王國梁
目前任職於美團雲端計算部門,負責雲平臺資源排程系統和 Go 相關係統設計和效能最佳化;曾任職於奇虎360主要在從事高效能中介軟體產品的開發和效能最佳化。Go 語言重度使用者,開原始碼質量評估工具 Goreporter 的作者,曾上過 Github 周最熱開源專案,目前2000+star;知乎專欄——進擊的 Golang,是關註人數最多的 Go 相關專欄;熱愛開源和分享,目前是 Kubernetes member 及多個著名開源專案 contributor。
前言
今天的演講主要內容是就 GO 語言中怎麼透過程式碼分析驅動程式碼質量與大家做一些分享交流。我目前在美團的雲端計算部門任職,主要負責雲平臺資源的排程和 go 語言的效能最佳化問題,曾經在360做過一些中介軟體的開發。寫過一個開源專案 goreporter,透過分析程式碼生成程式碼質量的報告,可以對我們的程式碼有整體的瞭解。現在360的一些研發部門主要是在用它做一些程式碼的 review 工作,而在美團這邊則是被資訊保安部門用作程式碼安全審計的工具。現在我在開源方面主要在做 Kubernetes 排程開發以及效能最佳化工作,另外,我會經常在知乎專欄(進擊的Golang)上也寫一些 golang 相關的文章,大家有興趣可以看一下。
今天的演講分為四個部分,第一是討論下開發效率與程式碼質量他們之間的關係以及我們為什麼放棄質量,第二是程式碼分析技術的一些簡單介紹,其次是如何在 go 語言中實現程式碼分析工具,最後是一些總結和心得體會。
開發效率與程式碼質量
我們先來講講開發效率與程式碼質量。首先我想問一下大家,在寫程式碼的過程中有多少部門或者組內做過 review?很少。那麼為什麼我們不關註程式碼質量呢?我想,有很多原因,或許是我們自身開發習慣,也可能是團隊開發氛圍的問題,導致我們一味追求開發速度,不去考慮我們寫的程式碼的質量到底是如何。我們自己也可能懶得重新再去看之前寫過的程式碼或者重新思考我們之前寫過的程式碼,甚至不知道怎麼改我們的程式碼、不知道怎麼寫比較好。
這些問題導致我們一直在放棄程式碼質量,但是我們為什麼會選擇放棄程式碼質量?因為那需要太多時間精力,也會拖慢研發的進度,主觀感受是這樣的。但是從另外一個方面考慮,就是我們怎麼能夠降低我們去追求程式碼質量的代價?