(點選上方公眾號,可快速關註)
來源:melonstreet ,
www.cnblogs.com/QG-whz/p/9636366.html
JVM的記憶體區域是怎麼劃分的?
JVM的記憶體劃分中,有部分割槽域是執行緒私有的,有部分是屬於整個JVM行程;有些區域會丟擲OOM異常,有些則不會,瞭解JVM的記憶體區域劃分以及特徵,是定位線上記憶體問題的基礎。那麼JVM記憶體區域是怎麼劃分的呢?
首先是程式計數器(Program Counter Register),在JVM規範中,每個執行緒都有自己的程式計數器。這是一塊比較小的記憶體空間,儲存當前執行緒正在執行的Java方法的JVM指令地址,即位元組碼的行號。如果正在執行Native方法,則這個計數器為空。該記憶體區域是唯一一個在Java虛擬機器規範中沒有規定任何OOM情況的記憶體區域。
第二,Java虛擬機器棧(Java Virtal Machine Stack),同樣也是屬於執行緒私有區域,每個執行緒在建立的時候都會建立一個虛擬機器棧,生命週期與執行緒一致,執行緒退出時,執行緒的虛擬機器棧也回收。虛擬機器棧內部保持一個個的棧幀,每次方法呼叫都會進行壓棧,JVM對棧幀的操作只有出棧和壓棧兩種,方法呼叫結束時會進行出棧操作。
該區域儲存著區域性變數表,編譯時期可知的各種基本型別資料、物件取用、方法出口等資訊。
第三,本地方法棧(Native Method Stack)與虛擬機器棧類似,本地方法棧是在呼叫本地方法時使用的棧,每個執行緒都有一個本地方法棧。
第四,堆(Heap),幾乎所有建立的Java物件實體,都是被直接分配到堆上的。堆被所有的執行緒所共享,在堆上的區域,會被垃圾回收器做進一步劃分,例如新生代、老年代的劃分。Java虛擬機器在啟動的時候,可以使用“Xmx”之類的引數指定堆區域的大小。
第五,方法區(Method Area)。方法區與堆一樣,也是所有的執行緒所共享,儲存被虛擬機器載入的元(Meta)資料,包括類資訊、常量、靜態變數、即時編譯器編譯後的程式碼等資料。這裡需要註意的是執行時常量池也在方法區中。根據Java虛擬機器規範的規定,當方法區無法滿足記憶體分配需求時,將丟擲OutOfMemoryError異常。由於早期HotSpot JVM的實現,將CG分代收集拓展到了方法區,因此很多人會將方法區稱為永久代。Oracle JDK8中已永久代移除永久代,同時增加了元資料區(Metaspace)。
第六,執行時常量池(Run-Time Constant Pool),這是方法區的一部分,受到方法區記憶體的限制,當常量池無法再申請到記憶體時,會丟擲OutOfMemoryError異常。
在Class檔案中,除了有類的版本、方法、欄位、介面等描述資訊外,還有一項資訊是常量池。每個Class檔案的頭四個位元組稱為Magic Number,它的作用是確定這是否是一個可以被虛擬機器接受的檔案;接著的四個位元組儲存的是Class檔案的版本號。緊挨著版本號之後的,就是常量池入口了。常量池主要存放兩大類常量:
-
字面量(Literal),如文字字串、final常量值
-
符號取用,存放了與編譯相關的一些常量,因為Java不像C++那樣有連線的過程,因此欄位方法這些符號取用在執行期就需要進行轉換,以便得到真正的記憶體入口地址。
class檔案中的常量池,也稱為靜態常量池,JVM虛擬機器完成類裝載操作後,會把靜態常量池載入到記憶體中,存放在執行時常量池。
第七,直接記憶體(Direct Memory),直接記憶體並不屬於Java規範規定的屬於Java虛擬機器執行時資料區的一部分。Java的NIO可以使用Native方法直接在java堆外分配記憶體,使用DirectByteBuffer物件作為這個堆外記憶體的取用。
下麵這張圖,反映了執行中的Java行程記憶體佔用情況:

