

分享專家: 孔再華 資料庫架構師
文章來源: 轉自talkwithtrend 公眾號
具有豐富的資料庫環境問題診斷和效能調優的經驗,擅長DB2 PureScale 叢集產品的專案諮詢和實施。
在兩地三中心建設過程中,我們發現採用傳統的容災技術碰到3個問題。
1. 切換時間太長,即使透過自動化實現,主切備和備切主都需要花費幾十分鐘時間。
2. 操作風險太大,比如核心系統切換涉及到20步以上的操作步驟和上百條命令,每條命令都有出錯的可能。
3. 建設成本太高,同城機房按照1比2甚至1比1 的比例進行建設,伺服器平時完全閑置,除了一次性投入,每年還要耗費大量的維護費用。
因此相對於傳統容災方式,我們希望建設一個雙活平臺,解決降低RTO時間、降低成本和降低切換風險等需求。
在雙活平臺的選型過程中,基於當前需求是傳統型業務(非網際網路型別)做遷移,當前資料庫base是DB2和Oracle,從平臺角度發起而不想對業務開發進行改造,最終實現雙機房對等雙活等因素,我們最終發現Db2 pureScale GDPC方案最適合。
這個方案特點明顯: 高可用性,可擴充套件性和對應用透明。那麼選好型後,怎麼落地成了最關心的問題。因為雙活技術的複雜性,在方案設計的每個環節都需要慎重考慮,選擇最合適的方式,最終形成自己需要的方案(以下為內容分享)。
1.為什麼要基於Db2 pureScale做資料庫雙活?優勢和意義是什麼?
為了保證資料多中心部署0丟失,降低容災切換時間,減少人為操作風險,降低成本。雙活系統就是要將這幾個方面做到極致。
在選型的過程中發現其實沒有太多選擇,能做到這一點的成熟軟體和技術只有Db2pureScale叢集技術和OracleRAC技術。這裡說說我們為什麼要用Db2pureScale而不是OracleRAC。
從業界經驗來說,OracleExtendRAC是面向同城雙活的資料庫產品,然而從各方瞭解都不推薦使用,即便是使用了這個技術的案例裡面,災備機房節點也只是作為熱備,沒有提供對等的服務,這個是與我們建設雙活的應用標的有差距的。而DB2 GDPC(地理位置上分開的pureScale叢集)方案從設計之初就是為了做對等雙活,國內也已經有上線案例。從廠商支援力度上來說,IBM主推這個技術並且支援好,Oracle相比差一點。從底層技術來說,IBM的pureScale在可擴充套件性,對應用透明等特點上是優於Oracle的。所以建議選擇Db2GDPC方案來建設雙活環境。
2. 基於Db2 pureScale的資料庫雙活方案設計,要遵循哪些重要原則?
如果將資料庫雙活平臺作為未來的常規建設,應用越來越多的系統,那麼在建設初期,我們就要設定好平臺的標的:
1、通用性:基於LUW開放平臺,支援部署在任何廠商的儲存、伺服器和作業系統上。不能選擇一體機,大型機等不通用的裝置。
2、無差別性: 雙中心交易對等,同城之間同時處理業務請求,無主次之分。只有這樣的系統才能面對失去單資料中心的風險。
3、高可用性:最下化降低同城切換時間,同城站點出問題不會影響全域性業務。業務切換需要在最短時間內完成。
4、可維護性:基礎設定重大變更不停機,可以透過滾動升級的方式完成維護操作。
5、可遷移性:平臺對業務系統透明,開發無需改動程式碼,即可快速部署到該平臺。同樣該平臺部署的系統也可平滑遷移出來。
6、安全穩定執行,該平臺可以實現5個9的執行標的。
基於以上標的,在Db2 pureScale的資料庫雙活方案設計裡面,我們遵循對等雙活和對應用透明的原則,剋服困難,最大化雙活的高可用性優點,改善效能相關的缺點。
總體設計
3.如何選擇雙中心站點和仲裁站點的定位,仲裁站點需要什麼條件?
