來自:好想學Python(微訊號:stshouji)
作者:DJun(小丁),碼齡18年,從事IT工作5年,踩過無數“語言”坑最後入坑Python
從構思到程式碼實現,詳細講解如何透過Python用200行程式碼實現一個帶介面的爬圖程式小專案。主要使用介面模組PyQt 4+HTTP模組requests+HTML檔案解析模組lxml,涉及執行緒基本用法、佇列基本用法、記憶體IO操作、簡單影象處理等。
這次做的是可以邊爬圖、邊下載、邊看圖的一個小軟體,為了更好地演示,特別挑選了一個HTML原始碼看起來比較有代表性的相簿站點。
先來看看最終效果是怎樣的:
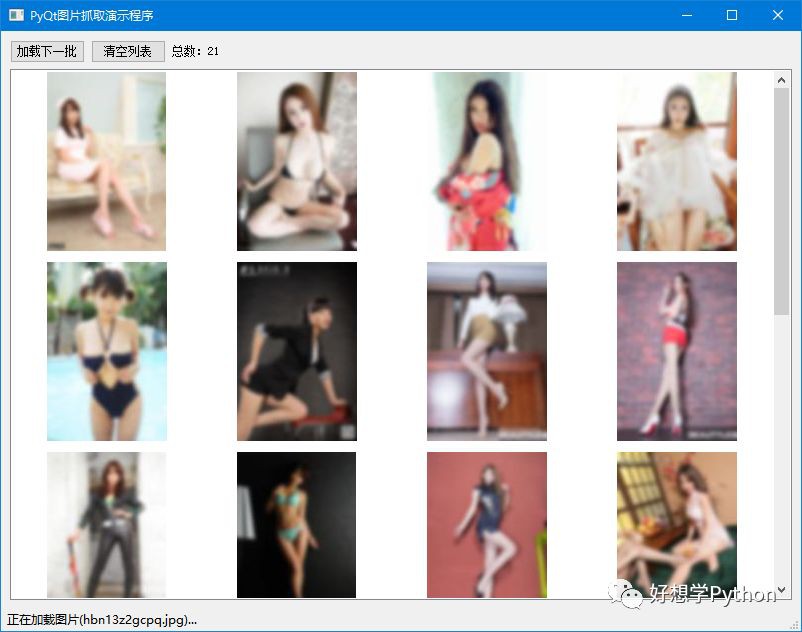
執行程式後:
① 自動從某相簿網站上抓取各種客氣小姐姐的照片,在介面上顯示預覽圖
② 每次載入一批並自動儲存在本地,需要時再點選按鈕載入下一批
③ 雙擊介面上的預覽圖開啟檢視高畫質大圖
聽起來是不是略cool?而這些並不需要多大的程式碼量(包括靈活的介面設計),就可以漂亮地實現。
嗯?你問筆者為何圖片是模糊的?由於會引起舒適,筆者在程式碼裡面用PIL影象處理庫加了點高斯模糊,不過只處理了介面上的預覽圖,實際下載下來的圖片檔案都是原圖資料未處理的哦。
(文章最後附上專案原始碼連結,其中包含用於演示的相簿網站的網址)
我們從實現效果倒推一下這個程式需要用到什麼“裝備”吧。
既然是爬圖,一般是會用到爬蟲常用的那幾款模組,本程式用的是“人用的”requests(“HTTP for humans”,它的slogan)做HTTP請求抓取HTML資料,然後用lxml處理,並用XPath解析得到網頁URL、圖片URL。
(requests中文檔案: http://docs.python-requests.org/zh_CN/latest/user/quickstart.html ;
XPath中文參考資料: https://www.runoob.com/xpath/xpath-tutorial.html )
爬下來的圖片需要顯示到介面上,那麼需要選用一款圖形介面模組,這裡選了PyQt(Qt的Python實現,Qt是源於1991年、曾在2008年被諾基亞收購、現屬Digia公司的一款非常強大的跨平臺圖形介面庫),別問我為什麼不用Python自帶的Tkinter,因為PyQt實在太香了,各種對圖形介面的支援都非常完善,自帶介面設計工具、資料轉換工具等,支援實現非常複雜的介面效果,而Tkinter擴充套件性太差就不提了。
綜合上面的兩種模組使用需求,我們還需要考慮:
① 爬圖時對網頁URL、圖片URL分開處理,從網頁URL獲取到HTML資料,解析出其中的網頁URL或圖片URL,而從圖片URL則直接獲取到圖片資料
② 爬圖過程中,不能因為爬圖正在工作而阻塞圖形介面導致介面無法操作,爬圖過程需要在後臺完成
③ 爬取一批圖片後自動暫停工作,點選按鈕繼續工作爬取下一批圖片
我們採用Python自帶的threading執行緒模組(Thread類、Lock類、Event類)、queue佇列模組(Queue類)來實現。
到這裡我們考慮到需要的暫時是這些:PyQt,requests,lxml,threading,queue。開發過程中需要其他的再作補充。
接下來可以開始動手啦,一邊分析,一邊開發程式。
01
爬圖思路
把圖片爬下來必須走的第一步,當然是對圖片所在的網頁進行解析啦。
我們先選一個網站上的頁面作為爬圖的起始頁面,這個頁面會包含很多圖集的入口連結。開啟Chrome(谷歌瀏覽器)訪問頁面,如圖。

