(點選上方公號,快速關註我們)
來源:陳汝丹
chenrudan.github.io
最近看了一些關於降維演演算法的東西,本文首先給出了七種演演算法的一個資訊表,歸納了關於每個演演算法可以調節的(超)引數、演演算法主要目的等等,然後介紹了降維的一些基本概念,包括降維是什麼、為什麼要降維、降維可以解決維數災難等,然後分析可以從什麼樣的角度來降維,接著整理了這些演演算法的具體流程。主要目錄如下:
-
1. 降維基本概念
-
2. 從什麼角度出發降維
-
3. 降維演演算法
-
3.1 主成分分析PCA
-
3.2 多維縮放(MDS)
-
3.3 線性判別分析(LDA)
-
3.4 等度量對映(Isomap)
-
3.5 區域性線性嵌入(LLE)
-
3.6 t-SNE
-
3.7 Deep Autoencoder Networks
-
4. 小結
老規矩,先上一個各個演演算法資訊表,X 表示高維輸入矩陣大小是高維數D乘以樣本個數N, ,Z 表示降維輸出矩陣大小低維數d乘以N,
,Z 表示降維輸出矩陣大小低維數d乘以N,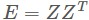 ,線性對映是
,線性對映是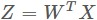 ,高維空間中兩兩之間的距離矩陣為A,Sw,Sb分別是LDA的類內散度矩陣和類間散度矩陣,k表示流形學習中一個點與k個點是鄰近關係,F表示高維空間中一個點由周圍幾個點的線性組合矩陣,
,高維空間中兩兩之間的距離矩陣為A,Sw,Sb分別是LDA的類內散度矩陣和類間散度矩陣,k表示流形學習中一個點與k個點是鄰近關係,F表示高維空間中一個點由周圍幾個點的線性組合矩陣, 。−表示不確定。P 是高維空間中兩點距離佔所有距離比重的機率矩陣,Q 低維空間中兩點距離佔所有距離比重的機率矩陣。
。−表示不確定。P 是高維空間中兩點距離佔所有距離比重的機率矩陣,Q 低維空間中兩點距離佔所有距離比重的機率矩陣。 表示全連線神經網路的層數,
表示全連線神經網路的層數,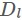 表示每一層的節點個數。
表示每一層的節點個數。

圖1 不同降維演演算法對比
這裡autoencoder是否去中心化個人覺得還是有點疑問,在處理影象資料的時候,會對輸入圖片做一個變到0均值的預處理,但是這個操作是針對一張樣本內減均值[1],這裡的去中心化指的是針對某一維資料減均值,並不是一個概念。下麵開始具體談談降維相關的內容。
1.降維基本概念
降維的意思是能夠用一組個數為d的向量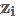 來代表個數為D的向量
來代表個數為D的向量 所包含的有用資訊,其中d<D。假設對一張512*512大小的圖片,用svm來做分類,最直接的做法是將圖按照行或者列展開變成長度為512*512的輸入向量,跟svm的引數相乘。假如能夠將512*512的向量在保留有用資訊的情況下降維到100,那麼儲存輸入和引數的空間會減少很多,計算向量乘法的時間也會減少很多。所以降維能夠有效的減少計算時間。而高維空間的資料很有可能出現分佈稀疏的情況,即100個樣本在100維空間分佈肯定是非常稀疏的,每增加一維所需的樣本個數呈指數級增長,這種在高維空間中樣本稀疏的問題被稱為維數災難。降維可以緩解這種問題。
所包含的有用資訊,其中d<D。假設對一張512*512大小的圖片,用svm來做分類,最直接的做法是將圖按照行或者列展開變成長度為512*512的輸入向量,跟svm的引數相乘。假如能夠將512*512的向量在保留有用資訊的情況下降維到100,那麼儲存輸入和引數的空間會減少很多,計算向量乘法的時間也會減少很多。所以降維能夠有效的減少計算時間。而高維空間的資料很有可能出現分佈稀疏的情況,即100個樣本在100維空間分佈肯定是非常稀疏的,每增加一維所需的樣本個數呈指數級增長,這種在高維空間中樣本稀疏的問題被稱為維數災難。降維可以緩解這種問題。