OOM可能發生在哪些區域上?
根據javadoc的描述,OOM是指JVM的記憶體不夠用了,同時垃圾收集器也無法提供更多的記憶體。從描述中可以看出,在JVM丟擲OutOfMemoryError之前,垃圾收集器一般會出馬先嘗試回收記憶體。
從上面分析的Java資料區來看,除了程式計數器不會發生OOM外,哪些區域會發生OOM的情況呢?
第一,堆記憶體。堆記憶體不足是最常見的傳送OOM的原因之一,如果在堆中沒有記憶體完成物件實體的分配,並且堆無法再擴充套件時,將丟擲OutOfMemoryError異常,丟擲的錯誤資訊是“java.lang.OutOfMemoryError:Java heap space”。當前主流的JVM可以透過-Xmx和-Xms來控制堆記憶體的大小,發生堆上OOM的可能是存在記憶體洩露,也可能是堆大小分配不合理。
第二,Java虛擬機器棧和本地方法棧,這兩個區域的區別不過是虛擬機器棧為虛擬機器執行Java方法服務,而本地方法棧則為虛擬機器使用到的Native方法服務,在記憶體分配異常上是相同的。在JVM規範中,對Java虛擬機器棧規定了兩種異常:1.如果執行緒請求的棧大於所分配的棧大小,則丟擲StackOverFlowError錯誤,比如進行了一個不會停止的遞迴呼叫;2. 如果虛擬機器棧是可以動態拓展的,拓展時無法申請到足夠的記憶體,則丟擲OutOfMemoryError錯誤。
第三,直接記憶體。直接記憶體雖然不是虛擬機器執行時資料區的一部分,但既然是記憶體,就會受到物理記憶體的限制。在JDK1.4中引入的NIO使用Native函式庫在堆外記憶體上直接分配記憶體,但直接記憶體不足時,也會導致OOM。
第四,方法區。隨著Metaspace元資料區的引入,方法區的OOM錯誤資訊也變成了“java.lang.OutOfMemoryError:Metaspace”。對於舊版本的Oracle JDK,由於永久代的大小有限,而JVM對永久代的垃圾回收並不積極,如果往永久代不斷寫入資料,例如String.Intern()的呼叫,在永久代佔用太多空間導致記憶體不足,也會出現OOM的問題,對應的錯誤信為“java.lang.OutOfMemoryError:PermGen space”

堆記憶體結構是怎麼樣的?
可以藉助一些工具來瞭解JVM的記憶體內容,具體到特定的記憶體區域,應該用什麼工具去定位呢?
-
圖形化工具。圖形化工具的優點是直觀,連線到Java行程後,可以顯示堆記憶體、堆外記憶體的使用情況,類似的工具有JConsole,VisualVm等。
-
命令列工具。這類工具可以在執行時進行查詢,包括jstat,jmap等,可以對堆記憶體、方法區等進行檢視。定位線上問題時也多會使用這些工具。jmap也可以生成堆轉儲檔案(Heap Dump)檔案,如果是在linux上,可以將堆轉儲檔案拉到本地來,使用Eclipse MAT進行分析,也可以使用jhap進行分析。
關於記憶體的監控與診斷,在後面會進行深入瞭解。現在來看下一個問題:堆內的結構是怎麼的呢?
站在垃圾收集器的角度來看,可以把記憶體分為新生代與老年代。記憶體的分配規則取決於當前使用的是哪種垃圾收集器的組合,以及記憶體相關的引數配置。往大的方向說,物件優先分配在新生代的Eden區域,而大物件直接進入老年代。
第一, 新生代的Eden區域,物件優先分配在該區域,同時JVM可以為每個執行緒分配一個私有的快取區域,稱為TLAB(Thread Local Allocation Buffer),避免多執行緒同時分配記憶體時需要使用加鎖等機制而影響分配速度。TLAB在堆上分配,位於Eden中。TLAB的結構如下:
// ThreadLocalAllocBuffer: a descriptor for thread-local storage used by
// the threads for allocation.
// It is thread-private at any time, but maybe multiplexed over
// time across multiple threads. The park()/unpark() pair is
// used to make it avaiable for such multiplexing.
class ThreadLocalAllocBuffer: public CHeapObj
{ friend class VMStructs;
private:
HeapWord* _start; // address of TLAB
HeapWord* _top; // address after last allocation
HeapWord* _pf_top; // allocation prefetch watermark
HeapWord* _end; // allocation end (excluding alignment_reserve)
size_t _desired_size; // desired size (including alignment_reserve)
size_t _refill_waste_limit; // hold onto tlab if free() is larger than this
從本質上來說,TLAB的管理是依靠三個指標:start、end、top。start與end標記了Eden中被該TLAB管理的區域,該區域不會被其他執行緒分配記憶體所使用,top是分配指標,開始時指向start的位置,隨著記憶體分配的進行,慢慢向end靠近,當撞上end時觸發TLAB refill。因此記憶體中Eden的結構大體為:

第二、新生代的Survivor區域。當Eden區域記憶體不足時會觸發Minor GC,也稱為新生代GC,在Minor GC存活下來的物件,會被覆制到Survivor區域中。我認為Survivor區的作用在於避免過早觸發Full GC。如果沒有Survivor,Eden區每進行一次Minor GC都把物件直接送到老年代,老年代很快便會記憶體不足引發Full GC。新生代中有兩個Survivor區,我認為兩個Survivor的作用在於提高效能,避免記憶體碎片的出現。在任何時候,總有一個Survivor是empty的,在發生Minor GC時,會將Eden及另一個的Survivor的存活物件複製到該empty Survivor中,從而避免記憶體碎片的產生。新生代的記憶體結構大體為:

第三、老年代。老年代放置長生命週期的物件,通常是從Survivor區域複製過來的物件,不過當物件過大的時候,無法在新生代中用連續記憶體的存放,那麼這個大物件就會被直接分配在老年代上。一般來說,普通的物件都是分配在TLAB上,較大的物件,直接分配在Eden區上的其他記憶體區域,而過大的物件,直接分配在老年代上。
第四、永久代。如前面所說,在早起的Hotspot JVM中有老年代的概念,老年代用於儲存Java類的元資料、常量池、Intern字串等。在JDK8之後,就將老年代移除,而引入元資料區的概念。
第五、Vritual空間。前面說過,可以使用Xms與Xmx來指定堆的最小與最大空間。如果Xms小於Xmx,堆的大小不會直接擴充套件到上限,而是留著一部分等待記憶體需求不斷增長時,再分配給新生代。Vritual空間便是這部分保留的記憶體區域。
那麼綜上所述,可以畫出Java堆內的記憶體結構大體為:

透過一些引數,可以來指定上述的堆記憶體區域的大小:
-
-Xmx value 指定最大的堆大小
-
-Xms value 指定初始的最小堆大小
-
-XX:NewSize = value 指定新生代的大小
-
-XX:NewRatio = value 老年代與新生代的大小比例。預設情況下,這個比例是2,也就是說老年代是新生代的2倍大。老年代過大的時候,Full GC的時間會很長;老年代過小,則很容易觸發Full GC,Full GC頻率過高,這就是這個引數會造成的影響。
-
-XX:SurvivorRation = value . 設定Eden與Srivivor的大小比例,如果該值為8,代表一個Survivor是Eden的1/8,是整個新生代的1/10。
常用的效能監控與問題定位工具有哪些?
在系統的效能分析中,CPU、記憶體與IO是主要的關註項。很多時候服務出現問題,在這三者上會體現出現,比如CPU飆升,記憶體不足發生OOM等,這時候需要使用對應的工具,來對效能進行監控,對問題進行定位。
對於CPU的監控,首先可以使用top命令來進行檢視,下麵是使用top檢視負載的一個截圖:

load average 代表1分鐘、5分鐘、15分鐘的系統平均負載,從這三個數字,可以判斷系統負荷是大還是小。當CPU完全空閑的時候,平均負荷為0;當CPU工作量飽和的時候,平均負荷為1。因此 load average 這三個數值越低,代表系統負荷越小,那麼什麼時候能看出系統負荷比較重呢?這篇文章(Understanding Linux CPU Load – when should you be worried)裡解釋得非常通俗。如果電腦裡只有一個CPU,把CPU看成一條單行橋,橋上只有一個車道,所有的車都必須從這個橋上透過。那麼
系統負荷為0,代表橋上一輛車也沒有

