

圖片:Westworld Season 2
作者
王強
簡介
Python追隨者,曾無意間利用微信好友男女比例證明瞭自己的程式員身份。個人公號:C與Python實戰
上一篇文章中《Python爬蟲抓取智聯招聘(基礎版)》我們已經抓取了智聯招聘一些資訊,但是那些對於找工作來說還是不夠的,今天我們繼續深入的抓取智聯招聘資訊並分析,本文使用到的第三方庫很多,涉及到的內容也很繁雜,請耐心閱讀。
執行平臺: Windows
Python版本: Python3.6
IDE: Sublime Text
其他工具: Chrome瀏覽器
0、寫在前面的話
本文是基於基礎版上做的修改,如果沒有閱讀基礎版,請移步 Python爬蟲抓取智聯招聘(基礎版)
在基礎版中,構造url時使用了urllib庫的urlencode函式:
url = 'https://sou.zhaopin.com/jobs/searchresult.ashx?' + urlencode(paras)
try:
# 獲取網頁內容,傳回html資料
response = requests.get(url, essay-headers=essay-headers)
...
其實用reuqests庫可以完成此工作,本例將該部分改為:
url = 'https://sou.zhaopin.com/jobs/searchresult.ashx?'
try:
# 獲取網頁內容,傳回html資料
response = requests.get(url, params=paras, essay-headers=essay-headers)
...
1、找到職位連結
為了得到更加詳細的職位資訊,我們要找到職位連結,在新的頁面中尋找資料。上篇文章中我們沒有解析職位連結,那再來找一下吧:
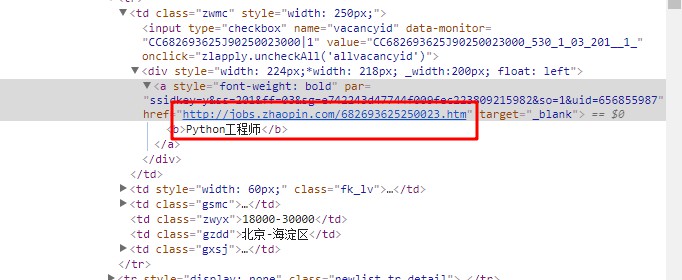
修改一下正則運算式:
# 正則運算式進行解析
pattern = re.compile('(.*?) .*?’ # 匹配職位詳情地址和職位名稱
‘
.*?’ # 匹配公司名稱
‘
‘, re.S) # 匹配月薪
# 匹配所有符合條件的內容
items = re.findall(pattern, html)
2、求工資平均值
工資有兩種形式xxxx-yyyy或者面議,此處取第一種形式的平均值作為分析標準,雖有偏差但是也差不多,這是求職中最重要的一項指標。
for item in items:
salary_avarage = 0
temp = item[3]
if temp != '面議':
idx = temp.find('-')
# 求平均工資
salary_avarage = (int(temp[0:idx]) + int(temp[idx+1:]))//2
3、解析職位詳細資訊
3.1 網頁解析
第一步已經將職位地址找到,在瀏覽器開啟之後我們要找到如下幾項資料:
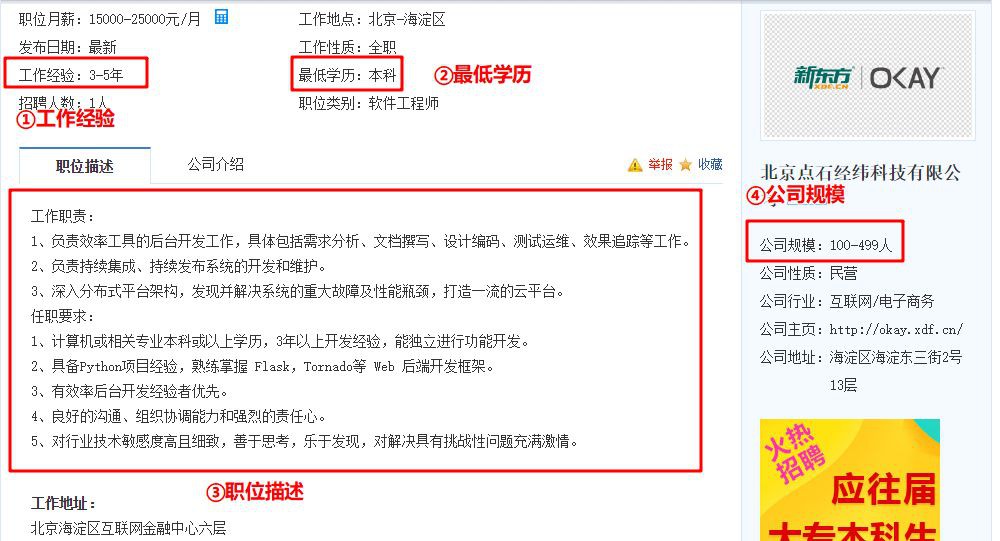
在開發者工具中查詢這幾項資料,如下圖所示:
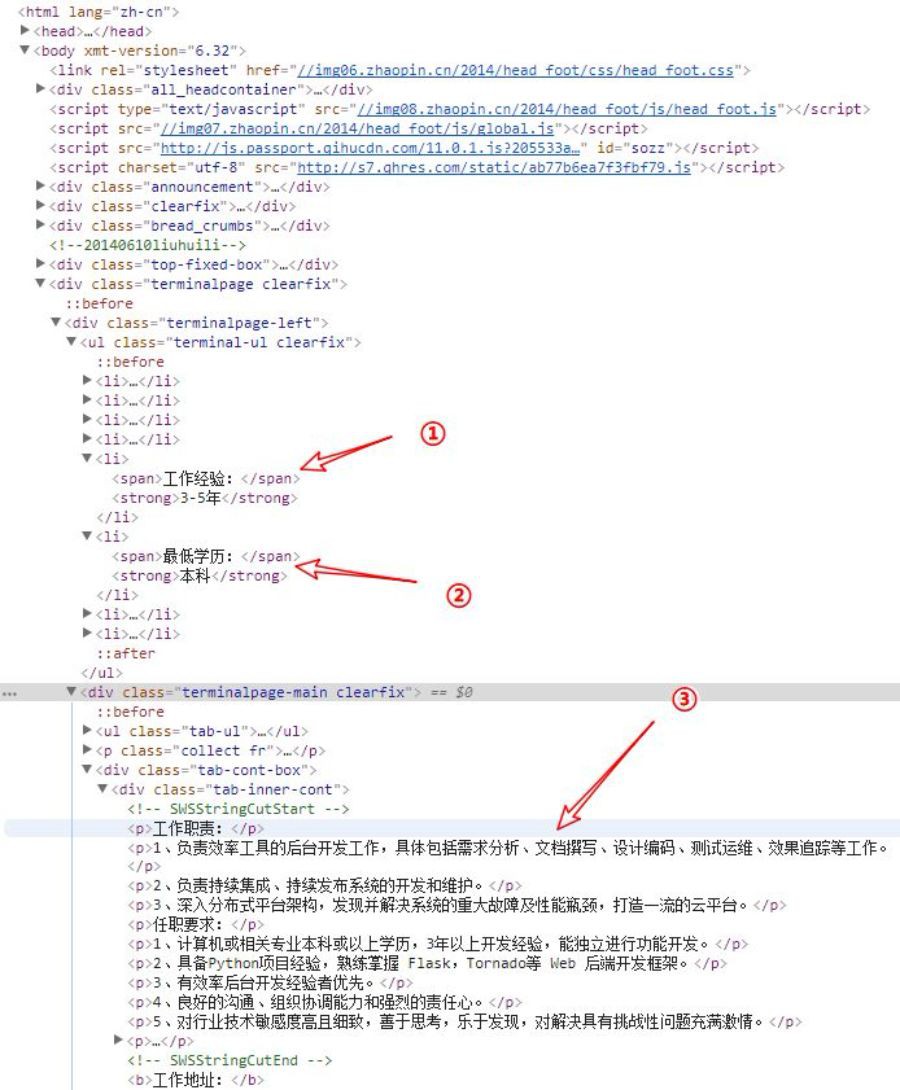
HTML結構如下所示:
# 資料HTML結構
<body>
|------<div class="terminalpage clearfix">
==>|------<div class="terminalpage-left">
==>==>|------<ul class="terminal-ul clearfix">
==>==>==>|------<li><span>工作經驗:span><strong>3-5年strong>
==>==>==>|——<li><span>最低學歷:span><strong>本科strong>
==>==>|——<div class=“terminalpage-main clearfix”>