而為什麼可以降維,這是因為資料有冗餘,要麼是一些沒有用的資訊,要麼是一些重覆表達的資訊,例如一張512*512的圖只有中心100*100的區域內有非0值,剩下的區域就是沒有用的資訊,又或者一張圖是成中心對稱的,那麼對稱的部分資訊就重覆了。正確降維後的資料一般保留了原始資料的大部分的重要資訊,它完全可以替代輸入去做一些其他的工作,從而很大程度上可以減少計算量。例如降到二維或者三維來視覺化。
2. 從什麼角度出發來降維
一般來說可以從兩個角度來考慮做資料降維,一種是直接提取特徵子集做特徵抽取,例如從512*512圖中只取中心部分,一種是透過線性/非線性的方式將原來高維空間變換到一個新的空間,這裡主要討論後面一種。後面一種的角度一般有兩種思路來實現[2],一種是基於從高維空間對映到低維空間的projection方法,其中代表演演算法就是PCA,而其他的LDA、Autoencoder也算是這種,主要目的就是學習或者算出一個矩陣變換W,用這個矩陣與高維資料相乘得到低維資料。另一種是基於流形學習的方法,流形學習的目的是找到高維空間樣本的低維描述,它假設在高維空間中資料會呈現一種有規律的低維流形排列,但是這種規律排列不能直接透過高維空間的歐式距離來衡量,如下左圖所示,某兩點實際上的距離應該是下右圖展開後的距離。如果能夠有方法將高維空間中流形描述出來,那麼在降維的過程中就能夠保留這種空間關係,為瞭解決這個問題,流形學習假設高維空間的區域性區域仍然具有歐式空間的性質,即它們的距離可以透過歐式距離算出(Isomap),或者某點坐標能夠由臨近的節點線性組合算出(LLE),從而可以獲得高維空間的一種關係,而這種關係能夠在低維空間中保留下來,從而基於這種關係表示來進行降維,因此流形學習可以用來壓縮資料、視覺化、獲取有效的距離矩陣等。
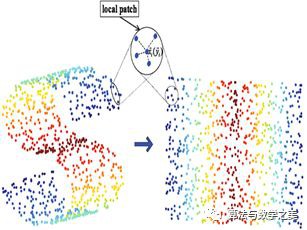
圖2 流形學習
3. 幾種降維方法流程
3.1 主成分分析PCA
PCA由Karl Pearson在1901年發明,是一種線性降維方法,高維空間(維數為D)的某個點 透過與矩陣W相乘對映到低維空間(維數為d,d<D)中的某個點
透過與矩陣W相乘對映到低維空間(維數為d,d<D)中的某個點 ,其中W的大小是D∗d,i對應的是第i個樣本點。從而可以得到N個從D維空間對映到d維空間的點,PCA的標的是讓對映得到的點盡可能的分開,即讓N個的方差盡可能大。假如D維空間中的資料每一維均值為0,即
,其中W的大小是D∗d,i對應的是第i個樣本點。從而可以得到N個從D維空間對映到d維空間的點,PCA的標的是讓對映得到的點盡可能的分開,即讓N個的方差盡可能大。假如D維空間中的資料每一維均值為0,即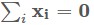 ,那麼兩邊乘上
,那麼兩邊乘上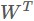 得到的降維後的資料每一維均值也是0,考慮一個矩陣
得到的降維後的資料每一維均值也是0,考慮一個矩陣 ,這個矩陣是這組D維資料的協方差矩陣,可以看出對角線上的值是D維中的某一維內的方差,非對角線元素是D維中兩維之間的協方差。
,這個矩陣是這組D維資料的協方差矩陣,可以看出對角線上的值是D維中的某一維內的方差,非對角線元素是D維中兩維之間的協方差。
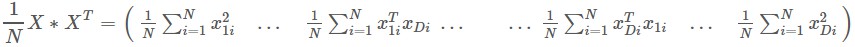
