前言
前面我們的幾篇文章介紹了一系列關於運運算元的基礎介紹,以及各個運運算元的最佳化方式和技巧。其中涵蓋:檢視執行計劃的方式、幾種資料集常用的連線方式、聯合運運算元方式、並行運運算元等一系列的我們常見的運運算元。有興趣的童鞋可以點選檢視。
本篇介紹在SQL Server中查詢最佳化器的工作方式,也就是一個好的執行計劃的形成,是如何評估出來的,作為該系列的進階篇。
廢話少說,開始本篇的正題。
技術準備
資料庫版本為SQL Server2008R2,利用微軟的一個更簡潔的案例庫(Northwind)進行分析。
正文內容
在我們將寫好的一個T-SQL陳述句拋給SQL Server準備執行的時候,首選要經歷的過程就是編譯過程,當然如果此陳述句以前在SQL Server中執行過,那麼將檢測是否存在已經快取的編譯過的執行計劃,用以重用。
但是,執行編譯的過程需要執行一系列的最佳化過程,關於最佳化過程大致分為兩個階段:
1、首先,SQL Server對我們寫的T-SQL陳述句先執行一些簡化,通常由查詢本身來尋找互動性及重新安排操作的順序。
在此過程中,SQL Server側重於陳述句寫法調整,而不過多的考慮成本或者分析索引可用性的等,最重要的標的就是產生一個有效的查詢。
然後,SQL Server才會載入元資料,包括索引的統計資訊,進入第二個階段。
2、在這個階段才是SQL Server一個複雜的最佳化過程,這個階段SQL Server會根據上一階段形成的執行計劃運運算元進行評估和嘗試,甚至於重組執行計劃,所以相對這個最佳化過程是一個耗時的過程。
透過如下流程圖,來理解該過程:
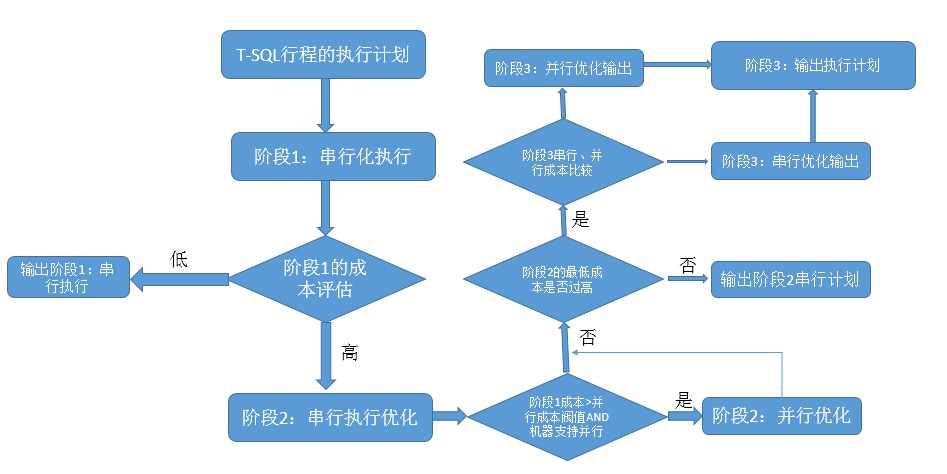 這個圖看上去有點複雜,我們來詳細分析下,其實就是將這個最佳化階段分為3個子階段
這個圖看上去有點複雜,我們來詳細分析下,其實就是將這個最佳化階段分為3個子階段
<1>這個階段僅考慮序列計劃,也就說單處理器執行,如果這個階段找到了一個好的序列計劃,最佳化器就不會進入下一階段。所以對於資料量少的情況,或者執行陳述句簡單的情況下,基本採用的都是序列計劃。
當然,如果這個階段開銷比較大,那麼會進入到第2個階段,再進行最佳化。
<2>這個階段首先對第1階段的序列計劃進行最佳化,然後如果環境支援並行化操作,則進行並行化操作,透過進行比較,然後進行最佳化後的成本如果比較低則輸出執行計劃,如果成本還是比較高,則進入第2階段,再繼續最佳化。
<3>其實到達這個階段就是最佳化的最後一個階段了,這個階段會對第2個階段中採用序列和並行的比較結果進行最後一步最佳化,如果序列執行好那就進一步最佳化,當然如果並行執行好的話,則再繼續並行最佳化。
其實第3階段是查詢最佳化器的無奈之舉,當到達第3階段了就是一個補救階段,只能最後做優化了,最佳化完好不好的就只能按照這個執行計劃執行了。
那麼上述過程中,各個階段的最佳化的原則有哪些:
關於這些最佳化器的最重要原則的就是:盡可能的減少掃描範圍,不管是表或者索引,當然走索引比表好,索引的量也是越少越好,最理想的情況是隻有一條或者幾條。
所以,SQL Server也尊重上述原則,一直圍繞著這個原則去最佳化。
一、篩選條件分析
所謂的篩選條件,其實就是我們所寫的T-SQL陳述句中的WHERE陳述句後面的條件,我們會透過這裡面的陳述句進行儘量縮小資料掃描範圍,SQL Server透過這些陳述句來最佳化。
一般格式如下:
column operator
或者
而這上面格式中operator包括:=、>、、<=、BETWEEN、LIKE
比如:name=’liudehua’、price>4000、4000