首選需要說明DB2GDPC方案邏輯上需要三個站點,其中兩個站點作為雙活的資料中心,第三個站點作為仲裁站點。
雙站點的定位和條件:
1.雙活站點之間需要可靠的 TCP/IP 連結相互通訊,還需要RDMA(具有 RoCE 或 Infiniband)網路連結。具有成員和 CF 的兩個站點是生產站點,它們處理資料庫事務。這兩個生產站點相距應該不超過 50 公里,透過 WAN 或暗光纖(必要時還使用距離範圍擴充套件器)來連線這兩個站點,並且在它們之間配置了單個 IP 子網。距離更短將獲得更高效能。在工作負載相當少的情況下,可以接受更遠的距離(最多可達 70 或 80 公里)。
2.雙站點的CF和成員節點是對等的。每個生產站點都有一個 CF 以及相同數目的主機/LPAR 和成員。
3.每個生產站點都有它自己的專用本地 SAN 控制器。SAN 已分割槽,以便可從這兩個生產站點直接訪問用於 DB2 pureScale 實體的 LUN。在站點之間需要 LUN 之間的一對一對映,所以第一個站點上的每個 LUN 都在第二個站點上具有相同大小的對應 LUN。而GPFS同步複製用作儲存器複製機制。
4.對於RDMA網路支援RoCE和infiniband。個人建議使用RoCE,通用性和可部署性強。如果使用 RoCE 進行成員/CF 通訊:使用多個配接器埠進行成員和 CF 通訊,以適應其他頻寬和提供冗餘。對於以完全冗餘方式配置的總共四個交換機,在每個站點中使用雙交換機。將每個成員和 CF 中的其他系結的專用乙太網網路介面設定為 GPFS 脈動訊號網路。也就是我們說的私有TCP網路。如果使用 Infiniband 進行成員/CF 通訊:
僅支援每個成員和 CF 具有單個配接器埠以及每個站點具有單個交換機。此介面用於成員和 CF 通訊以及 GPFS 脈動訊號網路。
第三個站點的定位和條件:
1. 單個主機(非成員主機,也非 CF 主機),專用於叢集仲裁職責,與叢集中的其他主機位於相同作業系統級別。可以使用虛擬機器。
2. 不需要訪問兩個生產站點中的 SAN。
3.不需要RDMA通訊,也不需要私有網路(RoCE的情況下使用到的TCP私網)。
需要為叢集中的每個共享檔案系統都需要仲裁盤,這個檔案系統的仲裁盤就是從這個第三站點劃分出來的。沒有使用者資料儲存在這些裝置上,因為這些裝置僅用來儲存檔案系統配置資料以用於恢復,並且充當檔案系統磁碟配額的仲裁磁碟。這些裝置的大小需求為最小需求。通常,50 到 100 MB 的裝置在大多數情況下能夠滿足需求。此裝置可以是本地物理磁碟或邏輯捲 (LV)。
請遵循下列準則來配置 LV:
在同一捲組 (VG) 中建立邏輯捲。為捲組至少分配一個物理磁碟。實際數目取決於所需要的邏輯捲數,而邏輯捲數又取決於共享檔案系統數。如果有可能,請使用兩個物理捲以提供冗餘。
有限的條件下,例如只有兩個資料中心,仲裁站點可以放在所謂的主中心機房裡,但是硬體上要和其他節點分開。這個主中心機房的定位就是可能於此關聯的其他重要系統在這個機房,訪問更直接和快速。在存在這種定位的情況下,主CF節點,跑批的成員節點建議放在這個機房裡。
通訊網路設計
4. 如何規劃和設計叢集內部通訊網路?