那麼針對降維後d維資料的協方差矩陣 ,如果希望降維後的點盡可能分開,那麼就希望B對角線上值即每一維的方差盡可能大,方差大說明這些維上資料具有非常好的區分性,同時希望d的每一維都是正交的,它們正交就會使得兩個維是無關的,那麼它們就不會包含重疊的資訊,這樣就能最好的表現資料,每一維都具有足夠的區分性,同時還具有不同的資訊。這種情況下B非對角線上值全部為0。又由於可以推導得出
,如果希望降維後的點盡可能分開,那麼就希望B對角線上值即每一維的方差盡可能大,方差大說明這些維上資料具有非常好的區分性,同時希望d的每一維都是正交的,它們正交就會使得兩個維是無關的,那麼它們就不會包含重疊的資訊,這樣就能最好的表現資料,每一維都具有足夠的區分性,同時還具有不同的資訊。這種情況下B非對角線上值全部為0。又由於可以推導得出

這個式子實際上就是表示了線性變換矩陣W在PCA演演算法中的作用是讓原始協方差矩陣C對角化。又由於線性代數中對角化是透過求解特徵值與對應的特徵向量得到,因此可以推出PCA演演算法流程(流程主要摘自周志華老師的《機器學習》一書,其中加入了標的和假設用於對比後面的演演算法。周老師書中是基於拉格朗日乘子法推匯出來,本質上而言與[3]都是一樣的,這裡很推薦這篇講PCA數學原理的部落格[3])。
-
輸入:N個D維向量
 ,降維到d維
,降維到d維 -
輸出:投影矩陣
 ,其中每一個
,其中每一個 都是D維列向量
都是D維列向量 -
標的:投影降維後資料盡可能分開,
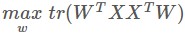 (這裡的跡是因為上面提到的B的非對角線元素都是0,而對角線上的元素恰好都是每一維的方差)
(這裡的跡是因為上面提到的B的非對角線元素都是0,而對角線上的元素恰好都是每一維的方差)
-
假設:降維後資料每一維方差盡可能大,並且每一維都正交
-
1.將輸入的每一維均值都變為0,去中心化
-
2.計算輸入的協方差矩陣

-
3.對協方差矩陣C做特徵值分解
-
4.取最大的前d個特徵值對應的特徵向量

此外,PCA還有很多變種kernel PCA, probabilistic PCA等等,本文暫時只考慮最簡單的PCA版本。
3.2 多維縮放(MDS)
MDS的標的是在降維的過程中將資料的dissimilarity(差異性)保持下來,也可以理解降維讓高維空間中的距離關係與低維空間中距離關係保持不變。這裡的距離用矩陣表示,N個樣本的兩兩距離用矩陣A的每一項 表示,並且假設在低維空間中的距離是歐式距離。而降維後的資料表示為,那麼就有
表示,並且假設在低維空間中的距離是歐式距離。而降維後的資料表示為,那麼就有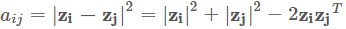 。右邊的三項統一用內積矩陣E來表示
。右邊的三項統一用內積矩陣E來表示 。去中心化之後,E的每一行每一列之和都是0,從而可以推導得出
。去中心化之後,E的每一行每一列之和都是0,從而可以推導得出

其中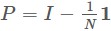 單位矩陣I減去全1矩陣的
單位矩陣I減去全1矩陣的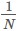 ,i⋅ 與⋅j 是指某列或者某列總和,從而建立了距離矩陣A與內積矩陣E之間的關係。因而在知道A情況下就能夠求解出E,進而透過對E做特徵值分解,令
,i⋅ 與⋅j 是指某列或者某列總和,從而建立了距離矩陣A與內積矩陣E之間的關係。因而在知道A情況下就能夠求解出E,進而透過對E做特徵值分解,令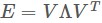 ,其中 Λ 是對角矩陣,每一項都是E的特徵值λ1≥…≥λd,那麼在所有特徵值下的資料就能表示成