我們選用圖上有多行每行四張小姐姐預覽圖的區域作為圖集的入口點。僅僅是一個頁面上這一小部分而已嗎?我們再往下看。

在最下麵有一行有“1”“2”“3”“4”……的翻頁連結,我們就選這裡作為翻頁爬取更多圖集的入口吧。
然後我們按F12開啟Developer Tools(開發者工具)檢視Elements(元素),在這裡可以看到頁面上的元素對應的HTML原始碼。不過直接在這裡找似乎太麻煩了,我們回到頁面,在預覽圖上點選右鍵,選擇“檢查”。

在Elements這邊就能直接看到剛才點選“檢查”的位置對應的網頁元素了。
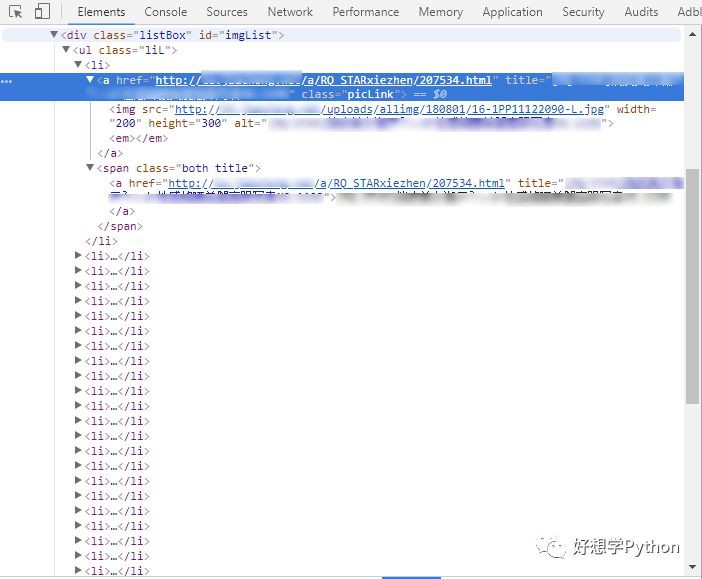
不難發現,網頁設計者在設計HTML模板時,對id、class的命名還是挺友好的,比如第一行的div標簽,id是“imgList”,我們推測是“圖片清單”的意思,可以確定我們需要的區域就在這個div標簽下麵。
div下的ul標簽下麵有一堆li標簽,每個li標簽分別對應一張預覽圖(li下麵的a標簽和img標簽)以及圖下麵的文字(li下麵的span標簽和a標簽)。觀察到兩個a標簽的href屬性都是一樣的,是進入到圖集的連結,我們取其一就行。
觀察到ul標簽有class屬性“liL”,我們由此寫出取出圖集連結的XPath:

為什麼要用ul這個標簽來定位呢?往後翻了幾個頁面,發現基本上是id為“imgList”的div標簽下麵跟一個class為“liL”的ul標簽,我們秉承“讓這條XPath儘量通用”的編寫原則,儘量利用能提取到確切需要的資料它的最簡特徵資訊,能不用id屬性儘量不用。最終寫出來的是上面這樣。
那下麵翻頁的連結如何取到呢?別緊張,我們接下來看看進入圖集後的頁面。

隨便點選一個圖集後,我們發現這裡下麵的這行有“1”“2”“3”“4”……的翻頁連結,不是長得跟剛才上一個頁面的翻頁連結一模一樣嗎?馬上用“檢查”看一下相關元素,筆者把兩邊的Elements放在一起截圖,方便對比,如圖。