在整個DB2GDPC的方案裡面,仲裁站點僅僅需要TCPIP網路通即可,不需要SAN,RDMA,私網等,所以需要重點關註雙活站點的CF和成員節點的網路設計。
1. 雙站點DWDM通訊硬體:建議冗餘,租用不同運營商線路。
2. 乙太網對外服務:乙太網卡建議做冗餘,採用雙網絡卡系結,建議是主備樣式。每個乙太網的交換機也建議冗餘,使用類似VPC等虛擬系結技術。交換機間互聯線路要求冗餘。
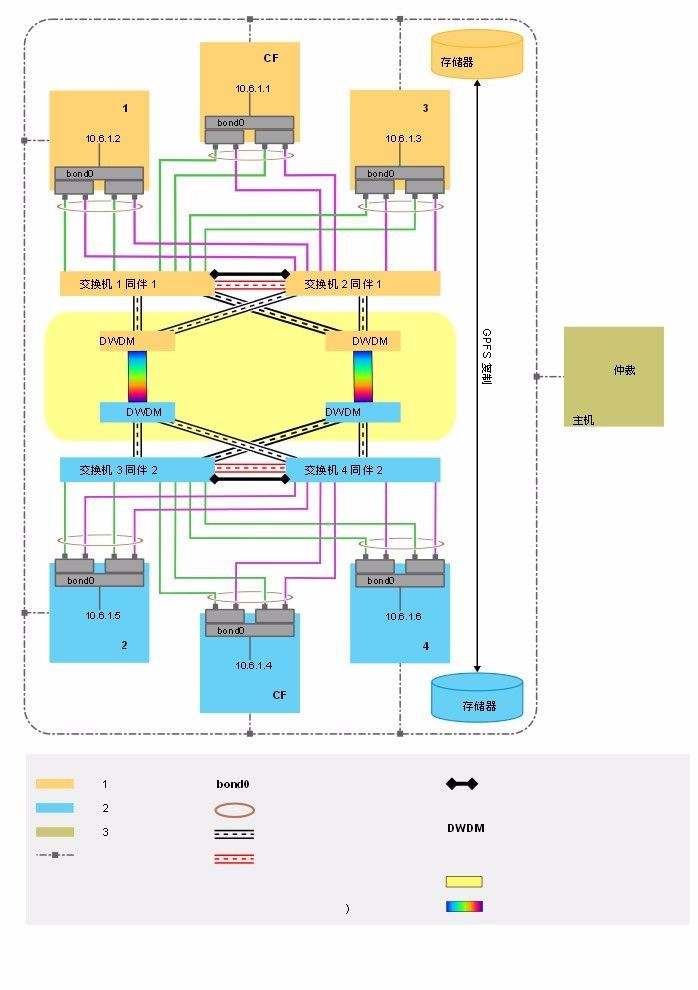
3. RoCE網路和私網:RoCE網絡卡自帶兩口,可以連線到不同的交換機上,但是這兩個口對於網絡卡吞吐量沒有影響。建議每個節點採用多網絡卡,每張網絡卡連結在不同的RoCE交換機上。RoCE網絡卡是不能做系結的,都是實際的物理地址。所有的RoCE網路都劃在一個VLAN裡面。這裡還要關註一個私網,專門給GPFS走心跳和資料的網路,是TCPIP協議。
這個私網建議做多口系結,也是主備樣式,每個口連線到不同的RoCE交換機上,與RoCE網路劃分在同一個VLAN裡面。交換機的建議和乙太網交換機差不多,每個站點冗餘系結。

共享儲存設計
5. 如何設計儲存網路,仲裁站點需要儲存嗎? NSD server怎麼配置?
透過一張圖來瞭解多站點GPFS複製拓撲。GPFS複製透過建立檔案系統的兩個一致的副本來提供儲存器級別的高可用性;每個副本在另一個副本發生故障時都可用於恢復。
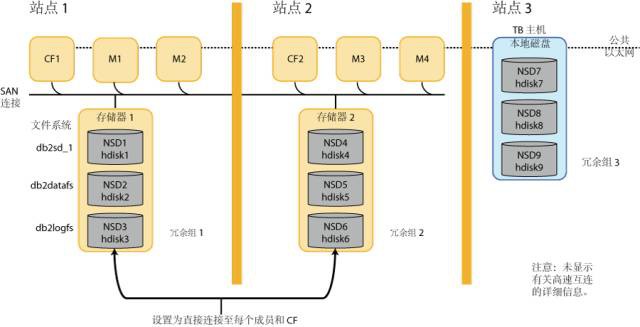
GPFS為檔案系統的第一個副本和第二個副本提供了兩個單獨的儲存控制器。這些儲存控制器分別稱為冗餘組 1 和冗餘組 2。GPFS將資料和檔案系統元資料都儲存在冗餘組中。
RSCT 和GPFS叢集使用多數節點配額而不是仲裁磁碟配額。對於具有三個地理位置分散的站點的 GDPC,主站點和輔助站點具有相同數目的成員,並且每個站點中都有一個 CF。第三個站點中存在單個仲裁主機。仲裁主機是包含所有檔案系統仲裁磁碟的檔案系統仲裁冗餘組的所有者。這些磁碟僅包含檔案系統描述符資訊(例如,檔案系統配置元資料)。
仲裁站點仲裁主機只需要透過 TCP/IP 訪問同一叢集中的其他主機。它不需要訪問冗餘組 1 和冗餘組 2 中的資料。在仲裁主機上面,每個共享檔案系統都需要獨立的檔案系統仲裁磁碟用於檔案系統配額以及進行恢復。每個磁碟最少需要 50 MB。它可以是本地物理磁碟或邏輯捲 (LV)。
擴充套件: 因為GPFS複製時透過在本機直接透過SAN訪問遠端磁碟來寫實現同步。當站點1和2之間網路出現問題的時候,資料複製需要停40秒(磁碟超時屬性)。這個在很多時候是不能容忍的,尤其出現網路質量差的情況下。所以我在這個地方做了些改進併在生產驗證。如圖中的db2logfs檔案系統是用來放置資料庫日誌的,當資料庫日誌的io停止的時候資料庫也是會hang住,所以我將db2logfs相關遠端盤的主機對映都去掉,這樣強制db2logfs在複製的使用tcp網路。
資源設計
6. 如何分配成員和CF節點的資源。在DB2 pureScale GDPC資料庫雙活技術方案設計的資源設計環節中,我們該如何劃分及分配成員和CF節點的資源? 從哪些點方面進行入手考慮(例如併發訪問量、資料量等),需要特別關註哪些什麼(例如寫讀比例、寫一致性、讀一致性等)?