,其中 Λ 是對角矩陣,每一項都是E的特徵值λ1≥…≥λd,那麼在所有特徵值下的資料就能表示成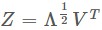 ,當選取d個最大特徵值就能讓在d維空間的距離矩陣近似高維空間D的距離矩陣,從MDS流程如下[2]:
,當選取d個最大特徵值就能讓在d維空間的距離矩陣近似高維空間D的距離矩陣,從MDS流程如下[2]:
-
輸入:距離矩陣
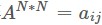 ,上標表示矩陣大小,原始資料是D維,降維到d維
,上標表示矩陣大小,原始資料是D維,降維到d維 -
輸出:降維後矩陣
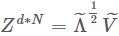
-
標的:降維的同時保證資料之間的相對關係不變
-
假設:已知N個樣本的距離矩陣
-
1.算出$a{i\cdot}、a{\cdot j}、a_{\cdot \cdot}$
-
2.計算內積矩陣E
-
3.對E做特徵值分解
-
4.取d個最大特徵值構成
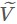 ,對應的特徵向量按序排列構成
,對應的特徵向量按序排列構成
3.3 線性判別分析(LDA)
LDA最開始是作為解決二分類問題由Fisher在1936年提出,由於計算過程實際上對資料做了降維處理,因此也可用作監督線性降維。它透過將高維空間資料投影到低維空間,在低維空間中確定每個樣本所屬的類,這裡考慮K個類的情況。它的標的是將樣本能盡可能正確的分成K類,體現為同類樣本投影點盡可能近,不同類樣本點盡可能遠,這點跟PCA就不一樣,PCA是希望所有樣本在某一個維數上盡可能分開,LDA的低維投影可能會重疊,但是PCA就不希望投影點重疊。它採用的降維思路跟PCA是一樣的,都是透過矩陣乘法來進行線性降維,投影點是 。假設按下圖中的方向來投影,投影中心對應的原來高維點分別是μ1,μ2。由於希望屬於不同類的樣本盡可能離的遠,那麼就希望投影過後的投影中心點離的盡可能遠,即標的是
。假設按下圖中的方向來投影,投影中心對應的原來高維點分別是μ1,μ2。由於希望屬於不同類的樣本盡可能離的遠,那麼就希望投影過後的投影中心點離的盡可能遠,即標的是 ,但是僅僅有中心離的遠還不夠,例如下圖中垂直於x1軸投影,兩個中心離的足夠遠,但是·有樣本在投影空間重疊,因此還需要額外的最佳化標的,即同類樣本投影點盡可能近。那麼同類樣本的類間協方差就應該盡可能小,同類樣本的協方差矩陣如下。
,但是僅僅有中心離的遠還不夠,例如下圖中垂直於x1軸投影,兩個中心離的足夠遠,但是·有樣本在投影空間重疊,因此還需要額外的最佳化標的,即同類樣本投影點盡可能近。那麼同類樣本的類間協方差就應該盡可能小,同類樣本的協方差矩陣如下。
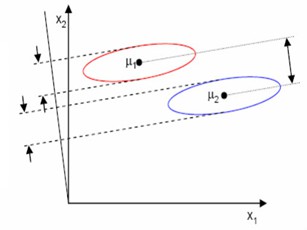
圖3 LDA進行投影(圖來源[4])
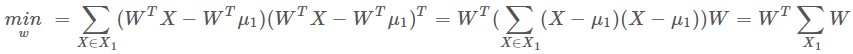
其中μ1=(u1,…,uN),W=(w1,…,wd),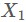 表示樣本屬於第1類的集合,中間的矩陣
表示樣本屬於第1類的集合,中間的矩陣 是屬於第的樣本協方差矩陣,將K個類的原始資料協方差矩陣加起來稱為類內散度矩陣,
是屬於第的樣本協方差矩陣,將K個類的原始資料協方差矩陣加起來稱為類內散度矩陣, 。而上面兩個類的中心距離是中心直接相減,K個類投影中心距離需要先計算出全部樣本的中心
。而上面兩個類的中心距離是中心直接相減,K個類投影中心距離需要先計算出全部樣本的中心 (