我們可以藉助一些工具,讓機器幫我們做一些程式碼 review 或者有一些自動化的建議,我們透過程式碼工具做一些程式碼的審核,比如說我們可以統一程式碼風格,在 go 語言中我們大家都瞭解gofmt,也可以透過工具程式碼分析,分析程式碼中的缺陷,或者根據程式碼給出一些更好的最佳化建議或者是評估程式碼可維護性有多高,程式碼是不是對後期的維護更加的友好等等。我們都可以透過工具實現這些功能,這就減少了我們在人力時間上的花費。
程式碼分析技術
那麼我們又該如何去實現這些功能?透過程式碼分析技術。
程式碼分析中五種常見技術
一、詞法分析,在語言內部的標記序列,怎麼把字元定義為是一個標記還是關鍵字或是操作等等。
二、語法分析,我們既然得到了這些標記,還可以把這些標記進行型別上的檢查。
三、語意分析,我們的每一行程式碼,或者是每一個標識,它的一些背景關係的關係,是否符合語意上的規則。
四、控制流分析,透過指令得到控制流圖。
五、資料流分析,比如我們想檢視一些熱點資料,對一些資料的分析等等。
靜態和動態分析
靜態和動態分析有很大的區別,它們之間有很明顯的特點可以區分,靜態分析是分析原始碼的結構,主要是做一些程式碼的檢查驗證分析,動態分析其實就是分析平時的一些資料,比如我們經常使用的追蹤技術等等之類的,而靜態分析就是我們做的 linter 之類的相關工具。
在go語言中進行程式碼分析
它的主要優勢一個是靜態型別,還有就是語法更加簡單,比動態的特性更簡單,同時,它的標準庫直接支援了程式碼分析的一些包。
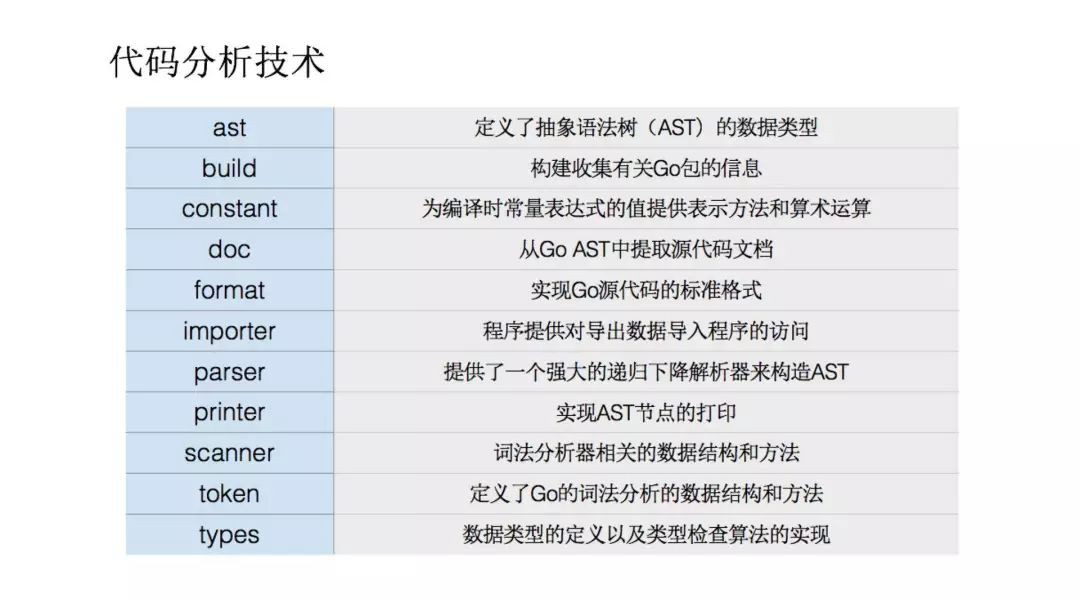
在 原始碼中go 目錄下的一些包,第一個 ast,一些資料結構和型別都在這裡定義。 build 是構建收集有關30包的資訊,constant 是一些常用的常量表達方法,doc 是 go 語言提取原始碼的檔案,goastformat 它是實現原始碼的標準格式,importer 是程式提供了對匯入資料程式的一些訪問,parser 是提供了一個遞迴下降的構造 ast,相當於遍歷。printer 可以直接支援 ast 節點,scanner 主要是測碼分析器的一些資料和方法,token 定義測碼分析的資料結構,還有types主要定義資料型別和實現型別檢查的演演算法。這些都是程式碼分析的基礎工具,在 GO的標準庫下已經給我們提供。
從上層角度來看,程式碼分析可以分為幾個比較抽象的概念,比如程式碼解析(怎麼去從我們的原始碼中解析出來,再去分析一些基本的資料),型別檢查,語法分析以及指標分析。

