回憶一下
我們都知道Linux的IO模型有阻塞、非阻塞、SIGIO、多路復用(select,epoll)、AIO(非同步I/O)等。
資料庫可能比較傾向於使用AIO。從時序上面來講,AIO是使用者應用發起IO請求io_submit()後,它就不需要去等待,讓後臺給它搞定讀寫。之後本執行緒或者其他執行緒就可以透過io_getevents()去同步I/O的結果。

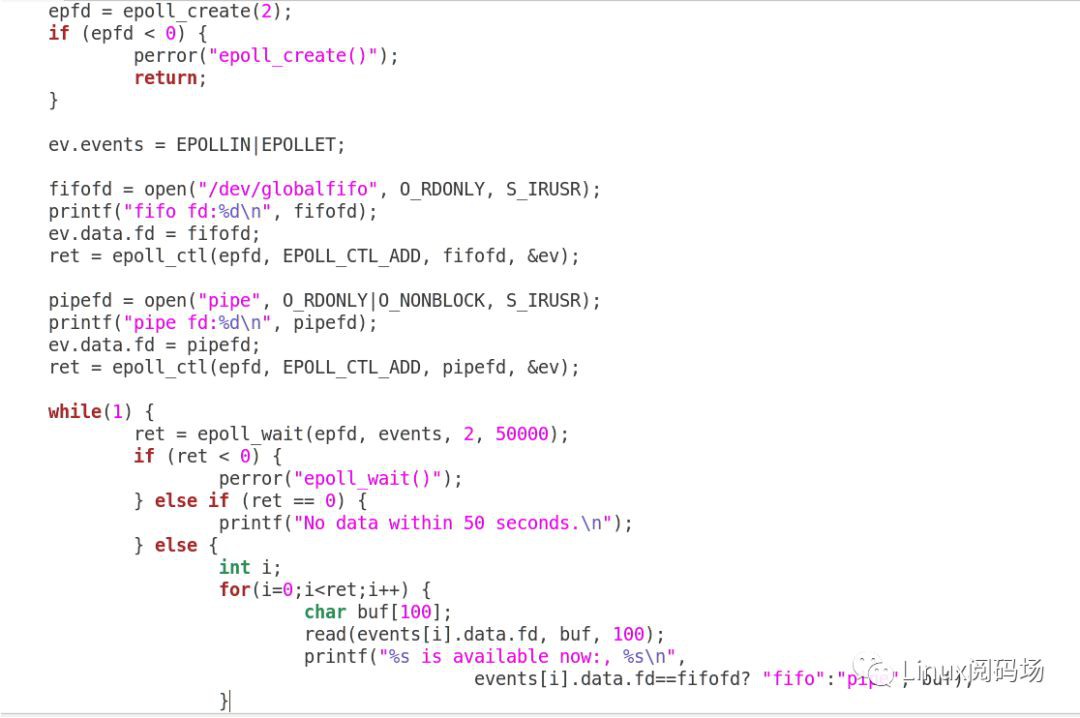
這樣的AIO有一個極大的好處在於,IO不會阻塞住CPU的行為,有利於充分利用硬體的資源,有利於讓CPU、IO都parallel起來 。當然,同樣的動作,似乎用epoll()、SIGIO也可以呈現出來。尤其是epoll(),幾乎是C10K問題解決方案在Linux的代名詞。epoll_wait()先等待IO請求的read、write可以發生,而後再根據傳回的事件發起讀寫請求:
事件驅動模型libevent等,看起來是事件到來,callback被執行的Reactor樣式:

但是其底層其實也是靠epoll()來實現,這個我們透過strace就可以看出。請見我的3分鐘小電影:
大不一樣
epoll()本質上其實還是先等待IO的讀寫可以發生,而後再以Linux常規read()、write() API去發起IO請求。而AIO則是不管三七二十一,直接發IO請求,但是並不等待這個請求的結束,讓Linux後臺自己去完成讀寫。我們來看一個典型的AIO程式設計案例:

它是透過io_submit()把IO請求發出去之後,它並不需要等IO的結束。後面用io_getevents()去同步。上面的程式碼中,io_getevents()的程式碼與io_submit()的程式碼擺在一起,但是其實它們並不需要一定是同一個執行緒。
AIO和傳統epoll()的本質區別是,epoll()等方式,它只是一個事件獲取機制,獲取事件後,之後的read(), write()還是要走Linux的傳統路線,經過Linux核心本身的各個層次(如page cache,IO排程等)。而AIO是骨子裡面,自己就是一個IO的方式,最終沒有經過傳統的Linux read(),write()這種”all is file”的類VFS介面。Linux native的AIO本身call的函式,本身就是系統呼叫。strace執行AIO動作的行程得到的直接就是類似如下的結果:
strace ./aio….
…
io_setup(128, {3077799936}) = 0
io_submit(3077799936, 1, 0xbfa5e730) = 1
io_getevents(-1217167360, 1, 1, {…}NULL) = 1
在ARM Linux的系統呼叫表裡也可以看出:

故而,AIO可以更多地把機會交給使用者空間,讓使用者空間根據自身的IO特點來為自己量身定製IO的行為。AIO一般也直接結合DIO(direct IO)來使用,進一步繞開核心本身的IO排程和cache機制。
我中意你
那麼AIO有什麼可能的優勢被資料庫所青睞呢?
1. 透過AIO,可以遮蔽掉Linux核心底層的page cache。而制定application-level的cache機制。
我們都知道,Linux會針對每個檔案對應的inode,創立一個address_space,並以Radix樹來組織它的page cache命中情況,page的替換演演算法,整體是LRU,預測頁面本身的活躍度。這個策略,固然非常符合區域性性原理(Locality),但是不能針對使用者程式本身的特徵,進行使用者級的cache。
2.透過AIO(尤其是結合DIO),可以一定程度上,進行使用者級別的IO scheduling。採用AIO,使用者可以控制傳送給內核的IO請求,從而控制誰比誰更重要。核心固然有它的IO排程演演算法,但是它是比較general的。
3. 透過AIO,可以進行使用者級別的read-ahead和write-behind控制。
我們都知道,Linux核心本身會根據使用者的讀請求,去預測後續的讀,從而在後續的讀還沒有發起的情況下,就提前預讀。詳見:《宋寶華: 檔案讀寫(BIO)波瀾壯闊的一生》,但是這種預讀的page,並不一定是上層應用想要的page。而內核的write-behind機制,也可能導致核心累積到很多dirty資料後,出現寫磁碟的突發性洪泛。現在AIO機制,我們把這些都交給使用者。
4. 透過AIO,不阻塞地在前臺執行緒,直接dispatch IO請求,帶來很好的
scalability。在InnoDB裡面,可以透過 innodb_use_native_aio來配置使用同步的IO還是AIO,而且它有一番對比,值得細細地品讀。同步IO的時候,query threads是將IO請求放入queue,由InnoDB後臺執行緒的每個執行緒處理一個IO請求。而AIO的時候,query threads直接發IO請求。
With synchronous I/O, query threads queue I/O requests, and InnoDB background threads retrieve the queued requests one at a time, issuing a synchronous I/O call for each. When an I/O request is completed and the I/O call returns, the InnoDB background thread that is handling the request calls an I/O completion routine and returns to process the next request. The number of requests that can be processed in parallel is n, where n is the number of InnoDB background threads. The number of InnoDB background threads is controlled by innodb_read_io_threads and innodb_write_io_threads.
With native AIO, query threads dispatch I/O requests directly to the operating system, thereby removing the limit imposed by the number of background threads. InnoDB background threads wait for I/O events to signal completed requests. When a request is completed, a background thread calls an I/O completion routine and resumes waiting for I/O events.
參考閱讀
https://dev.mysql.com/doc/refman/8.0/en/innodb-linux-native-aio.html
https://www.scylladb.com/2017/10/05/io-access-methods-scylla/
https://blog.pythian.com/importance-oracle-database-related-kernel-parameters-aio-max-nr-bonus-track/