(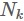 表示屬於第k類的樣本個數),透過類間散度矩陣來衡量,即
表示屬於第k類的樣本個數),透過類間散度矩陣來衡量,即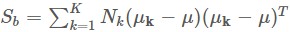 。整合一下,LDA演演算法的最佳化標的是最大化下麵的costfunction:
。整合一下,LDA演演算法的最佳化標的是最大化下麵的costfunction:
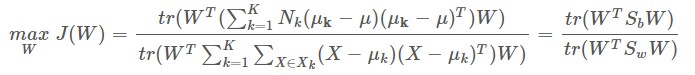
二分類情況下,W的大小是D∗1,即J(W)本身是個標量,針對K類的情況,W的大小是D∗d−1,最佳化的標的是對上下的矩陣求它的跡。這裡可以發現在LDA中沒有對資料去中心化,如果要去中心化每個類的中心就會重疊了,所以這個演演算法沒有去中心化。然後J(W)對W求導,這個式子就表明瞭W的解是 的d-1個最大特徵值對應的特徵向量組成的矩陣。那麼就可以透過W來對X進行降維。
的d-1個最大特徵值對應的特徵向量組成的矩陣。那麼就可以透過W來對X進行降維。

-
輸入:N個D維向量
 ,資料能夠被分成d個類
,資料能夠被分成d個類 -
輸出:投影矩陣$W=(w1, …, w{d-1}),其中每一個,其中每一個w_i$都是D維列向量
-
標的:投影降維後同一類的樣本之間協方差盡可能小,不同類之間中心距離盡可能遠
-
假設:最佳化標的是最大化
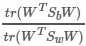
-
1.求出類內散度矩陣Sw 和類間散度矩陣Sb
-
2.對做奇異值分解
 ,求得
,求得
-
3.對矩陣
 做特徵分解
做特徵分解 -
4.取最大的前d-1個特徵值對應的特徵向量$w1,…,w{d-1}$
個人覺得這裡的最佳化標的實際上體現了一個假設,即假設最佳化標的上下的運算式都是對角矩陣,W的變換使得Sd 與Sw 都變成了對角矩陣。
3.4 等度量對映(Isomap)
上面提到的MDS只是對資料降維,它需要已知高維空間中的距離關係,它並不能反應出高維資料本身潛在的流形,但是可以結合流形學習的基本思想和MDS來進行降維[5]。也就是高維空間的區域性空間的距離可以用歐式距離算出,針對MDS的距離矩陣A,某兩個相鄰的點之間距離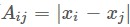 也就是它們的歐式距離,距離比較近的點則透過最短路徑演演算法來確定,而離的比較遠的兩點之間Aij = ∞,把矩陣A確定下來,那麼這裡就涉及到判斷什麼樣的點相鄰,Isomap是透過KNN來確定相鄰的點,整體演演算法流程如下:
也就是它們的歐式距離,距離比較近的點則透過最短路徑演演算法來確定,而離的比較遠的兩點之間Aij = ∞,把矩陣A確定下來,那麼這裡就涉及到判斷什麼樣的點相鄰,Isomap是透過KNN來確定相鄰的點,整體演演算法流程如下:
-
輸入:N個D維向量
,一個點有K個近鄰點,對映到d維 -
輸出:降維後矩陣

-
標的:降維的同時保證高維資料的流形不變
-
假設:高維空間的區域性區域上某兩點距離可以由歐式距離算出
-
1.由KNN先構造A的一部分,即求出相鄰的點並取它們的歐式距離填入Aij,其他的位置全部初始化為無窮大
-
2.根據最短路徑演演算法(Dijkstra演演算法)找到距離比較近的點之間的路徑並填入距離
-
3.將距離矩陣A作為MDS的輸入,得到輸出
3.5 區域性線性嵌入(LLE)
如之前提到過的,流形學習的區域性區域具有歐式空間的性質,那麼在LLE中就假設某個點 xi 坐標可以由它周圍的一些點的坐標線性組合求出,即 (其中 Xi 表示 xi 的鄰域上點的集合),這也是在高維空間的一種表示。由於這種關係在低維空間中也被保留,因此