不難發現,兩邊都有class為“pages”的div標簽,從“pages”這個詞推測這裡就是顯示翻頁連結的地方。同樣也是有ul標簽,以及下麵一堆li標簽分別對應網頁上的“1”“2”“3”“4”……這些連結。需要排除掉“首頁”、當前頁標號這些無用的連結,觀察到他們的href屬性都為“#”,那麼加個href屬性的篩選條件就可以了。另外觀察到需要取的連結的href屬性值都是不完整的,只有“xxxx.html”這種形式,這裡有個小技巧,透過Python自帶庫urllib.parse裡的urljoin()方法,將當前URL跟“xxxx.html”連線起來,就變成完整的連結了。待會在後面實現。
寫出取出翻頁連結的XPath如下:

在同樣的頁面上透過“檢查”檢視高畫質大圖對應的連結,

如法炮製,寫出取出高畫質大圖的XPath如下:

測試的時候發現,這樣子按部就班取出來的高畫質大圖,每次都是從同一個圖集同一個順序開始爬取。我們用Python自帶的random模組裡面的shuffle方法,對連結進行打亂,這樣每次爬取出來的就不全是一樣的了,非常隨緣。
抓取到的連結有網頁和圖片兩種,網頁的放入一個佇列,圖片的放入另一個佇列。分別開啟兩個執行緒,一個按順序從佇列裡面取出網頁URL,按照上面寫的三種XPath規則解析出來,再放入佇列,再從佇列取出新URL,如此反覆;另一個按順序從佇列裡面取出圖片URL,做下載的操作,併傳送Qt的訊號更新介面(不允許在非主執行緒中更新處在主執行緒中的介面),如此反覆。
限於篇幅,完整的雙執行緒+雙佇列的實現可以在專案程式碼中結合程式碼的背景關係進行理解。
爬圖的核心程式碼真的不多,除去執行緒的殼子、連同requests獲取資料的操作一起看,如圖所示。

小技巧:requests請求資料所用的User-agent可以透過在瀏覽器位址列輸入執行以下程式碼,在出現的彈窗中獲取。

02
介面設計
介面設計的部分相對簡單,這裡說一些比較關鍵的點吧。
安裝好PyQt後,在安裝目錄下會有qtdesigner程式,執行它開啟“Qt Designer”(Qt設計師),可以在這裡直接設計介面。
選擇MainWindow模板(包含基本窗體、選單欄、狀態列),然後來一波控制元件拖放操作,介面控制元件就設計好了。如圖。


綜合窗體設計預覽和“物件檢視器”來看,按鈕(QPushButton)和文字標簽(QLabel)是排列在“Horizontal Layout”(水平排列層,對應QHBoxLayout)裡面的,這個Layout跟下麵的“List Widget”(串列控制元件,對應QListWidget)又是排列在“Vertical Layout”(垂直排列層,對應QVBoxLayout)裡面的。這些控制元件並不是隨隨便便從控制元件欄拖動到窗體上處於絕對位置的哦!透過對控制元件屬性的簡單調校,是可以實現調整視窗大小或者最大化時只有下麵的List Widget擴大這樣的效果的。
其實用List Widget串列控制元件來顯示爬到的圖片的預覽圖並不是它本身設定的用法,藉助的是它“IconMode”(圖示樣式)的顯示方式,利用將圖片放入串列項的圖示(QIcon)裡面,把圖片排列顯示在串列控制元件上。
既然不是它本身設定的用法,必然會出現一些糾結的問題,比如橫豎向不同的圖片排列在一起的時候,會出現橫向圖片在格子中居上而不是居中的問題。查了很多檔案資料,嘗試了很多種方式,最後選擇“QPainter居中畫圖”的方式來解決問題,這些在專案原始碼中都有體現,這裡暫時不細講。
限於篇幅,對控制元件的調校細節,可以下載專案原始碼,用Qt Designer開啟“MainWindow.ui”檔案詳細檢視。
透過程式碼載入“MainWindow.ui”介面檔案的方式也很簡單,只需要呼叫uic.loadUi()方法即可。接著作一些事件關聯、訊號關聯。抽取出來看,大體框架如圖。