==>==>==>|——<div class=“tab-cont-box”>
==>==>==>==>|——<div class=“tab-inner-cont”>
==>==>==>==>==>|——<p>工作職責:p>
==>==>==>==>==>|——<p>********p>
==>==>==>==>==>|——<p>********p> # 工作職責詳情
==>|——<div class=“terminalpage-right”>
==>==>|——<div class=“company-box”>
==>==>==>|——<ul class=“terminal-ul clearfix terminal-company mt20”>
==>==>==>==>|——<li><span>公司規模:span><strong>100-499人strong>
3.2 程式碼實現
為了學習一下BeautifulSoup庫的使用,我們不再使用正則運算式解析,而是BeautifulSoup庫解析HTML標簽來獲得我們想要得到的內容。
解析庫的安裝:pip install beautifulsoup4
下麵介紹一下本例中使用到的功能:
-
庫的引入:
from bs4 import BeautifulSoup -
資料引入:
soup = BeautifulSoup(html, 'html.parser'),其中html是我們要解析的html原始碼,html.parser指定HTML的解析器為Python標準庫。 -
查詢標簽:
find(name,attrs,recursive,text,**kwargs),find傳回的匹配結果的第一個元素 -
查詢所有標簽:
find_all(name,attrs,recursive,text,**kwargs)可以根據標簽名,屬性,內容查詢檔案,傳回找到的所有元素 -
獲取內容:
get_text()就可以獲取文字內容 -
獲取子標簽:
soup.p這種方式就可以獲取到soup下的第一個p標簽
def get_job_detail(html):
requirement = ''
# 使用BeautifulSoup進行資料篩選
soup = BeautifulSoup(html, 'html.parser')
# 找到標簽
for ul in soup.find_all('ul', class_='terminal-ul clearfix'):
# 該標簽共有8個子標簽,分別為:
# 職位月薪|工作地點|釋出日期|工作性質|工作經驗|最低學歷|招聘人數|職位類別
lis = ul.find_all('strong')
# 工作經驗
years = lis[4].get_text()
# 最低學歷
education = lis[5].get_text()
# 篩選任職要求
for terminalpage in soup.find_all('div', class_='terminalpage-main clearfix'):
for box in terminalpage.find_all('div', class_='tab-cont-box'):
cont = box.find_all('div', class_='tab-inner-cont')[0]
ps = cont.find_all('p')
# "立即申請"按鈕也是個p標簽,將其排除
for i in range(len(ps) - 1):
requirement += ps[i].get_text().replace("\n", "").strip() # 去掉換行符和空格
# 篩選公司規模,該標簽內有四個或五個標簽,但是第一個就是公司規模
scale = soup.find(class_='terminal-ul clearfix terminal-company mt20').find_all('li')[0].strong.get_text()
