
作者丨孫子荀
單位丨騰訊科技高階研究員
研究方向丨多模態內容質量
本人過去幾年一直從事內容質量方面的演演算法工作,近期出於興趣對假新聞這個問題做了一些調研,簡單總結一下提供讀者參考。
在某種程度上假新聞的是一個微觀領域問題,它和謠言分類,事實判斷,標題黨檢測,垃圾內容挖掘等都比較類似,在宏觀上說都屬於內容質量的領域,所以很多方法其實是通用的框架。
本文主要簡單介紹了我們的做法和幾篇具有典型代表的假新聞論文,從不同的方法路徑去瞭解多模態、網路遊走、特徵挖掘等手段在假新聞領域上的一些實踐。
模型構建
根據 [Kai Shu, 2017] 的劃分,模型在這裡主要有兩類:1)基於內容的建模;2)基於社交網路的模型。
1. 基於內容建模
有 1.1 面向知識和事實庫的和 1.2 面向行文風格的。
1.1 面向知識庫
事實檢查系統有點類似謠言鑒別系統 ,對文章描述的觀點和客觀事物進行校真,類似 QA 系統是一個比較複雜的 NLP 領域,包括知識表示、知識推理。在知識庫資料集上有集中劃分方式:
1. 專家系統:各個領域的專家構建的知識庫, 顯然這種方式的效率和擴充套件性都非常差。 不過如果是垂直類目(生物,歷史)那或許可以在某個客觀事實比較多的類目下進行嘗試;
2. 集體智慧:使用者集體知識的反饋來構建的一套知識庫。
1 和 2 有了之後其實可以透過類似檢索的方法,來對新的內容進行相似度判斷,從而充分利用積累的歷史內容提供出來的特徵指示。
3. 基於演演算法分類:使用知識圖譜或者事理圖譜來對內容進行真實性判斷,當前主要的開放知識圖譜有 DB-pedia 和 Google Relation Extraction 資料集。
這個領域的問題,類似 NLP 的 QA 問題,有興趣的同學可以參考 [Yuyu Zhang, 2017] 的 VRN變分推理網路。
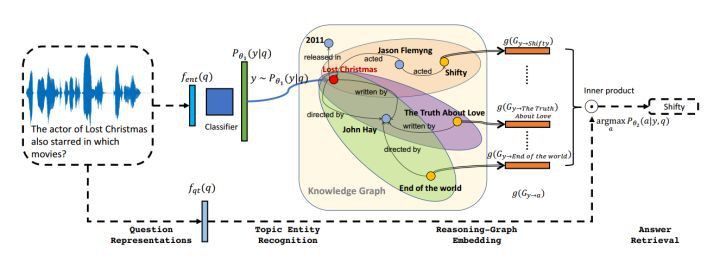
作者透過機率模型來識別問句中的物體,問答時在 KB 上做邏輯推理,且推理規則將被學習出來。即可用於做事實判斷。
當前這個方向技術落地成本高,難度較大,效果也不一定理想。
1.2 面向內容風格
用文章內容本身的行文風格,透過背景關係無關文法得到句子的句法結構,或者 RST 修辭依賴理論等其他 NLP 深度模型去捕捉句子文法資訊。
