
導讀:中期選舉前,特朗普政府上演了一場“潛伏”版“水門事件”,而由於一位程式員及其在GitHub上釋出的行文風格相關性分析,這位匿名告密者的身份被迅速鎖定在副總統身上。
這次的結果也似乎會與當年的尼克鬆大有不同。
作者:魏子敏
來源:大資料文摘(ID:BigDataDigest)

先來看看事情的經過。
9月5日,《紐約時報》發表了一封匿名來信《我是特朗普政府中的一名抵抗者》,作者自稱特朗普總統身邊的高管,對特朗普的執政大肆批評並揭露了不少白宮內幕,稱政府內部存在針對特朗普的“抵抗力量”。來信中他表示,為了美國的利益,自己一直“潛伏”在總統身邊,讓總統的很多錯誤決定無法執行。
《紐約時報》表示已經確認了該高官身份,但是為了保護他,選擇了匿名釋出這篇文章。

▲《紐約時報》報道
《紐約時報》報道連結:
https://cn.nytimes.com/opinion/20180906/trump-white-house-anonymous-resistance/
儘管自特朗普上臺以來,反對之聲就一直不絕入耳。但這次曝光者自稱來自特朗普身邊高層,且自稱正百般阻撓各種政策實施。並且特朗普還不知道他是誰。這讓特朗普大為光火。

▲《紐約時報》報道配圖
文章釋出後,特朗普迅速在推特上高呼“謀反(TREASON?)”,要求《紐約時報》把這個膽小的匿名者交給政府。

這件事到此或許還是停留在政府層面的一場鬧劇。但是很快,事情就發生了新轉機。
幾天前,一位名叫Michael W. Kearney的程式員在GitHub公佈了一個指令碼,用神經網路,將這封來信的行文風格和用詞與每個白宮高管的推特文字進行了分析對比,並分別求出了相關係數。
Github連結
https://github.com/mkearney/resist_oped/blob/master/README.md
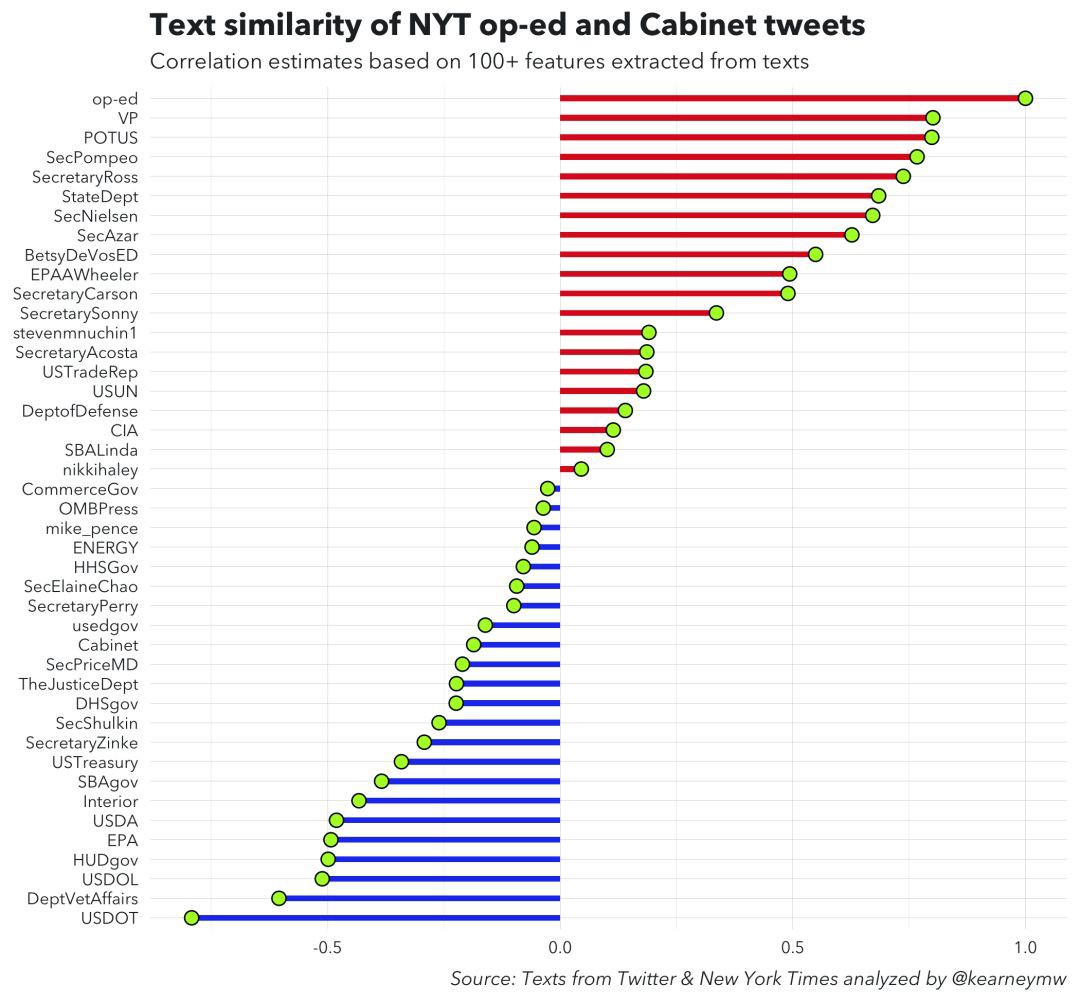
執行結果是副總統(VP, Vice President)的相關係數最高。