上面這些陳述句是我們寫的陳述句中最常用的方式,並且這種方式也將被SQL Server用來減少掃描,並且這些列被索引改寫,那將儘量採取索引進行獲取值,但是SQL Server也不是萬能的,有些寫法它也是不能識別的,也是我們寫陳述句要避免的:
a、where name like ‘%liu’這貨就不能被SQL Server最佳化器識別,所以它只能透過全表掃描或者索引掃描執行。
b、name=’liudehua’ OR price >1000,這個同樣也是失效的,因為它不能利用兩個的篩選條件進行逐步減少掃描。
c、price+4>100這個同樣不被識別
d、name not in (‘liudehua’、‘zhourunfa’),當然還有類似的:NOT 、NOT LIKE
舉個例子:
SELECT CustomerID FROM Orders
WHERE CustomerID=’Vinet’
SELECT CustomerID FROM Orders
WHERE UPPER(CustomerID)=’VINET’
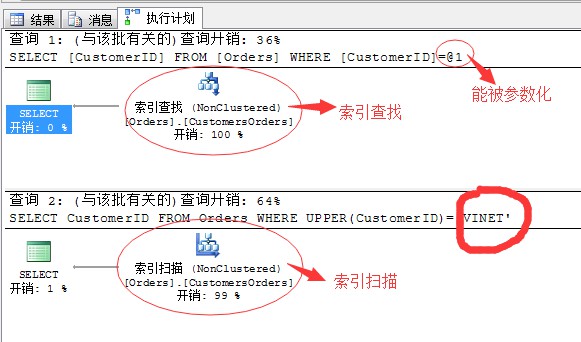
所以上述的方式寫陳述句的時候需要儘量避免,或者採取變通的方式實現。
二、索引最佳化
經過上面的篩選範圍的確定之後,SQL Server緊接著開始索引的選擇,首先要確定的第一件事就是篩選欄位是否存在索引項,也就是說是否被索引改寫。
當然,如果查詢項為索引改寫最好,如果不被索引改寫,那麼為了充分利用索引的特性,就引入了書簽查詢(bookmark)部分。
所以,鑒於此,我們在建立索引的時候,所參考的屬性值就為篩選條件的列了。
關於利用索引最佳化的選擇:
CREATE INDEX EmployeesName ON Employees(FirstName,LastName)
INCLUDE(HIREDATE) WITH(ONLINE=ON)
GOSELECT FirstName,LastName,HireDate,EmployeeID
FROM EmployeesWHERE FirstName=’Anne’
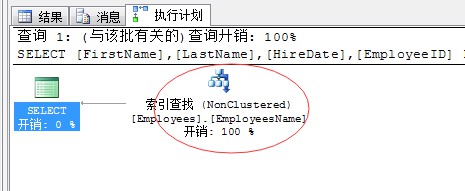
當然也不盡然只要查詢列存在索引改寫就執行索引查詢,這取決於掃描的內容的多少,所以對於索引的利用程度還取決獲取內容的多少
來舉個例子:
CREATE INDEX NameIndex ON person.contact(FirstName,LastName)
GO
SELECT * FROM Person.Contact
WHERE FirstName LIKE ‘K%’SELECT * FROM Person.Contact
WHERE FirstName LIKE ‘Y%’GO
完全相同的查詢陳述句,來看執行計劃:
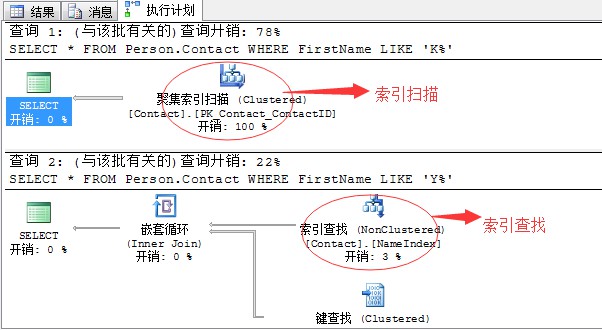
完全相同的查詢陳述句,產生的查詢計劃完全不同,一個是索引掃描,一個則是高效的索引查詢。
這裡我只告訴你:FirstName like ‘K%’的有1255行;而FirstName like ‘Y%’只有37行,其中
其實,關於這裡的原因就是統計資訊在作怪了。
所以,特定的T-SQL陳述句不一定生成特定的查詢計劃,同樣特定的查詢計劃不一定是最優的方式,影響的它的因素很多:關於索引、關於硬體、關於表內容、關於統計資訊等諸多因素影響。
關於統計資訊這塊是大篇幅內容,我們放在以後的篇幅中介紹,有興趣的可以提前關註。
有問題可以留言或者私信,隨時恭候有興趣的童鞋加入SQL SERVER的深入研究。共同學習,一起進步。
原文出處: 指尖流淌-吳學雷的部落格
原文連結: http://www.cnblogs.com/zhijianliutang/p/4175551.html