作者:彭雨露
來源:Yura不說資料說(ID:Data_tells_U)

坦白說,看前幾部電影的時候,我一直在想“到底放不放阿信的歌啊?什麼時候放啊?”,那看《飛馳人生》的時候,直到影片結束片尾曲《一半人生》響起的時候,我才記起來,哦,之前我是為了這首歌才看的這部電影。

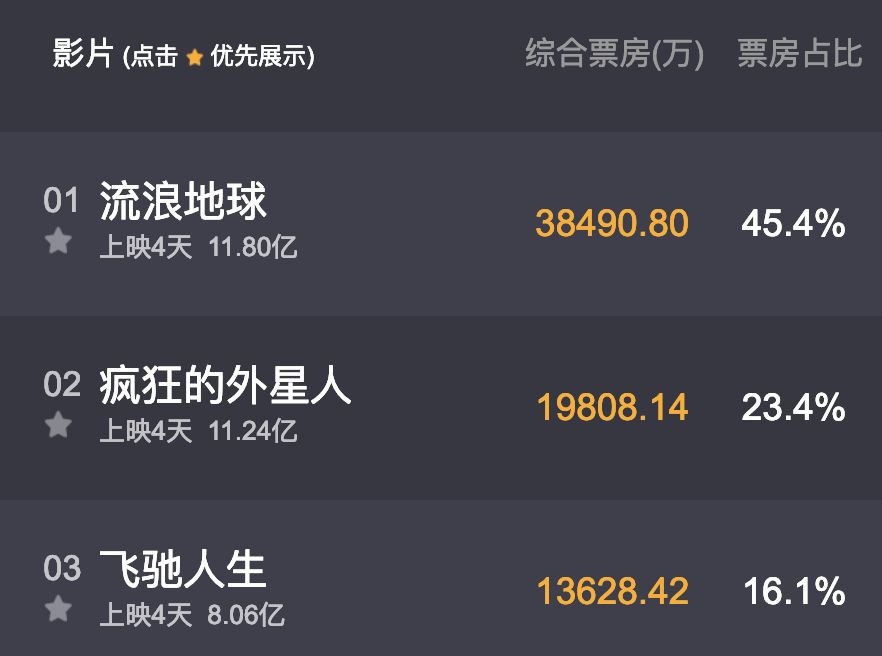
01 資料爬取
其實我一開始是想用豆瓣網的評論的,但是我翻了翻吧,發現“最熱評論”只能看到500條,“最新評論”只能顯示100條,拿600條資料能分析出個啥?

百度了一下,看大家都是用貓眼評論,於是就……爬貓眼!
網頁版的貓眼只能顯示有限的評論,切換到APP版本才能看到所有評論。

找network裡面的網頁也不難,隨便拿一條評論搜尋一下就可以找到?

Crtl+F

關鍵是找到不同網頁之間的變化規律(要不是我在這上面栽了跟頭,初三就能寫完這篇文章了……?)



有些網址,錶面看上去,區別就是在於offset(偏移量),但是實際上更改這個數值到1005的時候就爬不到東西了(可能是由於網頁內部的設定吧),就是說這麼下去我們只能得到1000條評論。
那是哪1000條評論呢?我們看到網址中有個關鍵詞“ts=1549640420581”,其實就是當前時間的意思(時間戳),轉化一下就是:

所以1000條就是從這個時間點,往前偏移15條後,最新的1000條評論。
透過百度各位大神的爬蟲過程,我發現終極解決方法就是更改ts的值!如果說偏移量15的意思是從這個查詢的時間往前偏移15條再取得15條評論資料(limit=15),那麼我們每次更改ts值不就可以了。
第一個ts值是程式開始執行的時間,第二個值就從已經獲取的評論資料中拿到最早的那個資料,以此不斷往前翻滾……
我爬取了2月8日24點之前的所有評論資訊,按app顯示此時至少有80000+條資料,但是我爬下來總共只有4w+條…資料缺失還是比較嚴重的。

