
導讀:資料與資料應用中的許多概念彼此有著千絲萬縷的聯絡,同時也有著概念上的偏重與區別,那我們可以先從資料應用領域中的常見概念先聊起。
作者:高揚、衛崢、尹會生
插畫設計:萬娟
01 什麼是資料
資料是什麼?這幾乎成為一個我們熟視無睹的問題。
有不少朋友腦子裡可能會直接冒出一個詞“數字”——“數字就是資料”,我相信會有一些朋友會斬釘截鐵地這麼告訴我。
一些朋友會在稍作思考後回答“數字和字元、字母,這些都是資料”。
不知道你現在是不是正在糾結哪個回答更正確,亦或第二個回答更合理一些,我們先放一放。先看下麵這組例子:
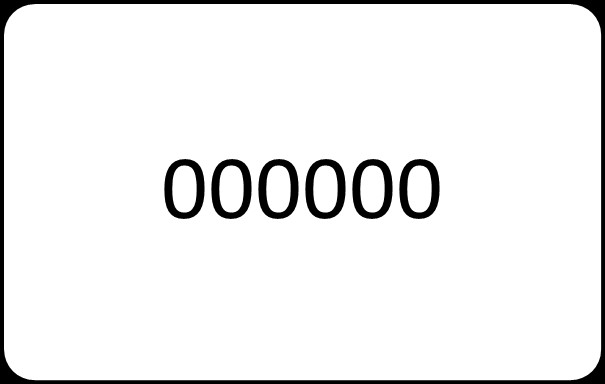
這裡有6個0,請問它是資料嗎?
我們再看這樣的例子:

這裡有4個1和2個a,那麼它是資料嗎?
也許你可能會搖搖頭,“這到底是啥意思?”不錯,這也就是我們在認識資料的過程中存在的一個很要命的問題,幾乎在我們出發時就攔住了我們的去路。
我們回過頭再想想剛才的問題可能會得到比較令自己和他人信服的回答“承載了資訊的東西”才是資料,換句話說,不管是石頭上刻的畫,或者小孩子在沙灘上歪歪扭扭寫出的字跡,或者是嬉皮士們在牆上的塗鴉,只要它表達一些確實的含義,那麼這種符號就可以被認為是資料。而沒有承載資訊的符號,就不是資料。這個觀點似乎看上去要比我們前面的回答理性得多,也科學得多,但是這個觀點真的不需要補充了嗎?
我們假設這兩個例子都有一些比較特殊的場景,假設第一組裡出現的6個0其實是時分秒的簡寫,000000表示00點00分00秒,而如果寫作112349則表示11點23分49秒的含義,那麼它是不是也是資料呢?假設第二組出現的5個1和2個a其實是一組密碼,5個1代表一個被約定的地點,aa代表一種被約定的事件,那這組數字字母的意義也有了相應的解讀,那麼它是不是也是資料呢?
不難看出,一些符號如果想要被認定為資料,那就必須承載一定的資訊。而資訊很可能是因場景而定,因解讀者的認知而定,所以一些符號是不是可以被當做資料,有相當的因素是取決於解讀者的主觀視角的。不知道這個觀點你是不是認可,總之這點很重要。
02 什麼是資訊
說到這裡,我的同事娟娟非常認真且煞有介事地跟我說:“我覺得數字、字母、影象,這些都是資料,跟資訊不資訊的沒啥關係。”看著她認真地跟我抬槓,我覺得蠻好,至少在認識資料過程中積極思考只有好處。

資訊一詞,在沒有學術背景的情況下其實有著很多解釋,例如,廣播中的聲音、網際網路上的訊息、通訊系統中傳輸和處理的語音物件、甚至是小區和校園的訊息看板,也就是人類社會傳播的一切內容。1948年,數學家夏農(Claude Elwood Shannon)在題為《通訊的數學理論》的論文中指出:“資訊是用來消除隨機不定性的東西”。這句話如果要我們來舉個例子說明的話,大概可以想象這樣一個場景。
我說了兩句話:“我今年33歲。”“我明年34歲。”
那麼第一句話如果是為了對不瞭解我的人介紹我的年齡的話而可以算作資訊的話,第二句話則不是資訊。至少你會覺得說了第一句以後,後面這句簡直就是廢話,因為這個從第一句話完全可以推匯出來。

再比如,某一天巴西足球隊和中國足球隊進行了比賽。
-
結果第二天張三告訴我,“昨天巴西隊贏了。”
-
而後李四告訴我,“昨天中國隊輸了。”
-
再而後王五告訴我,“昨天的比賽不是平局。”

