關於Kafka,人們經常問的一個問題就是:Kafka是否適合用於長期的資料儲存,你也知道Kafka會儲存記錄日誌,如下所示:

問題是你是否可以將此日誌視為檔案,並將其用作資料的真實來源儲存。Kafka 的設計意圖之一就是要將它作為資料儲存系統。
Confluent 的聯合創始人和 CTO Neha Narkhede曾經做過一個演講關於“ETL 已經過時,而實時流正當下”,並討論了企業級資料處理領域所面臨的挑戰。
如今大多數企業都面臨來自新應用程式,新業務機會,物聯網等的大量資料。一個理想架構應該是乾凈,最佳化的系統,允許企業利用所有資料。
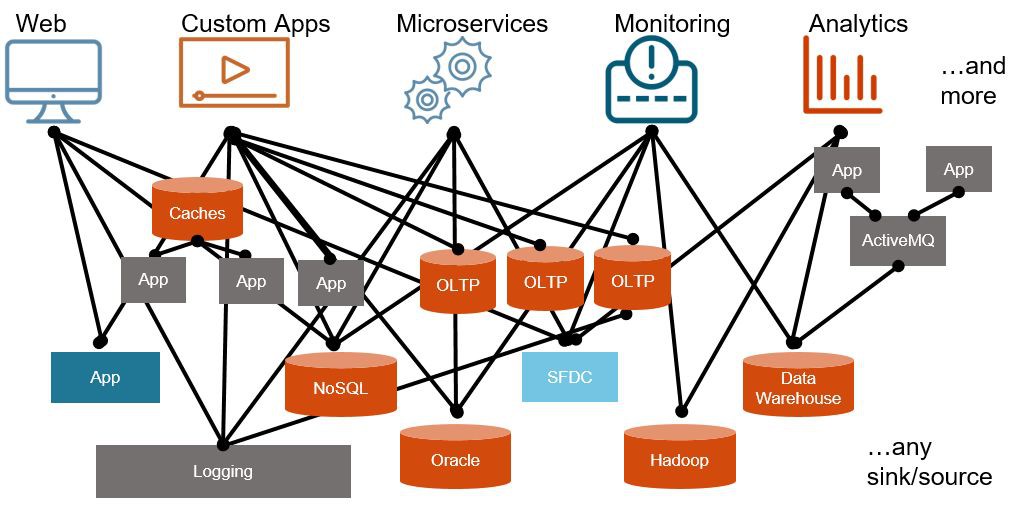
然而,用於解決這些問題的傳統系統是在大規模分散式系統出現之前設計的,缺乏能夠滿足現代資料集的拓展能力
因而 Narkhede 提出了現代流處理對資料集的新需求:
● 能夠處理大量且多樣性的資料;
● 平臺必須要從底層就支援實時處理,這會促進向以事件為中心的根本轉變;
● 必須使用向前相容的資料架構,必須能夠支援新增新的應用,這些新的應用可能會以不同的方式來處理相同的資料。

而正是這些需求推動了Kafka的釋出,Apache Kafka 在 LinkedIn 目前每天處理 14 萬億條的訊息,在峰值時每秒鐘會釋出超過450萬條訊息。

此外世界 500 強的公司,如 Cisco、Netflix、PayPal 和 Verizon。Kafka 已經快速成為流資料的儲存方案,並且為應用整合提供了一個可擴充套件的訊息支撐(backbone),能夠跨多個資料中心。
正是Kafka強大的功能特性,帶動了不少的程式員都開始深入瞭解這個專案,本文就是和大家分享一本關於Kafka的書《Kafka權威指南》

● Kafka核心作者和業界一流一線人員共同執筆
● 全面介紹Kafka設計原理和架構細節
● 英文原版深受讀者喜愛,亞馬遜4星好評
本書詳細介紹瞭如何部署Kafka叢集、開發可靠的基於事件驅動的微服務,以及基於Kafka平臺構建可伸縮的流式應用程式。透過詳盡示例,你將會瞭解到Kafka的設計原則、可靠性保證、關鍵API,以及複製協議、控制器和儲存層等架構細節。
閱讀路線
每個應用程式都會產生資料,包括日誌訊息、度量指標、使用者活動記錄、響應訊息等。如何行動資料,幾乎變得與資料本身一樣重要。本書將透過以下知識點展開:
● 瞭解釋出和訂閱訊息模型以及該模型如何被應用在大資料生態系統中
● 學習使用Kafka生產者和消費者來生成訊息和讀取訊息
● 瞭解Kafka保證可靠性資料傳遞的樣式和場景需求
● 使用Kafka構建資料管道和應用程式的最佳實踐
● 在生產環境中管理Kafka,包括監控、調優和維護
● 瞭解Kafka的關鍵度量指標
● 探索Kafka如何成為流式處理利器
目錄如下:

讀者書評:
@ruhm :在學習大資料的過程中額外學習的,基本解答了我心中的三個問題 1. Kafka 是什麼。 2. Kafka 如何做到可靠性和高效能兩個特性的設計的。 3. Kafka 在流式計算領域的應用場景有哪些。
@einverne:雖然有點老,但作為入門來看還是不錯的。其實看Kafka官網doc就已經很詳細了。
@jianjie_ohyeah:挺不錯 尤其是實現、可靠性保證、跨DC容災和流式的章節;不得不說,Kafka 是一款十分成功的的專案!
@zoltar:寫的非常清楚易懂,把很多設計點講了出來,非常好
另一本Kafka好書
1、《Apache Kafka 原始碼剖析》

以Kafka 0.10.0版本原始碼為基礎,本書從Kafka的應用場景、原始碼環境搭建開始逐步深入,不僅介紹Kafka的核心概念,而且對Kafka生產者、消費者、服務端的原始碼進行深入的剖析,最後介紹Kafka常用的管理指令碼實現,讓讀者不僅從宏觀設計上瞭解Kafka,而且能夠深入到Kafka的細節設計之中。
當然,無論讀哪一本都好,別忘官方檔案。(檔案地址:http://kafka.apache.org/documentation.html)
●輸入m獲取到文章目錄