CF和成員節點的記憶體主要就是CPU和記憶體的分佈,還有就是RDMA通訊網絡卡資源。
我們至今還沒有遇到網絡卡頻寬瓶頸。即便是在雙活環境出現CF和成員通訊瓶頸也不是因為頻寬,而是Db2叢集內部通訊的機制導致。所以對於RDMA網絡卡,冗餘滿足高可用即可。
成員CPU的估算是基於工作負載來的,直接比較的物件是單機的資料庫資源配置。因為成員相對於傳統單機資料庫有更多的消耗,所以在同樣一個節點的負載需求情況下,建議成員CPU要比單機更多一些。 CF的CPU需求和RDMA卡有關係。IBM官方推薦一個CF的RDMA卡口對應6-8個CPU核心。
成員節點的記憶體也是相對於同樣工作負載下單機的資料庫記憶體配置來比較的。因為成員和CF之間有了更多的鎖,所以主要區別就在於成員節點的locklist需求變得更大,個人建議調整為單機資料庫的兩倍吧。CF的記憶體消耗主要是GBP和GLM這兩大塊。給大家一個公式:GBP大小是LOCAL BUFFERPOOL總頁面數*1.25KB*MEMBER數量。GLM就是所有member節點locklist總和吧。解決這兩大塊的估算再加一些就是整個CF的記憶體配置需求量了。
訪問設計
7. 客戶端採用什麼方式連線資料庫節點?
在雙活環境,怎麼最大化負載均衡並不是最主要的考慮因素,最大化效能才是需要考慮的。因為跨站點的通訊延時,所以要儘量避免跨中心訪問。所以客戶端應該採用偏好連結的方式來訪問資料庫節點。
每個應用伺服器配置自己的資料源,透過Client Affinity的方式連線到資料庫成員節點,有效避免跨站點訪問。一旦成員節點出現故障,ACR可以自動將應用伺服器連線到其他存活的成員節點。
在這個基礎上,還有幾點需要註意:
1、跑批節點放在主CF同機房member上。
2、啟動資料庫的時候第一個啟動的成員節點要選擇和主CF在同一機房。因為有些資料庫的自動管理工作是在第一個啟動的member上完成的。
8.基於Db2 pureScale做資料庫雙活,對於重要業務需求的實現程度如何?方案的優點有哪些?
基於Db2 pureScale的資料庫雙活平臺在我行已經上線三年,期間陸續遷入了6套優先順序比較高的系統。整個執行過程算是達到了預期。也經歷過網路故障等實際考驗,表現都如預期。所以這個高可用性和可維護性都得到了驗證。
但是這個方案在滿足資料0丟失,可用性非常高的情況下,還是犧牲了部分效能。因為距離的原因,寫盤和通訊都不可避免延長。所以遷入地系統在跑批的時候明顯比以前長,這也是沒辦法的。
9.基於Db2 pureScale的資料庫雙活方案,有哪些侷限?有什麼可以繼續改進的地方呢?
在這個方案裡面,我覺得從技術上還有比較多的地方需要改進。一方面熱點資料問題,雖然我們透過分割槽表隨機索引等方式打散熱點資料,但是還是需要從資料庫技術層面給出更好的改進。
另一方面是節點之間的通訊,因為延時的緣故,還需要從技術上繼續減少互動。同時頻寬不是問題,通訊的併發性也需要從技術上去解決。相信如果上述幾個方面能夠得到改進,這個方案將會得到更大的運用空間。
本號技術實戰和總結(20+本)
請識別小程式獲取電子書詳細資訊

溫馨提示:
請搜尋“ICT_Architect”或“掃一掃”二維碼關註公眾號,點選原文連結獲取更多電子書詳情。

求知若渴, 虛心若愚