資料格式如下(包括使用者id、使用者暱稱、使用者貓眼等級、性別、時間、評分、評論內容、點贊數和評論數):
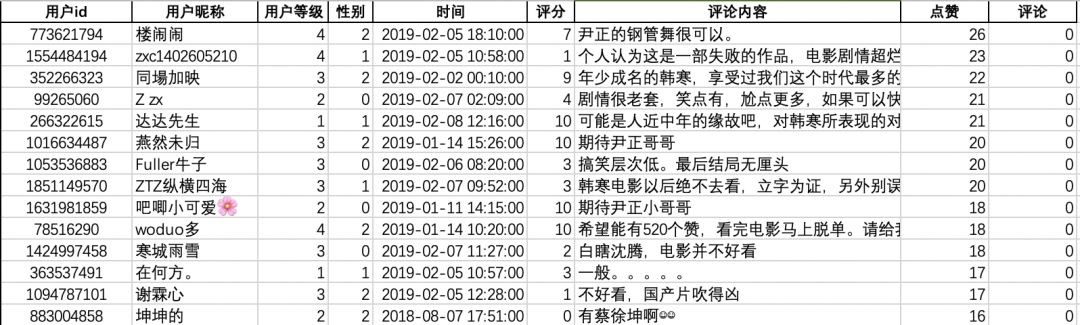

這些都是在json裡面,格式非常清晰明瞭。


02 資料清洗
拿到資料除了做詞雲用了python(程式碼在最後),其他的內容Excel分分鐘解決,這裡尤其感謝發明“資料透視表”的兄弟。

03 資料分析
1. 觀眾資訊

男女比例各佔一半,男的對賽車這類刺激性東西感興趣可以理解,這女觀眾都是為了啥?為了黃景瑜小哥哥的臉?還是像我一樣衝著阿信來的?這裡資訊太少,我只做少量胡思亂猜。

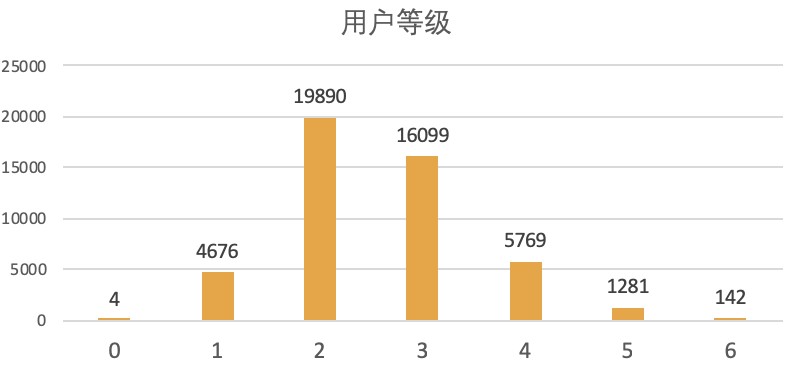
使用者等級又是類似於正態分佈的形狀,巧的嘞……其中0分和1分的使用者(可以認定為新註冊使用者)僅佔9.78%,可以看出評分的人中水軍是很少的,基本都是貓眼老使用者。
再看看這4天使用者評價數量的變化:

基本可得這部電影熱度呈現緩慢下降的趨勢(但是由於資料的不完整性,不能絕對說明)。
那使用者都喜歡在什麼時間評論呢?
對比看四天的評論hour資料:
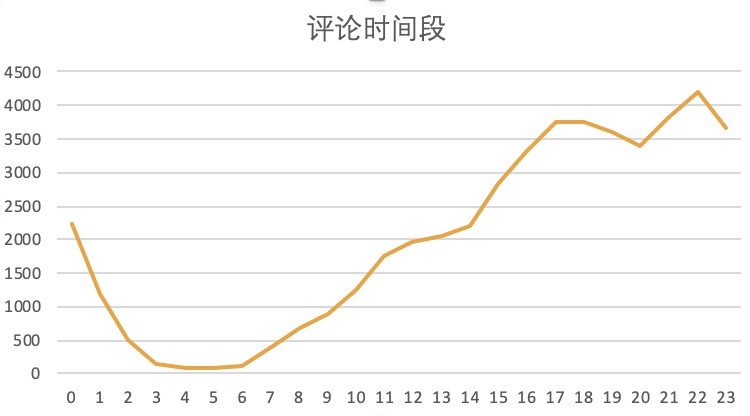
如果大家習慣看完電影馬上評價的話,那麼從評論趨勢來看,從中午12點之後評論數逐漸增加,推測是由於早上10點左右那場電影的結束。隨後評論數不斷增加,在晚飯前的5、6點和睡覺前的23點左右達到小高峰。嗯,非常符合大家“醒了看電影,看完吃飯,吃了再看,看了再睡”的“節假日生活作息”。