根據捕捉文字資訊描述種類的不同,作者分為兩類,檢測欺騙程度,檢測描述的主觀客觀程度(越客觀公正的可能性越大)兩種。震驚體的標題黨就屬於這類。
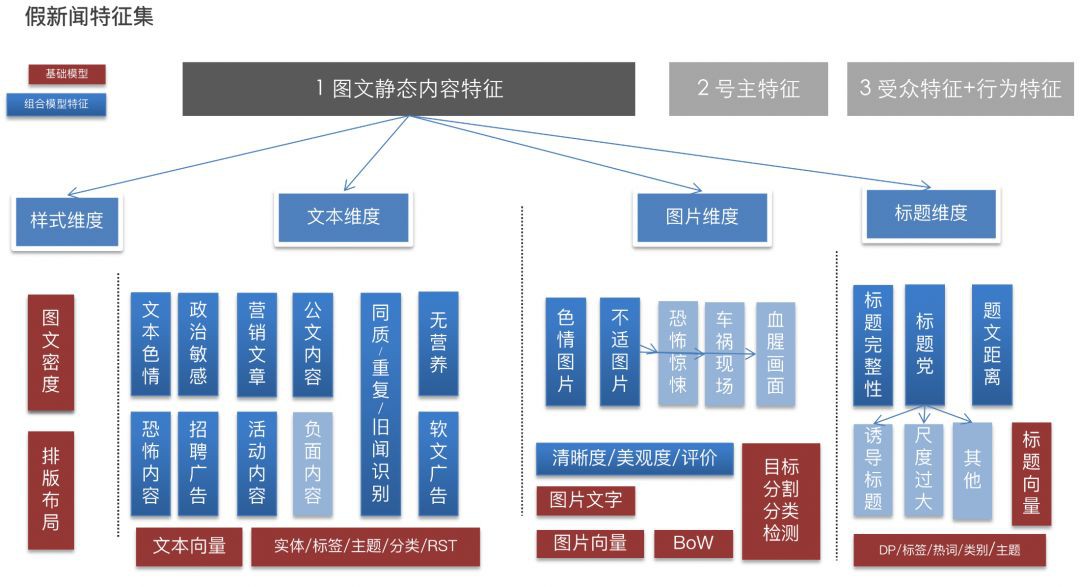
其中,假新聞可能用到的特徵,包括普通特徵和聚合特徵兩大類。普通特徵就是頁面,文字,圖片,標題等單純的特徵 embedding,聚合特徵就是把各個普通特徵進行組合和有監督的訓練成一個一個子模型問題。然後這些子模型的輸出又可以作為聚合特徵用在假新聞領域。
下圖就是我們使用的主要特徵集:
其他:基於社交網路建模
分為兩種,基於立場和基於傳播行為的。
前者主要是基於使用者對內容的操作(評論,點贊 ,舉報等等)構建矩陣或者圖模型。
而基於傳播行為對物件建模,類似 PageRank 的行為傳遞。下麵介紹的 News Verification by Exploiting Conflicting Social Viewpoints in Microblogs 一文就是這種型別 。
1. 對虛假新聞的傳播遊走軌跡跟蹤, 以及透過圖模型和演化模型中針對特定假新聞的進一步調查;
2. 識別虛假新聞的關鍵傳播者,對於減輕社交媒體的傳播範圍至關重要。
假新聞研究方向
[Kai Shu, 2017] 文章總結了假新聞的幾個主要的研究方向。
資料方面的研究工作:現在還沒有標準的測評資料集,這是需要去建立的。再有就是透過傳播特性去更早的檢測假新聞。另外一個就是從心理學角度去做假新聞的意圖檢測,這個角度過去往往被忽略。
模型特徵方面的研究工作:往往會使用使用者的畫像特徵,內容特徵(NLP、CV)結合深度學習,還有傳播網路特徵,比如使用者和內容之間的關係構造出來的網路特徵,網路本身的 embedding 表現。
模型方面的研究工作:第一個就是特徵之間的組合。第二是預測標的的變化。第三不論是從內容源,還是文章風格,或者內容的反饋(評論,等互動行為)都有各自的限制,組合這些模型。最後就是空間變換,把特徵變換到另外的 latent 語意空間嘗試解決。
資料集
FakeNewsNet
BuzzFeed 和 PolitiFact 兩個平臺的資料集,包括新聞內容本身(作者,標題,正文,圖片影片)和社交背景關係內容(使用者畫像,收聽,關註等)。
資料集可獲取方式:
https://github.com/KaiDMML/FakeNewsNet
代表論文