1、程式碼的解析
第一步是我們要從原始碼中去解析出所有的 tokens,也就是我們說的識別符號,可以透過 go/scanner 和 go/token來實現;第二步是透過tokens來構建ast(抽象語法樹),可以透過go/parser和go/ast實現;然後,既然我們得到了ast我們就可以驗證下token之間的關係,透過go/types和go/constant來對token進行檢查;後面我們就可以根據自己的需要對ast進行分析,以及分析我們關註的所有與ast和節點相關的程式碼資料。

我們來看一塊簡單的程式碼,把它標識為不同型別token後會發現有五種型別:(只有四個),藍色的是關鍵字,紅色字(例如我們自己定義的變數)和紫色字是基本型別,以及特殊字元(比如檔案的節數還有註釋,都是屬於特殊字元),還有運運算元(例如加減乘除的一些標記是運運算元)

2、型別的檢查
可以看到一個完整程式有哪些部分和型別組成,所有生成的token都有它的位置,型別以及它的值到底是什麼,這是在後面程式碼分析中一個很重要的步驟,就是把它的token資訊透過我們的基礎工具來獲取,這樣就可以在型別上做一些程式碼分析,比如某些型別屬於有函式變數都可以檢查。
3、語法的檢查
下麵是透過語法檢查,透過輸入一些詞素組成的資料結構,比如說 i+1 可以把它轉換成樹狀結構。在一個檔案中包含哪些部分,在 ast 有一個檔案,會有一些宣告,宣告又分為函式宣告和其他的一些全域性的宣告,主要關註的在函式宣告中,下麵有一些註釋檔案,它的型別是什麼,name 是什麼以及這個函式體是什麼,可以看一下右側,把我們剛才看到的 ast 真的去做一個視覺化,這裡面我們看一下,我們這一個檔案,左邊的程式碼,這裡面就會有這個程式碼中它有一些在 ast 上是一個什麼樣的結構,然後我們的檔案中包括一些 name 一些宣告還有一些範圍,importer 這裡面一些註釋還有其他的,我們看到在它的宣告中就分為一些全域性的一些宣告還有我們的函式,在函式裡面,有一些函式的 name 和型別,在這個 ast 中有哪些資訊,我們可以從這裡面拿到一些資訊。


4、token.Fileset
在 fileset 中,我們可以做程式碼中的基本單元,記錄下這個專案有多少個檔案,位置是什麼,檔案資源的偏移,在 fileset 裡有多個檔案,還有它快取之後的檔案,檔案中還有每一行的資訊,包含哪些字元,以及我們剛才看到的那些 token 的資料。

5、如何遍歷ast?
下麵看一下我們的重點,怎麼遍歷我們的 ast。有兩種方式,一種簡單的方式是 inspect 遍歷 fileset,在這裡面看是屬於一些變數,還是屬於你的一些基本的標識,這是我們去簡單的去做一個遍歷,然後另外一種就是我們要去實現每次遍歷 ast 呼叫 walk 的方法,右邊這個,我們呼叫 walk 方法的時候,需要在 visitor 有一個引數,需要自己去實現 visitor,這個 visitor 裡面就是我們要想要去分析裡面寫了一些程式碼分析的演演算法,我們的外部實現一個 visitor 把它傳入我們的 walk 去呼叫,這樣它會根據我們的分析的一些規則去提取出 ast 中我們去關註的一些資訊。

我們看第一個例子,就是關於位元組對齊,這些結構體,是我們經常去宣告一個結構體,不知道大家有沒有關註過這裡面的位元組對齊的問題,我們可以算一下這個結構體佔了多少空間。它的大小是72,佔了72空間,我們知道它需要以8為位元組對齊,當它是連續的記憶體空間的時候,第一個必須去對齊它最低的8的單元,因為我們第二個佔用了24個size,它們一共是72個空間,我們調整順序的時候發現,它的大小可以達到最小64個size,即使再加進去一個也是64個,我們相當於把 A 和 D 合併在一個8的單元裡面,這個大家應該都比較清楚,我們想做的這件事就是我們怎麼去發現,我們怎麼去計算這個結構體確實是做了一些位元組對齊的最佳化,是沒有佔用額外的空間,我們看一些對記憶體比較敏感的應用的時候,可能會註意這些,那麼我們又該怎麼去選擇分析它這個結構?

我們首先在包裝提供了 side off 函式,透過分析程式中所有的 struct,可以把實際大小計算出來,再去遍歷一下這個 struct 中所有元素,把每一個元素取一下它自己本身應該佔用的空間的大小,abcde 佔用空間的和就是我們這個結構體能達到的最小的佔用的記憶體空間。
首先我們載入程式,因為它有 load 的工具包,可以透過這個工具包把程式載入下來,做一些型別的檢查,這些不是我們所要的,左邊我們分析一下結構體的過程,首先是我們拿到了某一個宣告的型別資訊,然後把它轉換成對應的結構體的資訊,如果不是結構體或者是其他的一些函式,那就直接跳出了,不需要繼續檢查,因為我們關註的是所有的結構體是不是做了記憶體最佳化,有一個 side off 我們可以拿到 struct 它實際佔用的空間大小,還有它對齊的單位是什麼,這裡面就是8,我們這裡面可以看到,我們要去遍歷一下一下 struct 當中所有的屬性,我們拿到每個屬性所有的佔用空間大小,這時候我們可以看到,我們既然拿到了屬性的空間大小以及結構體實際佔用空間的大小,可以比較一下這兩個值大小是不是一致的,如果一致,其實在這裡面已經做到了佔用了結構體最小的位元組,如果不是就說明我們的結構體需要調整我們一些屬性的順序,從而達到佔用最小的空間。