(其中 Xi 表示 xi 的鄰域上點的集合),這也是在高維空間的一種表示。由於這種關係在低維空間中也被保留,因此 ,兩個式子裡面權重取值是一樣的。
,兩個式子裡面權重取值是一樣的。
基於上面的假設,首先想辦法來求解這個權重,假設每個樣本點由周圍K個樣本求出來,那麼一個樣本的線性組合權重大小應該是1∗K,透過最小化reconstruct error重構誤差來求解,然後標的函式對f求導得到解。

求出權重之後,代入低維空間的最佳化標的

來求解Z,這裡將F按照 N∗K 排列起來,且加入了對Z的限制。這裡用拉格朗日乘子法可以得到 MZ=λY 的形式,從而透過對M進行特徵值分解求得Z。
-
輸入:N個D維向量
,一個點有K個近鄰點,對映到d維 -
輸出:降維後矩陣Z
-
標的:降維的同時保證高維資料的流形不變
-
假設:高維空間的區域性區域上某一點是相鄰K個點的線性組合,低維空間各維正交
-
1.由KNN先構造A的一部分,即求出K個相鄰的點,然後求出矩陣F和M
-
2.對M進行特徵值分解
-
3.取前d個非0最小的特徵值對應的特徵向量構成Z(這裡因為最小化標的,所以取小的特徵值)
3.6 t-SNE
t-SNE也是一種將高維資料降維到二維或者三維空間的方法,它是2008年由Maaten提出[6],基於2002年Hinton提出的隨機近鄰嵌入(StochasticNeighbor Embedding, SNE)方法的改進。主要的思想是假設高維空間中的任意兩個點,xj 的取值服從以 xi 為中心方差為 σi 的高斯分佈,同樣 xi 服從以 xj 為中心方差為σj 的高斯分佈,這樣 xj 與 xi 相似的條件機率就為

即 xj 在 xi 高斯分佈下的機率佔全部樣本在 xi 高斯分佈下機率的多少,說明瞭從 xi 角度來看兩者的相似程度。接著令 pij =(pi|j+pj|i)/2n用這個機率來作為兩個點相似度在全部樣本兩兩相似度的聯合機率 pij 。公式如下,論文沒有解釋σ是標量還是向量,但是因為在後續的求解中 pij 不是直接由下麵這個聯合機率公式求出,而是透過前面的條件機率來求,前面的式子針對每一個樣本i都會計算一個σi,具體給定一個確定值 ,其中
,其中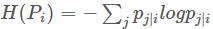 。接著透過二分查詢來確定 xi 對應的σi,使得代入上面的兩個式子後等於Prep的值,因此這裡的σ應該是個向量。不太可能所有樣本都共用一個高斯分佈引數。
。接著透過二分查詢來確定 xi 對應的σi,使得代入上面的兩個式子後等於Prep的值,因此這裡的σ應該是個向量。不太可能所有樣本都共用一個高斯分佈引數。

同時將低維空間兩個點的相互關係或者說相似程度也用聯合機率來表示,假設在低維空間中兩點間歐式距離服從一個自由度的學生t分佈,那麼在低維空間中兩個點的距離機率在所有的兩個點距離機率之中的比重作為它們的聯合機率。

假如在高維空間的 xi,xj 與對應在低維空間中的 zi,zj 算出來的相似性值 pij,qij 相等,那麼就說明低維空間的點能夠正確的反應高維空間中的相對位置關係。所以tsne的目的就是找到一組降維表示能夠最小化pij 和qij 之間的差值。因此,tsne採用了KullbackLeibler divergence即KL散度來構建標的函式 ,KL散度能夠用來衡量兩個機率分佈的差別。它透過梯度下降的方法來求輸入資料對應的低維表達 zi,即用標的函式對 zi 求導,把 zi 作為可最佳化變數,求得每次對 zi 的梯度為
,KL散度能夠用來衡量兩個機率分佈的差別。它透過梯度下降的方法來求輸入資料對應的低維表達 zi,即用標的函式對 zi 求導,把 zi 作為可最佳化變數,求得每次對 zi 的梯度為 ,然後更新迭代 zi ,在實際更新的過程中則像神經網路的更新一樣加入了momentum項為了加速最佳化,大概的演演算法流程如下:
,然後更新迭代 zi ,在實際更新的過程中則像神經網路的更新一樣加入了momentum項為了加速最佳化,大概的演演算法流程如下:
-
輸入:N個D維向量
,對映到二維或者三維,定值Perp,迭代次數T,學習率η,momentum項繫數α(t) -
輸出:降維後資料表示z1,…,zN
-
標的:降維到二維或者三維視覺化(重點是視覺化)
-
假設:在高維空間中,一個點 xj 的取值服從以另外一個點 xi 為中心的高斯分佈。在低維空間中,兩個點之間的歐式距離服從自由度為1的t分佈
-
1.先由二分查詢確定 xi 的σi
-
2.計算成對的$P{j|i},得到,得到p{ij} = (p{j|i}+p{i|j})/2$
-
3.初始化z1,…,zN
-
4.計算qij
-
5.計算梯度 ∂J/∂zi
-
6.更新

-
7.重覆4~6至收斂或者完成迭代次數T
需要註意的是,這個演演算法將低維資料作為變數進行迭代,所以如果需要加入插入新的資料,是沒有辦法直接對新資料進行操作,而是要把新資料加到原始資料中再重新算一遍,因此T-sne主要的功能還是視覺化。
3.7 DeepAutoencoder Networks
Autoencoder是神經網路的一種,它是一種無監督演演算法,可以用來降維也能用來從資料中自動學習某種特徵,這個神經網路的原理是輸入一組值,經過網路之後能夠獲得一組輸出,這組輸出的值盡可能的跟輸入的值大小一致。網路由全連線層組成,每層每個節點都跟上一層的所有節點連線。Autoencoder的結構如下圖4所示,encoder網路是正常的神經網路前向傳播z=W x+b,decoder網路的傳播引數是跟它成對稱結構的層引數的轉置,經過這個網路的值為 ,最後傳播到跟網路的輸入層個數相等的層時,得到一組值x′,網路希望這兩個值相等x′=x,這個值與真實輸入 x 值透過交叉熵或者均方誤差得到重構誤差的costfunction,再透過最小化這個cost和梯度下降的方法使網路學到正確的引數。因此可以透過這個網路先經過”encoder”網路將高維資料投影到低維空間,再經過”decoder”網路反向將低維資料還原到高維空間。
,最後傳播到跟網路的輸入層個數相等的層時,得到一組值x′,網路希望這兩個值相等x′=x,這個值與真實輸入 x 值透過交叉熵或者均方誤差得到重構誤差的costfunction,再透過最小化這個cost和梯度下降的方法使網路學到正確的引數。因此可以透過這個網路先經過”encoder”網路將高維資料投影到低維空間,再經過”decoder”網路反向將低維資料還原到高維空間。
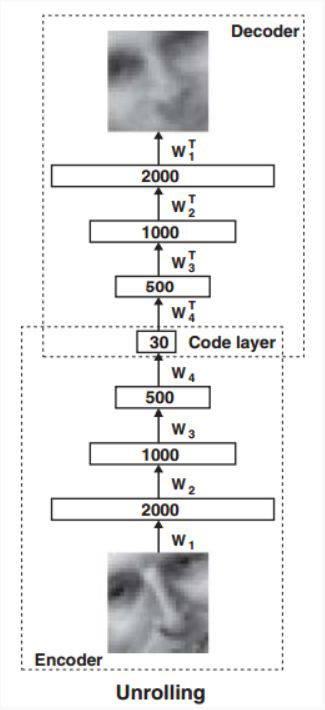
圖4 Autoencoder網路結構圖
然而在實際的實現網路過程中,整個網路實際上層數只是圖4中的一半,即4層網路,2000-1000-500-30的全連線結構。因為權重引數實際上在encoder和decoder中是相同的,enocoder過程是上一層的節點值乘以權重得到這一層的節點值,而decoder是這一層節點值與權重矩陣的轉置相乘得到上一層的節點值。下圖[7]更加清晰的展示了每一層實際的結構,包括一次前向傳播和後向傳播,因此可以拿最頂層的值作為網路的降維輸出來進行其他的分析,例如視覺化,或者作為壓縮特徵使用。
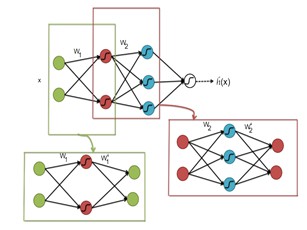
圖5 Autoencoder層間結構