LIAR
該資料集也是來自 PolitiFact,包括內容本身和內容的基礎屬性資料(來源,正文)。
資料集可獲取方式:
http://www.cs.ucsb.edu/~william/data/liar_dataset.zip
代表論文

Twitter and Weibo DataSet
一個比較全的資料集包括帖子 ID,發帖使用者 ID,正文,回覆等資料。
資料集可獲取方式:
http://alt.qcri.org/~wgao/data/rumdect.zip
代表論文

Twitter15 Twitter16
被上面的資料集使用。來自 Twitter 15、16 年的帖子,包括了帖子之間的樹狀收聽,關註關係和帖子正文等。
資料集可獲取方式:
https://www.dropbox.com/s/7ewzdrbelpmrnxu/rumdetect2017.zip?dl=0
代表論文

Buzzfeed Election Dataset & Political News Dataset
Buzzfeed’s 2016 收集的選舉假新聞,以及作者收集的 75個 新聞故事。假新聞,真新聞和諷刺新聞。
資料集可獲取方式:
https://github.com/rpitrust/fakenewsdata1
代表論文

資料挖掘
[Benjamin D. Horne and Sibel Adalı,2017] 透過手工構建了大量的特徵,使用單因素方差分析和秩和檢驗對特徵進行挖掘。 發現真新聞文章明顯長於假新聞文章,假新聞很少使用技術詞彙,更少的標點符號,更少的引號和更多的詞彙是冗餘的。另外標題也有明顯的不同,假新聞的標題會更長,更喜歡增加名詞和動詞。真的新聞透過討論來說服,假新聞透過啟發來說服。
類似的內容分析還有:Automatic Detection of Fake News。
[z.zhao et, 2018] 發現大多數人轉發(紅點)真實新聞是從一個集中的來源(綠點)。而虛假新聞透過人們轉發其他轉發者來傳播的。

相關論文介紹
在工業界比如網際網路公司解決該類問題主要還是透過構建 pipeline,融合多個模型:內容向模型集,使用者向模型集,結合號主釋出者特徵,內容產生的使用者行為特徵等綜合構建一套體系進行解決。

我們在實際控制的時候結合了幾十個靜態 + 動態特徵模型和知識庫進行召回 pop 人工驗證。

然而和工業界處理問題不同的是,頂會的相關論文主要根據資料集的特點,透過單模型進行建模解決。主要的參考的維度有:1)內容本體 ;2)內容生產源(源,內容釋出者);3)內容閱讀者(使用者)及其行為(訂閱,評論)三大類,多個小類的特徵進行融合處理。
比如透過端到端的深度學習,基於機率分佈的特徵挖掘,構建新穎的綜合類標的函式等大一統的方式進行嘗試解決。很多模型往往只能在小規模資料集上進行實踐。我們介紹幾篇學術領域相關較新論文。


這篇是 CIKM 2017 的 long paper。作者認為透過構建社交圖譜並不便利,構建一些假新聞的特徵也需要大量人工知識。文章認為之前的檢測方法不能很好的一次整合正文(text),反饋(response),源(source)三者的特徵。論文的資料集來自 twitter 和 weibo,weibo 中的正文就是討論的某個話題,而非一般的文章,反饋就是主題參與者的回覆,源就是回覆的使用者。
整個架構由兩個部分組成:Capture 模組用於提取一篇正文所有的反饋文字資訊,透過 LSTM 來組裝多個回覆內容。 Scoure 模組透過構建使用者關係網路降緯後計算得到一對si和y^i ,si用於後續網路計算,y^i 也可用於單獨的使用者分析。

如上圖的 Capture 部分用來抽取文章和使用者的低維度表示 ,用一個 RNN 來抽取正文(text)的向量。

η 表示訂閱的數量 ,Xu 表示使用者的全域性特徵,xτ 就是所有回覆評論的文字特徵。
Score 部分,作者對於參與計算的使用者特徵構造,文中使用了使用者之間共同訂閱參與主題數量構建的矩陣,然後進行 SVD 降緯,獲得對使用者的表示 yi, 然後參與計算得到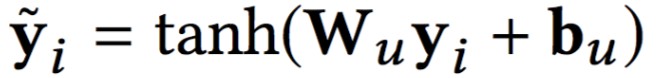 ,之後透過一個 mj 的 mask 處理,和上一階段得到的那些與正文 aj 產生關係的使用者,對應的特徵向量做求和平均之後得到文章打分向量 pj。
,之後透過一個 mj 的 mask 處理,和上一階段得到的那些與正文 aj 產生關係的使用者,對應的特徵向量做求和平均之後得到文章打分向量 pj。
Capture 得到的 vj 和 Score 的 pj 進行拼接,得到 cj, 最終的 Loss 函式是二分類交叉熵損失 sigmoid 加上 L2 正則約束。
最終的 Loss 函式是二分類交叉熵損失 sigmoid 加上 L2 正則約束。
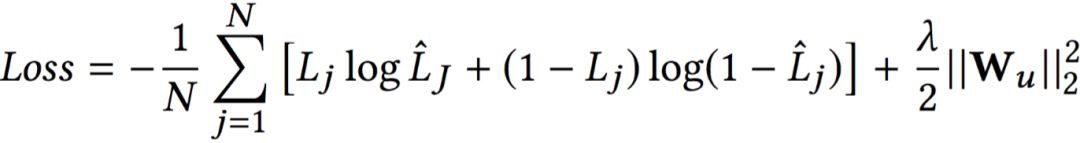
不得不說作者把基於使用者參與的內容對文章的刻畫和使用者之間的行為構建的網路對文章的刻畫,二者蘊含的資訊都轉化成文章的向量同時進行反向傳遞的標的學習,這點具有很大的突破性。