return {'years': years, 'education': education, 'requirement': requirement, 'scale': scale}
本次我們將職位描述寫入txt檔案,其餘資訊寫入csv檔案。
csv檔案採用逐行寫入的方式這樣也可以省點記憶體,修改write_csv_rows函式:
def write_csv_rows(path, essay-headers, rows):
'''
寫入行
'''
with open(path, 'a', encoding='gb18030', newline='') as f:
f_csv = csv.DictWriter(f, essay-headers)
# 如果寫入資料為字典,則寫入一行,否則寫入多行
if type(rows) == type({}):
f_csv.writerow(rows)
else:
f_csv.writerows(rows)
新增寫txt檔案函式:
def write_txt_file(path, txt):
'''
寫入txt文字
'''
with open(path, 'a', encoding='gb18030', newline='') as f:
f.write(txt)
我們最重要對職位描述的內容進行詞頻統計,一些標點符號等會影響統計,使用正則運算式將其剔除:
# 對資料進行清洗,將標點符號等對詞頻統計造成影響的因素剔除
pattern = re.compile(r'[一-龥]+')
filterdata = re.findall(pattern, job_detail.get('requirement'))
write_txt_file(txt_filename, ''.join(filterdata))
至此,職位詳細資訊的獲取及儲存的工作已經完成,來看一下此時的main函式:
def main(city, keyword, region, pages):
'''
主函式
'''
csv_filename = 'zl_' + city + '_' + keyword + '.csv'
txt_filename = 'zl_' + city + '_' + keyword + '.txt'
essay-headers = ['job', 'years', 'education', 'salary', 'company', 'scale', 'job_url']
write_csv_essay-headers(csv_filename, essay-headers)
for i in range(pages):
'''
獲取該頁中所有職位資訊,寫入csv檔案
'''
job_dict = {}
html = get_one_page(city, keyword, region, i)
items = parse_one_page(html)
for item in items:
html = get_detail_page(item.get('job_url'))
job_detail = get_job_detail(html)
job_dict['job'] = item.get('job')
job_dict['years'] = job_detail.get('years')
job_dict['education'] = job_detail.get('education')
job_dict['salary'] = item.get('salary')
job_dict['company'] = item.get('company')
job_dict['scale'] = job_detail.get('scale')
job_dict['job_url'] = item.get('job_url')