前提是隻要他們都是說實話的人,那麼對於我來說,也就只有張三告訴我的能算資訊,李四和王五說的則不能算做資訊。甚至連張三說的“昨天巴西隊贏了”這句話是否能夠被算作資訊,我們都要表示懷疑,因為這也有點“廢話”的意味——但凡對足球運動有點認識的人這幾乎可以認定,即便你不告訴我昨天巴西隊贏了,我也能猜個八九不離十,因為可能性實在是太大太大了,大到幾乎是一定的,幾乎是毋庸置疑的。國足的粉絲們請放下手中的臭雞蛋和爛西紅柿,聽我把例子講完。
現在資訊是什麼清晰多了吧?我們可以粗忽地認為,資訊就是那些把我們不清楚的事情闡明的描述,而已經明確或者知曉的東西讓我們再“知曉”一遍,這些被知會的內容就不再是資訊了。這個概念是很有用的,我們後面在講資訊理論的時候也會再做定量的說明,現在只做一個定性的瞭解。
資料和資訊是我們在資料挖掘和機器學習領域天天要打交道的基礎,也是我們研究的主要物件。所以對資料和資訊有個比較一致性的認識對後面咱們討論問題是非常有好處的。
03 什麼是演演算法
演演算法這個名稱大家應該通常不陌生,如果你是一個資訊相關專業的本科學生,至少在本科一年級或者二年級就接觸過不少演演算法了。隨便開啟一個人力資源網站去搜搜看“演演算法工程師”,好的演演算法工程師的年薪也隨便就到三五十萬甚至上百萬的都有的。
演演算法是什麼?演演算法可以被理解成為“計算的方法和技巧”,在計算機中的演演算法大多數指的就是一段或者幾段程式,告訴計算機用什麼樣的邏輯和步驟來處理資料和計算,然後得到處理的結果。
科班出身的資訊相關專業的朋友看到這裡就會覺得比較親切了,經典的演演算法有很多,比如“氣泡排序”演演算法,這幾乎是所有以高階語言為依託的《資料結構》的入門必學;再比如“八皇后問題”演演算法,這幾乎也是我們在講窮舉計算時的經典保留演演算法案例(就是在國際象棋棋盤上放八個能夠橫豎斜無限制前進的皇后,讓它們之間互相還不能攻擊,看有多少種解);還有不少我們聽說過的演演算法,比如MD5演演算法,ZIP2壓縮演演算法等各種不勝列舉的演演算法。下圖就是八皇后問題的一組解,我們經過窮舉是可以求出所有92組解的。

應該說演演算法是資料加工的靈魂。如果說資料和資訊是原始的食材,資料分析的結論是菜餚,那麼演演算法就是烹調過程;如果說資料是玉璞,資料中蘊含的知識是價值連城的美碧,那麼演演算法就是玉石打磨和加工的機床和工藝流程。
演演算法在高階語言發展了很多年之後,更多的被封裝成了獨立的函式或者獨立的類,開放介面供人呼叫,然而演演算法封裝地再好卻是不能用純粹不假思索地使用就能獲益的東西,要知道,這些封裝只是在一定程度上避免了我們重覆發明輪子而已。
大家不要以為演演算法全都是演演算法工程師的事情,跟普通的程式員或者分析人員無關,演演算法說到底是對處理邏輯理解的問題。
《孫子兵法·作戰篇》有雲,“不盡知用兵之害者,則不能盡知用兵之利”,意思是說,不對用兵打仗的壞處與弊端進行充分瞭解的話同樣不可能對用兵打仗的好處有足夠的認識。演演算法的應用是一個辯證的過程,不僅在於不同演演算法間的比較和搭配使用有著辯證關係,在同一個演演算法中,不同的引數和閾值設定同樣會帶來大相徑庭的結果,甚至影響資料解讀的科學性。這一點請大家務必有所註意。
04 統計、機率和資料挖掘
統計、機率、資料挖掘,這幾個詞經常伴隨出現,尤其是統計和機率兩個概念,幾乎就像自然界的伴生礦一樣分不了家,有很多出版社都出版過叫做《機率統計》的書籍。
我們這本書本身也不準備從學術的角度給統計和機率做嚴格的區分,在平時工作中我們用的統計大多為計數功能,例如我們在使用EXCEL中也會用到COUNT、SUM、AVERAGE等這些統計函式;如果是在軟體開發的朋友在用SQL語言對資料庫的某些欄位進行計數(count)、求和(sum)、求平均(avg)等函式。而機率的應用大多則是根據樣本的數量以及佔比得到“可能性”和“分佈比例”等描述數值。當然,機率的用法遠其實不止這些,在資料挖掘中同樣用到大量機率相關的演演算法。
資料挖掘這個詞很多時候是和機器學習一起出現,現在網上眾人對這兩個詞的關係說法也是莫衷一是。有的說資料挖掘包含機器學習,有的說機器學習是資料挖掘發展的更高階段云云。在我看來,資料挖掘和機器學習這樣的詞彙命名應該是資訊科學自然進化和衍生出來的,帶有一定的約定俗成的色彩,人們的看法見仁見智也在情理之中。
我的觀點是這樣。
首先我認為沒有必要一定要給兩個詞彙劃一個界限,或者一定要把他們做嚴格的概念區分,因為區分的標準到目前本就沒有科學而無爭議的界定,況且是不是能分清一個演演算法屬於資料挖掘的範疇還是機器學習的範疇對於演演算法本身使用是沒有任何影響的。這兩個詞大家如果想聽解釋的話,不妨只從字面意思去理解就已經足夠了。
資料挖掘——首先是有一定量的資料作為研究物件,挖掘——顧名思義,說明有一些東西並不是放在錶面上一眼就能看明白,要進行深度的研究、對比、甄別等工作,最終從中找到規律或知識,“挖掘”這個詞用的很形象。
機器學習——我們先想想人類學習的目的是什麼?是掌握知識,掌握能力,掌握技巧,最終能夠進行比較複雜或者高要求的工作。那麼類比一下機器,我們讓機器學習,不管學習什麼,最終目的都是讓它獨立或至少半獨立地進行相對複雜或者高要求的工作。我們在這裡提到的機器學習更多是讓機器幫助人類做一些大規模的資料識別、分揀、規律總結等人類做起來比較花時間的事情。但是請註意,與資料挖掘一起出現的這個機器學習概念和我們說的“人工智慧”還是相差甚遠,因為這裡面對“智慧”的考究程度實在是太低了。
05 什麼是商業智慧
另一個和大資料一起經常出現的詞彙是商業智慧,也就是我們平時簡稱的BI(Business Intelligence)。