這篇是中科院計算機研究所的金志威和曹娟博士的研究工作,發表在 AAAI 2016。

Step 1:作者透過一個 Topic 模型來進行衝突的觀點挖掘。
透過對發帖的支援和反對行為構造信用網路(Credibility NetWork),作者認為每一個帖子(tweet)都是由一組混合的主題 topic,和對某個特定主題 topic 多種觀點 viewpiont 組成。 每一個主題-觀點(topic-viewpoint )pair,它的分佈引數來自 Dirichlet 分佈 。k 表示 topic 維度,l 表示 viewpoint 維度。
。k 表示 topic 維度,l 表示 viewpoint 維度。
1. 每一個帖子,組成它的所有 topic,符合一個引數為 θt 的 Dirichlet 分佈 。
。
2. 同樣對所有可能的 topic,組成它的所有的 viewpoint 同樣符合一個引數為 ψtk 的 Dirichlet 分佈。
然後怎麼生成文章呢,就是透過 θt 為引數的多項式分佈中得到主題,從 ψtk 的多項式分佈中得到觀點 Vtn,由於這裡已經確定了 ψtk 的 k,就是主題 k=Ztn,所以就是![]() ,l 就是 Vtn。
,l 就是 Vtn。
那最終一個 tweet 的 topic-viewpoint 生成的引數 Φkl 就可以寫成 ,就是產生自多項式分佈
,就是產生自多項式分佈 。
。
如果一個來自同一個主題下麵的多個主題-觀點 pair,之間距離非常大(設定值h) 。距離採用 Jensen-Shannon Distance(JSD),其實 JSD 是 KL Divergence(Dkl)的等價樣式。
具體衝突觀點挖掘如下:
1. 對一個新聞資料集建模,生成大量的 topic-viewpoint pair;
2. 比較同一個 topic 生成的 topic-viewpoint 對的 JSD,建立連結關係;
3. 用 Wagstaff et al 2001 提到的帶限制的 K-means 演演算法,把某個 topic 下的 viewpoint 觀點聚合成兩個彼此衝突的堆。
Step 2:構建網路迭代學習
接下來就是信用網路的定義。根據上面的主題模型挖掘,我們已經有了引數 θt(主題)和 ψtk(觀點),就可以得到一個 tweet t 在 topic k 上的 viewpoint l 觀點為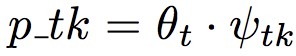 ,兩兩 tweet 的函式值定義為:
,兩兩 tweet 的函式值定義為: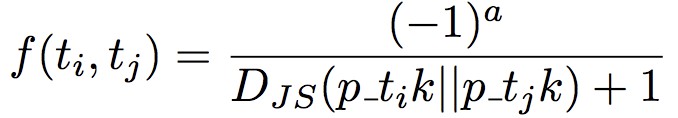 , Djs 表示 Jensen-Shannon 距離。wij 就是 f(ti,tj) 的矩陣。
, Djs 表示 Jensen-Shannon 距離。wij 就是 f(ti,tj) 的矩陣。
文中定義 loss function 如下:
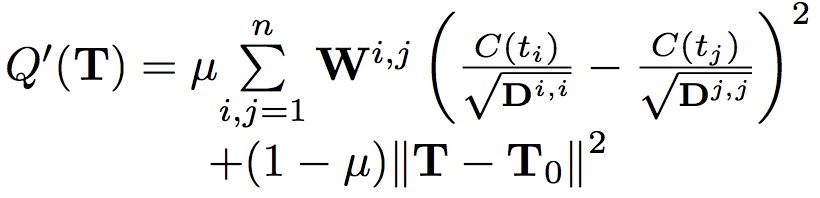
其中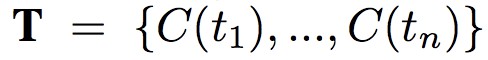 的 C(ti) 表示 tweet ti 的信用值,是需要學習的引數。 具體求導和證明網路可收斂過程可以參考論文,最終得到每 k 輪迭代的運算式:
的 C(ti) 表示 tweet ti 的信用值,是需要學習的引數。 具體求導和證明網路可收斂過程可以參考論文,最終得到每 k 輪迭代的運算式:



論文開始先透過大量資料分析挖掘,發現帖子內容,作者和主題三者和新聞的真假有很強的關聯性。於是把三者放入一個深度擴散網路中 ,同時最小化三者的標的。

論文透過學習顯式特徵(Explicit)和潛在特徵(Latent),潛在特徵透過 GRU 的 Hidden 層和 Fusion 層得到:
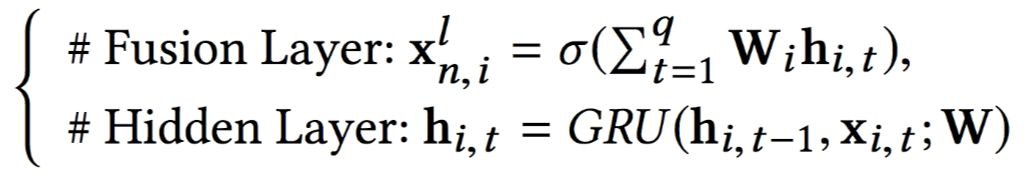

潛在特徵透過 GRU 的 Hidden 層和 Fusion 層得到:
論文提出了一個 GDU 單元,不僅可以針對帖子正文,還可以對作者,主題同時進行學習。


其中,作者的 L(Tu) 如下:

其他的 L(Tn) L(Ts) 是一樣的形式。
最終的網路架構三者相互連線起來如下圖:

論文和其他方法進行了對比。整個方法有點類似圖神經網路。


這篇文章中了 WSDM ’19 ,個人認為創新性很高。把作者(或者是釋出者),新聞,社交網路的使用者,和使用者直接的訂閱行為,構建了 5 個矩陣。


新聞內容矩陣;使用者矩陣;使用者-新聞行為矩陣,作者-新聞釋出關係矩陣。其中新聞內容矩陣,和使用者矩陣,採用 NMF 進行分解。


使用者-新聞行為矩陣分解的標的是:高信用分的使用者偏好分享真實新聞,低信用分使用者偏好分享假新聞。

作者-新聞釋出關係矩陣分解的標的:基於新聞釋出者的潛在特徵,可以透過他釋出的行為得到。文章把新聞釋出者分為各種黨派風格 o ,然後用分解後的矩陣擬合這個特徵。
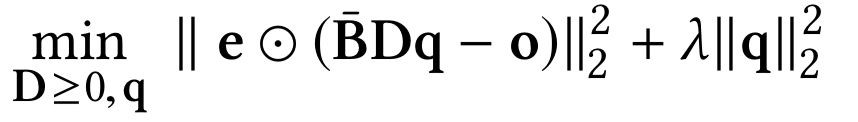
透過和 Hadamard 正交矩陣做運算 ⊙ 來衡量誤差大小。
最後透過把剛剛幾個矩陣得到的分解矩陣進行運算,最終標的是:
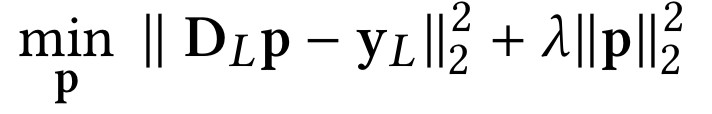
把所有的矩陣分解標的和最終標的拼接起來就得到的整體標的函式:
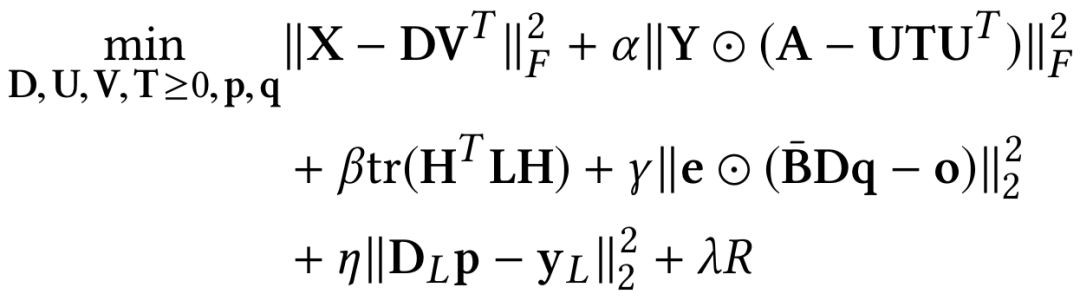
具體求導過程需要一定數學知識,對這篇論文有興趣的同學可以看原文。
相關比賽
Dean Pomerleau 和 Delip Rao 在 2017 年舉辦了假新聞挑戰:Exploring how artificial intelligence technologies could be leveraged to combat fake news.
比賽地址:
http://www.fakenewschallenge.org/
訓練樣本和預測輸入都是一個長事件標題和一段正文內容。輸出的標的是正文內容是對標題的:1)贊同,2)反對,3)討論,4)不相關。

