。
其實,關於這個Index Spool的設計的目的,完全為了就是提升效能,因為我們知道上面的查詢陳述句每個子查詢的進行,都必須回呼主查詢的結果,所以為了避免每次都回呼,就採用了Index Spool進行暫存,而這個Index Spool儲存的位置就是Tempdb,所以Tempdb執行的快慢直接關乎這種查詢陳述句的效能。
這也是我們為什麼強調大併發的資料庫搭建,建議將Tempdb庫單獨存放於高效能的硬體環境中。
Index Spool 物理運運算元在 Argument 列中包含 SEEK:() 謂詞。Index Spool 運運算元掃描其輸入行,將每行的副本放置在隱藏的假離線檔案(儲存在 tempdb 資料庫中且只在查詢的生存期記憶體在)中,併為這些行建立非聚集索引。這樣可以使用索引的查詢功能來僅輸出那些滿足 SEEK:() 謂詞的行。
如果重繞該運運算元(例如透過 Nested Loops 運運算元重繞),但不需要任何重新系結,則將使用假離線資料,而不用重新掃描輸入。
跟索引離線類似的還有一個相似的運運算元:表離線,其功能類似,表離線儲存的應該是鍵值列,而表離線則是儲存的是多列資料了。
來看例子
SELECT O1.OrderID,O1.Freight
FROM Orders O1
WHERE O1.Freight>
(
SELECT AVG(O2.Freight)
FROM Orders O2
WHERE O2.CustomerID=O1.CustomerID
)
這個查詢和上面的類似,只不過是查詢的同一個客戶加入的超過所有訂單運費平均值的訂單。
此陳述句同樣不是獨立的子查詢陳述句,每個子查詢的結果的形成都需要依賴主查詢的結果項,為了加快速度,提升效能,SQL Server會將主表查詢的的結果項暫存到一張臨時表中,這個表就被稱為表離線
我們來看這句話的執行計劃:
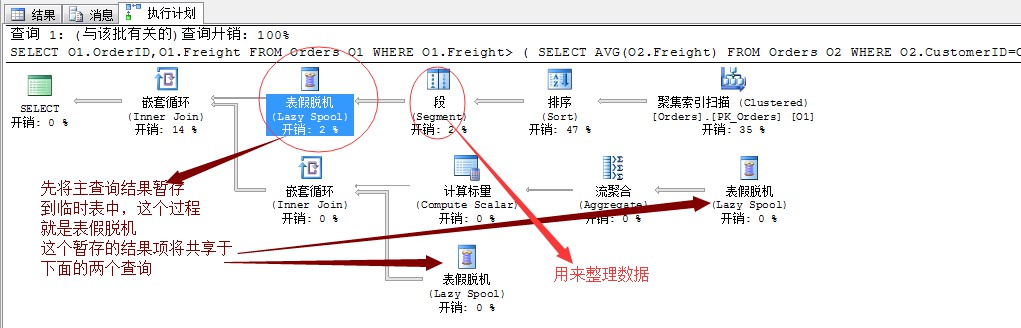
這裡就用到了一個表離線的運運算元,這個運運算元的作用就是用來暫存後面掃描獲取的結果集合,用於下麵的子查詢的應用
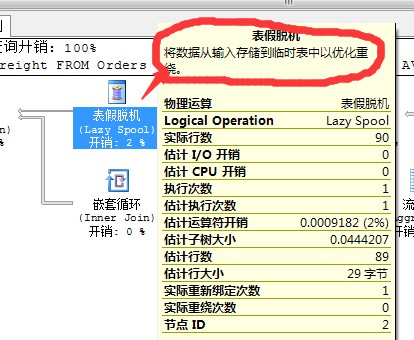
這個表離線形成的結果項也是儲存到臨時庫Tempdb中,所以它的應用和前面提到的索引離線類似。
上面的執行計劃中,還提到了一個新的運運算元:段(Segment)
這個運運算元的解釋是:
Segment 既是一個物理運運算元,也是一個邏輯運運算元。它基於一個或多個列的值將輸入集劃分成多個段。這些列顯示為 Segment 運運算元中的引數。然後運運算元每次輸出一個段。
其實作用就是將結果進行彙總整理,將相同值匯聚到一起,跟排序一樣,只不過這裡可以對多列值進行匯聚。
我們再來看一個例子,加深 一下關於段運算的作用
SELECT CustomerID,O1.OrderID,O1.Freight
FROM Orders O1
WHERE O1.Freight=
(
SELECT MAX(O2.Freight)
FROM Orders O2
WHERE O2.CustomerID=O1.CustomerID
)
這個陳述句查詢的是:每個顧客所產生的最大運費的訂單資料。
以上陳述句,如果理解起來有難度,我們可以變通以下的相同邏輯的T-SQL陳述句,相同的邏輯
SELECT O1.CustomerID,O1.OrderID,O1.Freight
FROM Orders O1
INNER JOIN
(
SELECT CustomerID,max(Freight) Freight
FROM Orders
GROUP BY CustomerID
) AS O2
ON O1.CustomerID=O2.CustomerID
AND O1.Freight=O2.Freight
先根據客戶編號分組,然後獲取出最大的運費項,再關聯主表獲取訂單資訊。
以上兩種陳述句生成的相同的查詢計劃:
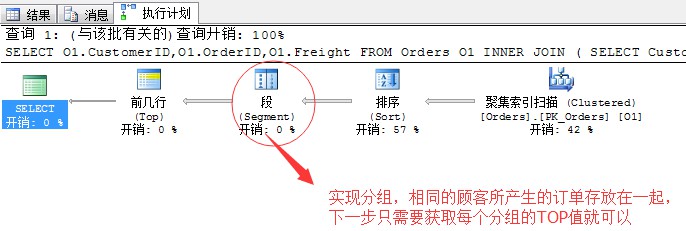