註意這裡的pyqtSignal產生的物件一定要放在類共有屬性下麵,否則會報錯“AttributeError: ‘PyQt4.QtCore.pyqtSignal’ object has no attribute ‘connect’”。限於篇幅,pyqtSignal相關用法請參考官方檔案(英文, http://pyqt.sourceforge.net/Docs/PyQt4/new_style_signals_slots.html )。
03
程式最佳化
爬圖、介面兩部分都設計好了,接下來考慮一下程式最佳化問題。
01
圖片分批載入
由於圖片的載入是在執行緒裡面實現的,執行緒裡面用一個“while True”迴圈,從佇列中取出圖片URL進行下載。我們需要一種能控制執行緒暫停的方式,來解決“分批載入”這個問題。
既然是執行緒相關,我們優先考慮一下threading模組裡面有什麼適合用的。檢視檔案發現,Event事件類比較適合這種使用場景。簡單說,Event產生的實體物件可以儲存一個標記,標記為False時,呼叫它的wait()方法可以進行阻塞等待,而標記為True時wait()方法不阻塞或者從阻塞中恢復。
為了方便,我們在MyMainWindow的初始化__init__()裡面操作一下:
self.running_event = Event()
self.running_event.set() # 一開始不需要讓執行緒等待,設定標誌為True然後在執行緒中加入等待的程式碼:
self.running_event.wait()但這樣子並不會自己自動產生阻塞,還需要寫一段程式碼主動設定標誌為False從而產生阻塞,於是在處理圖片URL的執行緒中加入判斷程式碼,如果達到批次數量時,就改變event的標誌為False,這樣當執行到wait()就會自動產生阻塞了,如下程式碼:
with self.data_lock:
if len(self.data_list) % self.PAGE_LIMIT == 0:
self.running_event.clear()最後在“載入下一批”的按鈕中加入程式碼解除wait()阻塞即可:
self.running_event.set()02
預覽圖載入小圖、高斯模糊、居中顯示
如果我們不清除串列控制元件中的圖片,隨著圖片數量增加,記憶體佔用會越來越高。不管Qt或者別的模組有沒有對這些地方作出最佳化,我們在程式開發的時候都要保持著隨時做最佳化的好習慣。
利用PIL模組,簡單幾行程式碼就可以把縮小圖片、高斯模糊兩種操作一起實現,先縮小再高斯模糊,在一般配置的機器上處理時間是非常短的。
考慮到預覽小圖的空間佔用並不會太高,我們在產生小圖的時候直接寫入到BytesIO即位元組記憶體IO中,讓QIcon最終載入存在於記憶體中的位元組資料即可。
關鍵程式碼如下:
# PIL開啟圖片
img = Image.open(file_name)
# 鎖定長寬比縮小圖片
w, h = img.size
ratio = self.PIC_SIZE / (h if h >= w else w)
img = img.resize((int(w * ratio), int(h * ratio)), Image.ANTIALIAS)
# 高斯模糊
img = img.filter(ImageFilter.GaussianBlur(radius=2))
# 暫存於記憶體中,使用BytesIO
bio = BytesIO()
img.save(bio, 'jpeg')
# 關閉PIL影象控制代碼
img.close()
# 從BytesIO載入圖片資料
qimg = QImage.fromData(bio.getvalue())
# 關閉BytesIO控制代碼
bio.close()限於篇幅,可以在下載專案程式碼後檢視具體實現。
03
爬取到的圖片檔案名的命名
文章開頭有一張儲存的圖片檔案的截圖,觀察到所有圖片檔案都是從圖片URL得到的原始檔案名,亂七八糟的。我們可以利用網頁上的標題文字來給圖片檔案重新命名。
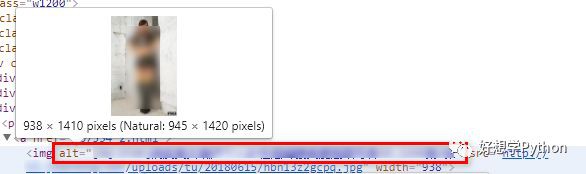
這一個最佳化點作為擴充套件練習題吧。處理思路:取用原網頁的img標簽的alt屬性文字(alt的值剛好是圖片標題)即可,如圖所示。同樣也可以用XPath取出。

獲取本專案請訪問:
https://github.com/djun/PyQtPicsCrawler
●編號501,輸入編號直達本文
●輸入m獲取文章目錄

Web開發
更多推薦《18個技術類微信公眾號》
涵蓋:程式人生、演演算法與資料結構、駭客技術與網路安全、大資料技術、前端開發、Java、Python、Web開發、安卓開發、iOS開發、C/C++、.NET、Linux、資料庫、運維等。