組委會認為,觀點檢測任務和假新聞任務場景是有強相關的,僅僅相關或不相關會比較容易。透過正文來分析觀點是否贊同標題的內容陳述。第一名採用了深度摺積神經網路和 GBDT 兩個模型。第二名採用了多種模型得到特徵(如 NMF,LDA ,LSI,unigrams 等等)加上多層 MLP。這次比賽其實只能算假新聞領域的一個子問題的嘗試。
[Andreas Hanselowski, 2018] 這篇 COLING 的 Long Paper 中作者對這次比賽的前三名的方法和特徵表現進行了分析,提出了自己的改進方案,取得了該任務 state-of-the-art 的表現。

他們的框架把語意資訊特徵透過 stackLstm 表徵,再加上對標題和正文的特徵融合,實驗表現在小樣本的類別上有明顯提升。
參考文獻
[1]. Yuyu Zhang, Hanjun Dai, Zornitsa Kozareva, Alexander J. Smola, Le Song. “Variational Reasoning for Question Answering with Knowledge Graph”. arXiv preprint arXiv:1709.04071, 2017.
[2]. Zhiwei Jin, Juan Cao, Yongdong Zhang, and Jiebo Luo. “News Verification by Exploiting Conflicting Social Viewpoints in Microblogs”. AAAI 2016.
[3]. Kai Shu, Suhang Wang, Huan Liu. “Beyond News Contents: The Role of Social Context for Fake News Detection”. WSDM 2019.
[4]. Kai Shu, Amy Sliva, Suhang Wang, Jiliang Tang, Huan Liu. “Fake News Detection on Social Media: A Data Mining Perspective”. SIGKDD 2017.
[5]. William Yang Wang. “Liar, Liar Pants on Fire”: A New Benchmark Dataset for Fake News Detection. ACL 2017.
[6]. Natali Ruchansky, Sungyong Seo, Yan Liu. “CSI: A Hybrid Deep Model for Fake News Detection”. CIKM 2017.
[7]. Andreas Hanselowski, Avinesh PVS, Benjamin Schiller, Felix Caspelherr, Debanjan Chaudhuri, Christian M. Meyer, Iryna Gurevych. “A Retrospective Analysis of the Fake News Challenge Stance Detection Task”. arXiv preprint arXiv:1806.05180, 2018.
[8]. Benjamin D. Horne, Sibel Adali. “This Just In: Fake News Packs a Lot in Title, Uses Simpler, Repetitive Content in Text Body, More Similar to Satire than Real News”. ICWSM 2017.

點選以下標題檢視更多往期內容:
讓你的論文被更多人看到 如何才能讓更多的優質內容以更短路徑到達讀者群體,縮短讀者尋找優質內容的成本呢? 答案就是:你不認識的人。
總有一些你不認識的人,知道你想知道的東西。PaperWeekly 或許可以成為一座橋梁,促使不同背景、不同方向的學者和學術靈感相互碰撞,迸發出更多的可能性。
PaperWeekly 鼓勵高校實驗室或個人,在我們的平臺上分享各類優質內容,可以是最新論文解讀,也可以是學習心得或技術乾貨。我們的目的只有一個,讓知識真正流動起來。
? 來稿標準: • 稿件確系個人原創作品,來稿需註明作者個人資訊(姓名+學校/工作單位+學歷/職位+研究方向) • 如果文章並非首發,請在投稿時提醒並附上所有已釋出連結 • PaperWeekly 預設每篇文章都是首發,均會新增“原創”標誌
? 投稿郵箱: • 投稿郵箱:hr@paperweekly.site • 所有文章配圖,請單獨在附件中傳送 • 請留下即時聯絡方式(微信或手機),以便我們在編輯釋出時和作者溝通
 #投 稿 通 道#
#投 稿 通 道#
?
現在,在「知乎」也能找到我們了
進入知乎首頁搜尋「PaperWeekly」
點選「關註」訂閱我們的專欄吧
關於PaperWeekly
PaperWeekly 是一個推薦、解讀、討論、報道人工智慧前沿論文成果的學術平臺。如果你研究或從事 AI 領域,歡迎在公眾號後臺點選「交流群」,小助手將把你帶入 PaperWeekly 的交流群裡。

▽ 點選 | 閱讀原文 | 獲取最新論文推薦

