作者:丨像我這樣的人丨
來自:https://www.jianshu.com/p/e386f549d17a
爐石傳說原畫連結:http://news.4399.com/gonglue/lscs/kptj/
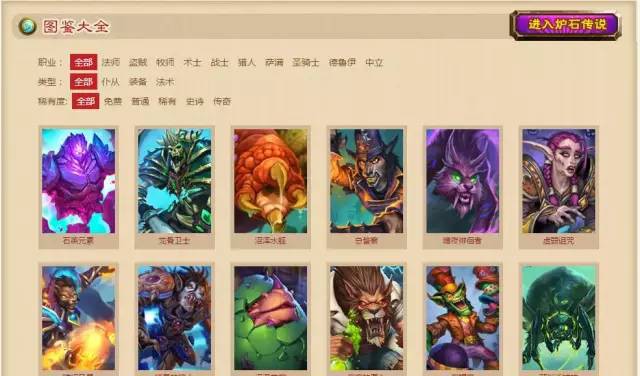

該網站透過點選檢視更多載入新的內容
本打算使用Selenium模擬點選獲取圖片資訊
嘗試發現原始碼中 該按鈕並無相應的跳轉連結

這不應該啊 沒有相應的跳轉連結 點選後是如何載入新的圖片?
後來瀏覽整體網站原始碼後 發現把問題想複雜 根本不需要模擬點選檢視更多

網站其實已經載入了所有的卡牌原畫 只是之後的原畫做了隱藏處理預設不展示 style=display
點選檢視更多後 顯示原畫
那麼只需使用requests獲取網頁原始碼
用BeautiSoup/正則運算式/pyQuery解析元素 遍歷相應img的url 即可下載
教訓:爬蟲前 不要根據網頁所對的操作實施相應的程式碼爬取 不要有這樣的思維定式 首先要做的是先大體瀏覽分析整個網頁的原始碼 有的可能直接寫在原始碼或json或js中 無需再加工
爐石傳說卡牌連結:http://cha.17173.com/hs/
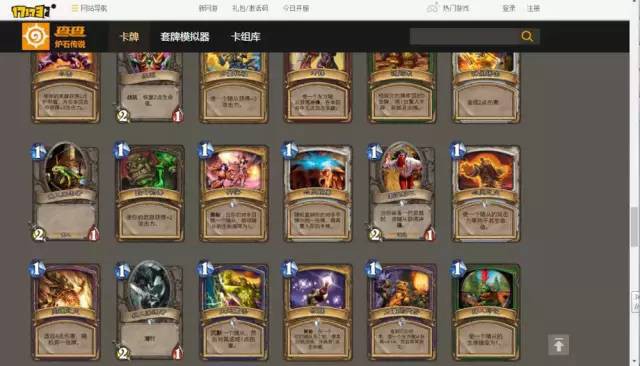
該網站透過下拉右邊的捲軸不斷載入新的卡牌
與上一個網站不同 上一個網站一次性寫入了所有卡牌 只不過做了隱藏處理
該網站是透過js動態載入渲染出的卡牌 直接獲取原始碼 無法得到所有卡牌資訊
那麼就用selenium模擬下拉捲軸(selenium簡直居家必備之神器)
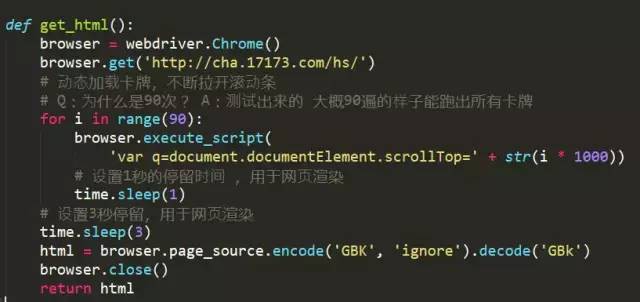
使用selenium執行js指令碼 每次執行下拉1000個單位捲軸 執行90次
為什麼是90次 測試出來的 大概90次拉到底
註意:這裡要增加1~3秒的暫停時間 用於網頁渲染
第一次沒有設定停留時間 無法獲取新的資料 懷疑自己 懷疑人生
經前端/後端好友L君的提示 需增加暫停時間 這樣才能獲得載入渲染後的資料
browser.page_source便可獲得動態載入的所有資料
有了資料 之後就很簡單 正則匹配獲取相應url下載即可
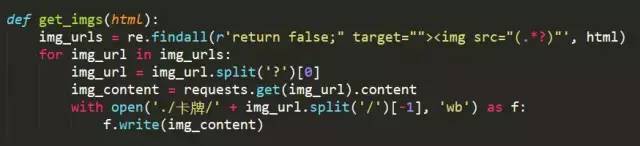
最後獲得了800張原畫 1324張卡牌


既然獲得了這麼多卡牌和原畫 不能浪費 利用起來 拼圖!
致敬下玩了好幾年的爐石


順手拼一下女神


完畢!
原始碼獲取地址:https://github.com/sadjjk/Hearth-Stone-Spider
玩過這款遊戲的點個贊?
●編號514,輸入編號直達本文
●輸入m獲取文章目錄

Web開發
更多推薦《18個技術類微信公眾號》
涵蓋:程式人生、演演算法與資料結構、駭客技術與網路安全、大資料技術、前端開發、Java、Python、Web開發、安卓開發、iOS開發、C/C++、.NET、Linux、資料庫、運維等。