商業智慧——業界比較公認的說法是在1996年最早由加特納集團(Gartner Group)提出的一個商業概念,透過應用基於事實的支援系統來輔助商業決策的制定。商業智慧技術提供使企業迅速分析資料的技術和方法,包括收集、管理和分析資料,將這些資料轉化為有用的資訊。如果這個書本式的概念讀起來還是比較費解,那麼就聽一個形象的比喻。
公司在日常運營過程中是需要做很多決策的,無時無刻都存在於公司的各個方面,而決策最終不管是股東大會討論也好還是企業領導部門領導直接釋出行政命令也好,最終可能是由於很多因素共同影響做出的結果,無論其來自主觀還是客觀。
這些決策可以如何得出呢?可以領導直接憑經驗決定;可以群策群力開會決定;可以問訊很多行業專家;甚至可以找個算卦先生來占卜……從概念來說都是屬於輔助決策。而顯然,我們都期望不論最終是如何做出的這些決策和命令,它們都應該是更為理性、科學、正確的。但是如何幫助他們做出更為理性、科學、正確的決策呢?商業智慧整體也就是研究這樣一個課題,到目前為止,業界普遍比較認可的方式就是基於大量的資料所做的規律性分析。因而,市面上成熟的商業智慧軟體大多都是基於資料倉庫做資料建模和分析,以及資料挖掘和報表的。
可以說,商業智慧是一個具體的大的應用領域,也是資料挖掘和機器學習應用的一個天然親密的場景。而且商業智慧這個解決問題的理念其實不僅僅可以應用於商業,還可以應用於國防軍事、交通最佳化、環境治理、輿情分析、氣象預測等等。
關於作者:高揚,金山軟體西山居資深大資料架構師與大資料專家,有多年程式設計經驗和多年大資料架構設計與資料分析、處理經驗,目前負責西山居的大資料產品市場戰略與產品戰略。專註於大資料系統架構以及變現研究。擅長資料挖掘、資料建模、關係型資料庫應用以及大資料框架Hadoop、Spark、Cassandra、Prestodb等的應用。
衛崢,西山居軟體架構師,多年的軟體開發和架構經驗,精通C/C++、Python、Golang、JavaScript等多門程式語言,近幾年專註於資料處理、機器學演演算法的研究、應用與服務研發。
尹會生,西山居高階系統工程師。曾任新浪研發中心技術經理、北京尚觀科技高階講師。擅長企業叢集解決方案和核心調優經驗,並提供高效能和高可用性叢集諮詢服務。近4年專註於Hadoop叢集、Spark叢集在推薦系統和BI相關領域的解決方案。
萬娟,星盤科技有限公司UI設計師平面,對VI設計、包裝、海報設計等、商業插畫、App互動、網頁設計等有獨到認識。多次參與智慧家居和智慧音箱等專案的UI設計。多次參加國際和國內藝術和工業設計比賽,並獲獎。從小酷愛繪畫,理想是開一個屬於自己的畫室。
本文摘編自《白話大資料與機器學習》,經出版方授權釋出。

延伸閱讀《白話大資料與機器學習》
轉載請聯絡微信:togo-maruko
點選文末右下角“寫留言”發表你的觀點
推薦語:以降低學習曲線和閱讀難度為宗旨,重點講解了統計學、資料挖掘演演算法、實際應用案例、資料價值與變現,以及高階拓展技能,清晰勾勒出大資料技術路線與產業藍圖。

更多精彩
在公眾號後臺對話方塊輸入以下關鍵詞
檢視更多優質內容!
PPT | 報告 | 讀書 | 書單 | 乾貨
Python | 機器學習 | 深度學習 | 神經網路
區塊鏈 | 揭秘 | 高考 | 數學
猜你想看
Q: 現在你知道什麼是資料了吧?
歡迎留言與大家分享
覺得不錯,請把這篇文章分享給你的朋友
轉載 / 投稿請聯絡:baiyu@hzbook.com
更多精彩,請在後臺點選“歷史文章”檢視

 點選閱讀原文,瞭解更多
點選閱讀原文,瞭解更多