# 對資料進行清洗,將標點符號等對詞頻統計造成影響的因素剔除
pattern = re.compile(r'[一-龥]+')
filterdata = re.findall(pattern, job_detail.get('requirement'))
write_txt_file(txt_filename, ''.join(filterdata))
write_csv_rows(csv_filename, essay-headers, job_dict)
4、資料分析
本節內容為此版本的重點。
4.1 工資統計
我們對各個階段工資的佔比進行統計,分析該行業的薪資分佈水平。前面我們已經把資料儲存到csv檔案裡了,接下來要讀取salary列:
def read_csv_column(path, column):
'''
讀取一列
'''
with open(path, 'r', encoding='gb18030', newline='') as f:
reader = csv.reader(f)
return [row[column] for row in reader]
# main函式裡新增
print(read_csv_column(csv_filename, 3))
#下麵為列印結果
['salary', '7000', '5000', '25000', '12500', '25000', '20000', '32500', '20000', '15000', '9000', '5000', '5000', '12500', '24000', '15000', '18000', '25000', '20000', '0', '20000', '12500', '17500', '17500', '20000', '11500', '25000', '12500', '17500', '25000', '22500', '22500', '25000', '17500', '7000', '25000', '3000', '22500', '15000', '25000', '20000', '22500', '15000', '15000', '25000', '17500', '22500', '10500', '20000', '17500', '22500', '17500', '25000', '20000', '11500', '11250', '12500', '14000', '12500', '17500', '15000']
從結果可以看出,除了第一項,其他的都為平均工資,但是此時的工資為字串,為了方便統計,我們將其轉換成整形:
salaries = []
sal = read_csv_column(csv_filename, 3)
# 撇除第一項,並轉換成整形,生成新的串列
for i in range(len(sal) - 1):
# 工資為'0'的表示招聘上寫的是'面議',不做統計
if not sal[i] == '0':
salaries.append(int(sal[i + 1]))
print(salaries)
# 下麵為列印結果
[7000, 5000, 25000, 12500, 25000, 20000, 32500, 20000, 15000, 9000, 5000, 5000, 12500, 24000, 15000, 18000, 25000, 20000, 0, 20000, 12500, 20000, 11500, 17500, 25000, 12500, 17500, 25000, 25000, 22500, 22500, 17500, 17500, 7000, 25000, 3000, 22500, 15000, 25000, 20000, 22500, 15000, 22500, 10500, 20000, 15000, 17500, 17500, 25000, 17500, 22500, 25000, 12500, 20000, 11250, 11500, 14000, 12500, 15000, 17500]