這裡我們來解釋一下,SQL Server的強大之處,也是段運運算元使用的最佳方式。
本來這句話要實現,按照邏輯需要有一個巢狀迴圈連線,參照上面的方式,使用表離線的方式進行資料的獲取。
但是,我們這句話獲取的結果項是每個顧客的最大運費的訂單明細項,而且CustomerID列作為輸出項,所以這裡採用了,先按照運費列(Freight)排序,
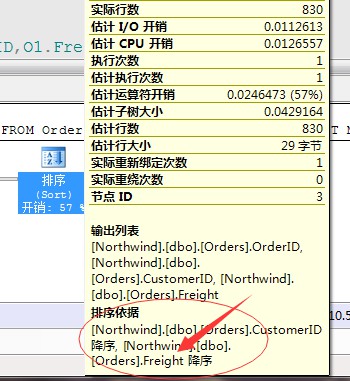
然後採用段運運算元進行將每個顧客相同的資料匯聚到一起,然後再輸出每個顧客的前一列(TOP 1)獲取的就是最每個顧客的運費最大的訂單項。
省去了任何的表假離線、索引假離線、關聯連線等一系列複雜的操作。
SQL Server看來這種智慧化的操作還是挺強的。
我們再來分析SQL Server關於子查詢這塊的智慧特性,因為經過上面的分析透過對比,相關的子查詢陳述句在執行時需要更多的消耗:
1、有時候需要透過索引假離線(Index Spool)、表離線(Table Spool)進行中間結果項的暫存,而這一過程的中間項需要建立、增加、刪除、銷毀等操作都需要消耗大量的記憶體和CPU
2、關於相關子查詢中以上提到的中間項的形成都是位於Tempdb臨時庫中,有時候會增大Tempdb的空間,增加Tempdb庫的消耗、頁爭用等問題。
所以,要避免上面的問題,最好的方式是避免使用相關子查詢,儘量使用獨立子查詢進行操作。
當然,SQL Server同樣提供了自動轉換的功能,智慧的去分析陳述句,避免相關的子查詢操作進行:
來看一個稍差的寫法:
SELECT o.OrderID
FROM Orders O
WHERE EXISTS
(
SELECT c.CustomerID
FROM Customers C
WHERE C.City=N’Londom’ AND C.CustomerID=O.CustomerID
)
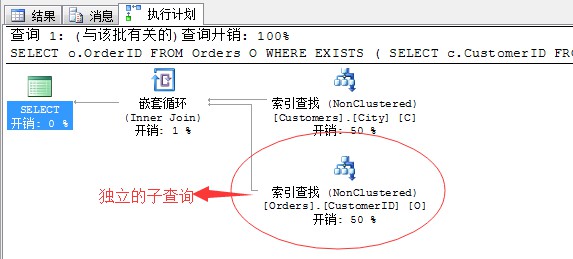
上面的陳述句,我們寫的是相關的子查詢操作,但是在執行計劃中形成的確實獨立的子查詢,這樣從而避免相關的子查詢所帶來的效能消耗。
其實上面陳述句,相對好的寫法是如下
SELECT o.OrderID
FROM Orders O
WHERE O.CustomerID IN
(
SELECT c.CustomerID
FROM Customers C
WHERE C.City=N’Londom’
)
這樣所形成的就是完全獨立的子查詢,這也是SQL Server要執行的意圖。所以這個陳述句形成的查詢計劃是和上面的查詢計劃一樣。
這裡的最佳化全部得益於SQL Server的智慧化。
但是我們在寫陳述句的時候,需要自己瞭解,掌握好,這樣才能寫出高效的T-SQL陳述句。
參考文獻
微軟聯機叢書邏輯運運算元和物理運運算元取用
參照書籍《SQL.Server.2005.技術內幕》系列
結語
本篇篇幅有點長,但是介紹的子查詢內容也還不是很全,後續慢慢的補充上,我們寫的SQL陳述句中很多都涉及到子查詢,所以這塊應用還是挺普遍的。到本篇文章關於日常調優的T-SQL中的查詢陳述句經常用到的一些運運算元基本介紹全了,當然,還有一些別的增刪改一系列的運運算元,這些日常生活中我們一般不採用查詢計劃調優,後續我們的文章會將這些運運算元也新增上,以供參考之用。
在完成本系列關於查詢計劃相關的調優之後,我打算將資料庫有關統計資訊這塊也做一個詳細的分析介紹。因為統計資訊是支撐SQL Server評估最優執行計劃的最重要的決策點,
所以統計資訊的重要性不言而喻。有興趣的童鞋可以提前關註。
關於SQL Server效能調優的內容涉及面很廣,後續文章中依次展開分析。
有問題可以留言或者私信,隨時恭候有興趣的童鞋加入SQL SERVER的深入研究。共同學習,一起進步。
原文出處: 指尖流淌-吳學雷的部落格
原文連結: http://www.cnblogs.com/zhijianliutang/p/4161832.html