類似的應用比如說我們可以檢查一些重覆的字面值,比如在程式碼中寫了很多相等的字串,按照我們正常寫的方法可能需要把它設一個全域性變數,再強製做一些型別轉換,但這是沒有必要的,甚至可能帶來一些風險。我們也可以透過這種方式然後去分析,還有一些冗餘的結構體,也是可以透過這樣的方式來發現。
第二個例子,遍歷 ast 的程式碼分析,我們剛才說的我們實現了 visitor 方法,如果在一個函式內部,我們宣告一個變數但沒有使用的話,會發生報錯宣告,我們去發現有哪些全域性的變數沒有使用,從而把一些沒有用的變數刪除。透過左側的程式碼,我們能夠發現哪些全域性的變數沒有被使用。我們看一下右邊,如果發現一個宣告的變數,把它標記為到底是使用還是沒有使用,如果這個變數使用了就把它設為1,第二個是在宣告的時候,如果是執行了第二個case,但是沒有執行第一個,到最後打印出來說這個是沒有去使用的,最後一個是重新呼叫了 walk 方法,要查一下這個函式中是不是也有這樣的一些情況。

其實也實現了我們遍歷的時候要做的工作。構造一個遍歷器,掃描包中的檔案,每次呼叫一個 walk。最後可以發現在這個裡面我們所有的宣告的變數到底使用沒有使用,如果說宣告了沒有使用就可以打印出來,某個變數在某一行某一個檔案沒有使用,但是宣告了。類似的工具可以透過我剛才說的可以去實現全域性變數一些結構體,或者是沒有用到的引數也是可以發現的,還有一些函式宣告了但是沒有使用。 
第三個,就是提出改進意見,就是這塊程式碼怎麼去寫,怎麼更簡練一點直觀一點,比如我們合併兩個 slice,我們可以透過一行程式碼,直接把一個 slice append 到另外一個。但如果我們的slice資料經過了轉變,即slice1 和 slice2 的元素型別是不一樣的,這樣就不符合程式碼最佳化的提示規則,或者說在合併slice時還要做一些其他的工作,這時候也是不符合的。我們在分析的時候,給出一個最佳化提示的前提是必須是完全符合我們左邊的規則的時候,我們才能給出它這樣的最佳化的建議。這裡,首先是在一個迴圈,必須有 Range,還需要這個迴圈中只有一行程式碼,而且 slice1 和 slice2 型別必須一樣,每個語意必須完全符合這些規則,才能去命中這一行程式碼。

我們看下具體的分析邏輯,首先我們要匹配 Range,把 slice 合併必須要有 append 操作,相當於內建一個函式,我們做型別檢查,看下 slice 型別是不是一致的,如果命中可以直接有一個提示,就是你應該去使用我們剛才看到的後面這個,去代替左邊這個,相當於給出了程式碼建議,在 CI 中,或者試執行我們的工具的時候,可以直接給你有這樣的提示,你就可以根據這個提示做相應程式碼上的最佳化,這是我們簡單的例子。比如我們還可以對它的傳回值進行檢查,型別的轉換的時候進行檢查,還有錯誤處理,比如有一行程式碼,有錯誤但是測試的時候忽略了,這會導致我們的程式崩潰,可以做一些安全性檢查。

統計類的程式碼分析,需要逐個分析檔案,對檔案中函式的圈複雜度的一些計算,例如你的函式有很多if的巢狀,這樣非常不利於我們後期的維護。還有逐個分析你的函式深度,例如你有很多程式碼塊,每一個程式碼塊巢狀,程式碼深度就+1,最後統計出來程式碼到底是深度是不是特別大,比如我們可以設一個分界值是15,如果大於這個值就會給出這樣的提示。類似的比如我們還可以做一些程式碼行長度的限制,或者是程式碼函式數量的統計,一些程式碼的註釋的統計。
 程式碼分析工具介紹
程式碼分析工具介紹
常見工具
下麵是我們比較常見的工具的介紹,大概分這些類別。根據我們平時使用到的一些特點,做的一個分類,比如程式碼規範的檢查,程式碼檢查,程式碼檢查中是不是符合程式碼友好型的檢查,還有安全檢測,程式碼本身的安全漏洞,Go語言本身也是有安全漏洞的,也被報出來,然後修複。有程式碼最佳化,記憶體對齊程式碼的最佳化,還有命名檢測,可能這個名字起的不是特別好,可以重新命名變數,或者單詞拼寫是不是有錯誤,還有一些程式碼統計,可以用這個工具分析出你的依賴關係,一個專案中依賴是不是太複雜或者冗長,可以調整一些程式碼結構。還有無效程式碼的檢查,以及冗餘程式碼的檢查,或者可以根據自己的需求去自定義,根據我們上面所講的程式碼分析的方式,根據它提供的工具可以自己去定製你想要分析的程式碼的特性。