我們用直方圖進行展示:
plt.hist(salaries, bins=10 ,)
plt.show()
生成效果圖如下:
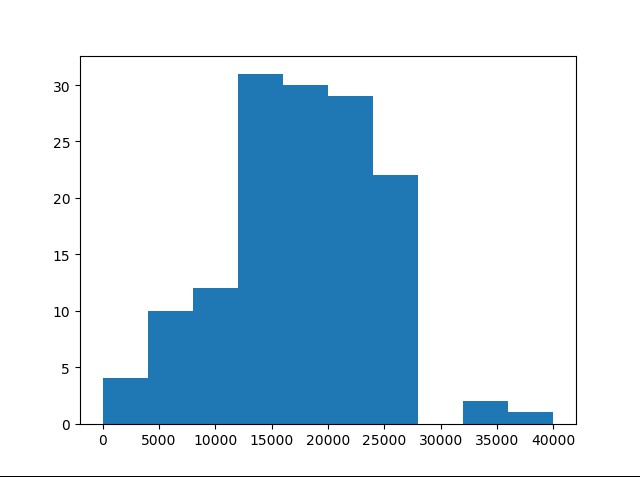
從圖中可以看出工資分佈的情況,這樣在你找工作時可以做一個參考。
4.2 職位描述詞頻統計
對職位描述詞頻統計的意義是可以瞭解該職位對技能的基本要求,如果正在找工作,可以估計一下自己的要求是否符合該職位;如果想要一年後換工作,那麼也可以提前做好準備,迎接新的挑戰。
詞頻統計用到了 jieba、numpy、pandas、scipy庫。如果電腦上沒有這兩個庫,執行安裝指令:
-
pip install jieba -
pip install pandas -
pip install numpy -
pip install scipy
4.2.1 讀取txt檔案
前面已經將職位描述儲存到txt檔案裡了,現在我們將其讀出:
def read_txt_file(path):
'''
讀取txt文字
'''
with open(path, 'r', encoding='gb18030', newline='') as f:
return f.read()
簡單測試一下:
import jieba
import pandas as pd
content = read_txt_file(txt_filename)
segment = jieba.lcut(content)
words_df=pd.DataFrame({'segment':segment})
print(words_df)
# 輸出結果如下:
segment
0 崗位職責
1 參與
2 公司
3 軟體產品
4 後臺
5 研發
6 和
7 維護
8 工作
9 參與
10 建築物
11 聯網
12 資料分析
13 演演算法
14 的
15 設計
16 和
17 開發
18 可
19 獨立
20 完成
21 業務
22 演演算法
23 模組
... ...
從結果可以看出:“崗位職責”、“參與”、“公司”、軟體產品“、”的“、”和“等單詞並沒有實際意義,所以我們要將他們從表中刪除。
4.2.2 stop word
下麵引入一個概念:stop word, 在網站裡面存在大量的常用詞比如:“在”、“裡面”、“也”、“的”、“它”、“為”這些詞都是停止詞。這些詞因為使用頻率過高,幾乎每個網頁上都存在,所以搜尋引擎開發人員都將這一類詞語全部忽略掉。如果我們的網站上存在大量這樣的詞語,那麼相當於浪費了很多資源。
在百度搜索stpowords.txt進行下載,放到py檔案同級目錄。接下來測試一下:
content = read_txt_file(txt_filename)
segment = jieba.lcut(content)
words_df=pd.DataFrame({'segment':segment})
stopwords=pd.read_csv("stopwords.txt",index_col=False,quoting=3,sep=" ",names=['stopword'],encoding='utf-8')
words_df=words_df[~words_df.segment.isin(stopwords.stopword)]
print(words_df)
# 以下為輸出結果
0 崗位職責
1 參與
2 公司
3 軟體產品
4 後臺
5 研發
7 維護
8 工作
9 參與
10 建築物
11 聯網
12 資料分析
13 演演算法
15 設計
17 開發
19 獨立
21 業務
22 演演算法
23 模組
24 開發
28 產品
29 標的
31 改進
32 創新
33 任職
35 熟練
38 開發
39 經驗
40 優先
41 熟悉
... ...