GitHub上的這一分析結果和白宮的某些調查不謀而合。據美聯社報道,白宮有分析結果稱,評論文章中出現了“lodestar”這一不常見詞彙,正是美國副總統經常使用的語言,一些人因而猜測彭斯是匿名作者。
接下來,事件矛頭直指美國副總統邁克·彭斯。
為證清白,彭斯在接下來的幾日做客兩檔電視節目,說願接受測謊儀檢測,同時為屬下作擔保,願意接受任何政府審核。
當然,也有人稱,在GitHub公佈的分析結果可以看出,特朗普的繫數0.798661比副總統的繫數0.801063差距非常小,這是否是中期選舉前特朗普自導自演的一齣大戲還不得而知。
這位讓副總統傷腦筋的程式員也並非等閑之輩。
從GitHub的個人主頁可以看出,Michael W. Kearney的真實身份是密蘇裡大學新聞學院的副教授,同時也在學校資訊學院任職,教授大眾媒體、政治傳播、定量研究方法和資料科學課程。
目前的研究重點正是在新媒體環境中的黨派選擇性曝光,可以說是一位兼具新聞傳播知識和程式技能的大咖。
Michael W. Kearney的research gate的主頁介紹:

Michael W. Kearney在密蘇裡大學的個人主頁:
https://mikewk.com/

或許這次,程式員真的要拯救世界了。
最後,附上Michael W. Kearney在GitHub上釋出的這篇手稿。
原文連結:
https://github.com/mkearney/resist_oped/blob/master/resist-oped-text-similarity.md
題目:使用資料科學識,推測誰撰寫了《紐約時報》關於特朗普政府內部抵抗的專欄文章
《紐約時報》發表了一篇關於白宮內部抵抗的評論文章。它是由一位匿名作者撰寫的,這名作者被稱為“特朗普政府的一名高階官員”。
很多人都在猜測撰寫這篇專欄文章的作者,早期猜測的線索是“lodestar”這個詞的使用。據悉,副總統邁克·彭斯經常使用這個詞。其他人則認為,匿名作者故意往彭斯身上潑髒水。
我們可能永遠不知道是誰真正撰寫了這篇文章。但是,就目前而言,我想指出的是,雖然分析白宮高階官員的溝通樣式是有據可循的,但這樣做卻忽視了資料科學的最新進展。
那麼,可以透過過去的通訊記錄來幫助識別匿名作者嗎?
其實數字媒體和資料科學現有技術,使我們可以在相對較短的時間內獲得(無論是否準確)見解。而且由於我做的很多工作都涉及到分析Twitter上所展示的政治溝通,我想我會試著用它來展示一些資料科學培訓案例,這僅僅需要大量資料和一點時間。
分析過程
首先,我從《紐約時報》專欄中獲取了文字。
1. 我收集了專欄文字
接下來,因為我需要一些樣本來與專欄的文字進行比較,所以我轉向Twitter。由於時間的緣故,我決定將我的分析範圍鎖定在總統內閣成員身上。
2. 我從使用推特的特朗普“內閣”那裡收集了最新的3, 200條推文
透過參考文字和Twitter推文樣本,之後我逐段拆分專欄文字,大致匹配推文的長度。
3. 我將專欄文字分成段落
使用與名稱或“op-ed”的作者進行匹配,然後為每個文字字串提取了超過100個特徵。這些特徵包括大寫、標點符號(逗號、句號、感嘆號等)、空格的使用、單詞長度、句子長度、’待成’動詞的使用、以及詞維度的大量詞庫表示,這類似於將常用單詞劃分為八十個不同的主題,然後測量每個文字使用相關主題的單詞程度。
4. 我將每個文字轉換為107個數字要素
最後,為了對op-ed和名稱之間的相似性進行實際測量,我平均了作者所特有的數字,然後使用這些值來估計專欄文字和Twitter使用者文字(關聯度量範圍從-1到1)之間的相關性。
5. 我估計了專欄文字和每個內閣成員帳戶釋出的推文之間的相關性
你可以找到我在Github上使用的程式碼。這是相關係數的直觀表示:
分析侷限性
本實踐有助於說明,如何使用資料科學來估計多個文字之間的相似性,但它沒有提供任何確鑿的證據來回答誰是撰寫《紐約時報》專欄文章的作者。
事實上,有很多理由說明為什麼人們應該對這種分析所做的推論持懷疑態度。我將在接下來的幾段中描述其中的一些限制。
首先,比較文字是有限的。因為它們是為Twitter而不是《紐約時報》設計的。他們也是由使用者撰寫的,他們的身份可能與他們的推文相關聯。
其次,比較文字庫但沒有考慮所有的可能選擇。例如,這沒有考慮“不使用Twitter的內閣成員”。它也省略了任何在特朗普政府工作但不是內閣正式成員的人。
第三,文字相似性分析假設:匿名專欄作者沒有嘗試偽裝自己的溝通樣式。即使他們確實試圖偽裝自己,一些溝通樣式可能不予考慮。一些誤導的線索,例如“lodestar”詞的使用,可能導致許多演演算法錯誤推測。
第四,假設撰寫推文的人是他們聲稱代表的實際人。例如,我們有理由相信特朗普並沒有操作@POTUS帳戶,但情況具體如何,我們不得而知。一些內部通訊人員也完全有可能影響推文訊息的傳送。或者,主管部門可能會有重疊的溝通樣式。因此,在白宮工作的人員都會有一些近似的匹配。

更多精彩
在公眾號後臺對話方塊輸入以下關鍵詞
檢視更多優質內容!
PPT | 報告 | 讀書 | 書單
Python | 機器學習 | 深度學習 | 神經網路
區塊鏈 | 揭秘 | 乾貨 | 數學
猜你想看
Q: 技術鑒定美國鬧劇,好玩嗎?
歡迎留言與大家分享
覺得不錯,請把這篇文章分享給你的朋友
轉載 / 投稿請聯絡:baiyu@hzbook.com
更多精彩,請在後臺點選“歷史文章”檢視