針對不同階段
開發階段可以使用程式碼格式化,程式碼風格檢測,以及自動填充 import,還有自動化表現測試模板,還有簡化工作。測試與迭代階段,程式碼格式化,單元測試和改寫率,不是有無效的程式碼,或者是程式碼風格上的錯誤。Codereview 的時候,我們可能有自己的平臺,可以加入一些圈複雜度,還有命名拼寫,還有重覆程式碼。 


總結&心得
下麵對一些程式碼分析的總結。首先我們說下什麼才叫團隊的程式碼風格統一,就是我們不仔細看程式碼,不看它的記錄和署名,我們不知道這個程式碼誰寫的,這就叫程式碼風格統一。風格統一對後期維護有很大的好處,即使有人員離職或者新人進入。還有自動化的 Codereview,我們一邊在追求我們的程式碼質量,一方面又不需要我們花費那麼多精力做 review,提高效率,還有消除開發人員對他人 Codereview 的抵觸心理,我們是同一個小組時,組長給我們做 Codereview 這種情況還好,如果是同組之間我們成員之間 Codereview 會有這種抵觸心理,透過工具可以減少這樣的一些事情的發生。還有 go 語言中程式碼分析的技術和方法,以及常見的一些程式碼分析是怎麼實現的,最後是給出不同類別以及不同的開發階段可以使用的程式碼分析的工具。
Q&A;
提問:我有兩個問題,一個是我做程式碼Review,遇到一個問題,就是專案有很多歷史遺留問題,這個落地起來難度很大,有沒有什麼比較好的方法?第二個是擴充套件這塊,go 這個擴充套件包這塊的程式碼。歷史的專案會有很多,這樣會出來很多問題,過多的問題,一下子可能解決不了,有沒有什麼好的方案?
王國梁:我們對於歷史程式碼,怎麼去做?一方面就是這個專案需要繼續開發,如果需要,如果你們想去做這個風格程式碼這樣一些工作的話,是不是需要花費你們的精力把舊程式碼重新的整理一下,這是有必要的。
提問:有人提出,新的程式碼質量檢查,新程式碼改寫老的程式碼,這樣一步步的去做。
王國梁:這屬於你們開發的時候怎麼選擇,如果有足夠的時間把這個程式碼做一下,可能越做越好,後期去改的話會發現之前的程式碼本身寫的就不好,再改的話,一方面怕改動太大,還會引入新的問題。
提問:擴充套件包呢?新引入他人的專案包,需要考慮它的程式碼檢查嗎?
王國梁:也是有的,但是這個程式碼檢查,比如之前有專門這個工具,會把標準庫的包忽略。通常情況下這部分沒必要,有的話可以提一些 pr 是可以的。
提問:兩個問題,一個是程式碼檢查,我們的 cover owasp top10 的問題有多少,另外就是剛才講的是靜態程式碼檢查,動態程式碼檢查大概是怎麼實現的?
王國梁:我今天講的大部分幾乎都是靜態的程式碼檢查,動態程式碼檢查目前我沒有特別研究這方面的工作。
提問:我們講那麼多問題,我們對 top10 owasp 的問題,可以改寫多少問題,比如程式碼註入等問題?
王國梁:剛才我們看有一些程式碼漏洞,防止程式碼註入的分析,一些安全性分析都是有的,這些東西其實都是有很多人自發的開發的,目前來說,沒有非常成型的專門去分析 GO 的,其實有很多人寫工具的,我們內部有需求,自己回去寫一些,這個程式碼對我們重要一些,我們可以專門針對這些程式碼做一些程式碼分析。
提問:剛才看到有360的檢查工具是您當時做的開發嗎?挺好用的,裡面還能檢查一些前期的。你自己後面維護了嗎?因為很長時間沒更新了。
王國梁:我前端技能不夠,介面好看度還是要改善,畢竟是360的東西,我在美團一直不好做一直更新維護,但是很多問題還是會解決的。
長按二維碼向我轉賬

受蘋果公司新規定影響,微信 iOS 版的贊賞功能被關閉,可透過二維碼轉賬支援公眾號。
![]()
微信掃一掃
使用小程式