系統負荷0.5,意味著橋上一半路段上有車

系統負荷1,意味著橋上道路已經被車佔滿

系統負荷1.7,代表著在橋上車子已經滿了(100%),同時還有70%的車子在等待從橋上透過:

從top命令的截圖中可以看到這三個值機器的load average非常低。如果這三個值非常高,比如超過了50%或60%,就應當引起註意。從時間維度上來說,如果發現CPU負荷慢慢升高,也需要警惕。
其他的記憶體、CPU等效能監控工具的使用,以一張腦圖來展示:
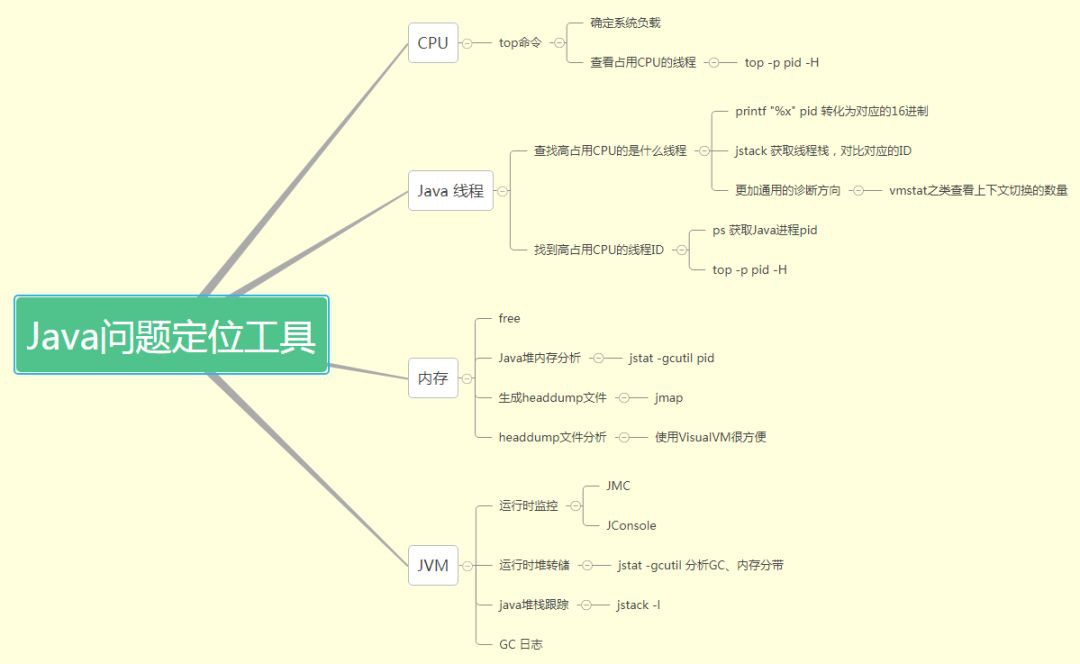
具體的使用方式可以參考從一次線上故障思考Java問題定位思路。
參考
-
《深入理解Java虛擬機器》
-
https://www.cnblogs.com/dreamroute/p/5946272.html
-
https://docs.oracle.com/javase/specs/jvms/se9/html/jvms-2.html#jvms-2.5
-
https://www.cnblogs.com/Kidezyq/p/8040338.html
-
https://www.cnblogs.com/baihuitestsoftware/articles/6405580.html
-
https://www.jianshu.com/p/cd85098cca39
-
http://www.ruanyifeng.com/blog/2011/07/linux_load_average_explained.html
【關於投稿】
如果大家有原創好文投稿,請直接給公號傳送留言。
① 留言格式:
【投稿】+《 文章標題》+ 文章連結
② 示例:
【投稿】《不要自稱是程式員,我十多年的 IT 職場總結》:http://blog.jobbole.com/94148/
③ 最後請附上您的個人簡介哈~
看完本文有收穫?請轉發分享給更多人
關註「ImportNew」,提升Java技能