2. 評分情況

按照我爬取的資料我們看到超過一半(52.37%)的觀眾給這部電影打了滿分10分,極少量使用者評分在6分以下(僅佔7.58%)。根據我爬取的資料,計算所得平均分是8.725,和實時顯示的分數8.8相差不大。

除了從宏觀角度看評分,我們來瞧瞧評論者性別和評論時間與最終評分有什麼不能說的秘密?

性別的不同並沒有造成評分很大的區別,男觀眾和女觀眾的評分平均分僅僅相差0.35分,“未知性別”人群的評分在兩者之間,基本等於男性評分8.53和女性評分8.88的的平均值(8.71)。嗯,我很有理由懷疑“未知人群”中男女比例也各佔一半!

從評分時間和評分的關係來看,低分一般出現在0點到7點之間,我猜吧,大概是在這種夜深人靜的時候,大家的情緒容易有大起大落,白天看完電影時的興奮已經退去,留下的只有深深的思考,或許還帶點批判性,吧。

3. 評論內容
先看看點贊數最高的5條評論。

我們發現前5條評論評分均為10分:其中第一條,emmm,與電影無關,暫時跳過。其他幾條都是贊美韓寒、沈騰和黃景瑜的。
那透過詞雲具體看一下評論內容:


從詞雲圖中可以看出:
-
出現頻率最高的是“好看”“不錯”“喜歡”,說明觀眾對《飛馳人生》的整體評價是很不錯的。
-
“韓寒”“沈騰”或是該片最大贏家,評論中對他們的名字提到多次;“黃景瑜”“尹正”作為相對名氣較小的演員,在此片中的表現也不遜其他人:尹正飾演的宇強說得了中二臺詞、跳得了性感鋼管舞,能給張弛帶來當頭一棒的警醒,也是一直在他身後的精神支柱;黃景瑜飾演的林臻東人設完美,簡直是所有女孩的理想型:多金、高顏值、優秀而又謙遜,愛了愛了。
-
從劇情來看,“勵志”“搞笑”“熱血”“夢想”這些詞語也說明這是一部超燃的電影,裡面有一句臺詞“不是非得贏,我只是不想輸”,夠中二吧?但也夠熱血。
-
詞雲裡面另一個高頻詞是“結局”(“結尾”),影片的最後張弛因為不能及時剎車沖向了落日,彩蛋裡面卻出現了他與兒子同學的飛行員爸爸比賽的場景。隨著兒子的投幣,場景一轉,浮現了“Heroes never die”,“英雄不朽”,張弛永遠地活在了他兒子的心中。另:巴音布魯克草原在新疆,哪兒有海?