從結果看出,那些常用的stop word比如:“的”、“和”、“可”等已經被剔除了,但是還有一些詞如“崗位職責”、“參與”等也沒有實際意義,如果對詞頻統計不產生影響,那麼就無所謂,在後面統計時再決定是否對其剔除。
4.2.3 詞頻統計
重頭戲來了,詞頻統計使用numpy:
import numpy
words_stat = words_df.groupby(by=['segment'])['segment'].agg({"計數":numpy.size})
words_stat = words_stat.reset_index().sort_values(by=["計數"],ascending=False)
print(words_stat)
# 以下是爬取全部“北京市海澱區Python工程師”職位的執行結果:
segment 計數
362 開發 505
590 熟悉 409
701 經驗 281
325 工作 209
820 負責 171
741 能力 169
793 設計 161
82 優先 160
409 技術 157
621 相關 145
322 崗位職責 127
683 系統 126
64 產品 124
904 專案 123
671 演演算法 107
78 任職 107
532 框架 107
591 熟練 104
可以看出,某些詞語還是影響了統計結果,我將以下stop word加入stopword.txt中:
開發、熟悉、熟練、精通、經驗、工作、負責、能力、有限、相關、崗位職責、任職、語言、平臺、參與、優先、技術、學習、產品、公司、熟練掌握、以上學歷
最後執行結果如下:
775 設計 136
667 系統 109
884 專案 105
578 熟練 95
520 框架 92
656 演演算法 90
143 分析 90
80 最佳化 77
471 資料庫 75
693 維護 66
235 團隊 65
72 程式碼 61
478 檔案 60
879 需求 58
766 計算機 56
698 程式設計 56
616 研發 49
540 溝通 49
527 模組 49
379 效能 46
695 編寫 45
475 資料結構 44
這樣基本上就是對技能的一些要求了,你也可以根據自己的需求再去修改stopword.txt已達到更加完美的效果。
4.2.4 詞頻視覺化:詞雲
詞頻統計雖然出來了,可以看出排名,但是不完美,接下來我們將它視覺化。使用到wordcloud庫,詳細介紹見 github ,使用pip install wordcloud進行安裝。
from scipy.misc import imread
from wordcloud import WordCloud, ImageColorGenerator
# 設定詞雲屬性
color_mask = imread('background.jfif')
wordcloud = WordCloud(font_path="simhei.ttf", # 設定字型可以顯示中文
background_color="white", # 背景顏色
max_words=100, # 詞雲顯示的最大詞數
mask=color_mask, # 設定背景圖片
max_font_size=100, # 字型最大值
random_state=42,
width=1000, height=860, margin=2,# 設定圖片預設的大小,但是如果使用背景圖片的話, # 那麼儲存的圖片大小將會按照其大小儲存,margin為詞語邊緣距離
)
# 生成詞雲, 可以用generate輸入全部文字,也可以我們計算好詞頻後使用generate_from_frequencies函式
word_frequence = {x[0]:x[1]for x in words_stat.head(100).values}
word_frequence_dict = {}
for key in word_frequence:
word_frequence_dict[key] = word_frequence[key]
wordcloud.generate_from_frequencies(word_frequence_dict)
# 從背景圖片生成顏色值
image_colors = ImageColorGenerator(color_mask)
# 重新上色
wordcloud.recolor(color_func=image_colors)
# 儲存圖片
wordcloud.to_file('output.png')
plt.imshow(wordcloud)
plt.axis("off")
plt.show()
執行效果圖如下(左圖為原圖,右圖為生成的圖片):

至此,詞頻統計及其視覺化完成。
5、其他想法
本例中進行了兩種資料分析,雖為進階版,但是還是有很多可以繼續發揮的地方:
-
分析工作年限和工資的關係並展示、預測
-
統計不同工作崗位的薪資差別
-
利用多執行緒或多行程提升效率
有興趣的可以嘗試做一下。
《Linux雲端計算及運維架構師高薪實戰班》2018年09月17日開課中,120天衝擊Linux運維年薪30萬,改變速約~~~~
*宣告:推送內容及圖片來源於網路,部分內容會有所改動,版權歸原作者所有,如來源資訊有誤或侵犯權益,請聯絡我們刪除或授權事宜。
– END –


更多Linux好文請點選【閱讀原文】哦
↓↓↓