06年的時候Hinton在science上發了一篇文章講如何用深度學習中的autoencoder網路來做降維[8],主要是提出了先透過多層RBM來預訓練權重引數,用來解決autoencoder降維後的質量依賴初始化網路權重的問題,即主要目的是提出一種有效的初始化權重的方式。上面的運算式中沒有加入非線性變換,真實網路中每一層跟權重做矩陣乘法之後還需要加上非線性變換。此外,autoencoder的模型中可以加入sparsity的性質[9],即針對N個D維輸入,某一層的某一個節點輸出值之和 趨近於0,即
趨近於0,即 ,其中l代表是哪一層,i代表是第幾個輸入。也能加對權重有要求的正則項。
,其中l代表是哪一層,i代表是第幾個輸入。也能加對權重有要求的正則項。
-
輸入:N個D維向量x1,…,xN,網路結構即每層節點數,迭代次數T,學習率η
-
輸出:降維後資料表示z1,…,zN
-
標的:網路能夠學習到資料內部的一些性質或者結構,從而能夠重構輸入資料
-
假設:神經網路就是特牛逼,就是能學到特徵,科科
-
1.設定層數和每一層節點數
-
2.初始化權重引數
-
3.前向傳播計算下一層的節點值z=W x+b
-
4.反向傳播計算上一層反向節點值
-
5.計算每一層對輸入和對這層引數W的梯度,利用反向傳播將error傳遞到整個網路
-
6.將分別對 W 和
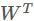 的梯度求和然後更新W
的梯度求和然後更新W -
7.重覆3~6至收斂或者完成迭代次數T
4.小結
本文主要重點放在演演算法流程是什麼,每一步具體做了什麼,有的地方可能理論闡述還不夠清晰。但是有意思的是除了t-sne和autoencoder之外,其他的幾種降維演演算法都是基於構造某個矩陣,然後對矩陣進行特徵值分解,得到相關的ZZ或者WW。Laplacian Eigenmaps拉普拉斯特徵對映沒有完整研究,但是看演演算法最後也是選擇前d個最小非零特徵值,這個很有意思,就是數學功底不好,暫時想不通為什麼基於特徵值的效果這麼好。而比較一層的autoencoder和PCA,假設autoencoder的標的函式是最小化均方誤差,雖然autoencoder沒有PCA那麼強的約束(要求每一維正交),但是autoencoder也許可以學到,因為本身基於最大化協方差的跡與最小均方差估計是等價的。幾種方法總是讓人感覺有著某些潛在的關聯,不知道是不是能夠提取出一種統一的模型能夠把降維這件事情給解決掉。
取用:
1.Data Preprocessing
2.Dimension Reduction: A Guided Tour
3.PCA的數學原理
4.A Tutorial on Data Reduction Linear Discriminant Analysis (LDA)
5.manifold learning with applications to object recognition
5.Visualizing Data using t-SNE
7.A Tutorial on Deep Learning Part 2: Autoencoders, Convolutional Neural Networks and Recurrent Neural Networks
8.Reducing the Dimensionality of Data with Neural Networks
8.CS294A Lecture notes Sparse autoencoder
【關於投稿】
如果大家有原創好文投稿,請直接給公號傳送留言。
① 留言格式:
【投稿】+《 文章標題》+ 文章連結
② 示例:
【投稿】《不要自稱是程式員,我十多年的 IT 職場總結》:
http://blog.jobbole.com/94148/
③ 最後請附上您的個人簡介哈~
覺得本文有幫助?請分享給更多人
關註「演演算法愛好者」,修煉程式設計內功