04 不成熟的程式碼
1. 爬取評論
1from bs4 import BeautifulSoup
2import requests
3import warnings
4import re
5from datetime import datetime
6import json
7import random
8import time
9import datetime
10
11
12
13essay-headers = {
14 ‘User-Agent’: ‘Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1’,
15 ‘Connection’:‘keep-alive’}
16cookies={‘cookie’:‘_lxsdk_cuid=168c325f322c8-0156d0257eb33d-10326653-13c680-168c325f323c8; uuid_n_v=v1; iuuid=30E9F9E02A1911E9947B6716B6E91453A6754AA9248F40F39FBA1FD0A2AD9B42; webp=true; ci=191%2C%E5%8F%B0%E5%B7%9E; _lx_utm=utm_source%3DBaidu%26utm_medium%3Dorganic; __mta=49658649.1549462270794.1549465778684.1549548206227.3; _lxsdk=30E9F9E02A1911E9947B6716B6E91453A6754AA9248F40F39FBA1FD0A2AD9B42; _lxsdk_s=168c898414e-035-f0e-e6%7C%7C463’}
17
18#url設定offset偏移量為0
19url = ‘http://m.maoyan.com/review/v2/comments.json?movieId=1218091&userId;=-1&offset;=0&limit;=15&ts;={}&type;=3’
20
21comment=[]
22nick=[]
23score=[]
24comment_time=[]
25gender=[]
26userlevel=[]
27userid=[]
28upcount=[]
29replycount=[]
30ji=1
31
32
33url_time=url_time=int(time.time())*1000#獲取當前時間(單位是毫秒,所以要✖️1000)
34
35for i in range(2000):
36 value=15*i
37 url_range=url.format(url_time)
38 res=requests.get(url_range,essay-headers=essay-headers,cookies=cookies,timeout=10)
39 res.encoding=‘utf-8’
40 print(‘正在爬取第’+str(ji)+‘頁’)
41 content=json.loads(res.text,encoding=‘utf-8’)
42 list_=content[‘data’][‘comments’]
43 count=0
44 for item in list_:
45 comment.append(item[‘content’])
46 nick.append(item[‘nick’])
47 score.append(item[‘score’])
48 comment_time.append(datetime.datetime.fromtimestamp(int(item[‘time’]/1000)))
49 gender.append(item[‘gender’])
50 userlevel.append(item[‘userLevel’])
51 userid.append(item[‘userId’])
52 upcount.append(item[‘upCount’])
53 replycount.append(item[‘replyCount’])
54 count=count+1
55 if count==15:
56 url_time=item[‘time’]
57 ji+=1
58 time.sleep(random.random())
59print(‘爬取完成’)
60print(url_time)
61result={‘使用者id’:userid,‘使用者暱稱’:nick,‘使用者等級’:userlevel,‘性別’:gender,‘時間’:comment_time,‘評分’:score,‘評論內容’:comment,‘點贊’:upcount,‘評論’:replycount}
62results=pd.DataFrame(result)
63results.info()
64results.to_excel(‘貓眼_飛馳人生.xlsx’)
2. 畫詞雲
1import pandas as pd
2import numpy as np
3import re
4import jieba
5import wordcloud
6import matplotlib.pyplot as plt
7from collections import Counter
8from PIL import Image
9jieba.load_userdict(“new.txt”) #新定義詞典
10df=pd.read_excel(‘貓眼_飛馳人生.xlsx’)
11
12comments=str()
13for comment in df[‘評論內容’]:
14 comments=comments+comment
15
16stopwords = {}.fromkeys([ line.rstrip() for line in open(‘stopwords.txt’) ])
17segs = jieba.cut(comments,cut_all=False)
18
19cloud_text =[]
20for seg in segs:
21 if seg not in stopwords:
22 cloud_text.append(seg)
23
24fre= Counter(cloud_text)
25
26mask = np.array(Image.open(‘d.jpeg’)) # 定義詞頻背景
27wc = wordcloud.WordCloud(
28 font_path=‘Hiragino Sans GB.ttc’, # 設定字型格式
29 mask=mask, # 設定背景圖
30 max_words=150, # 最多顯示詞數
31 max_font_size=150 # 字型最大值
32)
33
34wc.generate_from_frequencies(fre) # 從字典生成詞雲
35image_colors = wordcloud.ImageColorGenerator(mask) # 從背景圖建立顏色方案
36wc.recolor(color_func=image_colors) # 將詞雲顏色設定為背景圖方案
37plt.imshow(wc) # 顯示詞雲
38plt.axis(‘off’) # 關閉坐標軸
39plt.show() # 顯示影象
40wc.to_file(‘comment_pic.png’)
05 最後的最後

沒看電影的大家抓住假期的尾巴去瞧一瞧,電影很精彩,片尾曲《一半人生》也很好聽哦!

下麵是我看完電影當晚做的影評手賬?

關於作者:Yura,電腦科學與技術專業大四在讀,因在澳洲交換學習接觸了大資料,甚感興趣。遂開公眾號“Yura不說資料說”督促自己學習資料分析!歡迎大家關註我的個人公眾號,一起(監督我)學習。

